在本立场文件中,我们探讨了现有KE技术的若干局限,并主张有效的知识编辑必须考虑知识表征的复杂本质。我们提出三个潜在研究方向:(1)通过演绎闭路编辑处理知识互依性;(2)将模型的信念与置信度融入编辑过程;(3)为复杂互依的知识形式实现情境化更新。这些方向共同指向一种更系统化的KE方法演进路径,以期支撑下一代具备适应性与推理驱动能力的AI系统。
1 引言 大型语言模型(LLMs)[1, 2] 在众多领域展现出卓越性能,但其知识无法适应动态变化的世界,这构成了主要局限。与能够持续整合新知识并调整信念的真正智能不同,现有LLMs是静态的,在训练完成后便固化不变。这种静态特性引发了若干关键挑战:模型会随着世界变化而过时、在生成事实性知识时产生幻觉,并可能沿袭训练中学到的不安全规范。更新LLMs的传统方法需依赖计算成本高昂的重训练,或借助外部数据库的检索增强生成,但这些方法存在资源密集、时间延迟与检索鲁棒性等问题。
近年来,知识编辑(KE)[3–7] 作为一种替代性解决方案应运而生。它通过高效、精准地更新模型内部存储的知识,为实现更具适应性和可信度的AI系统提供了可能:现代KE技术 [8–10] 已能执行数千次连续编辑,同时保持模型的通用能力,从而使模型能够及时感知政策更新、人员变动与世界事件演变等日常变化。除了基础的知识更新,当前KE方法还可用于多样化应用,包括内容净化 [11]、隐私保护、机器遗忘 [12] 及人格调适 [13]。这些成果确立了KE在实际部署中作为动态模型维护与可控AI行为的一种可行且必要的方法。
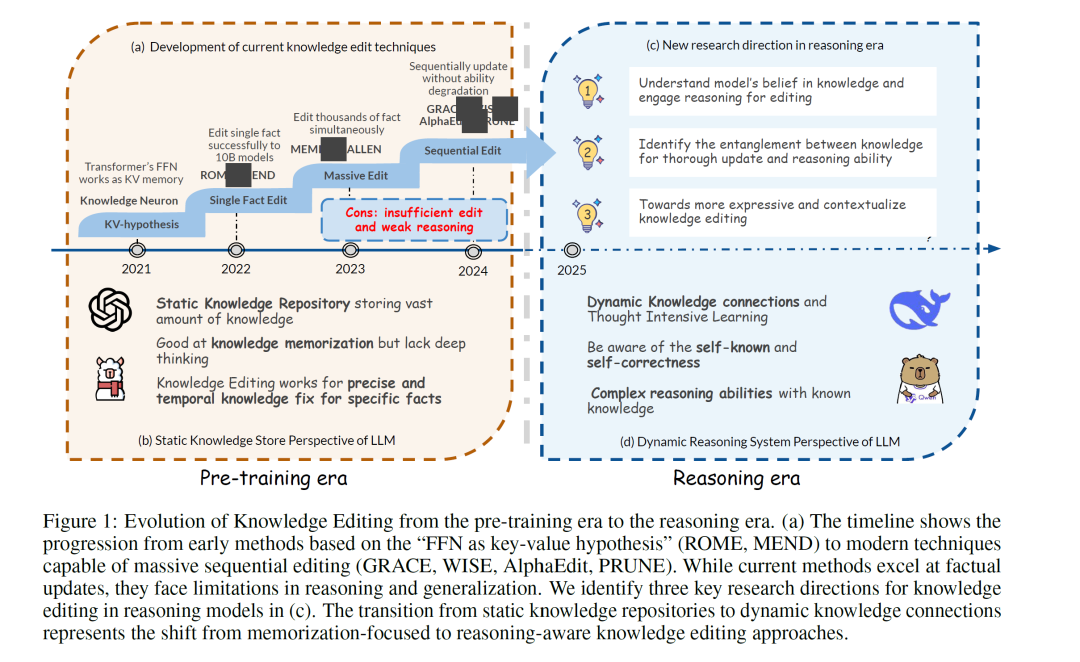
尽管取得了这些技术进步,当前KE方法仍存在一些局限,阻碍了其在智能推理模型中的实际应用。如图1(a)所示,现有方法主要聚焦于事实性知识,并基于“前馈网络充当键值记忆”的假设(见第2.2节),在推理密集型任务上泛化能力较差 [14, 15],且难以处理需要深入理解事实间关系的复杂知识场景。我们认为,这些局限源于当前KE范式与知识本质之间的错位:当前KE将知识视为孤立的原子三元组(图1(b)),未能考虑知识本身并非原子化而是相互缠结的特性。任何知识单元的意义、有效性与效用都源自其在动态、相互依存、语境敏感的其他知识单元网络中所处的位置。这种范式不匹配在推理模型时代变得尤为明显 [16],此时LLMs展现出连接离散知识片段、进行复杂推理推断以及基于内部信念与自我意识做出决策的复杂能力(图1(d))。在此类系统中,若在编辑单一事实时不考虑其与相关知识间的关联,往往会导致逻辑不一致与泛化能力弱,这是构建连贯、自适应AI的根本障碍。
