














更多相关文章阅读
持续反馈如何反作用于持续交付和持续集成?
作者简介:
梁定安
腾讯织云负责人,目前就职于腾讯社交网络运营部,开放运维联盟委员,腾讯云布道师,腾讯学院讲师,EXIN DevOps Master讲师,凤凰项目沙盘教练,复旦大学客座讲师。
导言
很高兴参与DevOps时代社区的拆书联盟第一季活动,有幸能与几位DevOps大牛一起解读《DevOps Handbook》一书,这本书作者牛,内容也很牛,就连著名的培训机构把这本书作为DevOps认证培训教材。
书中不仅方法论和实践丰富,而且所有案例都是取自于硅谷互联网企业的DevOps最佳实践,很值得我们研读。
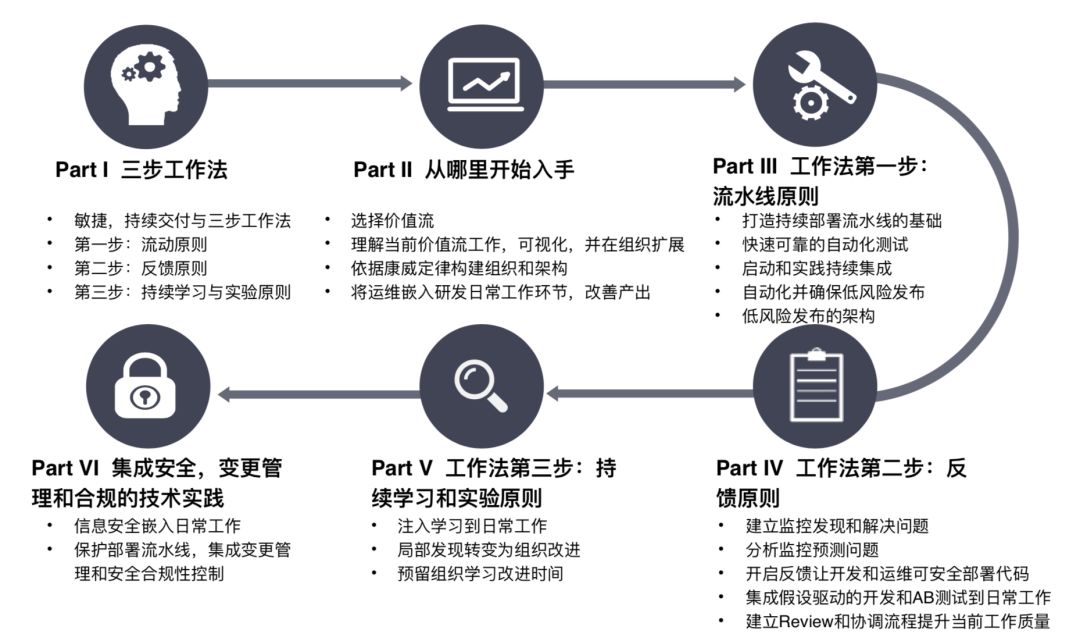
《DevOps Handbook》的拆书活动,共分成七部分,我负责的内容是“DevOps三步工作法”的第二部分:反馈实践。
《DevOps Handbook》把持续反馈的内容分成三部分:
第一是持续反馈的技术与案例,介绍在持续交付之后构建持续反馈体系的方法,主要是监控和告警能力的建设。
第二部分会介绍优秀的持续反馈如何反作用于持续交付和持续集成。
第三部分介绍实现持续反馈的非技术要素,包括组织、人员等软文化。
本文将介绍后续两部分内容
二、让发布更可靠&安全
2.1、部署pipeline中的监控
持续反馈的技术,聊一下怎么在Pipeline中部署监控,开展监控,在Pipeline中应该监控什么东西。
讲一个案例,Right Media是一个在线广告的公司,他们的广告库存是动态的,一旦有客户需求,他就马上要扩容,客户说我要投一个广告,要上线一个游戏,这个游戏会有很多人来玩,他就马上要扩容。
这时候遇到一个问题,运维人员部署很慢,开发人员甚至嘲笑运维人员,说你们连最本质的工作都做不好,你们为什么会害怕部署。
当他们CTO把这个职责放给开发团队的时候,开发团队发现部署自己的代码的时候一样部署不起来。
为什么,我们抛开架构问题时,其实还有一个很主要的问题,我们抛开部署难易度、部署配置管理的问题,还一个很重要的问题,在部署的每一个环节里其实是缺失了监控,他没办法知道我这个部署动作是正常还是异常。
所以Right Media后面做了一个很大胆的改革,他要求每一个步骤动作有由开发、测试、运维共同参与,这个其实也是DevOps提供的,甚至是开发都可以去部署。
通过这样的一些方法去把我们的代码质量提高,去完善我们的自动化测试,逐步去把一个很大的变更变成若干个很小的变更,变更量、变更代码越小,变更频繁增加,通过一个指标的监控,让整体的发布文化走向完善。
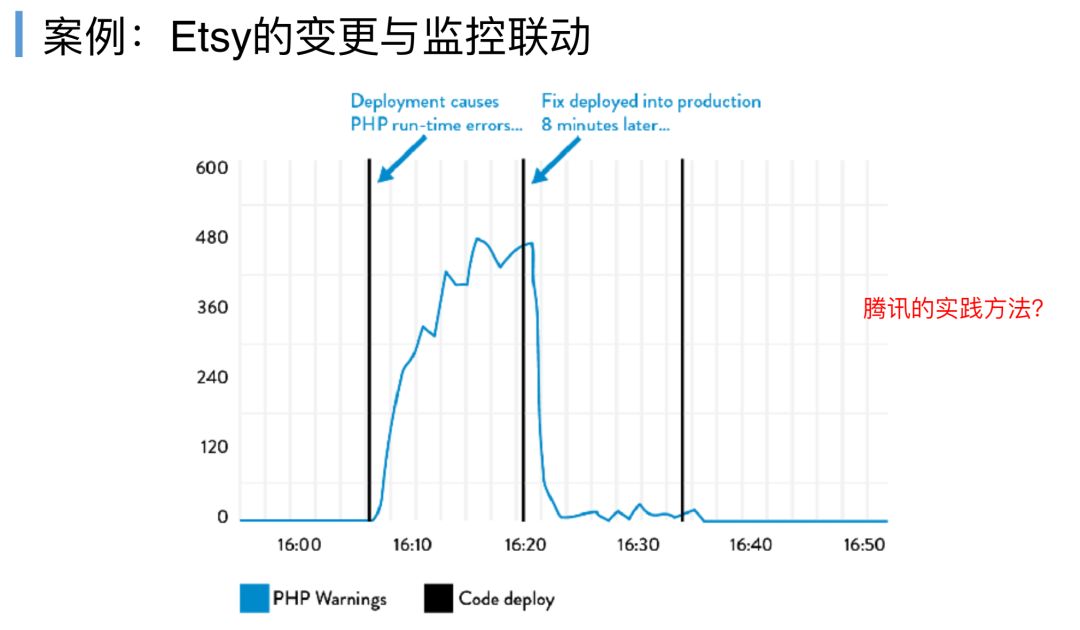
Etsy的案例,黑色线是部署PHP,部署完之后,16点过一点,在这个点部署部署完,PHP告警马上陡增,马上再发布一个东西,然后告警下降,修复了,用更频繁的部署,他每次部署就10分钟,更频繁的部署换来影响更小,我们可以做得更快更可控。
