大数据平台如何进行云原生改造

如今,企业都面临着日益增长的数据量、各种类型数据的实时化和智能化处理的需求。此时,云原生大数据平台的高弹性扩展、多租户资源管理、海量存储、异构数据类型处理及低成本计算分析的能力,受到了大家的欢迎。但企业应该如何做好大数据平台的云原生改造和升级呢?
为此,我们连线了智领云联合创始人兼 CEO 彭锋博士,一起来探讨大数据平台如何进行云原生改造。以下根据直播内容整理,有不改变原意的删减,完整内容可点击查看回放视频。(https://www.infoq.cn/video/2hzTak7zeZ293sbz2oDz)
A:虽然“云原生”近几年才火起来,但是业界在 2000 年初就开始做了。我 2005 年博士毕业加入 ask.com 后也是做云平台,当时的团队叫中间件团队(middleware)。Amzone 最开始做 IaaS 的时候还没有云原生的概念,先行者是制定了云原生 12 原则的 Heroku,它当时允许 APP 直接发到网上而不需要管理服务器,这也是早期的云原生应用。当时也没有现在很火的 K8s,所以云原生绝对不只是 K8s。容器的概念也是在 Docker 之前就已经出现,所以容器也不仅仅是 Docker。
云原生以前的门槛很高。我们在 Ask 的时候,几乎都是博士学历的人在做云平台,在 Twitter 的时候,基本上也没几个人会用。云原生概念从开始到现在的普及,大概用了 20 多的时间。其中最关键的是容器、微服务和声明式 API, 大家常说的 CI/CD 其实并不是云原生架构独有的。云原生关键的是面向资源编程,向系统申请需要的资源后就不需要管调度的细节了,应用的自动发布、容错,迁移等都是系统负责。面向资源编程,对整个分布式系统的开发、管理和易用性都有很大的好处。
A:一定是的。实际上,阿里做飞天的时候用的就是云原生技术。Hadoop 有三大组件:文件系统 HDFS、计算引擎 MapReduce、资源管理器 Yarn。现在 MapReduce 基本被 Spark 取代,作为存储的 HDFS 还有不少的应用,Yarn 的地位比较尴尬,因为它跟 K8s 做的都是资源管理的事儿。所以我觉得 MapReduce 和 Yarn 马上就要被淘汰了,像 Spark 以及大部分的数据应用现在都可以直接在 Kubernetes 上跑,所以大数据系统就并不再需要 Yarn 了。对于 HDFS,则会有一个云原生改造的升级。
Hadoop 本来有个对象存储系统 Ozone,现在 Ozone 被单独挪出去,不在 Hadoop 体系了。Hadoop 原来的这一套体系,大概率在三到五年后就会被完全被淘汰。这个改造是不可避免的,基于原来 Hadoop 生态体系的大数据平台一定会迁移到云原生平台。
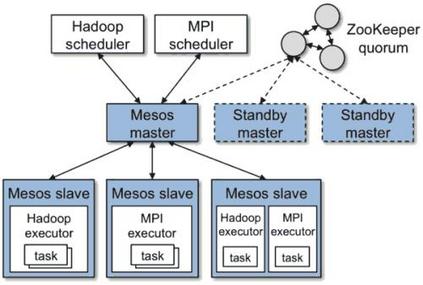
A:很早,大概 2011 年的时候。Mesos 上生产后,除了 Hadoop,其他所有应用都在 Mesos 上跑。当时,Mesos 就能支持 Twitter 内部八千多台机器的集群。Mesos 有自己的管理器,其实是走在 K8s 前面的。
我们当时为什么觉得这个很厉害?因为以前要发布一个系统,先得去申请机器、买机器,机器买回来后安装,装完后还要去测试。即使测试好了,也还要担心几个系统之间的第三方库有没有冲突。
大数据系统都是开源的。开源有个好处,就是便宜。开源不好的地方就是各个系统之间没有控制,两个开源系统依赖的第三方库有冲突。比如开源项目 A 用的是第三方库 C,另外一个开源项目 B 也用第三方库 C,但是两个项目依赖的 C 版本不一样,安装在同一个机器上就经常出问题,这是一个技术性的问题,困扰了大家很多年。
有了云原生功能后,每个应用都是自己的容器。我们当时用的还不是 Docker,是 universal container。这是 Mesos 自己做的一个容器,好处就是容器化、隔离,不会担心大家互相影响,应用可以实现秒级发布,对生产力的解放是革命性的。所以云化是必然趋势,大数据平台也遵从这样的趋势。