为弥合这一关键差距,本立场文件提出一种新的、基于知识机制的KE框架。尽管现有综述 [17, 18] 主要关注方法分类与基准性能,我们将深入探究知识存储与编辑的基本机制,阐明当前方法为何不足,并为该领域未来的改进提出具体方向。基于现实中知识错综复杂的特性,我们为下一代知识编辑确立了三大研究支柱,分别应对知识缠结表征中相互关联却又不可分割的三个维度(图1(c)):识别知识间缠结以实现彻底更新与推理能力;理解模型对知识的信念并借助推理进行编辑;迈向表达力强且情境化的知识编辑。图2概述了本文描绘的知识编辑图景。
在第2节,我们将全面介绍当前知识编辑方法的背景,包括LLMs作为隐式知识库的基础假设以及广泛采用的基于参数的编辑方法概览。在第3节,我们从知识存储机制的角度,探究编辑后知识冲突与泛化能力弱的成因。我们认为“前馈网络作为键值存储”的假设不足以理解知识的相互依存特性。如图2(a)所示,知识是互补且相互支撑的,而当前编辑方法却孤立处理事实,忽视了这些结构依赖。为构建鲁棒的知识编辑方法,我们提出 知识缠结假说,并引入一种新的知识编辑范式:识别和更新的不是孤立事实,而是其演绎缠结的知识邻域(如前提、结论、例外),从而尊重知识的系统性与相互依存性。
在第4节,鉴于知识与信念相互强化且动态演化,我们探讨了现代推理模型一个关键但尚未充分探索的特征:它们对知识持有自身信念,包括信心水平以及对存储于参数中的正确性的认知。这一特征为知识编辑带来了新挑战:模型对外部更新的抵抗与其对现有信念的信心相关。当模型持有强烈的先验信念时,它可能直接拒绝新的、即使是正确的知识(图2(b))。基于此洞见,我们提出 置信度引导的知识编辑,将模型的信念融入编辑过程,并对不同置信度的知识采用差异化策略。我们还提倡在编辑中结合模型的推理过程,为知识更新提供更多支持性证据,并使模型能够区分新旧知识。
在第5节,基于知识的语境依赖性与系统性特征,我们将知识编辑从原子三元组扩展到更具表达力、情境化的知识形式,包括事件、抽象概念与过程性知识(图2(c))。我们指出了编辑此类长文本、结构化知识的关键挑战,特别是精确定位的困难以及具体实例与其底层概念表征之间持续存在的差距。为此,我们提出一种简约而高效的数据集构建流程,旨在使模型能够高效内化新知识,最小化数据开销同时最大化泛化能力。
最后,在第6节,我们探讨知识编辑更广泛的应用前景。我们不仅将KE定位为一种用于持续、精准模型更新的实用工具,也视其为一种推理时干预的机制——实现在部署过程中实时行为引导与动态适应。重要的是,我们认为这些实用的编辑程序同时可以作为一个科学透镜:每一次编辑操作都是对模型内部“知识缠结网络”的一次探测性扰动;其成功或失败的路径恰恰揭示了知识如何存储、关联与推理,并为逆向工程及更好地理解LLMs的内部机制提供了宝贵信号。
我们希望这一综合框架能够推动未来在推理感知的知识编辑方面的研究,并助力开发能够在动态环境中持续学习的自适应AI系统。