整个案例都没有强调说是谁的过错,关键是我们团队怎么样去针对这个过错去修改我们的流程,去共同进步。腾讯的实践方法也类似,通过CMDB把我们的变更跟我们的监控关联起来,然后我们对这个变更对象操作变更的时候,我们的CMDB会有一条变更记录,然后监控系统发现异常的时候,它就会马上直接告警告出来,说我有一个业务告警,这个业务告警发生时这个功能正在变更,请及时处理,让告警更精准,推送到具体的人,实现了MTTI最短的时间,而不是我们收到一个告警还要去分析究竟是什么问题引起的。
要落后这样的发布文化,没办法回避一点,必须要推进我们的非功能规范,无论是我们的监控指标、覆盖度,这些跟业务逻辑无关,你的日志要输出什么能够,你的部署是不是支持独立部署的,是不是具备独立发布的,是不是高可用的等等,都是非功能规范。
在书中给了几个实践的方法,大家可以讨论一下在中国是不是可以推行得起来,因为这些全是硅谷的做法。
要求开发和运维都是要oncall,轮流值班,今天是你值班,你可能是开发,你值班你来发布或者说发布的告警全部跑到你这,他就有主观能动性,你要降低你的oncall成本,就必须去优化你的代码。
还提到了一点,让开发在下游工作,下游就是让开发来干运维的活,让开发自己维护自己的产品。
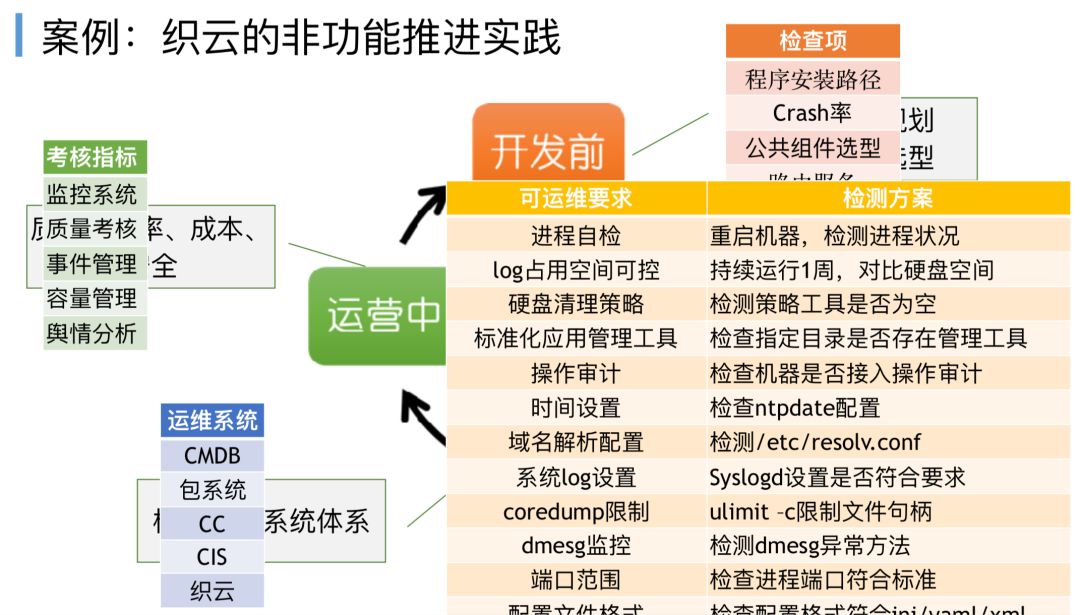
这里我特别想跟大家分享一个腾讯织云实践的案例,腾讯SNG运营部在2008、2009年推行织云标准化,要求所有的开发上线的时候都必须遵循运维的一些非功能的规范,当时运维团队提出了软件包必须要遵循一个包规范,一旦运维发现有开发没有按照这个包规范去发布它的应用程序,当时真实的情况是让开发同学发现这个问题,把不按照规范操作的那个开发人员抓到运维团队去做两周真实工作,这个是真实的案例,这个案例跟谷歌的SRE的实践,不谋而合。
非功能规范,织云也有一些实践案例,运维对应用程序的整个生命周期分成四个阶段,在不同阶段做不同事情,要把非功能规范落实到地,例如运维在开发前会提出的日志标准化格式要求,如JAVA程序、C程序、PHP程序,对应的目录结构、日志存放等。
去规范企业内的web服务,尽量集中统一用Nginx。
在服务投产上线前会验收,在测试或者持续集成、持续交付的过程中,用织云的运维体系去支持运维的标准化落地,并在运营中持续度量。
甚至运维会联合质量管理的QA同学,对研发质量定义出不同纬度的非功能考核的项目,让大家更好的去执行运维标准化的要求,保障每个新应用上线都能有很好的运维支持保障。
投产评审内容,书中提出了一些可供参考的点,如在做发布时应该遵守什么东西,在持续交付的过程中,代码缺陷数量和严重程度到达一定的值,其实这个发布是不允许去投产的。
