Tensorflow1.4 系列教程 03—— 利用 TensorFlow 1.4 的 Eager Execution 新特性构建和训练卷积神经网络 (CNN)
【导读】主题链路知识是我们专知的核心功能之一,为用户提供AI领域系统性的知识学习服务,一站式学习人工智能的知识,包含人工智能( 机器学习、自然语言处理、计算机视觉等)、大数据、编程语言、系统架构。使用请访问专知 进行主题搜索查看 - 桌面电脑访问http://www.zhuanzhi.ai, 手机端访问http://www.zhuanzhi.ai 或关注微信公众号后台回复" 专知"进入专知,搜索主题查看。随着TensorFlow 1.4 Eager Execution的出现,TensorFlow的使用出现了革命性的变化。专知为大家推出TensorFlow 1.4系列教程:
- 01:动态图机制Eager Execution
- 02:利用Eager Execution自定义操作和梯度(可在GPU上运行)
- 03 : 利用Eager Execution构建和训练卷积神经网络(CNN)
教程中的代码可以在专知的Github中找到:https://github.com/ZhuanZhiCode/TensorFlow-Eager-Execution-Examples
卷积神经网络简介
卷积神经网络(Convolutional Neural Network, CNN), 最早应用在图像处理领域。从最早的mnist手写体数字识别,到ImageNet大规模图像分类比赛,再到炙手可热的自动驾驶技术,CNN在其中都起到了举足轻重的作用。
最近CNN也被成功的应用到自然语言处理领域(Natural Language Processing),并取得了引人注目的成果。我将在本文中归纳什么是CNN,并以一个简单的文本分类的例子介绍怎样将CNN应用于NLP。CNN背后的直觉知识在计算机视觉的用例里更容易被理解,因此我就先从那里开始,然后慢慢过渡到自然语言处理。
什么是卷积运算
卷积神经网络与之前讲到的常规的神经网络非常相似:它们都是由神经元组成,神经元中有具有学习能力的权重和偏差。每个神经元都得到一些输入数据,进行内积运算后再进行激活函数运算。
那么有哪些地方变化了呢?卷积神经网络的结构基于一个假设,即输入数据是二维的图像,基于该假设,我们就向结构中添加了一些特有的性质。这些特有属性使得前向传播函数实现起来更高效,并且大幅度降低了网络中参数的数量。
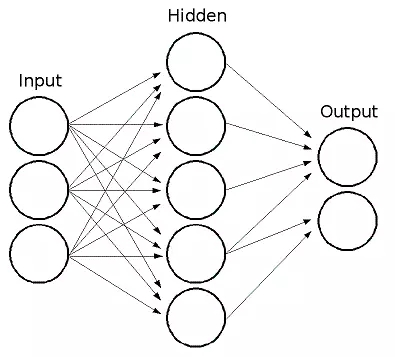
上图是常规的全连接网络,我们可以看到这里的输入层就是一维向量,后续的处理方式使用简单的全连接层就可以了。而卷积网络的输入要求是二维向量,这就需要向网络结构中加入一些新的特性来处理,也就是卷积操作
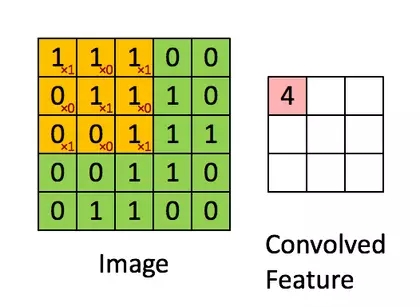
图中绿色为一个二值图像,每个值代表一个像素(0是黑,1是白)。(更典型的是像素值为0-255的灰阶图像)
图中黄色的滑动窗口叫卷积核、过滤器或者特征检测器,也是一个矩阵。
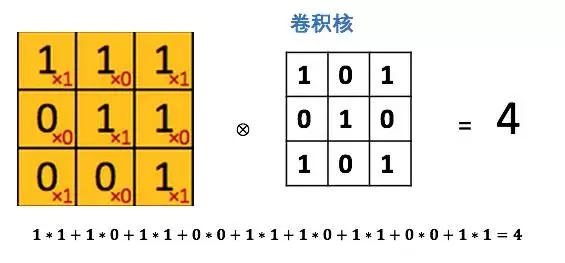
将这个大小是3x3的过滤器中的每个元素(红色小字)与图像中对应位置的值相乘,然后对它们求和,得到右边粉红色特征图矩阵的第一个元素值。
在整个图像矩阵上滑动这个过滤器来得到完整的卷积特征图如下:
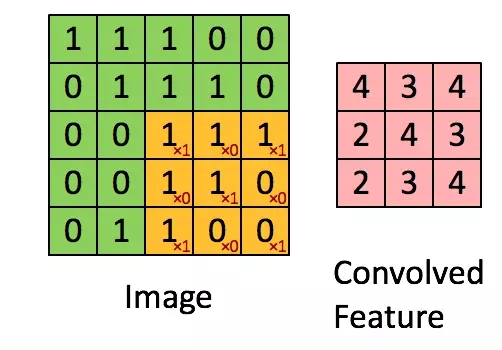
什么是卷积神经网络?
