解密Kernel:为什么适用任何机器学习算法?

作者 |
译者 | 陆离
编辑 | 一一
出品 | AI科技大本营(ID:rgznai100)
机器学习中Kernel的秘密(一)
本文探讨的不是关于深度学习方面的,但可能也会涉及一点儿,主要是因为 Kernel(内核)的强大。Kernel 一般来说适用于任何机器学习算法,你可能会问为什么,我将在文中回答这个问题。
一般来说,在机器学习领域中,我们要把相似的东西放在相似的地方。这个规则对所有的机器学习算法都是通用的,不论它是有监督、无监督、分类还是回归。问题在于我们应该如何准确地确定什么是相似的?为了揭示这个问题,我们将从 Kernel 的基础开始学习。
两个向量之间的点积是一个神奇的东西,可以肯定地说,它在一定程度上度量了相似性。通常在机器学习的文章中,点积表示成以下形式:
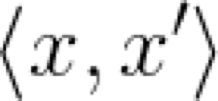
这表示了向量x和x'之间的点积。注意,为了简便起见,此处省略了向量符号的箭头。这个符号是向量分量乘积之和的简写:
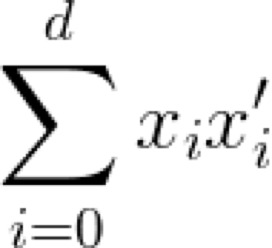
巧合的是,向量的范数是点积的平方根,可以这样表示:
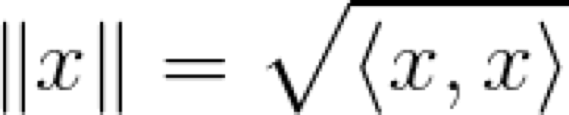
这当然不是全部的。我们肯定知道余弦定理,即点积等于向量之间角度的余弦与它们范数的乘积(这很容易用简单的三角函数来证明):
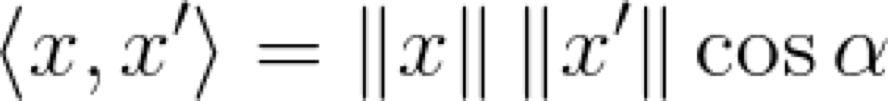
谈论角度和范数的好处在于,我们可以想象出这个点积是什么样子。让我们画一下这两个向量,它们之间的夹角为 α:
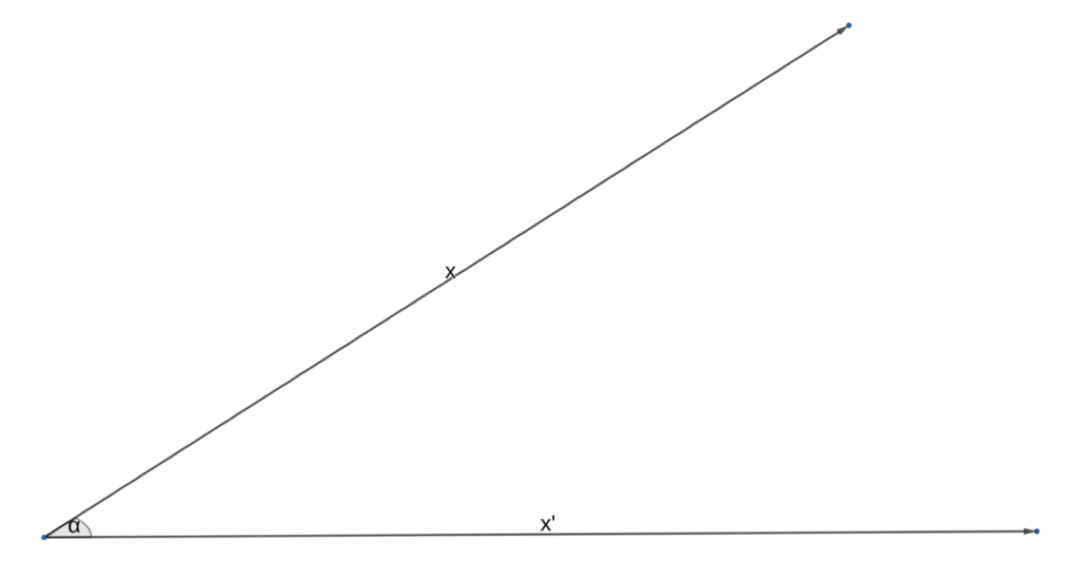
因此,如果我们采用点积作为相似性的度量,那么,它在什么时候会达到最大呢?这意味着是这些向量最相似的时候。显而易见,当余弦等于 1 的时候,就会发生这种情况,也就是当角度为 0 度或者弧度的时候。如果向量的范数都是相同的,那么显然我们讨论的是同一个向量!很好,让我们把目前为止学到的东西写下来:
点积是向量间相似性的度量
现在你应该希望了解一下谈论点积的意义。
当然,点积作为相似性的度量,在实际问题中可能会有用,或者一点儿用也没有,这取决于你要解决的问题。因此,我们需要对输入空间进行某种转换,使点积作为相似性的度量起到实际的作用,用 ϕ 来表示转换。现在,我们可以定义 Kernel 的含义了,映射空间中的点积:
Kernel 的定义非常直接,是对映射空间相似性的度量。实际上,数学家喜欢具体化。由于Kernel 所处理的底层函数和空间不应该存在隐含的假设,因此,通过函数分析 Kernel 背后存在着很多的理论,需要在其它的文章中来探索这方面的问题。简而言之,我们需要明确地说明想以什么样的函数来表示 ϕ:
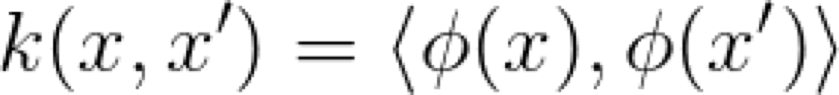
我们需要一个从 X 域映射到点积被定义好的空间的函数,这意味着它是一个很好的相似性度量。
Kernel 可以用作任何在点积过程(或相关范数)中定义的算法的泛化。最有名的是使用 Kernel 作为基础算法例子是支持向量机(Support Vector Machines)和高斯过程(Gaussian Processes),但也有一些是 Kernel 与神经网络一起使用的例子。