以后做的软件如果不是云原生的,百分之百不会有人用。因为,现在所有的新软件都用云原生的方式运行,老的软件就慢慢地跟不上了,不能说再单独搞个集群。所以,不能在云平台上跑的应用一定会被淘汰。
A:主要是互联网和大厂。现在的云原生大数据平台还不成熟。相比之下,企业更容易招到熟悉 Hadoop 技能的人。其次,这些大数据组件的云原生成熟度还不是特别高。Spark 今年 3 月份才具有一般可用性 (General availability,GA) ,并发布了 3.1 版本。Kafka 在今年 5 月份宣布 Kubernetes GA 但还没有开源。这两件事说明了现在主流的大数据组件厂商都在往 Kubernetes 上靠。这里就涉及到的 Spark、Hive 等核心组件以及他们依赖的相关组件都要升级,系统层面的升级对一般企业来讲是比较麻烦的。
国外的像 Twitter、Uber、Airbnb 等都在做这个事情,但他们的解决方案有的不是很理想。比如 Uber 是把整个 Yarn 挪到了 Kubernetes 上,这个有点不是特别好,我觉得应该把 Yarn 去掉,其他组件直接云原生化,比如类似于 MongoDB 的组件已经逐渐有 Kubernetes 发布版本出来。
综合起来的情况是, 现在大家都在推进,但还没有到特别成熟的阶段。
A:现在的大数据平台能解决基本的数据需求问题,但还有两个很大的问题需要解决。首先是资源管理。Yarn 的资源管理的粒度做得不是特别好,在多租户隔离和资源抢占上都能力有限,类似于 Spark 的应用没法混排,没法像云原生那样做到存算分离,计算和存储不能够充分利用每个节点的资源。最关键的是现在其他应用慢慢都不会为 Yarn 去做升级了,后续运维和升级会是问题。
其次,并不是说现在的大数据平台解决不了现在的问题,但是社区和生态的迁移已经是很明确的了。例如刚才说到的,像 MongoDB 都可以在 Kubernetes 跑,以后可能为了 Hadoop 就得单独搞一个集群。但如果用云原生的存储,就不需要单独一个集群了。所以,任务混排、资源隔离以及对新应用的支持等都是 Hadoop 体系现在比较大的硬伤。
A:现在所有的资源管理和编排可以依赖于 Kubernetes,企业可以专注在自己的业务逻辑和管理上。比如,现在容器存储接口(Container storage interface,CSI)越来越成熟,只要存储系统满足接口要求,那么无论是哪家提供商的应用就都可以访问。动态的依赖、发布和容错都可以依赖 Kubernetes 来做,这比要同时运行两个不同的集群要好很多。
另外,原来的 Hadoop 应用大概率不需要重写,因为它现在有专门兼容原来 HDFS 的存储,将兼容数据拷贝到 HDFS 兼容的存储上后,应用同样可以运行。现在我们要做的是,让 Hive 直接运行在 Spark 上、Spark 运行在 K8s 上,如此 Hive 的程序也不需要做大量的迁移就可以直接挪到 K8s 上,这样就能实现 K8s 集群的平稳迁移。
A:技术难点还是不少的,主要还是现在的大数据组件对 K8s 的支持还不是特别成熟,这是开源组件的问题。我举个例子。Spark 本身也依赖于很多别的开源组件,这些组件有的还没有支持 K8s,支持 K8s 组件中的版本也不一样。每个开源组件都号称自己支持 K8s,但把所有这些支持 K8s 的组件放到一起时,就会发现各种各样的版本存在冲突。还有一个问题就是 K8s 的升级太快。K8s 现在基本上每个季度升级一次,着也导致底下每个大数据组件支持的 K8s 版本不一样。总之,当前整个生态还不能协调地支持 K8s。
虽然很多大数据产品厂商都在做 K8s 支持,但在生产中还属于实验阶段。大家都还是处于刚刚起步的状态。从 K8s 自身来说,K8s 对有状态应用的支持和 CSI 存储方面的支持这两年也才完善起来,这两点是最大的技术难点,这也是大家最近一两年开始往 K8s 上迁移的原因。
A:我觉得,如果企业现在已经有 Hadoop 了,如果想未雨绸缪做迁移,那么可以开始尝试。一些不重要的业务可以先在云原生体系里跑起来,逐渐完善其稳定性,然后再逐渐扩展云原生集群。这个过程中,企业可以借用 K8s 管理体系不断完善流程。我不建议马上把 Hadoop 全搞过来,但是至少有一个测试集群,做好业务流程的验证。