知道了卷积运算了吧。那CNN又是什么呢?CNN本质上就是多层卷积运算,外加对每层的输出用非线性激活函数做转换,比如用ReLU和tanh。
常规的神经网络把每个输入神经元与下一层的输出神经元相连接。这种方式也被称作是全连接层。
在CNN中我们不这样做,而是用输入层的卷积结果来计算输出,也就是上图中的(Convolved Feature)。
这相当于是局部连接,每块局部的输入区域与输出的一个神经元相连接。对每一层应用不同的滤波器,往往是如上图所示成百上千个,然后汇总它们的结果。
这里也涉及到池化层(降采样),我会在后文做解释。
在训练阶段,CNN基于你想完成的任务自动学习卷积核的权重值。
举个例子,在图像分类问题中,第一层CNN模型或许能学会从原始像素点检测到一些边缘线条,然后根据边缘线条在第二层检测出一些简单的形状,然后基于这些形状检测出更高级的特征,比如脸部轮廓等。最后一层是利用这些高级特征的一个分类器。
为什么要用卷积神经网络?
图像处理中,往往会将图像看成是一个或者多个二维向量,传统的神经网络采用全联接的方式,即输入层到隐藏层的神经元都是全部连接的,这样做将导致参数量巨大,使得网络训练耗时甚至难以训练,而CNN则通过局部链接、权值共享等方法避免这一困难。
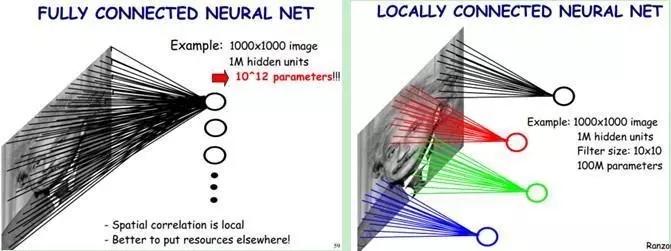
- 局部连接
对于一个1000 ×1000的输入图像而言,如果下一个隐藏层的神经元数目为10^6个,采用全连接则有1000× 1000 × 10^6 =10^12个权值参数,如此数目巨大的参数几乎难以训练;而采用局部连接,假如局部感受野是10x 10,隐藏层的每个神经元仅与图像中10 × 10的局部图像相连接,那么此时的权值参数数量为10 × 10 × 10^6 = 10^8,将直接减少4个数量级。
- 权值共享
隐含层每个神经元都连接10 * 10个图像区域,也就是说每一个神经元存在100个连接权值参数。如果我们每个神经元这100个参数相同呢?将这10×10个权值参数共享给剩下的神经元,也就是说隐藏层中10^6个神经元的权值参数相同,那么此时不管隐藏层神经元的数目是多少,需要训练的参数就是这10 × 10个权值参数(也就是卷积核(也称滤波器)的大小)
这大概就是CNN的一个神奇之处,尽管只有这么少的参数,依旧有出色的性能。但是,这样仅提取了图像的一种特征,如果要多提取出一些特征,可以增加多个卷积核,不同的卷积核能够得到图像的不同映射下的特征,称之为Feature Map。如果有100个卷积核,最终的权值参数也仅为100 × 100 =10^4个而已。另外,偏置参数也是共享的,同一种滤波器共享一个。
利用Eager Execution构建和训练卷积神经网络(CNN)
本教程将示范如何使用Eager Execution训练LeNet来分类MNIST数据集中的手写数字图片。
MNIST数据集
MNIST由手写数字图片组成,包含0-9十种数字,常被用作测试机器学习算法性能的基准数据集。MNIST包含了一个有60000张图片的训练集和一个有10000张图片的测试集。深度学习在MNIST上可以达到99.7%的准确率。TensorFlow中直接集成了MNIST数据集,无需自己单独下载。
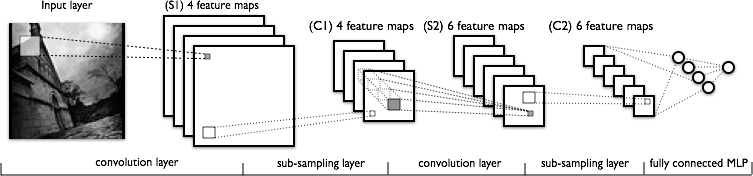
LeNet
LeNet是一种设计好拓扑的卷积神经网络,大致网络结构如下所示(图中一些具体参数,如卷积核数量,与LeNet有一些差别):
源码
#coding=utf-8
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
import tensorflow.contrib.eager as tfe
import numpy as np
tfe.enable_eager_execution()
# 使用TensorFlow自带的MNIST数据集,第一次会自动下载,会花费一定时间
mnist = input_data.read_data_sets("/data/mnist", one_hot=True)
flat_size = 3136
num_class = 10
dim_hidden = 1024
# 展示信息的间隔
verbose_interval = 100
# 定义各种层
layer_cnn0 = tf.layers.Conv2D(32, 5, activation = tf.nn.relu) # 卷积层0
layer_pool0 = tf.layers.MaxPooling2D(2, 2) # pooling层0
layer_cnn1 = tf.layers.Conv2D(64, 5, activation = tf.nn.relu) # 卷积层1