例如在测试过程中或在压测过程中,应用的告警是没办法处理的、没办法看得懂的,不给投产等等,如图内容。
这是发布过程中我们必须遵循的技术上的一些考量的点,一些关键的因素。
除此之外,站在业务的角度,技术团队还需要去考量一些内容,还需要去关注这个交付、这个部署、这个变更动作会不会影响业务的收入,会不会影响业务的用户量,如果会的话,请在指标上体现这个变更的影响。
这个变更会不会有一些高危的风险,会不会有一些监管的风险,像很多金融同行,变更操作必须要符合银监会、证监会、保监会的一些要求等等这些东西。
为什么提这种评审的内容,因为DevOps很强调的一个观点,欢迎有存在价值的流程,而不欢迎那些官僚的流程,不欢迎那些为了刷存在感而存在的流程。
例如在做发布时,是开发团队和运维团队的事情,但是审批流程需要走到另一个无关紧要的团队来授权,这个无关紧要的团队可能对项目的细节一无所知,这其实就是为了审批而审批,这种流程在DevOps里面,如果用老外的观点,是要严格删除的,这是妨碍组织进步、技术发展的,是业务日益增长的部署效率的需求和落后的审批效率之间的矛盾。
2.2、谷歌SRE的运维实践
让发布变得更可靠,Google的案例可以跟大家探讨一下。
去年有一本书很火,Google SRE那本书,同样《DevOps Handbook》也是拿Google SRE的案例来举例的。
可以这么说,如果按照谷歌对他们应用程序投产的质量要求,可能一个你不要求技能很强的人都能把这个工作做得挺好,因为他的技术文化也好,保障体系也好,其实做了很多这种要求。
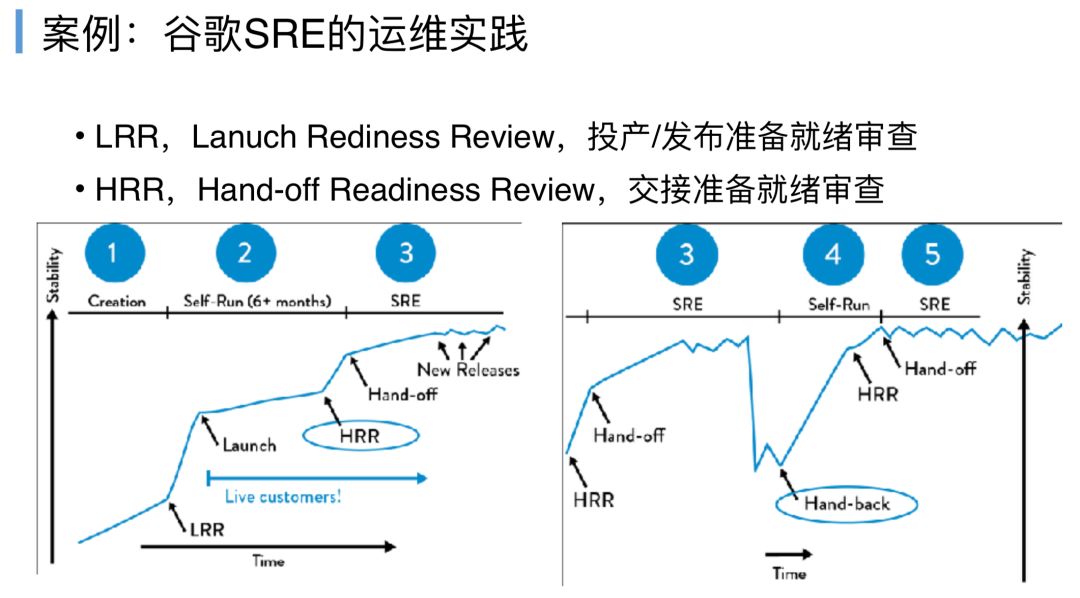
当然谷歌肯定是招了很优秀的人,但是如果单是从保障这个服务的可靠性来看,不需要很强的技能,都可以把这个服务运维得很好,因为谷歌提出了两个在应用程序或者在产品投产之前的很重要的环节,LRR和HRR,LRR是投产/发布准备就绪审查。
审查什么,谷歌SRE团队会给一个检查清单,里面列出了这个程序要投产,必须得符合,书中没有具体描述要符合怎么样的东西,只给了一些举例,假设你一定要高可用,不能写本地硬盘,一定要有状态等等,就是前面所说的非功能规范的要求,跟业务逻辑无关的,但是必须要求开发提前做好。
LRR做不好是没办法走到HRR的,LRR其实是一个投产前供开发、测试和产品团队去自检的流程,是一个软的流程。
当走完LRR节可以走到发布投产的环节,发布投产的环节就要走HRR,HRR是什么,用国内的话就是开发把这个服务交接给运维,交接的过程SRE就要来评审,开发是不是符合运维规定的非功能规范,全部做到了,可以进行Hand-off交接,就是开发放手交给运维。
然后运维接管维护职责,走到第三个阶段,运维的一段过程中,开发对这个程序有变更,有新的发布,一旦运维发现开发的发布又不符合HRR的要求,这时候运维有权这个应用程序交回给开发,就是一个Hand-back的过程,以这样来制约DevOps经常提的开发要自己吃自己的狗粮,既然你开发的东西难运维、不可运维,那你就自己去运维。
