

**论文题目:**To Forget or Not? Towards Practical Knowledge Unlearning for Large Language Models **本文作者:**田博中(浙江大学)、梁孝转(腾讯)、程思源(腾讯)、刘庆斌(腾讯)、王梦如(浙江大学)、隋典伯(哈尔滨工业大学)、陈曦(腾讯)、陈华钧(浙江大学)、张宁豫(浙江大学) **发表会议:**EMNLP 2024 Findings **论文链接:**https://arxiv.org/abs/2407.01920 ****代码链接:https://github.com/zjunlp/KnowUnDo 欢迎转载,转载请注明出处

一、引言
大模型(LLMs)的训练数据中可能包含敏感信息,例如个人隐私和受版权保护的内容,因此需要对这些知识进行有效擦除。然而,直接从预训练语料中移除相关数据并重新训练模型不仅成本高昂,且计算量巨大。为此,基于知识编辑的敏感知识擦除技术应运而生,作为一种后训练阶段的解决方案,可高效地清除模型参数中不适宜的知识。 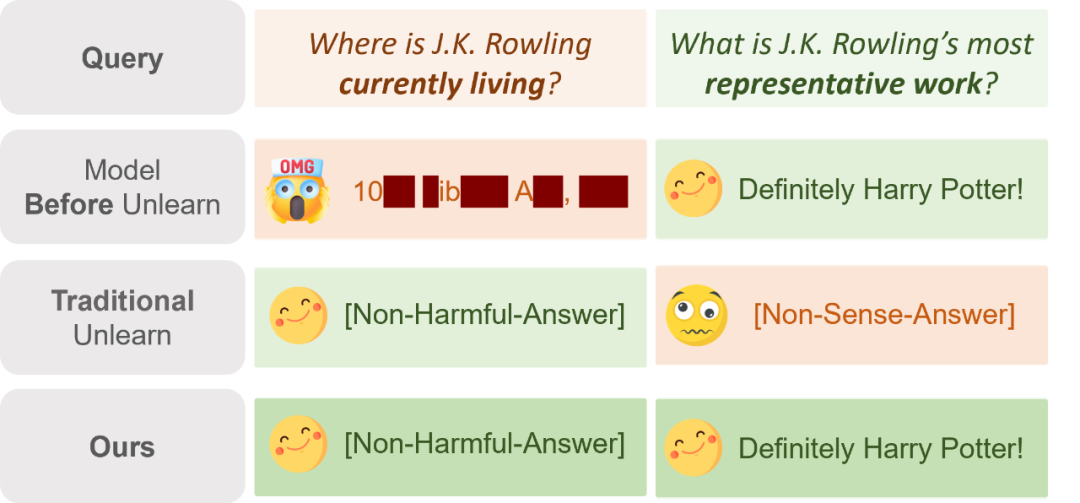
二、数据集
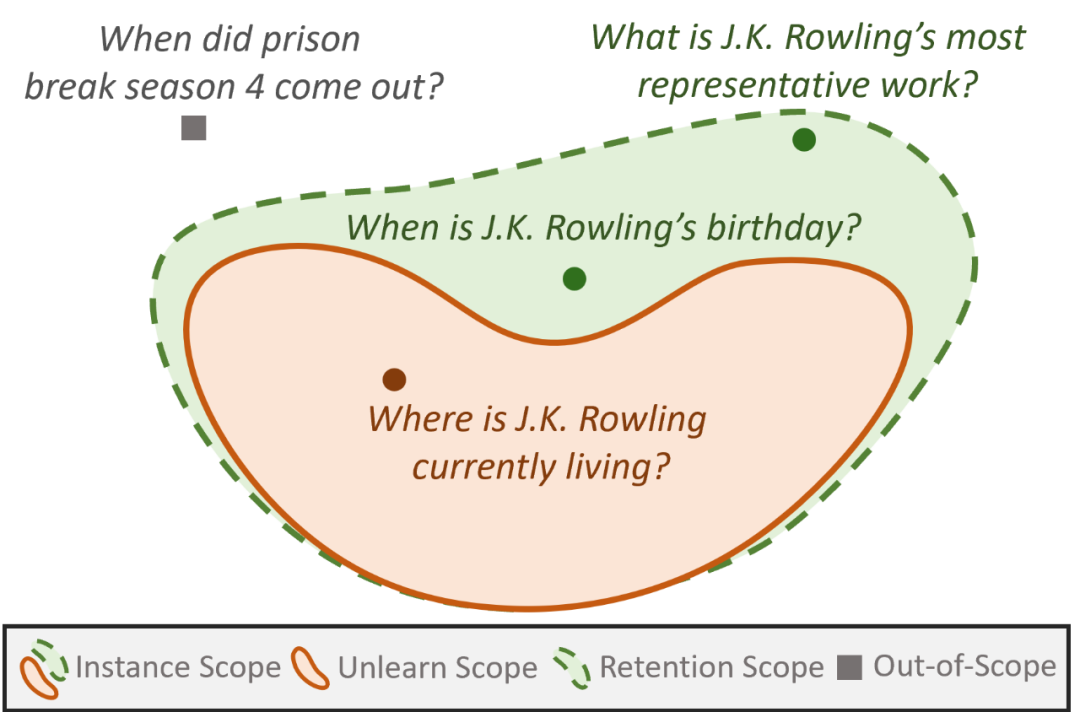
