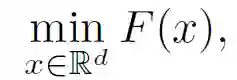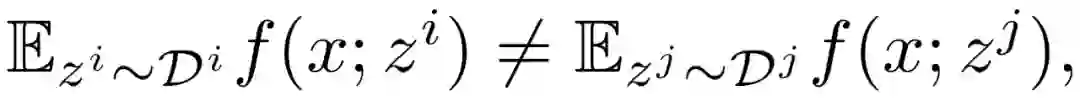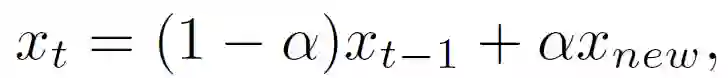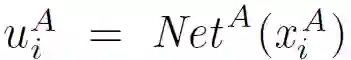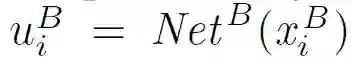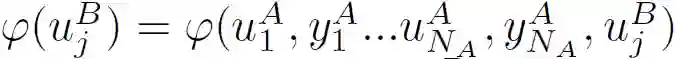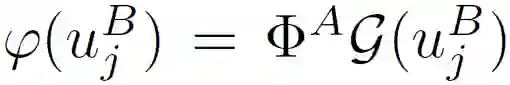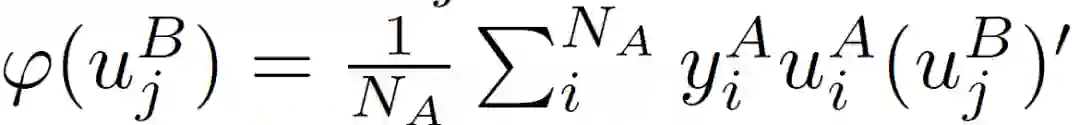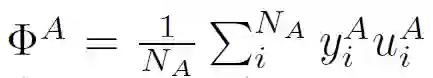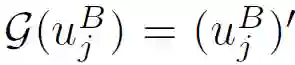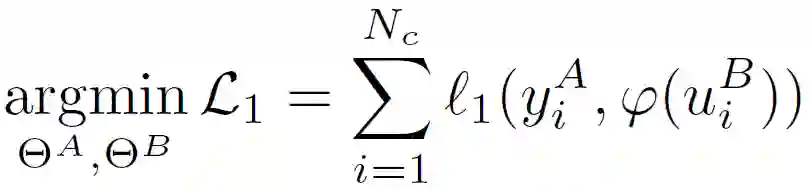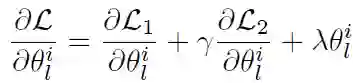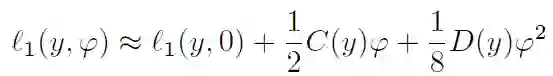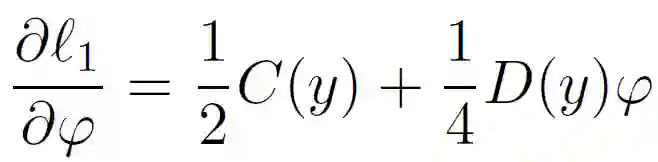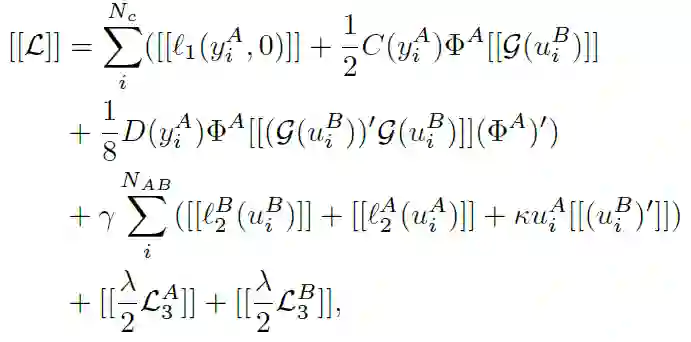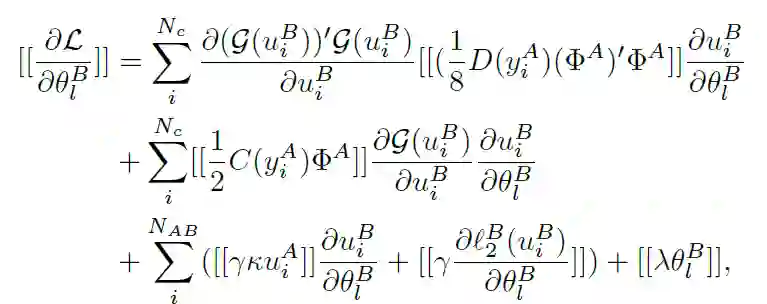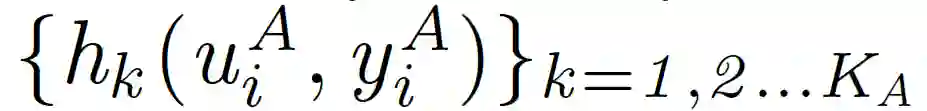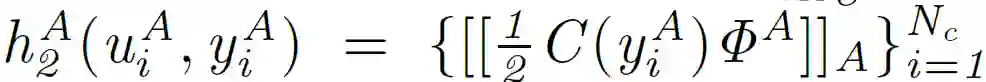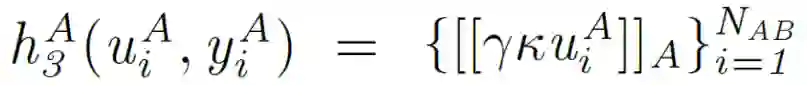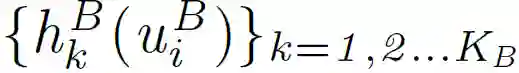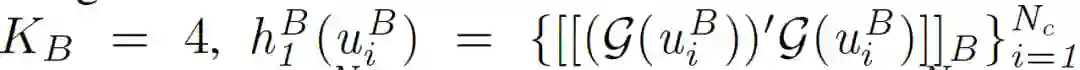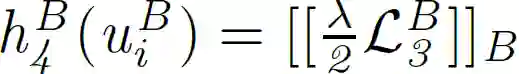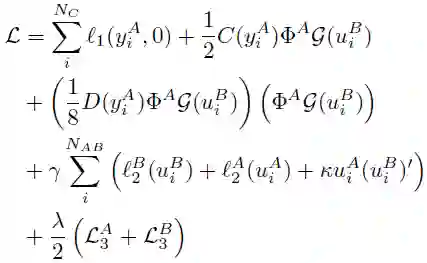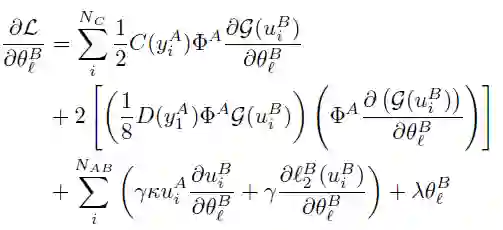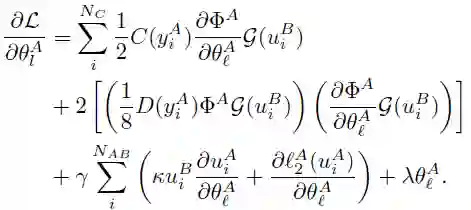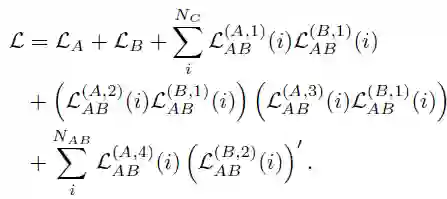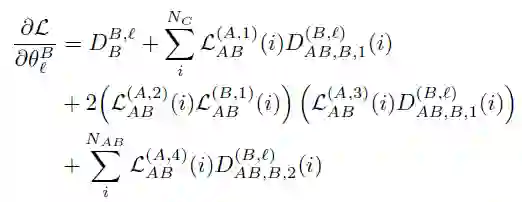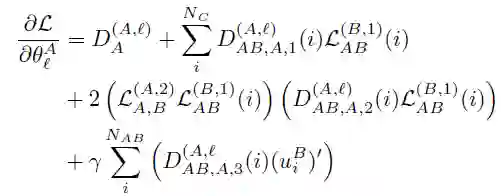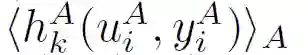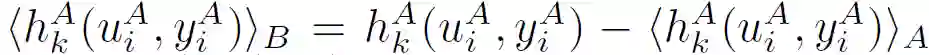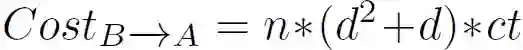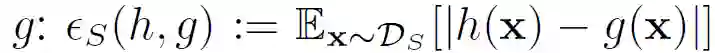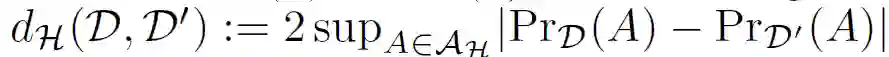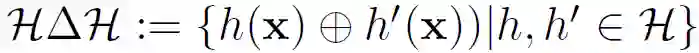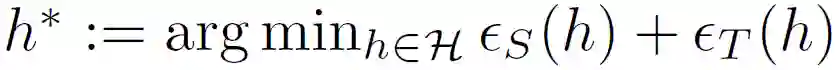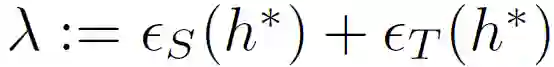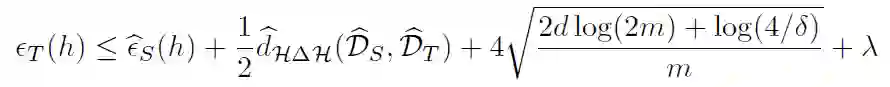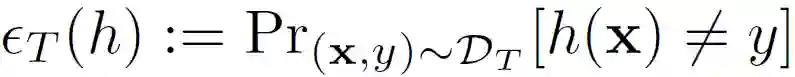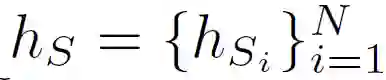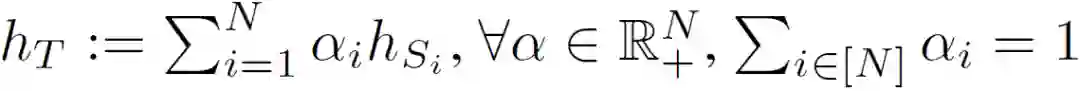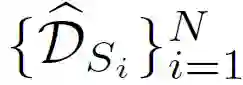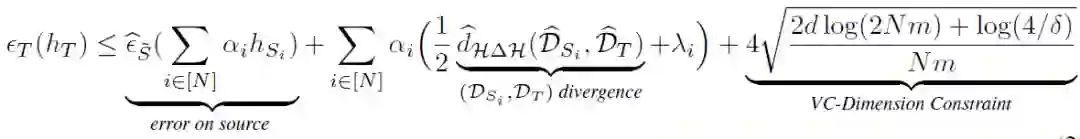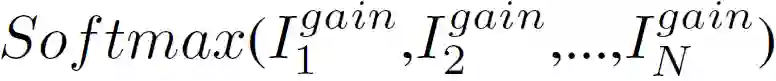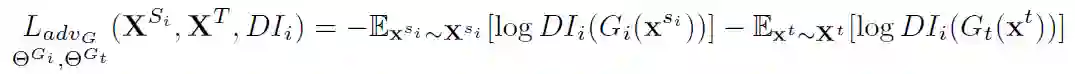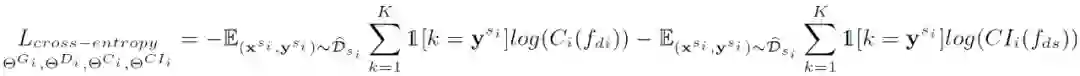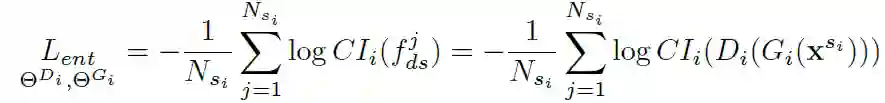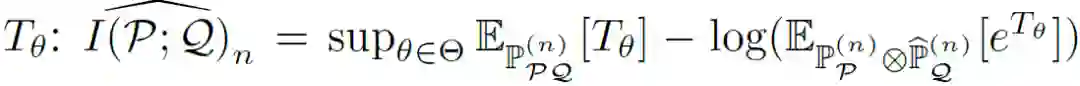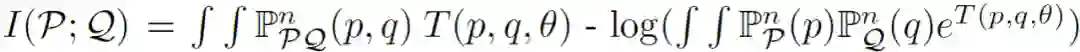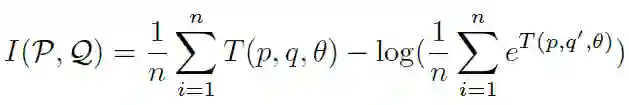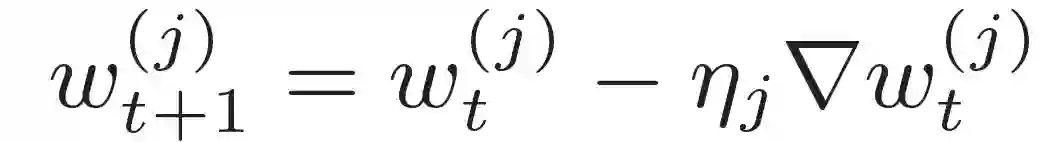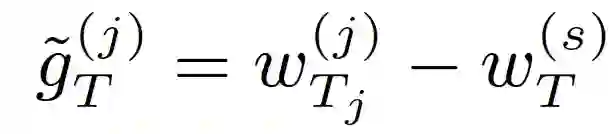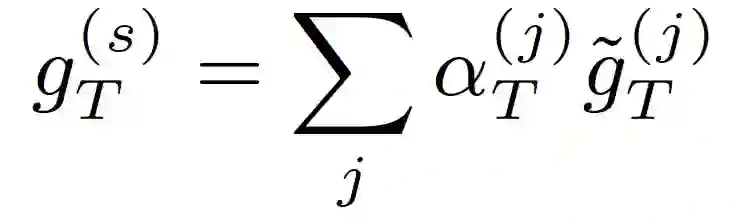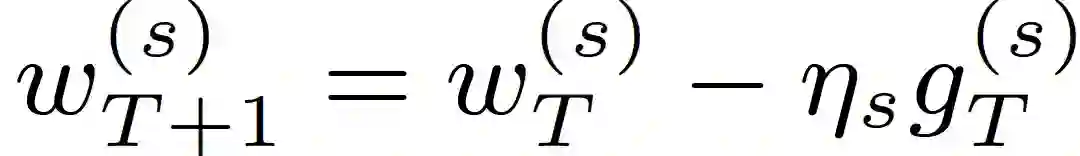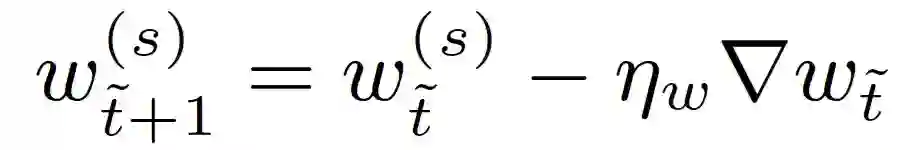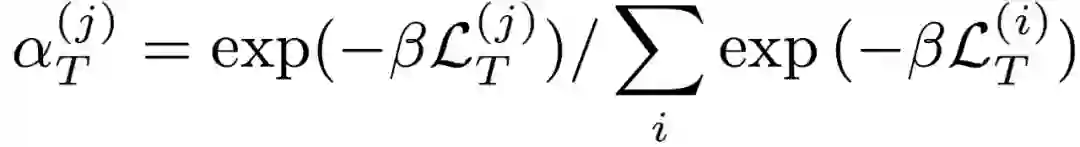在这篇文章中,作者通过 4 篇论文详细介绍了联邦学习中的联邦迁移学习问题,并探讨了向经典联邦学习中引入迁移学习的目的和意义。
海量训练数据是现代机器学习算法、人工智能技术在各个领域中应用获得成功的重要条件。例如,计算机视觉和电子商务推荐系统中的 AI 算法都依赖于大规模的标记良好的数据集才能获得较好的处理效果,如 ImageNet 等。然而在一些应用领域中,例如医学领域、经济学领域以及一些政务信息化领域中,海量的可用训练数据往往是非常有限的。存在这些问题的主要原因:一是,针对机器学习算法的数据标注任务需要专业的知识和经验才能完成,这种预处理任务的成本非常高,往往无法获得机器学习所需要的足够的标注数据。二是,各个行业对数据隐私和数据安全的保护越来越强,在一定程度上也限制了对训练数据的共享,也就进一步加剧了可用的标注数据缺乏的问题。
联邦学习(Federated Learning,FL)是解决上述问题的一种有效方法。2016 年,Google 首次提出了针对移动设备的联邦学习(FL)系统 [1],该系统允许用户形成一个联合体训练得到一个集中模型,而用户数据则安全地存储在本地,这就解决了数据隐私和安全保护问题。同时可以有效应用联合体各方所掌握的标注数据,解决标注数据缺乏的问题。但是,FL 要求联合体的不同方拥有的训练数据必须共享相同的特征空间,这就限制了 FL 的实用性。关于 FL 中的异构性问题,机器之心之前也有过专门报道,感兴趣的读者可以阅读相关文章。
微众银行 (WebBank) 进一步提出了联邦迁移学习(Federated Transfer Learning,FTL)[1,6]。FTL 通过应用同态加密(Homomorphic Encryption)和多项式近似代替差分隐私(Polynomial Approximation instead of Differential Privacy)的方法,为特定行业提供了一种更安全、更可靠的方法。与此同时,基于迁移学习的的特性,FTL 的参与方可以拥有自己的特征空间,而无需强制要求所有参与方都拥有或使用相同特征的数据,这使得 FTL 适合于更多的应用场景。
本文关注联邦迁移学习方法,在介绍联邦学习和迁移学习相关知识的基础上,重点探讨向经典联邦学习中引入迁移学习的目的和意义
。此外,本文还将梳理目前主流的联邦迁移学习方法,并重点介绍其中的 4 篇文章。
FL 允许多个参与方(也称为客户机、用户、客户端等)协作训练得到一个共享的全局模型,在这个过程中各个参与方无需分享本地设备中的数据,充分保证了参与方的数据隐私性和安全性。由 FL 系统中的中央服务器协调完成多轮联邦学习以得到最终的全局模型。其中,在每一轮开始时,中央服务器将当前的全局模型发送给各个参与方。各个参与方则根据其本地数据训练所接收到的全局模型,训练完毕后得到更新模型并将更新模型返回中央服务器。中央服务器收集到所有参与方返回的更新后,对全局模型进行一次更新,进而结束本轮更新。在整个更新过程中,数据保存在参与方本地设备中,而设备与中央服务器之间传输和交换的是加密后的模型。