这时候开发又要去自己维护,Self-Run,他觉得改进足够了,他又走一次LRR的环节,然后再Hand-off给运维,整个文化在谷歌就是一个很强的文化,你可以认为SRE在谷歌是一个很强势的团队,整个谷歌有超过一百万台物理服务器,他们的SRE团队只有1200人,这是2013年的数据。
这是一个DevOps文化的趋势,也很符合让开发自己维护开发的代码,开发在下游工作,你自己体会一下运维的痛苦,如果开发可以通过改一下代码就解决的事情,那千万不要把这个包袱丢给运维。
在腾讯的运维实践也做得有点类似,但是终究还是没有像SRE这么强势,所有不标准的发布定夺大部分还是会按产品优先的原则,但是会要求开发在后续工作中修改到标准,是通过考核保障的。
三、提升质量的更多方法
3.1、假设驱动开发与A/B测试
怎么样基于监控告警的能力进一步提升业务的质量。
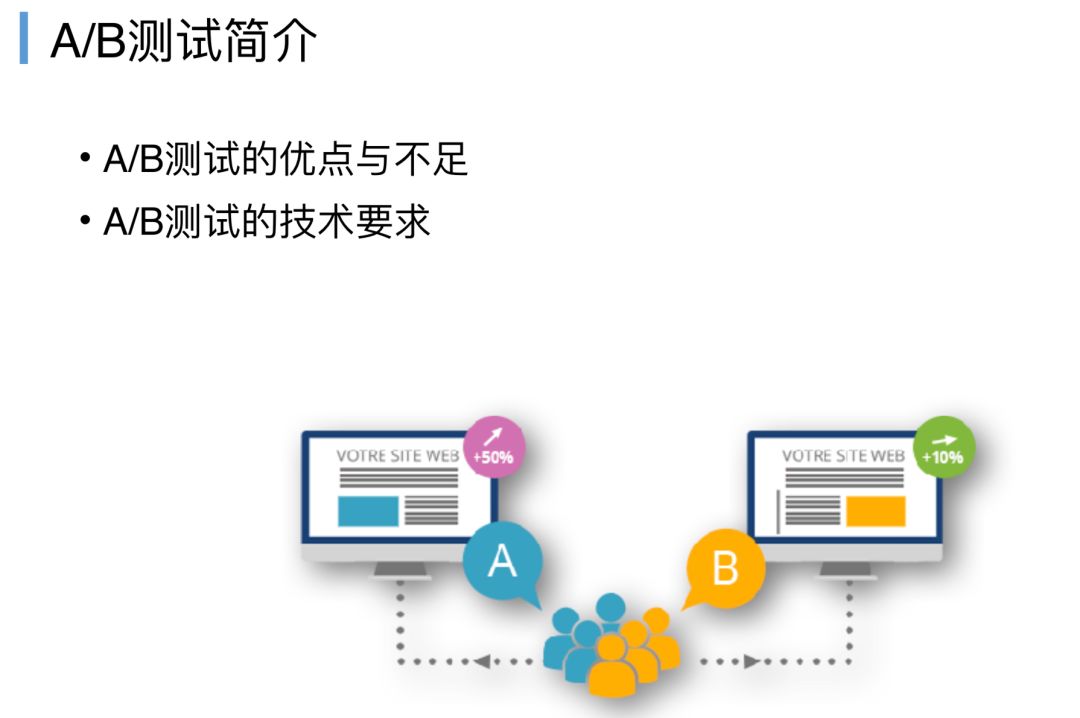
这里提到一个假设驱动开发的方法,要把监控能力运用在A/B测试这里,这里也有一个案例,Intuit公司,北美的一个专门做中小型企业财务管理方案的公司,这个公司闷声发大财,2012年利润就有45亿美元,整个公司有8500人。
公司CEO和管理团队都很提倡一个文化,他们从来不相信老板和产品经理拍脑袋想出来的产品需求,而是在工程实践、产品实践里和提倡一个文化就是要做A/B测试,Intuit会以最小的产品(MVP)的颗粒度给到他们的用户或者一些重点客户,然后用户来告诉产品经理哪个功能是最想要的,让产品保持迭代,从而去赢得市场,这也是Intuit能够成为这个领域的独角兽的核心能力之一。
A/B测试很早前就有了,电子邮件时代就有一些媒体会发这样的传单给用户,用户来选这个传单里面的这个产品是我需要的,从而来论证这个产品是ok的,那个产品是不ok的,做这样一个A/B测试。
A/B测试有一个好处,就像这个图举例,我们对我们的用户群体来做一些样本测试,就像上面这个图,我们是左边放图片还是右边放图片,左边放图片,业务的指标提升了50%,右边放图片只提升了10%,很明显要用左边这个方案。
A/B测试今天我们不展开讲,A/B测试同样是依赖于一些技术的要求,业务架构必须满足一些能力,我们才可以开展A/B测试和指标监控,首先我们要能够把我们的用户分群,这一批用户能访问我A服务,这一批用户能访问B服务,这是最基本的,这个其实对业务架构会有一定要求的,这里不展开。
《DevOps Handbook》里为什么提到假设驱动开发,因为他认为传统的开发方法,如瀑布流开发,往往需要一年或者极端情况的几年,才完成一个产品的开发。
这个产品无论产品质量和体验做得再好,如果不是用户要的,其实这一段时间是浪费的。