layer_pool1 = tf.layers.MaxPooling2D(2, 2) # pooling层1
layer_flatten = tf.layers.Flatten() # 将pooling层1的结果flatten
layer_fc0 = tf.layers.Dense(dim_hidden, activation = tf.nn.relu) # 全连接层0
layer_dropout = tf.layers.Dropout(0.75) # DropOut层
layer_fc1 = tf.layers.Dense(num_class, activation = None) # 全连接层1
def loss(step, x, y):
inputs = tf.constant(x, name = "inputs")
# 调用各种层进行前向传播
cnn0 = layer_cnn0(inputs)
pool0 = layer_pool0(cnn0)
cnn1 = layer_cnn1(pool0)
pool1 = layer_pool1(cnn1)
flatten = layer_flatten(pool1)
fc0 = layer_fc0(flatten)
dropout = layer_dropout(fc0)
logits = layer_fc1(dropout)
# 进行softmax,并使用cross entropy计算损失
loss = tf.nn.softmax_cross_entropy_with_logits(labels = y, logits = logits)
loss = tf.reduce_mean(loss)
# 每隔verbose_interval步显示一下损失和准确率
if step % verbose_interval == 0:
# 计算准确率
predict = tf.argmax(logits, 1).numpy()
target = np.argmax(y, 1)
accuracy = np.sum(predict == target)/len(target)
print("step {}:\tloss = {}\taccuracy = {}".format(step, loss.numpy(), accuracy))
return loss
optimizer = tf.train.AdamOptimizer(learning_rate = 1e-3)
batch_size = 128
# 训练1000步
for step in range(1000):
batch_data, batch_label = mnist.train.next_batch(batch_size)
# 原始batch_data的shape为[batch_size, 784],需要将其转换为[batch_size, height, weight, channel]
batch_data = batch_data.reshape([-1,28,28,1])
optimizer.minimize(lambda: loss(step, batch_data, batch_label))
运行结果:
step 0: loss = 2.302757740020752 accuracy = 0.1640625
step 100: loss = 0.17742319405078888 accuracy = 0.9609375
step 200: loss = 0.056245774030685425 accuracy = 0.9921875
step 300: loss = 0.11313237249851227 accuracy = 0.9609375
step 400: loss = 0.016188189387321472 accuracy = 1.0
step 500: loss = 0.026423435658216476 accuracy = 0.984375
step 600: loss = 0.08073948323726654 accuracy = 0.984375
step 700: loss = 0.0532052144408226 accuracy = 0.984375
step 800: loss = 0.06941711902618408 accuracy = 0.9765625
step 900: loss = 0.009956443682312965 accuracy = 0.9921875
对Tensorflow1.4教程感兴趣的同学,欢迎进入我们的专知Tensorflow主题群一起交流、学习、讨论,扫一扫如下群二维码即可进入(先加微信小助手weixinhao: Rancho_Fang,注明Tensorflow1.4)。

展开全文