从数学角度展示 FL,假设有 n 个参与方,经典 FL 表示为:
![]()
![]()
其中,z^i 为第 i 个参与方的设备中所存储数据采样。由于不同参与方的设备之间存在异构性,所存储的数据库也不同,从不同设备中提取的样本具有不同的期望值:
![]()
联邦学习的一次完整的更新过程由 T 个全局 epochs 组成。在第 t 个 epoch 中,中央服务器接收任意一个参与方设备发回的本地训练的模型 x_new,并通过加权平均来更新全局模型:
![]()
其中,α∈(0,1),α为混合超参数 (mixing hyperparameter)。在任意设备 i 上,在从中央服务器接收到全局模型 x_t 后,使用 SGD 进行局部优化以解决以下正则化优化问题:
![]()
中央服务器和客户机设备的工作线程执行异步更新。当中央服务器接收到本地模型时,会立即更新全局模型。
Google 的 FL 框架是在实际应用中使用的一套体系,为了能够满足实用性的要求,Google 的框架对上述经典 FL 架构做了一些修改和限定。它在中间结果中添加了噪声,以防止攻击者访问和推断私有信息。增加的噪声会降低准确度,从而导致生成低质量的模型。尽管如此,它仍在传输可能导致恶意攻击的敏感信息。最后,该框架要求所有参与方在同一个特征空间中拥有数据,这使得在实际场景中不同的参与方可能无法共享完全相同的特征空间。
1.2、迁移学习(Transfer Learning)
迁移学习是机器学习的一个重要分支,其主要目的是将已经学习过的知识迁移应用于新的问题中。关于迁移学习最权威的综述性文章是香港科技大学杨强教授团队的《A survey on transfer learning》[7]。我们在这里参考杨强教授的文章对一些迁移学习的基本概念进行阐述。
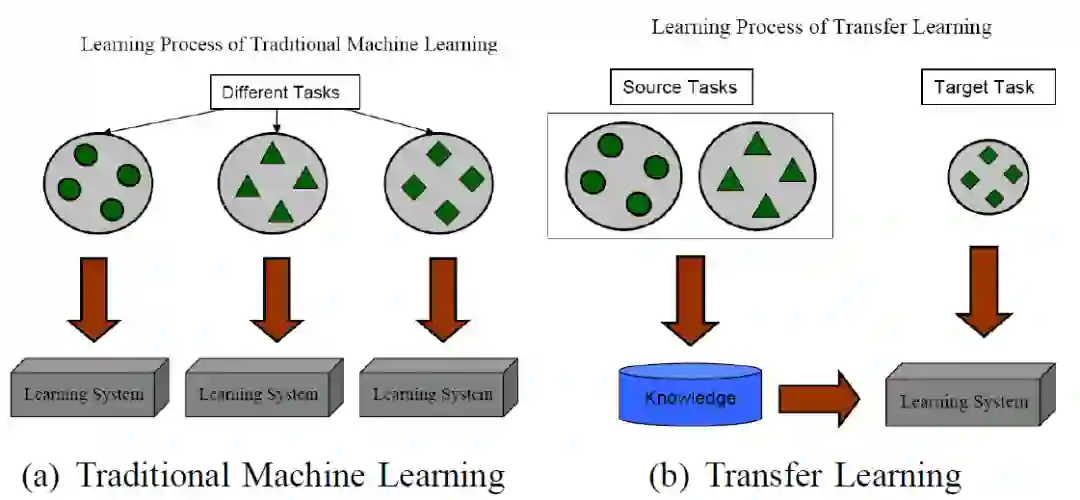
迁移学习允许在机器学习模型的训练和测试中所使用的域(domains)、任务(tasks)和分布(distributions)是不同的。正如杨强教授所举的例子,我们可能会发现学习识别苹果可能有助于识别梨,同样,学习演奏电子管风琴也有助于学习钢琴。也就是说,人类能够智能地应用先前所学的知识来更快地或更好地解决新问题。迁移学习的目的是使机器也能具备这种能力。图 1 示出了经典机器学习技术和迁移学习技术的学习过程之间的区别。可以看出,经典机器学习技术试图从零开始学习每一个任务,而迁移学习技术则是在目标任务的高质量训练数据较少的情况下,将前一个任务的知识转移到目标任务上。
![]()
从数学角度描述迁移学习,给定一个源域 Ds 和学习任务 Ts,目标域为 Dt 和学习任务 Tt,迁移学习的目的是利用 Ds 和 Ts 中的知识来改进对 Dt 中目标预测函数 f_T(·)的学习,其中 Ds ≠ Dt,或 Ts ≠ Tt。
在上面的定义中,域是一对 D={X,P(X)}。因此,条件 Ds ≠ Dt 意味着 Xs ≠ Xt 或 Ps(X) ≠ Pt(X)。例如,在文档分类示例中,这意味着源文档集和目标文档集之间的术语特征要么不同(例如,它们使用不同的语言),要么边际分布不同。类似地,将任务定义为一对 T={Y, P(Y | X)}。条件 Ts ≠ Tt 意味着 Y_S ≠ Y_T 或 P(Y_S | X_S) ≠ P(Y_T | X_T)。当目标域和源域相同,即 Ds=Dt,学习任务相同,即 Ts=Tt 时,学习问题成为传统的机器学习问题。当域不同时,(1)域之间的特征空间不同,即 X_S ≠ X_T;(2)域之间的特征空间相同,但域数据之间的边缘概率分布不同,即 P(X_S) ≠ P(X_T),其中 X_Si∈X_S,X_Ti∈X_T。给定特定的域 Ds 和 Dt,当学习任务 Ts 和 Tt 不同时,要么(1)域之间的标记空间不同,即 Y_S ≠ Y_T;要么(2)域之间的条件概率分布不同。
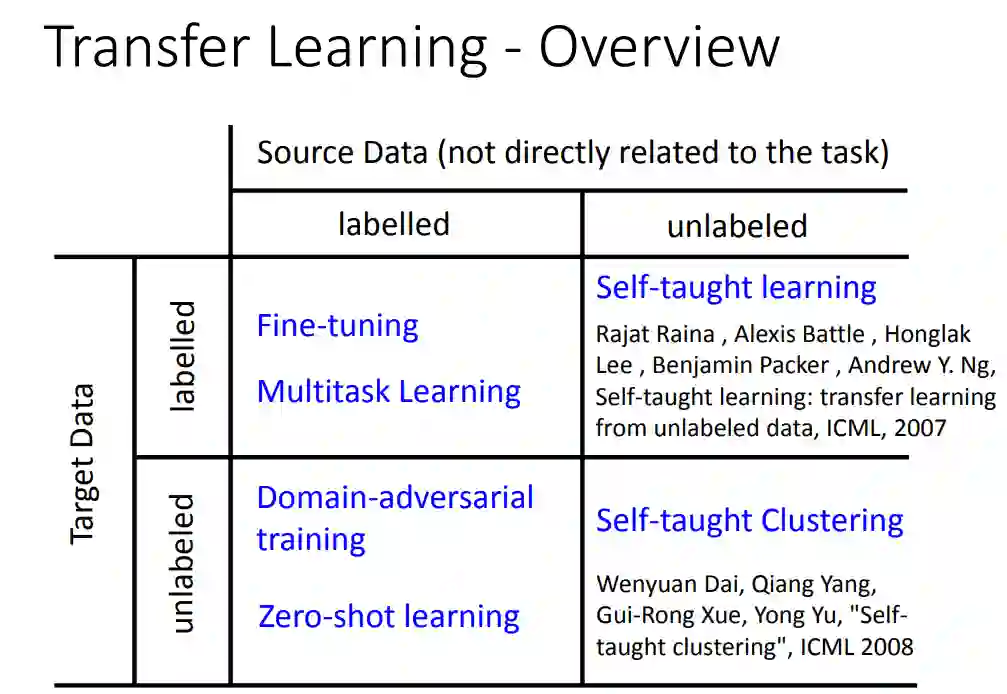
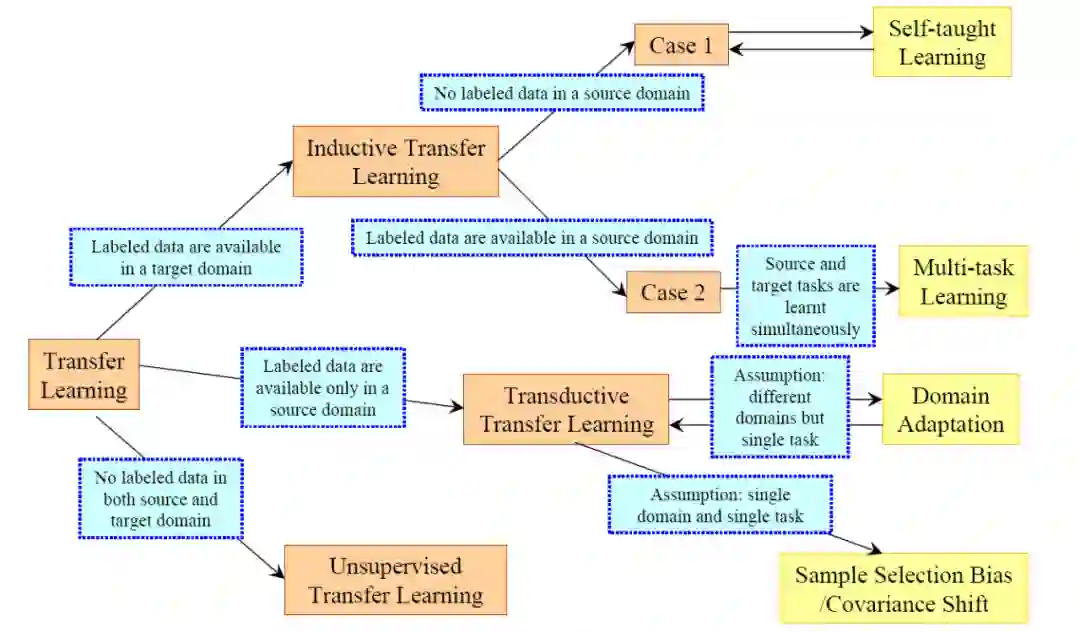
杨强教授在文章中还对不同迁移学习方法进行了类别划分,见图 2。在归纳迁移学习(inductive transfer learning)中,无论源域和目标域何时相同,目标任务都不同于源任务。当源域中有很多标记数据可用时,归纳迁移学习类似于多任务学习。然而,归纳迁移学习的目的仅仅是从源任务中转移知识,而多任务学习则试图同时学习目标任务和源任务。当源域中没有可用的标记数据时,归纳迁移学习与自学习类似。在自学习中,源域和目标域之间的标注空间可能不同,这意味着不能直接使用源域的边际信息。因此,自学习可以看做是源域中标注数据不可用的归纳迁移学习。下面为李弘毅老师关于迁移学习课程 PPT 中的截图,从另外的角度针对源、目标域内数据的标注情况进行了所涉及到的主要方法的列举,能够更好的帮助理解迁移学习。具体课件地址为:http://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2016/Lecture/transfer%20(v3).pdf。
![]()
在直推式迁移学习(transductive transfer learning)中,源任务和目标任务是相同的,而源域和目标域是不同的
。在这种情况下,目标域中没有可用的标记数据,而源域中有许多标记数据可用。此外,根据源域和目标域的不同情况,进一步将直推式迁移学习分为两种情况。一是,源域和目标域之间的特征空间不同;二是,域间特征空间相同,但输入数据的边缘概率分布不同。
在无监督迁移学习(unsupervised transfer learning)中,与归纳迁移学习类似,目标任务与源任务不同,但与源任务相关。无监督迁移学习的重点是解决目标域中的无监督学习任务,如聚类、降维和密度估计等。在这种情况下,在训练中源域和目标域中都没有可用的标注数据。
![]()
FTL 的目的是在保护隐私的前提下,利用迁移学习克服数据或标签的不足的问题。FTL 将 FL 的概念加以推广,以实现在任何数据分布、任何实体上均可以进行协同建模、以学习全局模型。它不仅可以应用于两个样本的空间,还可以应用于两个不同的数据集。
FTL 将来自不同特征空间的特征迁移到同一个潜在表示中,然后利用不同参与方收集的标注数据中的标签进行训练。在 Google 提出的 FL 实用框架中,强调的是参与方也就是联邦学习架构中的用户是独立的,但
不同参与方之间的特征必须是相同的
。而由杨强教授提出的 FTL 框架则是
强调不同参与方的特征是不同的
。也就是说,Google 的经典 FL 框架主要目的是保证各个参与方的用户隐私,而 FTL 框架的主要目的是应对数据不足、小数据量的问题,同时保证各个参与方的安全性和隐私性。
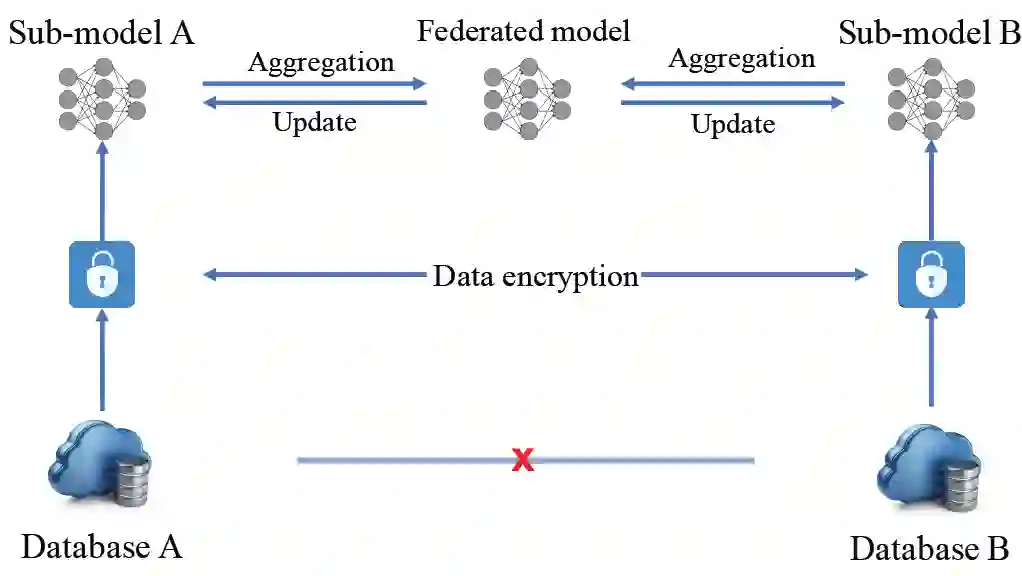
FTL 的工作流程见图 3 [2]。在训练一个模型时,A 和 B 双方首先计算并加密他们的中间结果,包括梯度和损失。然后由第三方收集并解密梯度和损失。最后,A 和 B 收到汇总结果并更新各自的模型。为了避免在反向传播过程中暴露参与方的数据,FTL 采用同态加密保证安全性,利用多项式差分近似来保证隐私性。与经典 FL 中将原始数据和模型保存在本地的处理方法不同,FTL 在数据传输之前,会令参与方对梯度进行加密,并使用一些技术如添加随机掩码等,以防止参与方在任务的任何阶段猜测得到对方的信息。
![]()
利用 FTL 框架,可以在原有的各种机器学习算法和模型的基础上进行改进。首先,不同参与方可以根据不同来源的数据首先训练各自的模型,然后,将这些模型数据进行加密后使之不能直接传输以免泄露参与方的隐私。在此基础上,对这些模型进行联合训练以得到最终的最优模型,再返回给各个参与方。
本文在接下来的文章中将重点介绍 FTL 框架 [1] 以及对 FTL 实用性能的分析[2]
。此外介绍两篇 FTL 相关的方法,其中一篇关注联邦域适应(Domain Adaption)的问题,属于直推迁移学习方法在联邦学习框架中的应用,另外一篇为微软研究院的工作,重点关注 FTL 中的梯度聚合方法。
2.1、 A Secure Federated Transfer Learning Framework