这是精益和敏捷的思想,如果产品要做十个零部件,那精益思想希望每个零部件都能独立出来,结合敏捷方法快速实现交付给用户看一下。
devops方法提出在做特性监控的时候,能不能有A/B测试的方案,让产品直接交付给用户。
在发布版本的时候要用灰度发布的方案,加入遇到用户不买单的情况,那就直接别发布了,停止灰度并全部回滚。
换成另一个方案,在特性计划的时候,产品经理规划一个新特性,一定要考虑A/B测试的因素在,这个其实是一个市场营销、用户体验、用户设计等范畴。《DevOps Handbook》推荐了一本《精益创业》,如果大家有负责产品规划,推荐要看一下这本书,讲到了很多方法论,做toc产品怎么做,做tob产品怎么做。
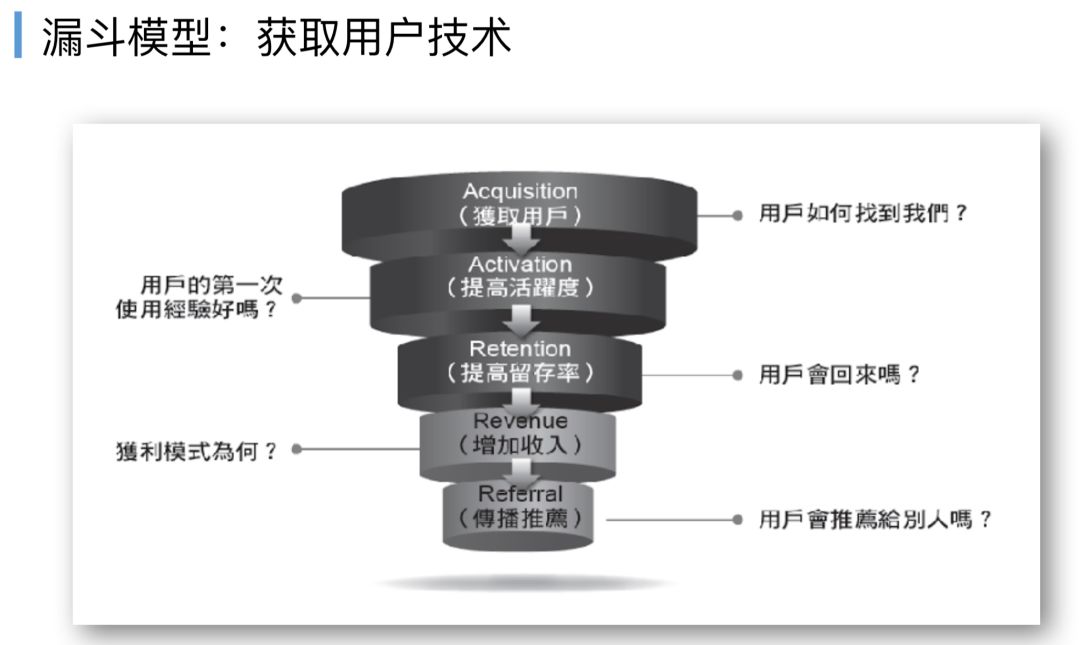
假设驱动开发还有一种做法,这种做法也是业界很通用的叫做漏斗模型,有些地方也叫漏斗获取用户模型的方法,最核心的是怎么样通过用户测试的方法去一层一层看到用户是如何使用产品功能进来的,每跳转一次用户流失了多少,最终注册和付费。
之前有个笑话,你看一个网站怎么样去做用户注册的过程,如果你注册一个账号需要五步,那你可能每跳转一步就流失20%的用户,到最后一步可能你的流失率是95%,太多了。
但是你看看色情网站是怎么注册的,可能一步就行了。
这虽然只是一个玩笑,但如果监控能力能够覆盖这一部分的需求,这个其实就实现了DevOps所提倡的,所有IT团队的工作都是为了实现业务价值,获取用户,这是一种实现业务价值的方法,在定义监控能力的时候也可以去考虑一下,是不是可以帮助到公司的产品人员,帮助公司的市场营销人员,去更好的识别用户的留存率。
3.2、优化部署流程中的评审与协调
第三部分最后一个环节,提升质量的方法还是要去不断优化部署流程中评审的过程、协调的过程。
书中给了一个方法,这个方法就是GitHub公司真实的案例。GitHub公司对外的产品是GitHub,内部也是严格践行DevOps,其实GitHub很多特性都是他们实践出来的。
他们怎么实践出来的,讲一个笑话,GitHub的CIO提过一个笑话,如果我们在提交代码的时候,这个代码的变动只有十行,我们要求另一个程序员给我们做代码审核,十行的代码很有可能给你提出十个问题,但是如果你提交一个变更,这个变更改动了五六百行代码,你还是找回他,同一个同行的程序员给你做代码的交叉审核,他会跟你说,你的代码写得不错,找不到一个问题。
这个其实反映了一个问题,我们需要保证我们每次变动它的变化都是最小的,怎么样可以做到最小,其实就是持续交付的一些原则,你必须每天都得提交一次你的代码,或者你一天提交几次,确保你的代码变动量是最小的,这样你才可以去做交叉审查,去做测试驱动开发等等。
GitHub公司自己实践出来的,这个特性也在很多GitLab、GitHub都有这种形式,GitHub flow,标准代码提交的过程,应该是什么样子的,首先它是定期的,提交这个代码分支一定要有版本的说明,当他提交完之后会有一个拉请求,去做自动化的编译、测试等等。