如果是新的企业,我强烈建议直接在 K8s 上搭建集群。因为新企业集群一般规模不会太大,使用云原生支持的大数据组件一般不会有太多问题,而且会很好用。如果先用 Hadoop 以后再迁移的话就会很麻烦。现在用云厂商的产品搭建一个云原生的大数据平台是很快的。
A:我觉得主要还是人才方面的挑战。作为一个技术人员要能发现行业趋势。倒不是说要追逐最新的技术,但是如何选择在合适的时间选择合适的技术很重要。我前两天也提到,如果面试中公司还在问 Hadoop 的问题,那么基本可以认为这个公司的技术有点过时了。
以前 DevOps 有专门的运维工程师,开发人员要自己掌控从开发、测试、发布的整个流程。以后,数据科学家和数据分析师大概率可以自己掌控数据探索、数据分析和数据展示的这一整套流程。以前的 ETL 工程师可能就会更加局限,企业对他们的需求量变得更小。企业招人可能会更多地倾向数据分析师、数据科学家,因为底层已经标准化了。
从客户那里也感觉到:数据分析师缺,懂业务的分析师也缺,既懂业务又懂技术的数据分析师更缺。现在很多公司还处在建设大数据平台的过程中,可能体现的不明显。但随着越来越标准化,大数据运维的使用门槛会越来越低,企业会更愿意使用云原生的大数据平台。
A:云原生改造中,组件是一部分,但还有其他工作,如 CI/CD、日志管理、用户管理、监控等。大数据领域里还有数据质量、元数据等都需要 K8s 环境下的管理系统。K8s 带来的好处就是现在所有应用都以同样的模式发布,使用同一套资源管理体系。但像元数据管理、数据质量管理、工作流调度等就不是 K8s 提供的了。
之前,Spark 在 Yarn 上面跑,ETL 要到 Hive 上跑,SQL 要在 MySQL 里跑,现在这些都要在 K8s 上,K8s 变得非常重要,这也需要声明式 API 做整个集群管理。
现在,很多硅谷公司把 ETL 改成了代码管理,Airflow 把调度管理也变成了代码管理。所以,现在的一个趋势就是 K8s 是把集群管理全部变成了代码管理,大数据平台迁移到 K8s 以后也可以做代码及流水级代码的管理,也可以用 Git 来管理。所以,大数据平台的云原生改造不仅是组件,开发和管理形式也会发生很大的改变。
A:Snowflake 就是云原生大数据平台最典型的例子。Snowflake 自己没有存储也没有计算,它的计算能力用 K8s,存储能力用各个云厂商的,它在中间是动态的,通过 K8s 给用户发送一个专有的 MPP。
绝大部分云原生系统都可以做到存算分离,像 CSI,我在上面的应用可以杀掉,CSI 存储还在那,天然地就做到存算分离。应用没有访问量时就叫停,有用户使用时再分配资源,这样做到错峰资源、弹性扩容。一个资源池可以统一分配资源,提高了资源利用率、管理效率和整个运维效率,让系统运行更合理。十几年前,一个略大的集群要几十个博士才能搞定,现在一个本科生就可以,所以生产力的提高要靠标准化。
A:DataOps 做云原生改造主要是因为两个方面。首先是刚才说的标准化,DataOps 需要管理所有组件,但如果组件不是标准化的,那么这个事就很难做。其次,云原生带来了各种产品,如 Spark,Flink 等标准的统一。DataOps 包括五个方面:数据开发及 CI/CD、自动化调度、数据质量、数据门户、安全和审计合规,这些都要在云原生标准化基础上才能实现。
2021 年人均年终奖 2.3 万元;字节跳动日均进账 10 亿;Flink 联合创始人离职;Boss 直聘强制全员春节原地过年 | Q 资讯
《中国卓越技术团队访谈录》是 InfoQ 打造的重磅内容产品,为了能进一步了解读者的实际需求和喜好,持续为大家生产有价值、具备启发性的内容,我们发起了本次调查,真诚邀请广大社区读者参与问卷。同时,如果你希望 InfoQ 关注并采访你所在的技术团队,也可以通过本问卷报名,报名选项在问卷底部。
点击【阅读原文】,即刻参与有奖问卷调查,还有机会获得精美礼品。
如对本次调研有任何疑问或建议,欢迎联系微信 13512772438。

点个在看少个 bug 👇