![]()
本文提出了联邦转移学习(FTL)来解决现有联邦学习方法的局限性,利用迁移学习为联邦学习框架下的样本和特征空间提供解决方案
。作者将 FTL 问题在一个隐私保护的环境下形式化,提供了一个用于解决现有 FL 方法无法应对的联邦学习问题的解决方案。此外,作者提供了一个端到端的 FTL 解决方案,并证明了该方法在收敛性和准确性方面的性能与非隐私保护的迁移学习相当。最后,在 FTL 框架下,作者将加同态加密(HE)和基于 beaver 三元组的秘文共享方法结合到神经网络的两方计算(two-party computation,2PC)中,这种加密处理方法只需对神经网络进行最小的修改并且几乎不会影响准确度,就可以实现对各个参与方的安全性和隐私性保护。
深度神经网络被广泛应用于迁移学习以找到隐藏的迁移机制。本文构建了一个迁移学习场景,其中 A 和 B 的隐藏表示由两个神经网络生成:
![]()
![]()
神经网络 NetA 和 NetB 作为特征转换函数,将 A 和 B 的源特征投影到一个共同的特征子空间中,A 和 B 可以在该子空间中进行知识迁移。实际上,可以应用任何其他的对称特征变换技术来构造公共特征子空间。只不过,使用神经网络可以建立一个端到端的解决方案来解决所提出的 FTL 问题。
![]()
在不失一般性的前提下,本文假设φ((u_j)^B)是线性可分的。也就是说,
![]()
![]()
![]()
![]()
![]()
此外,还要将 A 和 B 之间的对齐损失最小化,以便在联邦学习环境中实现特征迁移学习:
![]()
![]()
![]()
为了满足联邦学习的安全性和隐私性要求,在假设 A 和 B 不允许暴露其原始数据的情况下,需要进一步引入隐私保护方法来计算上述目标函数。作者对逻辑损失函数 l_1 采用二阶泰勒近似进行处理:
![]()
![]()
至此,针对 A 和 B 两个参与方的 FTL 完整目标函数构建完毕。作者在此基础上,讨论了 FTL 的两种替代结构:第一种是利用附加同态加密(HE)确保安全性,第二种是利用基于 beaver 三元组的密文共享以保证隐私性。
对二阶泰勒近似处理的目标函数以及梯度值进行同态加密处理(同态加密记做[[·]])。得到了 A 和 B 两个域的隐私保护损失函数和相应的梯度:
![]()
![]()
![]()
令[[·]]A 和[[·]]B 分别表示 A 和 B 的公钥的同态加密运算符。A 和 B 在本地初始化并执行各自的神经网络 NetA 和 NetB,以获得隐藏表示(u_i)^A 和(u_i)^B。A 计算并加密组件:
![]()
并将其发送到 B 以协助计算 NetB 的梯度。此时有如下参数:
![]()
![]()
![]()
![]()
并将其发送到 A 以协助计算 NetA 的梯度。此时有如下参数:
![]()
![]()
![]()
为了防止 A 和 B 的梯度暴露,A 和 B 进一步用加密的随机值屏蔽每个梯度。然后,它们互相发送被屏蔽的梯度和损失,并在本地解密这些值。一旦满足损耗收敛条件,A 可以向 B 发送终止信号。否则,它们将不再隐藏梯度,而是用各自的梯度更新权重参数,并继续进行下一次迭代。一旦模型训练完毕,FTL 可以对 B 中未标注的数据进行预测。
![]()
假设任何私有值 v 在 A 和 B 双方之间共享,其中 A 保留 < v>A,B 保留 < v>B,因此 v=<v>A+<v>B。此时,损失函数、梯度值记为:
![]()
![]()
![]()
在这种情况下,如果能够构造安全的矩阵加法和乘法,就可以保证整个执行过程的隐私性。由于使用公共矩阵或添加两个私有矩阵的操作可以简单地通过共享(Sharing)来完成,因此只需要讨论安全矩阵乘法操作。本文使用 Beaver’s 三元组实现矩阵乘法。
假设所需的计算是得到 P=MN,其中 M、N 和 P 的维数分别是 m x n、n x k 和 m x k。假设矩阵 M 和 N 被双方秘密共享,其中 A 保留 < M>A 和 < N>A,B 保留 < M>B 和 < M>B。为了辅助计算,在预处理阶段 A 和 B 分别生成了维度为 m x n、n x k 和 m x k 的三个矩阵 D、E、F,其中 A 保持 < D>A、<E>A 和 < F>A,而 B 保持 < D>B、<E>B 和 < F>B,满足 DE=F。满足协议要求,<P>A+<P>B=MN。可以看出,这种方法保证了在线计算的有效性。过程中 Beaver’s 三元组的生成方式如 Algorithm4:
![]()
![]()
![]()
![]()
关于完整的数学推导计算过程,感兴趣的读者可以阅读原文详细了解。A 和 B 在本地初始化并执行各自的神经网络 NetA 和 NetB,以获得隐藏表示(u_i)^A 和(u_i)^B。A 计算并加密组件:
![]()
![]()
![]()
A 将 k(k=1,...K_A)的上式结果发送给 B,类似的 B 也执行上述过程。训练过程完成后,则进入预测阶段。完成的基于密文分享的 FTL 过程如 Algorithm6 所示:
![]()
作者给出了多个公共数据集上进行的实验结果已验证本文所提出的方法,包括:NUS-WIDE 数据库和 Kaggle 的信用卡客户违约数据库(“Default-Credit”)
。NUS-WIDE 数据库包括了来自 Flickr 上的图像的 634 个低层次特征,以及它们的标签和真值标签。总共有 81 个真值标签。作者使用前 1000 个标签作为文本特征,并与所有低层特征进行结合,包括颜色直方图和颜色相关图等图像特征。作者在 A 和 B 之间建立了一个数据联合体来解决 1 对多的分类问题,其中 A 包含 1000 个文本标记特征和标签,而 B 包含了 634 个低级图像特征。
Default-Credit 数据库由信用卡记录组成,具体包括用户人口统计、支付历史记录和账单等,并以用户的默认付款作为标签。在对分类特征进行独热编码处理后,得到了一个包含 33 个特征和 30000 个样本的数据库。然后作者在特征空间和样本空间中对数据库进行分割处理,以模拟 A 和 B 双方联合的问题。具体来说,将样本分配给 A、B 或 AB 双方,这样可以保证在 A 和 B 之间存在少量重叠的样品。所有的标签信息都存储在 A 方。
作者针对 FTL 中不同的关键因素,包括重叠样本的数量、隐藏公共表示的维度和特征的数量,研究了该方法的有效性和可扩展性。作者在实验中对基本 FTL(TLL)、基于同态加密的 FTL(TLT)、基于密文共享的 FTL(SST)进行了对比。选择了三种机器学习模型:逻辑回归(LR)、支持向量机(SVM)和堆叠式自动编码器(SAEs)。
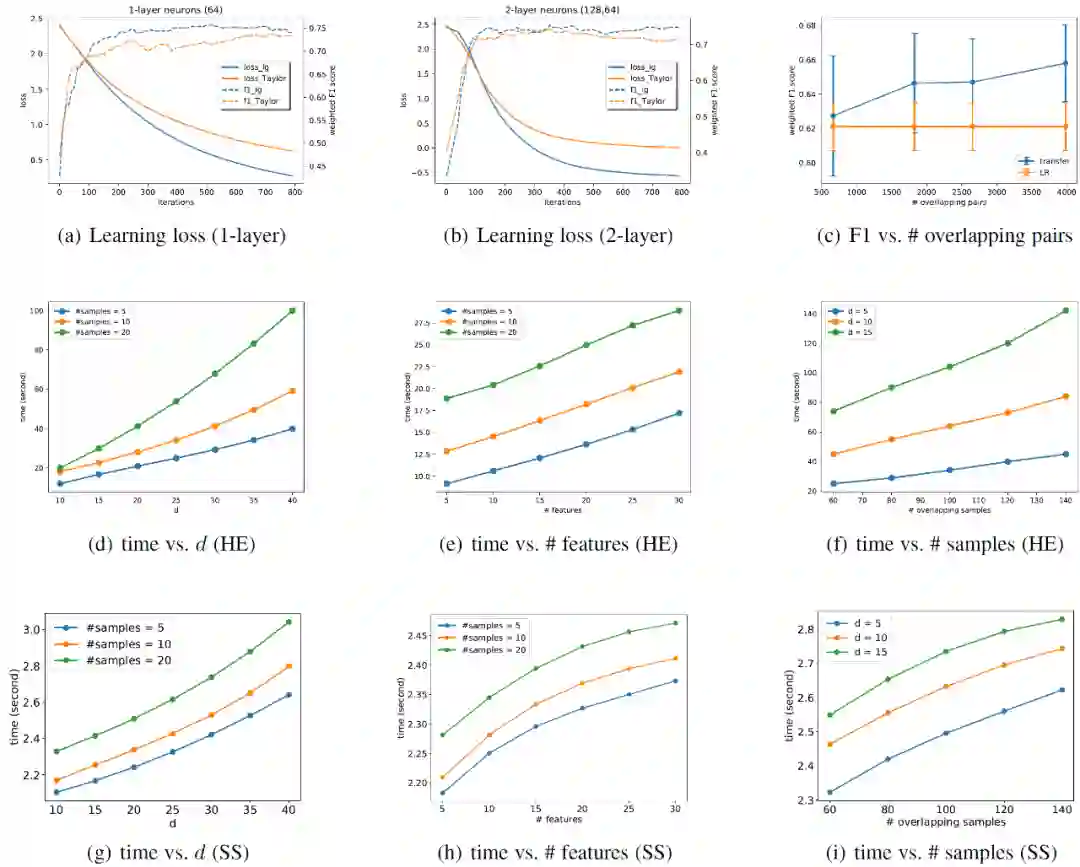
NUS-WIDE 数据库中的实验结果见图 5。其中图 5(a)和(b)展示了引入二阶泰勒近似处理的有效性。其中,第一种情况下 NetA 和 NetB 都有一个自动编码器层,分别有 64 个神经元。在第二种情况下,NetA 和 NetB 都有两个自动编码器层,分别有 128 个和 64 个神经元。在这两种情况下,作者分别使用了 500 个训练样本,1396 个重叠样本对。由实验结果可知,与使用基本的 logistic 损失相比,使用 Taylor 近似时损失的衰减速率相似,并且 Taylor 近似方法的加权 F1 得分也可与 logistic 方法相当。图 5(c)显示了改变重叠样本数对迁移学习性能的影响。重叠的样本对用于连接双方之间的隐藏表示,由实验结果可知 FTL 的性能随着数据集之间重叠的增加而提高。
![]()
进一步,
作者使用 Default-Credit 数据库中的实验来研究 FTL 的可伸缩性
。具体的,作者研究了训练时间如何随重叠样本数、目标域特征数和隐藏表示维度的变化而变化。基于所提出的迁移学习方法,B 向 A 发送消息的通信代价可以计算为:
![]()
其中,ct 表示消息的大小,n 是发送的样本数。在从 A 向 B 发送消息时,通信代价的计算方式相同。
为了加快 FTL 的计算速度,作者进行了
并行处理