合到主干分支的时候会有相应的必须的审批流程,审批完之后,合到主干就马上会部署,部署到准生产环境也好,部署到测试环境也好,测试就去测,冒烟测试、集成测试、系统测试,甚至是UI测试,来确保这个代码是ok的,功能提醒是ok的。
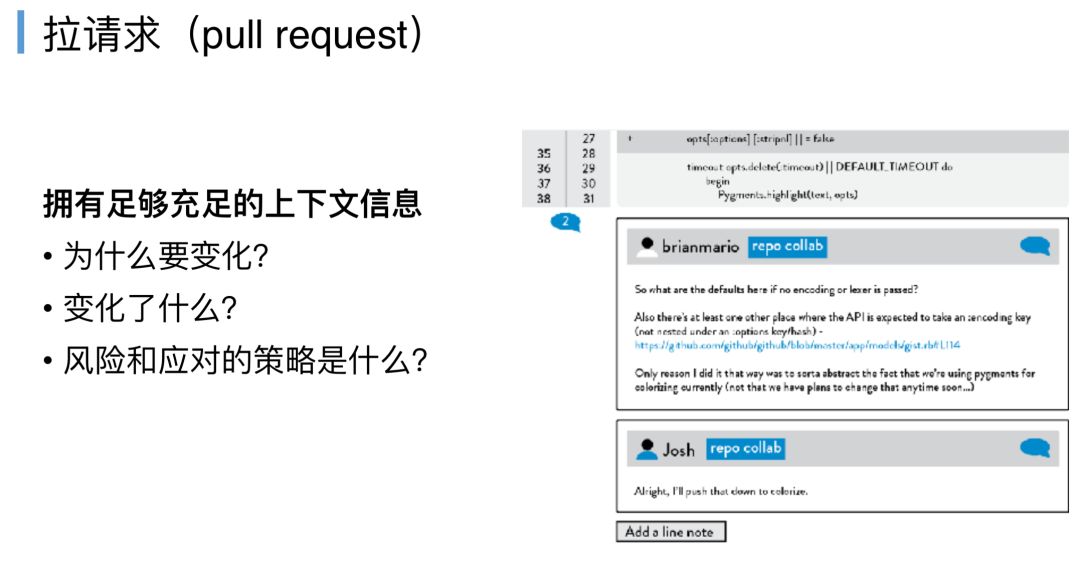
这里提到一点,拉请求(pull request),如果大家有用GitHub的经验或者有用Jenkins的经验,pull request大家都应该知道,这个在我们讲DevOps精益文化时,我们提到要怎么样减少浪费,里面提到很重要一点,代码搬运的过程是一个浪费的过程,如果我们不是拉的一个请求,是一个推的请求。
假设大梁写完代码了,我给小明提一个需求,我去告诉他说你什么时候有时间去帮我测一下代码,或者我的代码要构建了,这个会有等待的时间,我的代码写出来一直不被人家集成、测试、编译、交叉检查,这时候提出拉请求,很重要一点特征,如果是在GitHub的实现形式,它就是用webhook那种方法,当我的代码上去,这个分支自动就会调用一些自动化的工具。
如果是最常见的Jenkins,Pipeline设计好的话,它马上就会去编译或者马上就会调测试工具去测,去降低等待时间,这其实就是pull request。
我们先不讨论拉请求怎么样去自动化,《DevOps Handbook》提出了并不是所有的pull request都是pull request,他认为一定要拥有足够充足的上下文信息,它才算是一个pull request,就像右边的这个截图,你必须要写清楚你为什么要变化,你是为了做这样的一个新特性还是为了修复一个bug,还是纯粹为了代码更优雅,变化了什么,改动了哪里,你为什么这样改动,改动完之后有可能影响什么服务,是不是有收入的服务会被影响,你的风险,部署完能不能回滚,怎么回滚,等等,这样才是一个良好的pull request所携带的信息。
这里讲到一个案例,骑士资本,一家做VC业务的投资公司。当年他们有一个很经典的发布,因为一个发布的失败,影响了15分钟,导致他们15分钟交易损失了4.4亿美金。
在此之间运维团队在服务部可用的时候是蒙圈的,因为运维没办法回滚,没办法将这个影响降到最低,这个就是因为在运维做变更时,开发人员没把风险说好。
这个问题可以有两个角度的看法:
第一,怎么样能够更好的去监测到风险与故障,这个是上述刚刚花了很大的篇幅讨论的。
第二,能不能在发布过程中,无论是用灰度还是用审批还是用信息共享等等这种方法,让大团队发现这个问题,然后让这个问题不要出现。
书中还给了一个最简单直接的方法,当运维发布的时候,面对如此重要的一个影响交易的发布,应该有一个聊天群或微信群,周知和共享信息,让所有相关的团队都可以standby的去应对可能遇到的问题,或者开发跟大家说一下有什么样的风险,让大家提一下建议,他认为这种流程是很有必要的。