我们实际上需要 Kernel 和映射函数 ϕ 的另一个原因是输入空间可能没有定义明确的点积。快速地研究一个文档分析的例子,我们只想根据两个文档的主题来得出它们之间的相似性,然后可能会对它们进行分类。那么,这两个文档之间的点积究竟是什么呢?一种选择是获取文档字符的 ASCII 码,并将它们连接到一个大的向量中 —— 当然,这不是你在实践中要做的工作,而是仅供思考。
我们现在已经将文档定义为向量了,然而问题还是在于文件的长度,即不同文件的长度不同。这没什么大不了的,我们可以通过在较短的文档中填充一定长度的 EOS 字符来应对这个问题。然后我们就可以计算这个高维空间中的点积了。但还有一个问题是,这个点积的相关性,或者更确切地说,这个点积实际上意味着什么。显然,字符的细微变化会改变点积。即使我们用同义词来替换,它一样会改变点积。这是在比较两个文档的主题时要避免的问题。
那么,Kernel 是如何在此发挥作用的?理想的情况下,你需要找到一个映射函数 ϕ 将输入空间映射到一个特征空间,其中点积具有你想要的意义。在刚才文档比较的例子中,对于语义相似的文档,点积值是很高的。换句话说,这种映射应该使分类器的工作更容易,因为数据变得更容易分离。
我们现在可以看一下典型的 XOR 示例来进一步理解概念。XOR 是一个二进制函数,如下所示:
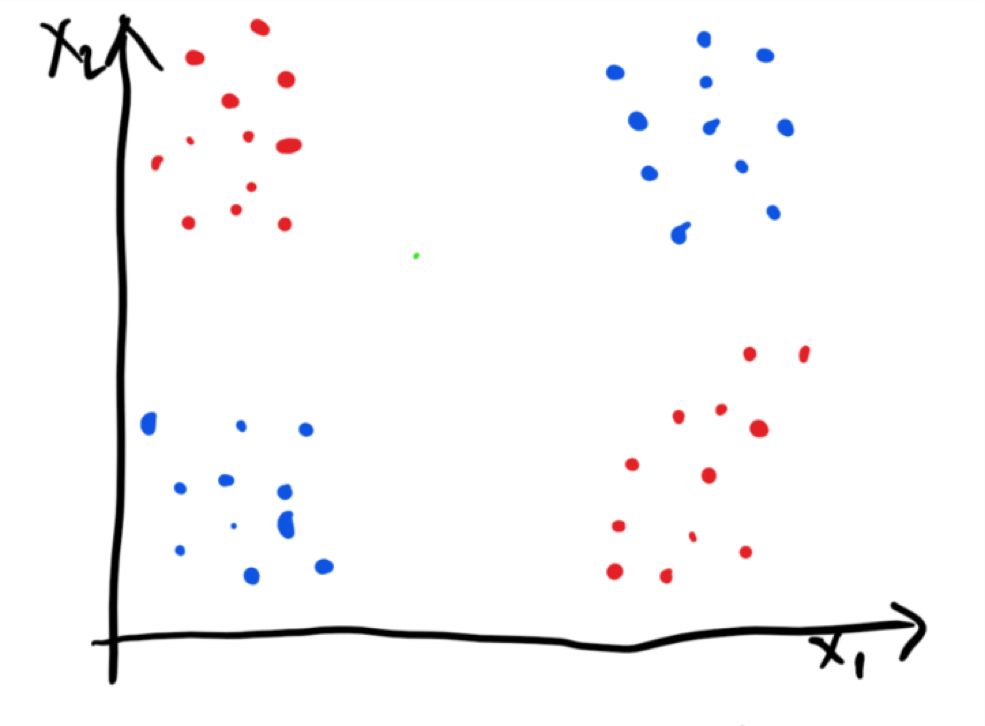
蓝色的点以 0 来分类,红色的点以 1 来分类。我们可以假设这是一个有噪音的 XOR 函数,因为集群的分布范围很广。我们马上注意到了一个问题,数据是不可线性分离的。也就是说,我们不能在红点和蓝点之间划一条线来分离它们。
在这种情况下能做些什么呢?我们可以应用一个特定的映射函数,以使工作变得更容易。具体来说,要创建一个映射函数,它将对通过红点集群的线附近的输入空间进行单侧反射。我们将表示出这条线下面附近的所有点。那么,映射函数将会得到以下结果:
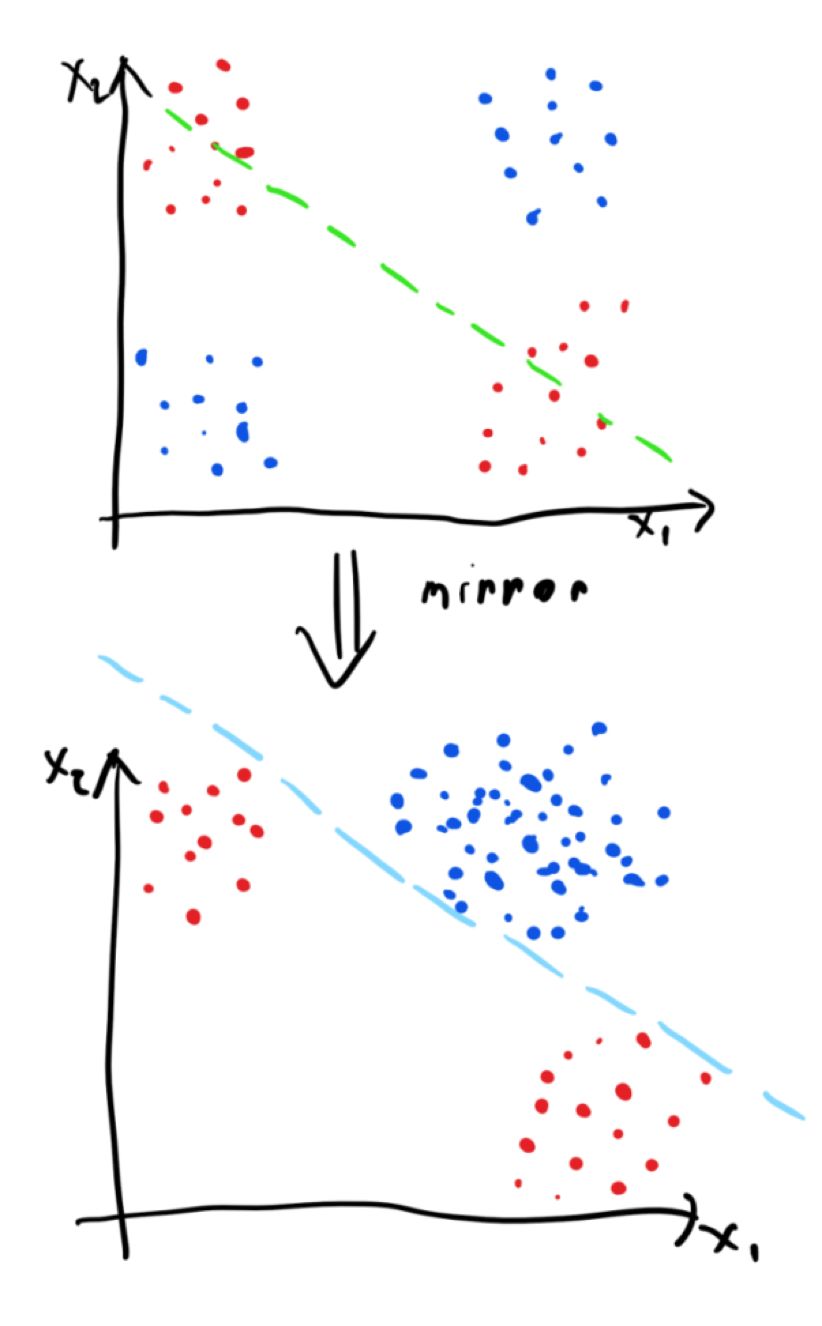
在映射之后,数据会变得很容易进行线性分离,因此如果我们有一个模型试图拟合一个分离的超平面(例如感知器),这就是一个理想的情况。显然,线性可分离很好,但是为了构建有效的模型,我们不一定需要线性可分离的,这就意味着并非所有的映射函数都需要得到线性可分离的数据才能构建有效的模型。
人们时常地混淆使用 Kernel 和使用映射函数的概念。Kernel 函数的输出是一个标量,是对两个点的相似性或相异性的度量,而映射函数的输出则是一个提供相似性计算的向量。Kernel 的有趣之处在于,有时我们可以计算原始空间中映射的点积,而无需显式地进行输入映射。这就允许我们处理无限维度空间的映射!这是一个很难理解的事情,所以我将在后面的文章中进行讨论。
最后,我想推荐一下 Smola 和 Schoelkopf 的书:《Learning with Kernels》。本书对 Kernel 核心及其理论背景进行了全面的阐述。
机器学习中Kernel的秘密(二)
在《机器学习中Kernel的秘密(一)》一文中,我用最简单的方法解释了 Kernel。在读本文之前,我建议你先快速地阅读一下这篇文章,了解一下 Kernel 是什么。希望你能得出这样的结论:Kernel是映射空间中两个向量之间的相似性的度量。
现在,我们可以讨论一些比较有名的 Kernel,以及如何结合这些 Kernel 来构建其它的 Kernel。记住,对于我们将要使用的示例,x’ 是用于绘图的一维向量,我们将 x’ 的值设置为 2。不再多说,让我们开始吧。