。并行处理逻辑流程包括三个阶段:并行加密、并行梯度计算和并行解密。在并行加密阶段,对发送给另一方的组件进行并行加密。在并行梯度计算阶段,对加密分量进行并行运算,包括矩阵乘法和加法,以计算加密梯度。在并行解密阶段,对掩模损失和梯度进行并行解密。最后,AB 双方交换解密的掩模梯度,用于更新神经网络。在划分为 20 个分区的情况下,并行方案比串行方案的速度提高了 100 倍。图 5(d)、图 5(e)和图 5(f)说明了基于 HE 的 FTL 的运行时间随着隐藏表示维度的大小、目标域特征的个数以及重叠样本数量实现近似线性增长。图 5(g)、图 5(h)和图 5(i)说明了训练时间如何随密文共享中的三个关键因素而变化。在其他因素不变的情况下,通信成本可以简化为 O(d^2)。
本文提出了一个安全的联邦迁移学习(FTL)框架,引入了同态加密和密文共享两种保护隐私的安全方法。同态加密方法简单,但计算成本较高。密文共享方法的优点是没有精度损失,计算速度也较快,但其主要缺点是需要离线生成和存储多个三元组才能执行在线的联邦学习。
FTL 框架是一个通用的隐私保护联邦迁移学习解决方案,并不局限于特定的机器学习模型或其它特征提取或映射的方法
。作为后续的研究方向,作者考虑将引入不同的分布式计算技术,以及廉价计算和通信方案来提高 FTL 框架的整体效率。
2.2、Quantifying the Performance of Federated Transfer Learning
![]()
FTL 利用迁移学习技术利用不同来源、不同特征的数据进行联合训练,同时实现数据隐私保护而不会造成严重的精度损失。然而,这些益处也伴随着额外的计算和通信消耗代价,因而存在效率问题。为了在实践中有效地部署和扩展 FTL 解决方案,我们需要深入了解基础设施会如何影响 FTL 的效率。本文并不是提出一种新的 FTL 方法,而是试图通过评估真实场景中部署的 FTL 的效率来回答上面的问题。
本文选择 FATE 的应用场景验证 FTL 的效率(WeBankFinTech. Webankfintech/fate. https://github.com/webankfintech/fate, 2019)。FATE 是由 Webank 的 AI 部门发起的开源项目,旨在提供安全的计算框架来支持联邦 AI 生态系统。它基于同态加密和多方计算(MPC)实现安全的计算协议。它支持联邦学习体系结构和各种机器学习算法的安全计算,包括逻辑回归,深度学习和迁移学习等。FATE 官方网站:https://fate.fedai.org/。FATE 的整体结构如下。
不同角色:FTL 中有三种不同的角色, 访客(Guest)、主机(Host)和仲裁者(Arbiter)。访客和主机都是数据的持有者。Guest 是启动特定任务以及执行多方模型训练的机构,Guest 基于自己本地存储以及 Host 提供的数据集进行训练。它们主要负责计算和数据加密。Arbiter 在任务开始之前将公钥发送给 Guest 和 Host,并允许它们之间进行数据交换。在模型训练期间,Arbiter 负责汇聚梯度以及验证模型是否收敛。
工作流:Guest 和 Host 首先使用自己的数据在本地计算和加密中间结果,这些数据将用于计算梯度和损失值。然后 Guest 和 Host 将加密的值发送给 Arbiter。最后,Guest 和 Host 从 Arbiter 处获取解密后的梯度和损失以更新模型。FTL 框架迭代地重复上述步骤,直到损失函数收敛为止。
训练过程:FTL 提供了同质和异质两种训练方法。对于同质方法,各方用不同的样本训练同一个模型。而对于异构特征,各方在不同的特征空间共享相同的样本,以加密的状态聚合这些特征并协同构建一个包含所有数据的模型。
此外,FATE 中的机器学习算法用 Python 实现,关于任务调度、线程 / 进程管理和数据通信等底层框架使用 Java 编写。在每一个参与方中,不同的节点上有多个处理器并行训练模型。不同进程、节点和参与方之间的数据传输基于 gRPC 远程过程调用。
FTL 和分布式机器学习(Distributed Machine Learning,DML)具有相似的特性,它们都有多个工作节点,这些节点保存不同的数据,并根据聚合结果更新模型
。然而,它们之间也存在一些显著的差异。对于分布式机器学习任务,参数服务器作为中心调度节点将数据和计算资源分配给工作节点以提高训练效率。但是对于 FTL 来说,数据持有者拥有自己的工作节点,并且对自己的数据拥有完全的自治权。此外,FTL 在训练模型时为了保证数据拥有者的数据隐私,所使用的加密方法需要更强大的计算能力和更快的网络来传输数据。数据隐私保护的要求也使得这样的数据传输更加频繁,这就进一步增加了对高效网络环境的需求。因此,FTL 的框架更为复杂,而分布式机器学习是 FTL 的一个理想情况,即:其中数据归一方所有,不需要加密。
对于一定的模型和数据集,分布式训练的性能是 FTL 所能达到的最优性能。原因是这两种模式都有相似的工作流程,但 FTL 有额外的开销,如数据加密和模型修改等,用以保证数据的隐私性。本文作者试图量化 FTL 的各种开销。首先测量端到端的任务完成时间,这就提供了两种方法之间的性能差距的概述。在 FTL 和分布式机器学习中,计算和数据传输对性能起着至关重要的作用,为了解释造成这种巨大性能差距的因素,进一步,作者将任务完成时间分解为 CPU 时间和通过网络传输数据的时间进行对比和分析。
作者使用 Google 云的虚拟实例进行验证,所使用的数据集是乳腺癌数据库[8],它包含 569 个样本和 32 个特征。为了使评估结果具有代表性,作者使用开源的 FTL 平台 FATE v0.1 进行评估。作者在 FTL 中使用了两种常见的 logistic 回归(Logistic Regression,LR)模型,即同质 LR 和异质 LR。根据同质模型和异构模型目标的不同,将数据库分为纵向和横向两部分。横向划分处理后生成同质模型所需的不同数据样本,而纵向划分处理后的数据库则具有不同的特征空间,用于构建异构模型。作为比较,作者使用 Tensorflowv2.0.0 实现了分布式 logistic 回归,其中包括一个参数服务器和两个工人结点。在所有的实验中,模型都用相同的迭代次数进行训练。
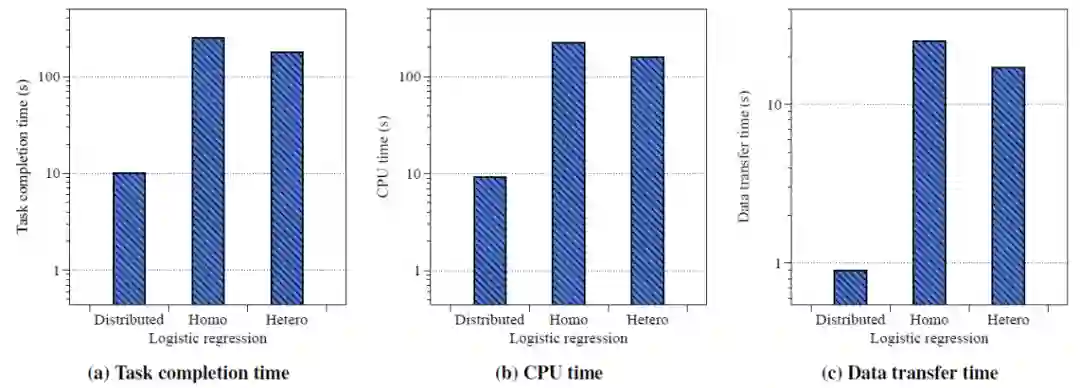
如图 6a 所示,与简单的分布式实现相比,同质 LR 和异构 LR 任务完成时间大约为 24 x (250s vs 10s) 和 17 x (177s vs 10s) 。此外,作者将任务完成时间分解为 CPU 时间和数据传输时间,以深入了解哪些因素导致了较大的开销。结果如图 6b 和 6c 所示。与分布式实现相比,这两种模型的 CPU 执行时间和数据传输时间都要长得多。实验结果表明,FTL 仍然面临巨大的计算和数据传输开销问题,需要进一步改进。
![]()
图 6. 同质(Homo)logistic 回归和异质(Hetero)logistic 回归的任务完成时间、CPU 执行时间和数据传输时间。
对于 CPU 的执行时间,仅仅根据评估结果很难解释时间增加的原因。作者对代码进行了分析,提出了两个可能的原因:1)由于数据加密,增加了计算量;2)大部分 CPU 资源都花在了额外的任务上,如进程间通信和内存拷贝。
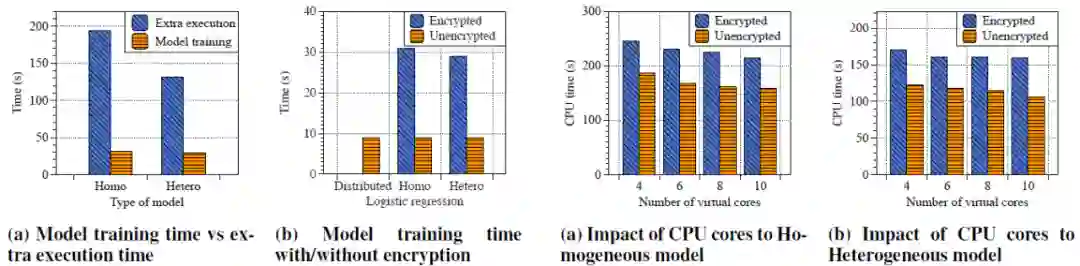
图 7a 给出了模型训练时间和额外执行时间的比例。以异构 LR 为例,只有 18% 的 CPU 执行时间(160s 中的 29s)用于模型训练。额外的 CPU 消耗会导致训练任务的性能显著下降。作者分析,性能下降的原因如下:1)不同运行阶段之间的数据交换和内存拷贝,如 python 和 JVM;2)在 JVM 中,仍存在两个进程,一个负责在数据准备好后创建和发布作业,另一个则对各种系统事件做出响应,并将数据传输给远程用户。两个进程之间的通信以及进程内的线程调度都会影响效率。总之,机器内部的进程间通信和内存副本是当前 FTL 实现的主要瓶颈。
![]()
图 7. (a)显示,只有大约 18% 的 CPU 执行时间用于实际的模型训练。关于数据加密的影响如(b)所示,当前的加密方法增加了 2 倍 以上的计算工作量。