这本书提到的一些变更控制的环节,要慎防过度的控制,对变更的控制一定是要把钱都花在刀刃上,怎么样算刀刃上的一些控制呢?这里举了一些方法,书中认为所有对代码质量的控制都是过度的控制,它认为开发人员完成代码开发并提交给测试,测试发现代码质量不高,打回来,然后开发人员再开发。
这样一个反复的动作其实都应该在编码环节去解决。
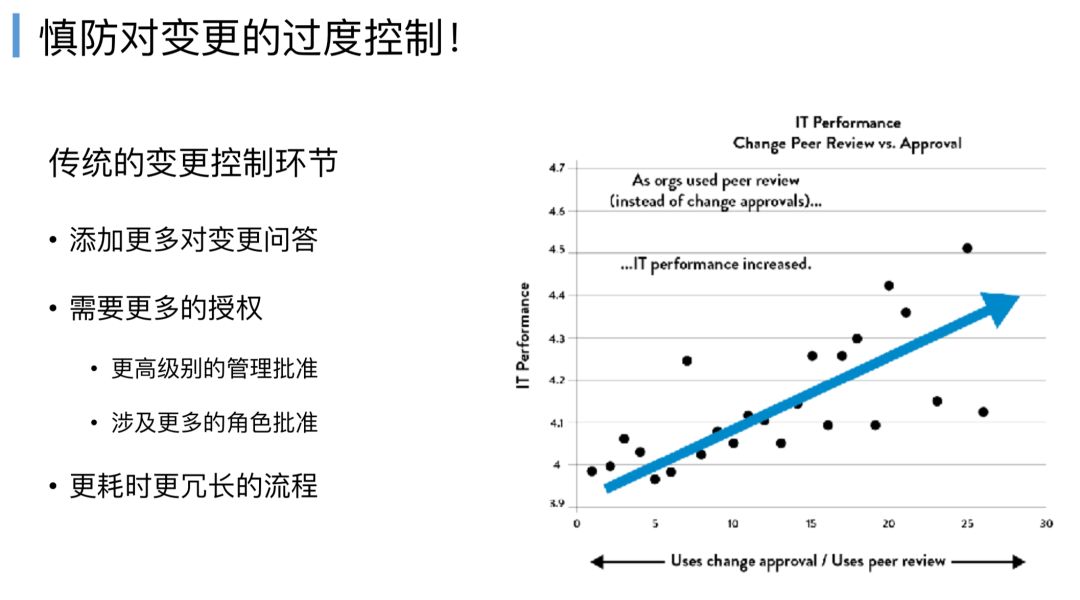
参考右边这个图,下面横轴X轴,往左边看是一些审批流程,往右边看是同行开发,代码的质量可以通过一些结对编程的方法,或者说自己研发团队可以解决的一个问题,不应该放在测试环节去解决。
这是一个谷歌的案例,这个案例有一条蓝线,往左边的黑点代表审批环节,往右边的黑点代表同行交叉检查环节,越采用交叉检查的代码质量越高,IT的效能越高,这远比走一个僵化的审批流程来得要快,况且很多审批流程,其实又是康威定律作用的,组织架构决定软件架构,既然设立了这样的一个组织,它就必然要去发挥它的价值(刷存在感),就一定要去审批,因为该组织存在就是为了审批的东西。
我和很多DevOps同行都有交流,大家往往都会纠结一个问题,究竟企业要实施DevOps,是不是应该推动一些组织结构的变化,这个答案毋庸置疑都是“是的”,但是组织不变同样也能实施,只是实施的没有这么优雅。
看了好多北美企业的DevOps实践,他们更容易接纳这种文化,可能国内有很多传统的企业,没办法一蹴而就的接受这种变化,这也是国内DevOps社区想做的,怎么样致力推进DevOps在中国的落地,找到对口中国企业的devops方法很有意义和价值。
怎么样去改进外部审批流程,书中给出了结对编程,下面有两个图,结对编程不是配对编程,不是一男一女的编程,往往是两个男人的编程。
书中对结对编程提出了几种不同的方法,有不同的模式,有驾驶员、领航员的模式,驾驶员是主要的写代码的人,领航员负责检查他的代码,但是有一个原则,不要驾驶员写了几千行上万行再给这个领航员去看,而是你每变动一点都要给他去看,这样不仅仅可以促进代码文化标准化的落地,还可以彼此的,相当于也是技能培训。
另外领航员也可以旁观者清,他可以更好的根据我们未来规划业务架构所需要的一些技术的方案,他可以给到写代码的人更多的建议。
还有Over-the-shoulder这种编程,一个人在写,后面一个人在看,这样你也不能写写代码聊聊微信了,不知道具体欧美怎么执行的。
还有一种跟pull request类似,利用一些工具,GitHub等这样一些工具,提交完代码,他就会把变量的那部分带上你的备注,发给邮件审批人,审批过了再去做。可以通过这个过程的度量,去把它做到足够轻量化。