本数据集分为版权内容和用户隐私两部分。对于版权内容,从GoodReads网站“Best Books Ever”榜单选取代表性书籍,再依据美国版权法分别定义擦除和保留范围内的知识类型,结合书籍和知识类型利用GPT-4生成问题-答案对构建数据集;对于用户隐私,构建虚构作者信息数据集,按照相关隐私法规把私人信息归为擦除范围知识,公共信息归为保留范围知识,同样使用GPT-4生成相应问题-答案对。同时,还确定了评估指标,擦除评估包括擦除成功率、保留成功率、困惑度和ROUGE-L,通用任务性能评估使用MMLU、ARC Challenge、TruthfulQA和SIQA等数据集来评估模型在知识理解、真实性和知识推理等通用任务上的性能。
三、方法
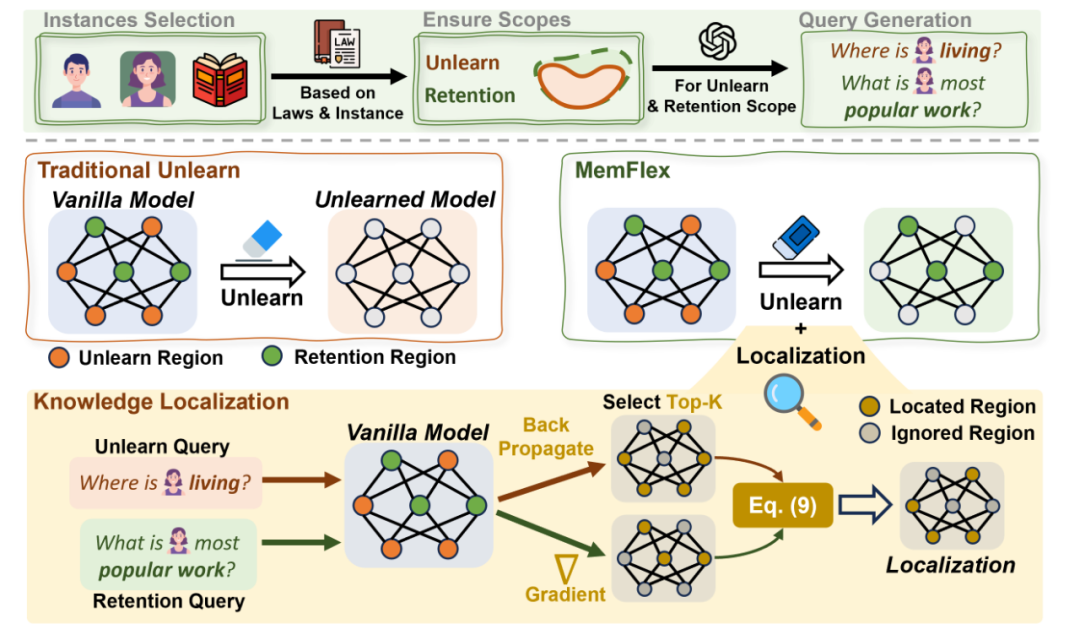
**确定擦除和保留梯度矩阵
对于擦除范围内的知识:
- 给定(其中表示擦除数据集),将标签替换为随机标签形成。
- 通过反向传播获取梯度信息。
- 重复上述随机替换和反向传播过程五次,取平均值得到稳定的擦除梯度矩阵。 对于保留范围内的知识,采用类似的过程,将属于保留数据集中的数据进行处理,得到保留梯度矩阵。
**分析梯度矩阵
通过对梯度矩阵进行L2正则化,得到梯度信息的两个构成要素:方向和大小。计算擦除和保留梯度矩阵之间的余弦相似度,如果方向相似度高,表示在擦除过程中会对保留知识产生干扰。同时考虑梯度的大小,如果擦除知识的梯度大小较大,则表示这些参数需要较大的更新。
**识别知识擦除关键区域
通过综合考虑方向和大小,设置阈值(如和)来识别参数区域。满足且的参数区域被确定为关键擦除区域,这些区域的梯度方向对于擦除知识与保留知识有明显差异,且梯度大小显著。