作者首先解释了为什么在 FTL 中数据传输时间增加了 16 倍以上(见图 6(c))。作者认为有以下两个原因。首先,FATE 中利用同态加密的典型算法 Paillier[9]来实现数据加密。Paillier 将单个数字的大小增加到 1024 位(通常情况下为 64 位)。因此,加密后要传输的数据总体大小大大增加。其次,FTL 需要修改模型来建立隐私保护,与分布式机器学习相比,这种处理方式使得 FTL 需要更频繁的数据传输。对于分布式机器学习,参数服务器和工作节点在每次迭代结束时交换数据以更新集中式模型。而对于 FTL 来说,各个参与方需要在每一次迭代的过程中反复进行密集的通信来加密和解密数据。
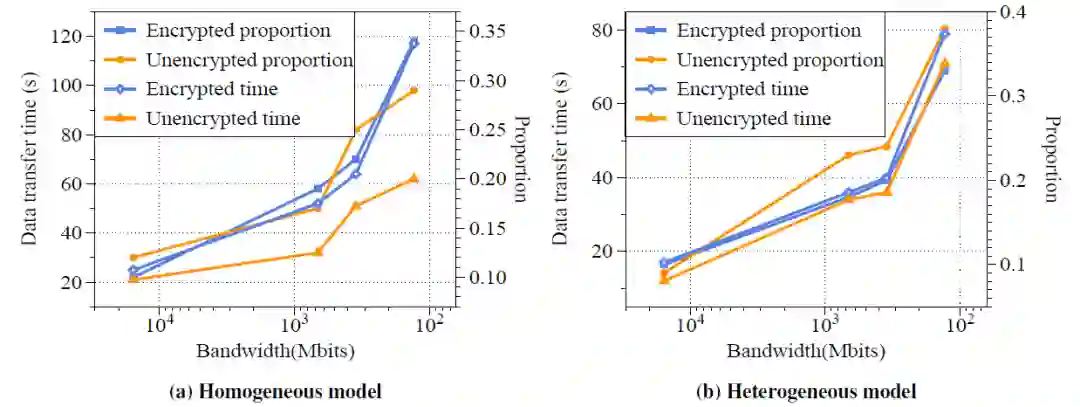
此外,在生产环境中,各个参与方在物理环境中可能并不位于一个数据中心,有时可能会存在较长的物理空间距离。这种物理空间的远距离存储会导致网络带宽出现变化。为了模拟实际案例并评估不同地理级别对 FTL 性能的影响,作者将不同的参与方放在位于美国、北美甚至全球的不同数据中心。图 8 给出了具体实验结果。当各个参与方位于世界各地时,在同质和异构模型中,通过因特网进行数据传输的时间分别占总完成时间的 34%(324s 中的 117s)和 33%(239s 中的 79s)。综上所述,为了使 FTL 实用化,我们还需要解决远距离数据传输的性能问题。
![]()
图 8. 在不同的地理位置设置参与方以模拟真实场景。不同的地理距离导致了带宽的变化。结果表明,随着带宽的下降,数据传输起着更重要的作用。当参与方位于世界各地时,数据传输时间最多会占总完成时间的 34%。
通过以上评估,作者总结了三个瓶颈,并提出了可能的解决方案来帮助优化当前的 FTL 框架:
1、机器内部的进程间通信(Inter-process communication,IPC)占总完成时间的 77%。
这是当前 FTL 实施的主要瓶颈。
进程间的数据交换和内存拷贝会导致极高的延迟。
为了缓解这个瓶颈,下面的一些技术可能会有所帮助。
2、对隐私保护的要求增加了更多的计算开销。问题在于未优化的基于软件的实现消耗了太多的 CPU 周期。近年来,由于 ASIC(如 GPU)或 FPGA(netFPGA)具有强大的计算能力,常被用来加速机器学习框架。例如,微软已经提出了一个成功的解决方案,通过在 FPGA 中实现深度模型来加速分布式 CNN[10]。这些解决方案为我们提供了在 FTL 基础设施中采用特定硬件进行数据加密的启发。
3、由于 FTL 涉及多个数据中心来训练一个模型,所以网络的状况极大影响了 FTL 的效率。各参与方之间密集的通信产生密集的网络流量,容易造成拥塞。对高效网络的需求促使我们探索采用先进的拥塞控制技术来提高数据传输效率的可能性。
2.3、Federated Adversarial Domain Adaptation
![]()
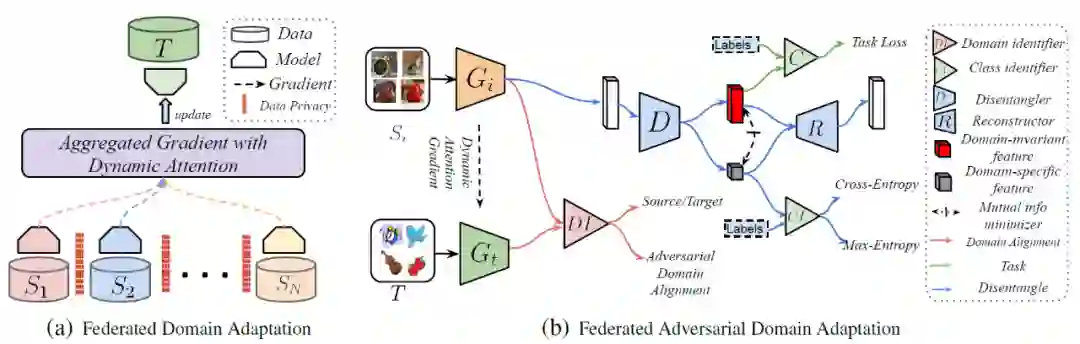
联邦学习在保护各参与方数据隐私性的同时保证了较好的模型训练效果,但是现有的方法忽略了以 Non-IID 方式收集每个节点上的数据的事实,从而导致节点之间的域迁移。例如,一台设备可能主要在室内拍照,而另一台则主要在室外拍摄。室内和室外的光线、背景都不通,所以不同设备中获取的图像数据一定是 Non-IID 的。在本文中,作者拟解决的问题是在无需用户任何额外监督的情况下,将知识从分散的节点迁移到具有不同数据域的新节点。作者将该问题定义为无监督联邦域自适应(Unsupervised Federated Domain Adaptation,UFDA),如图 9(a)所示。
本文聚焦于向联邦学习中引入直推式迁移学习中的领域自适应(Domain Adaption),提出了一种联邦对抗域适应方法(Federated Adversarial Domain Adaptation,FADA),通过对抗性技术解决联邦学习中的域迁移问题,如图 9(b)所示。通过为每个源节点训练一个模型并使用源梯度的聚合更新目标模型来保护数据隐私,与经典联邦学习不同,FADA 在保证数据分散学习模型的同时实现了减少域偏移。首先,作者从理论上分析了联邦域自适应问题,并构建了一个泛化界(Generalization Bound)。基于理论分析的结果,作者提出了一种有效的基于对抗性自适应和表示分离的自适应算法。此外,作者还设计了一个动态注意力模型来处理联邦学习中不同的收敛速度问题。
![]()
图 9. (a) 本文针对 UFDA 问题提出了一种方法,令模型在每个源域上分别训练,并利用动态注意力机制聚合其梯度来更新目标模型;(b) FADA 模型学习使用对抗性域对齐(红线)和特征分解器(蓝线)来提取域不变特征。
首先,作者从理论上对联邦域自适应问题的泛化界进行定义。令 Ds 和 Dt 分别表示输入空间 X 上的源和目标分布,以及一个基本真值标记函数 g:X→{0,1}。假设定义为函数 h:X→{0,1},其误差为基本真值标记函数:
![]()
将假设 h 对 Ds 的风险和经验风险分别表示为 ∈_S(h)和 ∈_S^(h)。类似的,h 对 Dt 的风险和经验风险分别表示为 ∈_T(h)和 ∈_T……(h)。分布 D 和 D’之间的散度定义为:
![]()
![]()
![]()
![]()
定理 1
. 设 H 为 VC - 维的假设空间,D^_S 和 D^_T 分别为 Ds 和 Dt 中提取的 m 大小样本的经验分布。对于每个 h∈H,在选择样本时,概率至少为 1-δ:
![]() (1)
(1)
令 Ds 和 Dt 分别表示 UFDA 系统中的 N 个源域和目标域。在联邦域自适应系统中,Ds 分布在 N 个节点上,训练过程中数据不可共享。经典的域自适应算法以最小化下述目标风险为优化目标:
![]()
然而,在 UFDA 系统中,由于安全和隐私的原因,一个模型不能直接访问存储在不同节点上的数据。作者提出为每个分布式源域学习不同的模型:
![]()
![]()
定理 2
. (联邦域自适应的加权误差界)。设 H 是一个 VC 维的假设类,且有:
![]()
(Dt)^ 是由联邦学习系统中每个源域和目标域的 m 大小的样本分别导出的经验分布。对于每个 h∈H,任意权重α,在选择样本时,概率至少为 1-δ:
![]() (2)
(2)
其中, 公式(2)中的界限是从公式(1)扩展而来的,如果只有一个源域存在(N=1),它们是等价的。公式 (2) 中的误差范围涉及多个假设。
在联邦域自适应系统中,不同节点上的模型具有不同的收敛速度。另外,源域和目标域之间的域迁移是不同的,导致一些节点对目标域没有贡献甚至是负迁移。为了解决这个问题,作者提出了动态注意力,它是源域梯度上的一个掩模。纳入动态注意力机制的原理是增加那些梯度对目标域有利的节点的权重,而限制那些梯度对目标域不利的节点的权重。具体来说,利用间隙统计(Gap Statistics)来评估无监督聚类算法(K-Means)对目标特征 f^t 的聚类效果。
![]()
其中,C_1, C_2, ... ,C_k,C_r 表示第 r 个聚类的观测指数,n_r=|C_r|。直观地说,较小的间隙统计值表明特征分布具有较小的类内方差。通过两个连续迭代之间的间隙统计增益来衡量每个源域的贡献,表示在目标模型用第 i 个源模型梯度更新之前和之后,聚类可以改进多少:(I_i)^gain=(I_i)^(p-1)-(I_i)^p,p 表征训练阶段。源域梯度掩模定义为:
![]()
由于域差异的存在,机器学习模型的性能急剧下降。作者提出了联邦对抗性对齐,将优化分为两个独立的步骤,一个特定领域的局部特征抽取器和一个全局鉴别器。具体包括:(1)对于每个域,训练一个本地特征提取器,Gi 对应 Di,Gt 对应 Dt,(2)对于每个(Di , Dt) 源域 - 目标域对,训练一个对抗性域标识符 DI,以对抗性的方式对齐分布。
首先,训练 DI 来识别特征来自哪个领域,然后训练生成器(G_i , G_t) 来混淆 DI。值得注意的是,D 只访问 G_i 和 G_t 的输出向量,而不违反 UFDA 的规则。给定第 i 个源域数据 X^(S_i),目标域数据 X^T,DI_i 的目标定义如下:
![]()