还有一些做法,结合我们的检查工具,例如代码提交,提交到代码库之后,分支之后,会有一些代码静态扫描工具去扫描一下,有控制空函数,也没有野指针,注释量是多少,你有没有引用高维函数等等,都可以把我们研发的流程或者研发质量的一些要求变成一些工具,给他去扫。
当然,这里能覆盖一点,但是不能解决所有的问题。还有一些是加强型的TDD,驾驶员写代码,领航员写测试用例,你们同时写,我先写完测试用例,你一提交,马上调用测试用例来测。谷歌在很多场合很多技术分享的时候都表明自己的工程师文化是严格执行TDD的。
结对编程文化有很多好处,也有很多规则,他要求大家一定要提交到主干之前都要交叉检查,你的代码环境有没有什么依赖变化,有没有一些冲突等,一定要定义清楚你是不是有高风险的,如果你认为你这个代码有安全问题,其实是应该有安全专家评审过的。
他认为这些在代码阶段所有的问题都是必要的一个流程,我们要结合工具去简化这类流程,但是代码生产出来,所有的风险不要让它遗留在测试阶段,不要让它遗留在投产阶段和运营阶段,必须把影响最小化的扼杀在萌芽阶段。
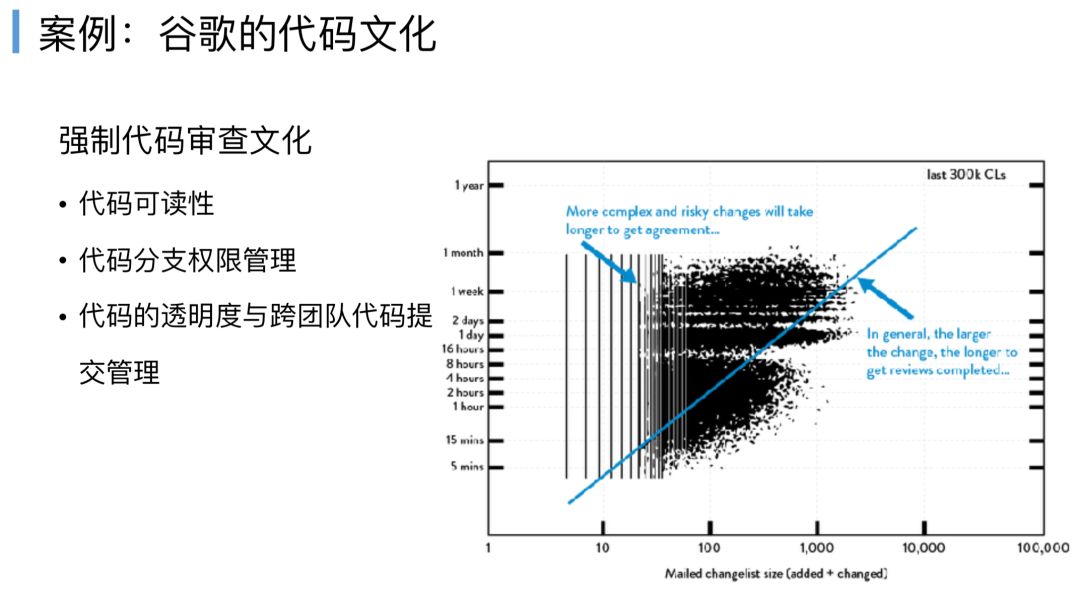
这里有谷歌的案例,X轴表示代码变化的大小,Y轴是评审的耗时,如果我们每次变更就是十行,可能一个人5分钟就可以评审完,如果变更一万行,他需要一个月甚至是几个月,强调了几点。
第一,你每次变更要足够小,频繁去提交你的代码,频繁让别人去看,然后你的代码可读性一定要强,这个自然而然会形成我们团队或者整个企业代码的文化,然后我们的分支管理权限必须要针对这种代码的文化去设计,还有代码的透明度,跨团队的代码管理能力。
我印象最深的是当年去硅谷跟他们交流很深的一个印象,当年那个同学他也是在国内工作了一段时间,然后技术移民去了美国,在硅谷工作,我去那边跟他聊,国内外企业的文化差异是什么,他提到一点,你在硅谷入职,你拿到的电脑里面,你打开谷歌的chrome浏览器,里面就已经给你收藏了所有谷歌业务指标的信息,包括业务的关键数据,谷歌认为每个员工都是善良的,既然你成为谷歌团队的一员,你有必要去了解整个公司业务的发展。
这个其实挺震撼的,在国内大部分公司相信还做不到这一点,很多老板都担心业务指标被无关的人看到会有机密泄漏或影响估值等风险。挺多这种中西文化的差异,但是我们还是要朝先进的互联网企业去学习。
书中很严肃的提到一点,除了所有有必要的流程,DevOps团队成员应该勇敢的站出来,勇敢的剔除官僚的流程。
我也号召大家勇敢的站出来,去给你老板汇报下,对现行不好的流程提出优化方法,运维对生产故障的总结思考能不能够通过代码的阶段去解决,而不是说默默的背了这个锅,这是DevOps不提倡的。
最后欢迎大家后续继续关注DevOps时代社区的拆书活动,一起探讨DevOps落地中国的最佳实践方法。
登录查看更多
相关内容

Arxiv
36+阅读 · 2020年5月24日
Arxiv
7+阅读 · 2018年5月21日




相关VIP内容
相关资讯