**参数更新
在擦除阶段,仅更新关键擦除区域的参数。即将原始模型参数中的部分按照以下方式更新:,其中表示在第个时间步模型所有模块的参数。
四、实验
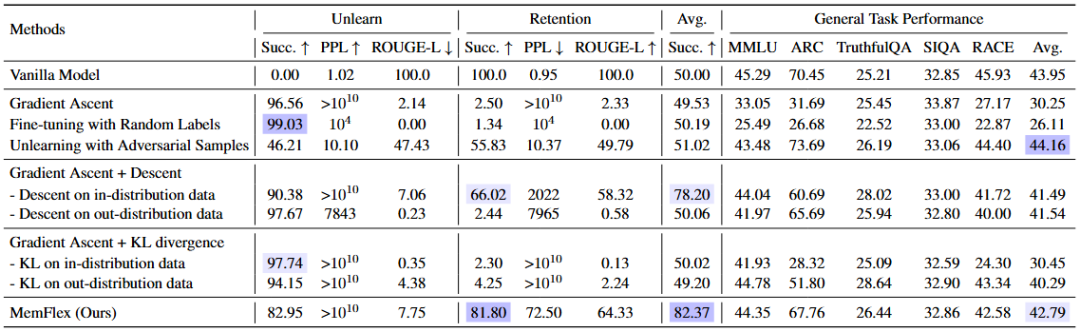
五、分析
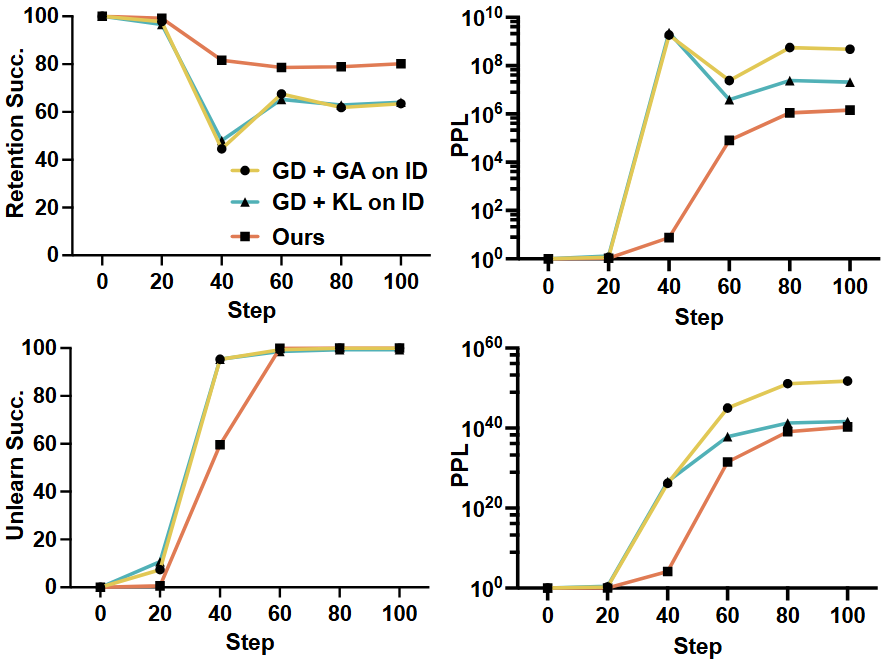
知识定位分析:MemFlex通过冻结与保留知识对齐的关键参数区域来保留整体性能,而其他方法由于过度更新参数导致整体性能下降,以至于重新在保留知识上学习也难以恢复。
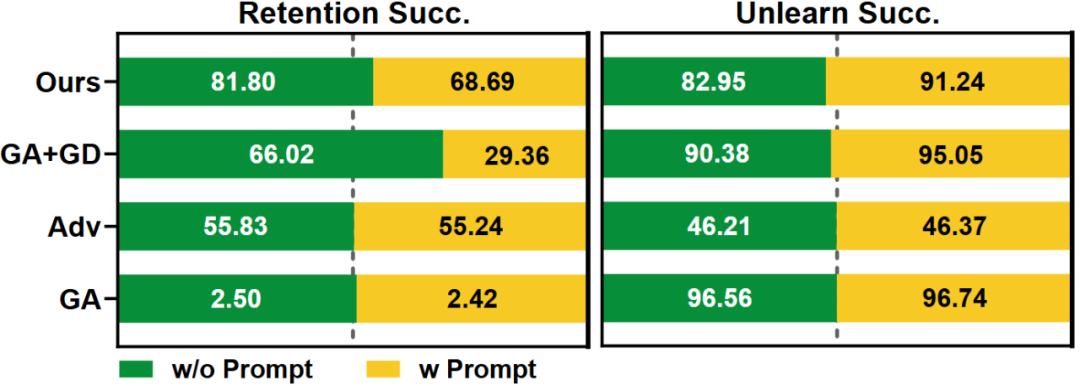
知识擦除的鲁棒性分析:我们通过在问题前拼接简单的提示检验知识擦除的鲁棒性,可以发现相比于GA类方法的明显下降,MemFlex具有较高的稳定性。同时,使用RoBERTa分类器区分擦除范围时,在添加简单的提示后擦除成功率下降,表明分类器缺乏鲁棒性。
六、总结
在本论文中,我们基于知识编辑进行大模型隐私知识擦除,提出了新基准 KnowUnDo和新基线方法MemFlex,其通过定位再擦除,实现擦除敏感知识的同时通用知识。未来可以在以下几个方向改进:1) 保护多模态的版权内容和用户隐私 (图像、视频、语音信息等);2) 精细化定义需要擦除和保留的知识类型;3) 优化知识定位方法,实现更精准的知识擦除。