第二步,保持 L_advD 不变,利用下面的目标函数更新 L_advG:
![]()
使用对抗性分解来提取域不变特征,将(G_i , G_t) 提取的特征分解为领域不变特征和领域特定特征。如图 9(b)所示,Di 将提取的特征分解为两个分支。具体地说,首先训练 K 路分类器 C_i 和 K 路类标识符 CI_i,分别基于 f_di 和 f_ds 特征来正确预测具有交叉熵损失的标签,目标函数如下:
![]()
其中,f_di 和 f_ds 分别表示域不变和域特定的特征。下一步中,冻结类标识符 CI_i,并且只训练表征分解器通过生成特定于域的特性 f_d 来混淆类标识符 CI_i,如图 9 所示。这可以通过最小化预测类分布的负熵损失来实现:
![]()
表征分解通过保留 f_di 和消除 f_ds 来实现知识迁移。为了增强分解,最小化域不变特征和特定域特征之间的互信息。为了应对离散变量问题,本文采用互信息神经估计器(Mutual Information Neural Estimator,MINE)利用神经网络来估计互信息:
![]()
![]()
![]()
域不变的和域特定的特征被转发到一个具有 L2 损失的重构器来重建原始特征,从而保持表征完整性,如图 9(b)所示。通过调整 L2 损失和互信息损失的超参数,可以实现 L2 重构和互信息量的平衡。
本文所提出的模型接受端到端的训练。使用随机梯度下降法训练联邦对齐和表征分解分量。联合对抗性对齐损失和表征分解损失与任务损失一起最小化。算法 1 给出了具体的训练过程。
![]()
作者在以下数据库中进行了实验:数字分类(digit Five)、目标识别(Office-Caltech10、DomainNet)和情感分析(Amazon Review)。
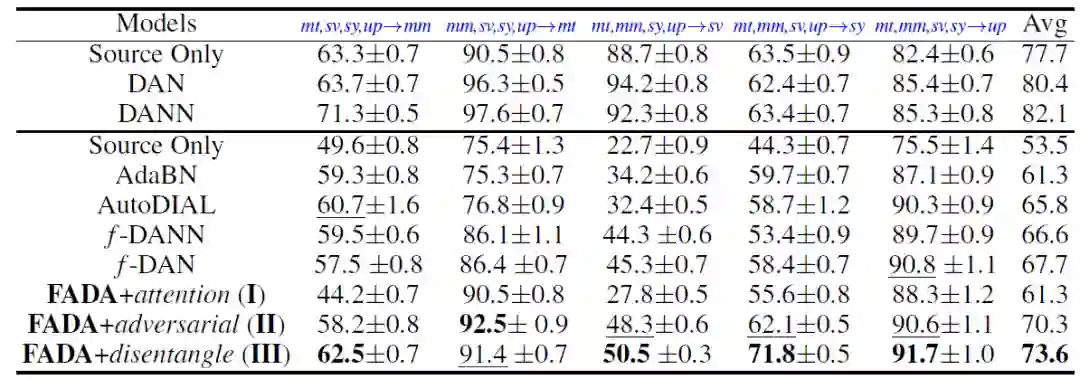
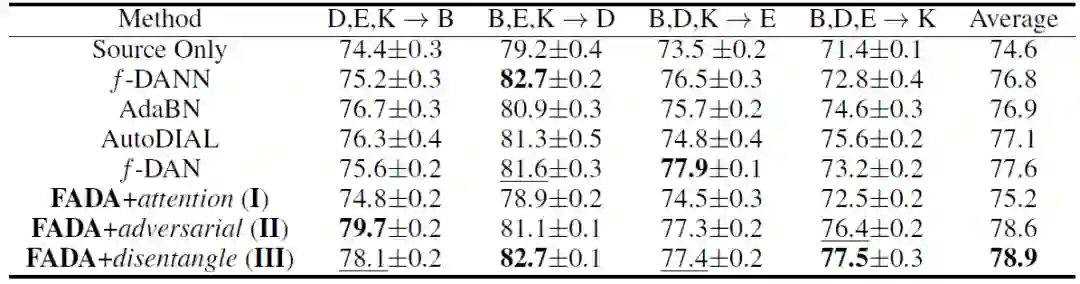
首先,关于 Digit Five 数据库中的结果见表 1。从表 1 结果中可以得出以下结论:(1) 模式 III 达到 73.6% 的平均准确率,显著优于其它基线算法。(2) 模式 I 和模式 II 的结果证明了动态注意力机制和对抗性对齐处理的有效性。(3) 与多源域适应相比,联邦域适应显示出的结果要弱得多,这表明 UFDA 非常具有挑战性。
表 1. 使用 UFDA 协议的 “Digit Five” 数据集的准确率(%)。FADA 达到 73.6%,优于其他基线方法。逐步调整 FADA 模型中的每个组件,目的是研究它们对最终结果的有效性。(模式 I:动态注意力机制;模式 II:I + 对抗性对齐;模式 III:II + 表征分解。mt、up、sv、sy、mm 是 MNIST、USPS、SVHN、合成数字、MNIST-M 的缩写)
![]()
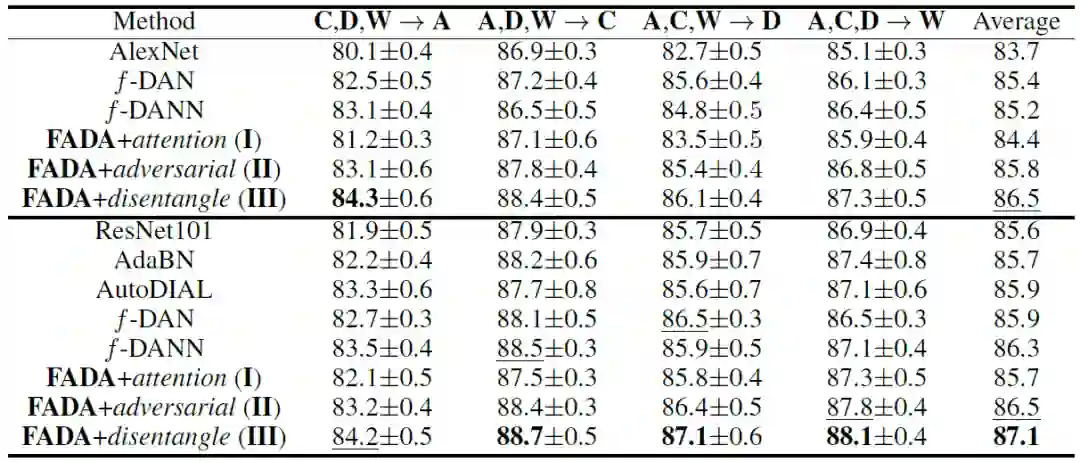
其次,Office-Caltech10 数据库中目标识别的实验结果见表 2。作者使用与基线方法相同的神经网络主干结构,并分别给出了实验结果。结果表明:(1)采用 AlexNet 网络结构时,FADA 模型的准确率为 86.5%,而使用 ResNet 网络结构的准确率为 87.1%,优于其它基线方法。(2) 当选择 C、D、W 作为目标域时,所有模型的性能都是相似的,但当选择 A 作为目标域时,性能较差。这一现象可能是由于 A 中的图像是从亚马逊网站中收集的并包含白色背景。
表 2. 使用 UFDA 协议的 Office-Caltech10 数据集的准确率(%)。上表显示了 AlexNet 的结果,下表显示了 ResNet 的结果
![]()
DomainNet 这个数据库包含大约 60 万张图片,分布在 345 个类别中(http://ai.bu.edu/M3SDA/)。它由六个领域组成:Clipart(clp),一个剪贴画图像集合;Infograph(inf),具有特定对象的信息图图像;绘画(pnt),以绘画形式对物体进行艺术描绘;Quickdraw(qdr),来自世界各地 “Quick raw!” 游戏玩家的图画;真实(rel),真实世界的图像;素描(skt),特定对象的素描图。这个数据库规模非常大,包含了跨不同域的信息丰富的视觉线索,为无监督的联邦域自适应提供了一个良好的实验平台。
在 DomainNet 上的实验结果如表 3 所示。FADA 在 AlexNet 和 ResNet 网络结构中分别达到 28.9% 和 30.3% 的准确率。在这两种情况下,FADA 都优于基线对比方法,从而证明了 FADA 在大规模数据库上的有效性。值得注意的是,DomaiNet 数据库包含大约 60 万个图像,因此即使性能提高百分之一也是非常困难的。从实验结果可以看出,当选择 infograph 和 quickdraw 作为目标域时,所有模型的性能都不理想。这种现象主要是由于 inf/qdr 域与其它域之间存在较大的偏移所引起的。
表 3. UFDA 协议下 DomainNet 数据集的准确率(%)。上表显示了 AlexNet 的结果,下表是 ResNet 的结果
![]()
Amazon Review 数据库的实验结果如表 4 所示。FADA 达到了 78.9% 的准确率,并且优于进行比较的基线方法。结果表明:(1)FADA 不仅对视觉任务有效,而且对 UFDA 学习模式下的语言任务也有很好的效果。(2) 从模式 I 和模式 II 的结果可以看出,动态注意力机制和联合对抗对齐处理有利于提高系统的性能。然而,从模式 II 到模式 III 的性能提升是有限的。这一现象表明,语言特征比视觉特征更难理清。
表 4. UFDA 协议下 Amazon Review 数据集的准确率(%)
![]()
本文首先提出了一个新的无监督联邦域自适应(UFDA)问题,并推导了 UFDA 的理论泛化界。受理论分析结果的启发,作者提出了一种新的联合对抗域适应(FADA)模型,通过一种新的动态注意力模式将从分布式源域学习到的知识迁移到未标记的目标域。此外,本文证明了表征分解可以提高 FADA 在 UFDA 任务中的性能。最后,作者还对 UFDA 视觉和语言基准进行了广泛的实验评估,证明了 FADA 对多个域适应问题的有效性。
2.4、Federated Transfer Learning with Dynamic Gradient Aggregation
![]()
本文为微软的研究成果,介绍了一个联邦学习仿真平台,该平台的目标应用场景是声学模型训练。作者表示,这是第一次尝试将 FL 技术应用到语音识别任务中。此外,所提出的基于 FL 平台的模块化设计可以支持不同的任务。作为平台的一部分,本文提出了一种新的分层优化方案和两种梯度聚合方法,使得训练收敛速度比其他分布式或 FL 训练算法提高了近一个数量级。分层优化除了提高收敛速度外,还为训练过程提供了额外的灵活性。在分层优化的基础上,作者提出了一种基于数据驱动的权重推断的动态梯度聚合算法。这种聚合算法可以用作为梯度质量的正则化器。
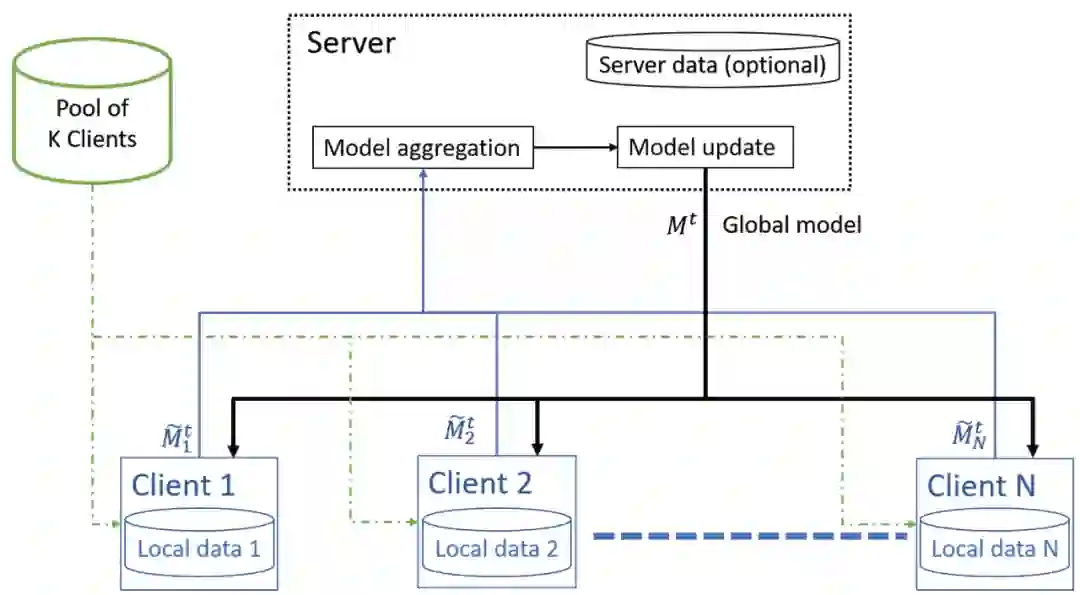
如图 10 所示,本文提出的平台由一个 K(远程)客户机池组成,每个客户机都拥有固定的本地数据库。与分布式训练(Distributed Training,DT)相反,训练数据不是在每一个 epoch 之后都进行重组,而是针对每个任务固定数据分离设置。每次迭代 t 中处理随机抽样的 N<<K 个客户机,并将它们返回到池中进行随机抽样并替换操作。仅使用这些 N 个客户机而不会影响总的处理性能,此外,限制对 N 个节点的处理可以减少迭代之间的延迟,并增强对恶意节点或攻击的鲁棒性。当完成对 N 个客户机的处理后,聚合更新模型,计算全局梯度值。在下一个迭代 T+1 开始之前,利用该梯度值更新全局模型。
![]()
本文所使用的 FTL 平台能够真实的模拟一个 FL 系统,但是不能实现加密或恶意节点攻击之类的功能。由于本文所考虑的语音识别(Speech Recognition,SR)模型规模较大,作者通过利用多个 GPU 的方式对平台进行了改进,以便将训练时间控制在小时或数天的数量级,而不是几周或几个月。此外,该平台使用固定的、数量非常少的 GPU,以支持任意数量的客户机。
