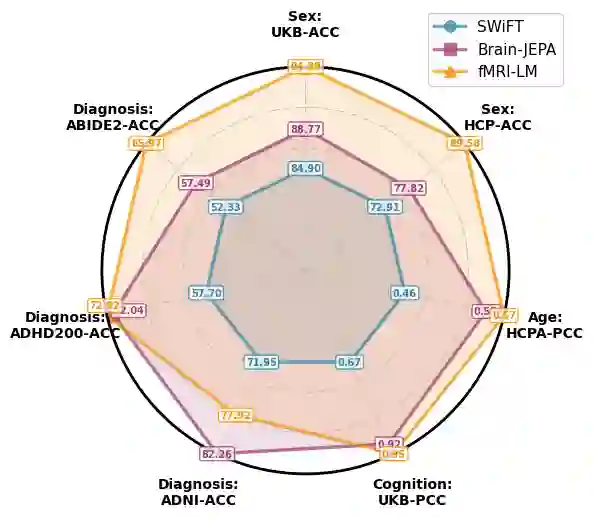
Recent advances in multimodal large language models (LLMs) have enabled unified reasoning across images, audio, and video, but extending such capability to brain imaging remains largely unexplored. Bridging this gap is essential to link neural activity with semantic cognition and to develop cross-modal brain representations. To this end, we present fMRI-LM, a foundational model that bridges functional MRI (fMRI) and language through a three-stage framework. In Stage 1, we learn a neural tokenizer that maps fMRI into discrete tokens embedded in a language-consistent space. In Stage 2, a pretrained LLM is adapted to jointly model fMRI tokens and text, treating brain activity as a sequence that can be temporally predicted and linguistically described. To overcome the lack of natural fMRI-text pairs, we construct a large descriptive corpus that translates diverse imaging-based features into structured textual descriptors, capturing the low-level organization of fMRI signals. In Stage 3, we perform multi-task, multi-paradigm instruction tuning to endow fMRI-LM with high-level semantic understanding, supporting diverse downstream applications. Across various benchmarks, fMRI-LM achieves strong zero-shot and few-shot performance, and adapts efficiently with parameter-efficient tuning (LoRA), establishing a scalable pathway toward a language-aligned, universal model for structural and semantic understanding of fMRI.
翻译:近年来,多模态大语言模型(LLM)的发展已实现图像、音频和视频的统一推理,但将此类能力扩展至脑成像领域仍基本处于空白。弥合这一差距对于连接神经活动与语义认知、发展跨模态脑表征至关重要。为此,我们提出fMRI-LM,这是一个通过三阶段框架连接功能磁共振成像(fMRI)与语言的基础模型。在第一阶段,我们学习一个神经标记器,将fMRI映射至语言一致空间中的离散标记。在第二阶段,我们调整预训练的LLM以联合建模fMRI标记与文本,将脑活动视为可进行时序预测和语言描述的序列。为克服自然fMRI-文本配对数据的缺乏,我们构建了一个大型描述性语料库,将多样化的基于成像的特征转化为结构化文本描述符,从而捕捉fMRI信号的低层组织。在第三阶段,我们执行多任务、多范式的指令微调,赋予fMRI-LM高层语义理解能力,以支持多样化的下游应用。在多个基准测试中,fMRI-LM展现出强大的零样本和少样本性能,并能通过参数高效微调(LoRA)高效适配,为构建面向fMRI结构与语义理解的语言对齐通用模型,确立了一条可扩展的路径。