FTL 平如全局模型、优化器参数和客户机特定数据集的标识符等)完成训练过程。在为该客户机执行训练后,工人结点将不敏感隐私的结果(即本地训练的模型和训练损失)发送回中央服务器。然后,中央服务器更新可用资源字典以及尚未处理的客户机。这个简单的调度过程一直持续到所有 N 个客户机都被处理完。为了保留服务器上的内存,客户机模型在由工人结点返回时以流方式聚合。一旦计算出聚合模型,中央服务器将使用它来更新全局模型,然后继续进行下一次迭代。
2.4.2 分层优化(Hierarchical Optimization)
FL 中常用的优化方法为小批量优化(Mini-batch optimization),例如经典的 FedAvg 等。本文提出了一种不同的方法:分层优化方法。训练过程包括两个优化步骤:首先,在客户机使用 “局部” 优化器,然后在中央服务器端使用 “全局” 优化器,利用聚合的梯度估计值。两层优化方法结合了 FedAvg 的优点和在中央服务器端进行二次优化带来的额外加速优势。此外,梯度聚合处理也是有益的,因为每次迭代会包含更多的数据。本文所提方法的完整流程见算法 1。
![]()
令 j^ th 表示客户机执行第 t 次迭代,以学习速率η_j 局部更新种子模型(w_T)^s:
![]()
第 j 个客户机返回平滑的局部梯度(g_T)^j,该梯度计算为最新更新的局部模型和之前全局模型之间的差:
![]()
由于直接计算 g_T 非常困难,一般通过加权和聚合方式计算它的近似值:
![]()
![]()
在更新过程中,种子模型会与原始任务越来越偏离。为了保证与先前任务的兼容性,作者在模型聚合和更新之后,在服务器端提出了一个针对已保存数据(与所讨论的任务相匹配)的训练步骤。模型更新在与能够保证数据匹配的方向上进行正则化。模型的这种 “温和” 更新处理可以避免与目标任务偏离太多。这对于各个参与方所拥有的数据是不平衡的和 / 或非常异构的情况尤其有用:
![]()
分层优化算法使训练的收敛速度提高了 2 倍,同时对平台的性能没有产生任何负面影响。此外,由于模型在每个客户机和迭代中传输两次,因此能够显著降低通信开销。
在许多 FL 场景和 SR 应用中,并不总是可以获得大量准确的可用的有标签数据。在这种情况下,有效的无监督训练至关重要。本文采用了两种无监督训练方法:利用多个假设和基于可用的本地文本。
第一种方法将语音识别器的 N 个最佳假设设置为一系列软标签(Soft Labels)。结果表明,这种 N - 最佳假设的方法,即使 N 相对较小,也能覆盖 90% 左右的正确标签。作为多任务训练的一部分,使用软标签对网络进行更新,其中每个任务的损失基于 DGA 算法(2.4.4 章节中进行详细阐述)进行加权处理。
第二种方法是采用基于从文本到语音(Text To Speech,TTS)的音频分层模型。该方法使用来自 TTS 的音频和随机采样语音的混合作为输入。首先,将 seq2seq 模型与组织级别的相关数据相适应,然后以联合的方式对特定于会话的数据进行调整。第一步创建一个新的种子模型,该种子模型用作在每个会话的 TTS 数据上运行上述 FTL 的起点。基于 TTS 的数据导致 seq2seq 模型显著偏离于原始模型,因此使用随机抽样的 “真实” 数据正则化处理训练过程。
在前文分析的过程中,需要对出现偏离的梯度进行专门的处理。类似的,在聚合阶段也对梯度进行加权处理,该方法被称为动态梯度聚合(Dynamic Gradient Aggregation,DGA)。本文提出了两种不同类型的 DGA 方法:一种是以训练损失作为加权系数的 “确定性” 方法,另一种是 “数据驱动” 方法,即训练神经网络来推断权重。在某些任务中,加权聚合对整体词错误率(Word Error Rate,WER)指标没有显著影响,但它使训练收敛速度显著加快。另一方面,无论是在标签质量可能发生显著变化的无监督训练情况下,还是在 FL 场景中经常出现的多样化局部数据情况中,DGA 算法都会显著影响收敛速度和分类性能。加权过程可以看作是一种正则化处理,目的是弱化梯度方向的影响。这样处理后,反向传播能够基于噪声较小的小批量梯度进行更新。作者提出,可以使用一个 Softmax 层来规则化处理权重:
![]()
其中,β称为该 Softmax 函数的温度(Temperature),温度可以调节梯度分量权重的聚合程度。
第二种方法基于强化学习来实现。使用一个网络来推断权重,并根据稀疏的、时间延迟的标签进行奖励训练。这种方法称为“RL 加权”(或 RL-DGA)。用于训练 Agent 的奖励取决于 Agent 所采取的行动 Action 有多好,通常它是基于一个特定的、预先确定的奖励政策。Agent 根据这种奖励策略采取行动,以优化与环境的交互作用,同时为系统引入新的状态。然后,在这种新状态下获得更新的观察值和新的奖励。基于主动强化学习,奖励直接取决于选择的行动。通过利用强化学习,使用神经网络 RL 根据来自每个客户机的一组输入特征(x_T)^j(或对等的观察值)来推断权重。Agent 决定梯度权值,以提高模型的字符错误率(Character Error Rate,CER)性能。
作者提出了一种以训练损失系数和梯度统计量为输入的学习最优加权策略的端到端系统。网络根据其产生的结果(即在每一时刻 T 的验证集上的 CER)来预测下一步的“动作”。RL 通过学习一系列的动作引导 Agent 最大化其目标函数(策略)。完整过程见算法 2。
![]()
奖励策略基于两个不同网络的 CER 性能,这两个网络是使用聚合梯度训练的。在使用推断权重或基于 Softmax 的权重进行训练后,这两个网络是同一种子模型的不同版本。根据比较结果,给定一个奖励 r_T 估计新状态 s_(T+1)。阈值和奖励参数θ、R 是奖励策略的一部分,详见算法 2。输入特征(x_T)^j 是由梯度幅值均值和方差值增强处理后的训练损失系数的组合。在局部训练迭代过程中,基于所有参数梯度值估计梯度相关系数。
与其他机器学习方法不同,强化学习不需要监督而只需要一个奖励信号。而且,强化学习中的反馈可以延迟:它不像在有监督学习算法中那样必须是即时的。数据是连续的,Agent 的操作只影响它接收的后续数据。由于这种近似不稳定,作者引入了一个回放记忆(Replay memory)。从回放记忆中随机使用小批量而不是使用最近的翻译作为训练样本,这就解决了后续训练样本的相似性问题。如果不采取这样的处理方法,后续处理会使神经网络陷入局部最小值,进而过早地结束训练过程。
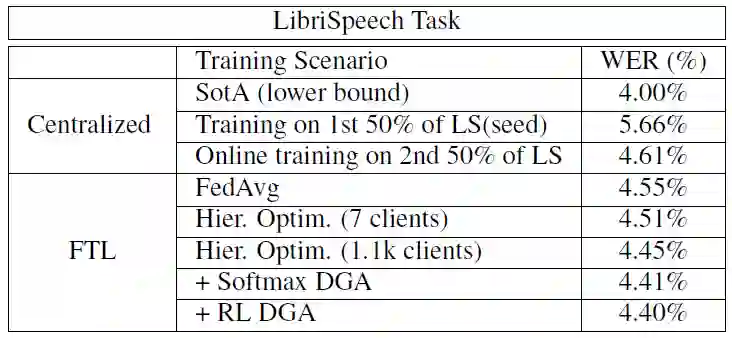
本文基于两个数据库进行实验:LibriSpeech 任务(LS 任务)用于有监督训练,基于 Powerpoint 演示文稿的内部数据库用于无监督训练。对于有监督实验,将训练数据分成两部分,每个部分 460 小时,这两部分中没有的交叉的说话人。第一部分用于训练种子模型后不再使用。利用数据库的第二部分模拟 FL 条件下的在线训练。对于 FL 训练过程,将遵循两个不同的方向:首先,将训练集分成 7 个不同的部分,不再重新混杂数据(与 DT 方法相反)。第二个方向是根据 1100 个说话人标签分离数据。每个分区(K=7 或 K=1.1k)分配给一个客户机。在 FTL 框架中,所有客户机都不知道其余的客户机,只有中央服务器 “知道” 使用了哪些客户机以及随机抽样确定参与聚合的客户机。在本文实验中,抽样的客户机数量 N 从 25 到 400 个不等,N 越大越好,但总体性能波动较小。
表 5 给出 LibriSpeech 任务的实验结果。其中,前 3 行为集中训练的结果,性能下界为对整个数据库进行训练的模型(离线训练)结果。第二个模型(“online training”行)是基于种子模型的结果,最初对前半部分数据进行训练直到收敛。模型是用第二部分数据在线训练的。然后,实验研究了模拟 FL 条件的第二种场景,通过对未知数据的训练,进一步改进了 FL 方式下的种子模型。实验研究了模型聚合的不同策略,如模型平均(表中的 FedAvg)行)或使用优化程序(如 Adam、LAMB、LAR 和 SGD)进行分层优化。对于 FedAvg 系统,在中央服务器端执行模型平均,而在客户机端使用 SGD 优化器进行训练。此外,实验还研究了中央服务器 / 客户机优化器的组合。
![]()
表 5. LibriSpeech 任务的实验结果,使用注意力模型进行离线 seq2seq 训练。
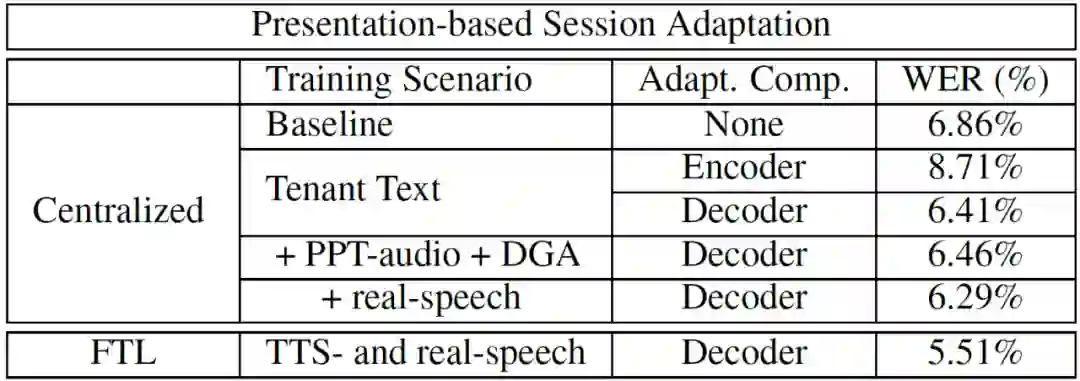
在无监督训练的情况下,本文方法为分层调整 seq2seq 模型:首先将种子模型与承租方数据相适应,然后基于 FTL 平台进行会话适配。这里使用的数据库由 TTS 数据和已用于训练 seq2seq 模型的真实语音随机样本组成,使用真实数据可防止模型过度拟合 TTS 数据。测试库基于四个 presentation,每次约 40 分钟,共有 1230 个句子,12k 个单词,词汇量为 2.5k 个单词。演示幻灯片中的文本数据也用于合成语音数据,总大小为 1.3 小时。作为初始模型,使用了基于 75k 小时数据训练的 LAS 模型。种子模型采用集中式的方式使用文本数据生成的 TTS 数据进行调整。当种子模型根据承租方文本数据进行了适配调整,它就可以被用作第二个自适应步骤的起始模型。第二步是基于 FTL 平台进行实验的。新模型使用基于 TTS 的音频迭代适应与 presentation 相关的文本。引入 DGA 方法相应的调整输入梯度的权重。然而,作者在实验中注意到该模型对合成的 TTS 数据的拟合速度非常快,整体性能急剧恶化。为了解决这个问题,作者在中央服务器端的训练中添加了真实的语音数据,以规范训练过程。真实的语音音频是从训练集中随机选取得到的。该真实语音音频数据集合的加入在提高整体识别性能的同时,显著降低了模型的恶化趋势。具体实验结果见表 6。实验结果显示分层方法比原始模型性能提高了 20%。作者还研究了 TTS 对说话人声音的适应性(假设 4 个演示文稿中的每一个都对应一个说话人),但是实验结果中并没有展示出额外的性能优势。
![]()
本文提出了一个新的应用于语音识别任务的联邦学习平台。尽管本文中关于该平台的讨论主要集中于 ASR 任务,但是实际上 FTL 平台可以很容易地推广到其他任务,如 FaceID 或 NLU 相关的任务等。目前,作者正在尝试使用 FTL 平台完成其他分类任务。此外,为了应对语音识别任务所特有的挑战,作者还引入了其它的新算法,包括对小批量之间的梯度进行加权处理从而提高收敛速度和改进模型性能等。所提出的梯度聚合方案在数据条件较差的情况下能够作为正则化处理器来弱化批次之间的梯度方向。
在这篇文章中我们重点关注了联邦学习中的联邦迁移学习问题。在回顾联邦学习、迁移学习的基础上,依托四篇文章对联邦迁移学习的基本架构、知识以及应用情况、算法等进行了讨论。其中,第一篇文章是杨强教授关于 FTL 的整体结构、设计思路的详细描述,第二篇文章重点是对目前的 FTL 平台在实际应用中面临的效率问题进行实验对比和分析。后两篇文章介绍了两种 FTL 中的算法,包括对抗域适应和动态梯度聚合等。这两篇文章聚焦的是联邦学习中各个参与方 Non-IID 数据分布情况的一种解决方法,更多的是对算法的描述,实际上未涉及完整 FTL 平台的构建,例如一些加密算法等的应用。
由我们所介绍的文章可以看出,目前完整 FTL 平台在实际应用中还面临很多问题,特别是隐私保护和性能中的一些瓶颈。但是,对于多参与方、小样本数据、数据分布差异大、已标记样本缺乏等大量存在的实际应用场景来说,联邦迁移学习有着非常好的应用价值。后续我们将继续关注联邦学习领域中的更多工作,以期望看到更多的工业场景中 FL、FTL 平台的应用。
[1] Liu Y , Kang Y , Xing C , et al. A Secure Federated Transfer Learning Framework. Intelligent Systems, IEEE, 2020, PP(99):1-1. https://arxiv.org/pdf/1812.03337.pdf
[2] Jing Q , Wang W , Zhang J , et al. Quantifying the Performance of Federated Transfer Learning. 2019. http://arxiv.org/abs/1912.12795
[3] Peng X , Huang Z , Zhu Y , et al. Federated Adversarial Domain Adaptation. 2019. http://arxiv.org/abs/1911.02054
[4] Dimitrios Dimitriadis, Kenichi Kumatani, Robert Gmyr, Yashesh Gaur, Sefik Emre Eskimez, Federated Transfer Learning with Dynamic Gradient Aggregation, August 2020, https://arxiv.org/pdf/2008.02452.pdf
[5] H Brendan McMahan, Eider Moore, Daniel Ramage, and Blaise Aguera y Arcas. Federated learning of deep networks using model averaging. 2016.
[6] Kewei Cheng, Tao Fan, Yilun Jin, Yang Liu, Tianjian Chen, and Qiang Yang. Secureboost: A lossless federated learning framework. arXiv preprint arXiv:1901.08755, 2019.
[7] Pan, Sinno Jialin,Yang, Qiang, A survey on transfer learning. IEEE TKDE, 22(10):1345–1359.
[8] H William. Breast cancer wisconsin (diagnostic) data set. https://archive.ics.uci.edu/ml/datasets/
Breast+Cancer+Wisconsin+(Diagnostic), 1995.
[9] Pascal Paillier. Public-key cryptosystems based on composite degree residuosity classes. In International
Conference on the Theory and Applications of Cryptographic Techniques, pages 223–238. Springer, 1999.
[10] Kalin Ovtcharov, Olatunji Ruwase, Joo-Young Kim, Jeremy Fowers, Karin Strauss, and Eric S Chung. Accelerating deep convolutional neural networks using specialized hardware. Microsoft Research Whitepaper, 2(11):1–4, 2015.
本文作者为
仵冀颖,工学博士,毕业于北京交通大学,曾分别于香港中文大学和香港科技大学担任助理研究员和研究助理,现从事电子政务领域信息化新技术研究工作。主要研究方向为
模式识别
、计算机视觉,爱好科研,希望能保持学习、不断进步。
关于机器之心全球分析师网络 Synced Global Analyst Network
机器之心全球分析师网络是由机器之心发起的全球性人工智能专业知识共享网络。在过去的四年里,已有数百名来自全球各地的 AI 领域专业学生学者、工程专家、业务专家,利用自己的学业工作之余的闲暇时间,通过线上分享、专栏解读、知识库构建、报告发布、评测及项目咨询等形式与全球 AI 社区共享自己的研究思路、工程经验及行业洞察等专业知识,并从中获得了自身的能力成长、经验积累及职业发展。
感兴趣加入机器之心全球分析师网络?点击阅读原文,提交申请。