线性 Kernel
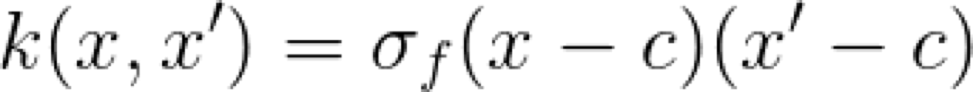
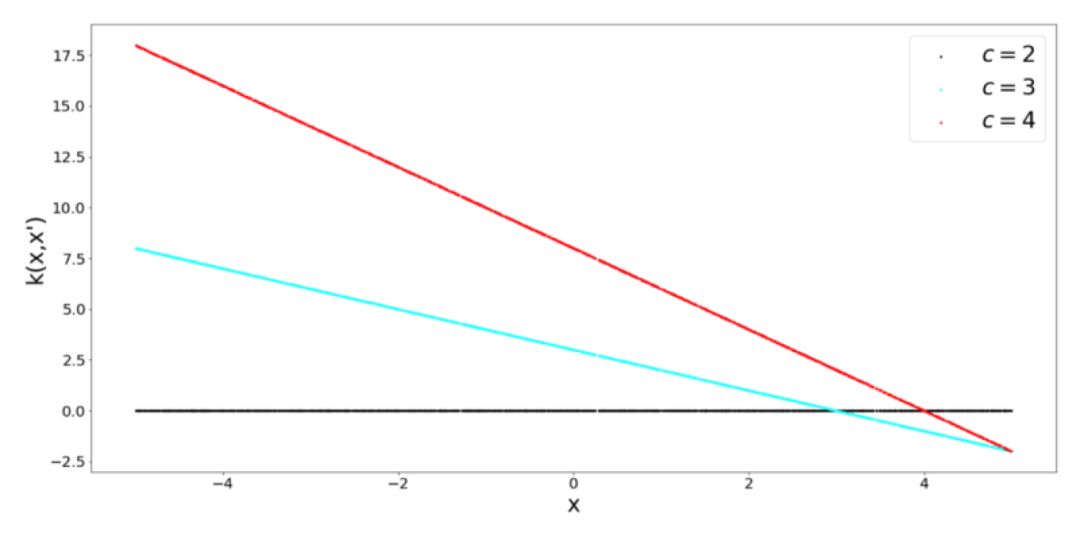
这个 Kernel 的超参数是 sigma 和偏差参数 c。直观地说,这个 Kernel 是什么呢?如果我们取一个特定的 x,并将它与所有其它的 x’ 相比较,就会得到一条直线。这就是它被称为线性 Kernel 的原因。不变的 x 值和变化的 x' 值有效地说明了我们沿着这条直线移动。
这个 Kernel 的另一个特点是,它具有非稳定性,这意味着它的值相对于 x’ 的绝对位置而不是相对位置发生了变化。另一个优点是,由于它是线性的,所以在优化过程中可以进行高效计算。
多项式 Kernel
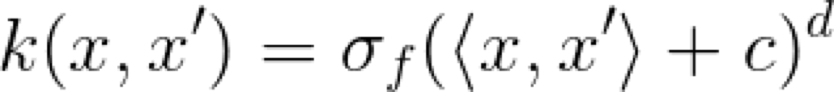
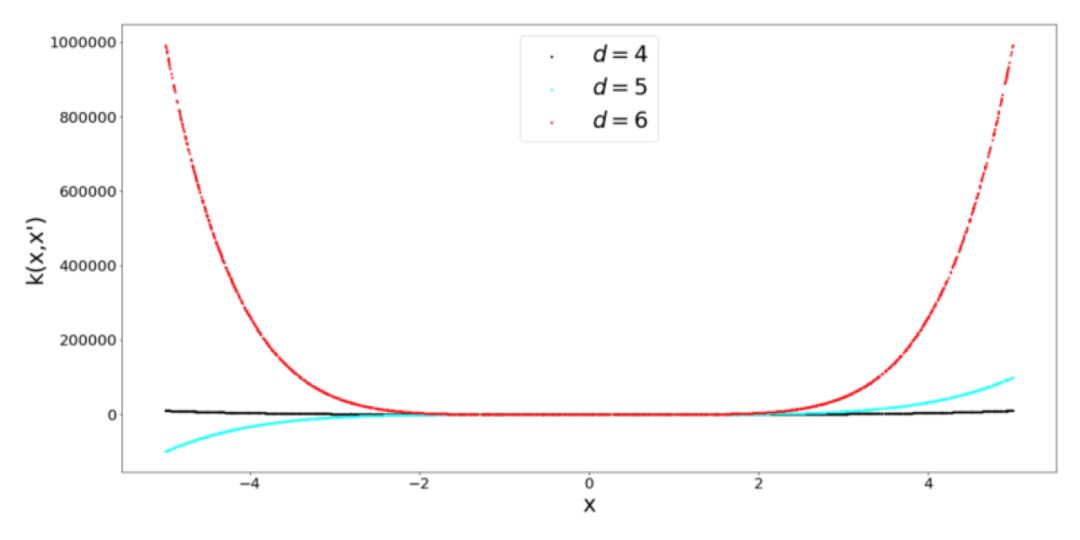
顾名思义,这个 Kernel 是一个带有偏差量 c 的多项式函数。我认为值得花点时间来考虑会产生Kernel 的映射函数 ϕ,因为 Kernel 是在映射空间中的一个相似性函数(点积),所以它会返回一个标量。在二维空间中二阶多项式 Kernel 的映射函数表示如下:
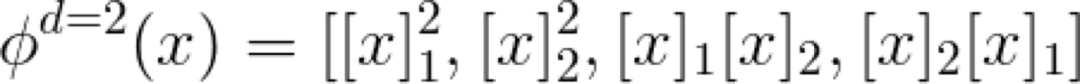
当增大输入维度 d 的值和多项式的阶数时,映射的特征空间就会变得相当大。那么,我们可以计算点积而不是进行转换,如上面的公式中所列的那样。这是 Kernel 理论中许多很不错的公式之一。
径向基函数 Kernel
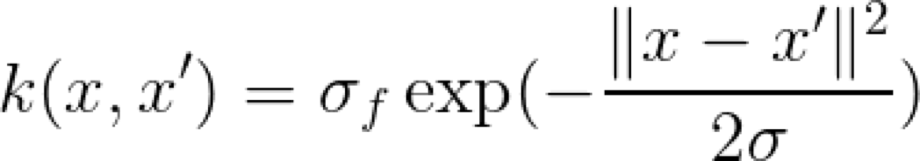
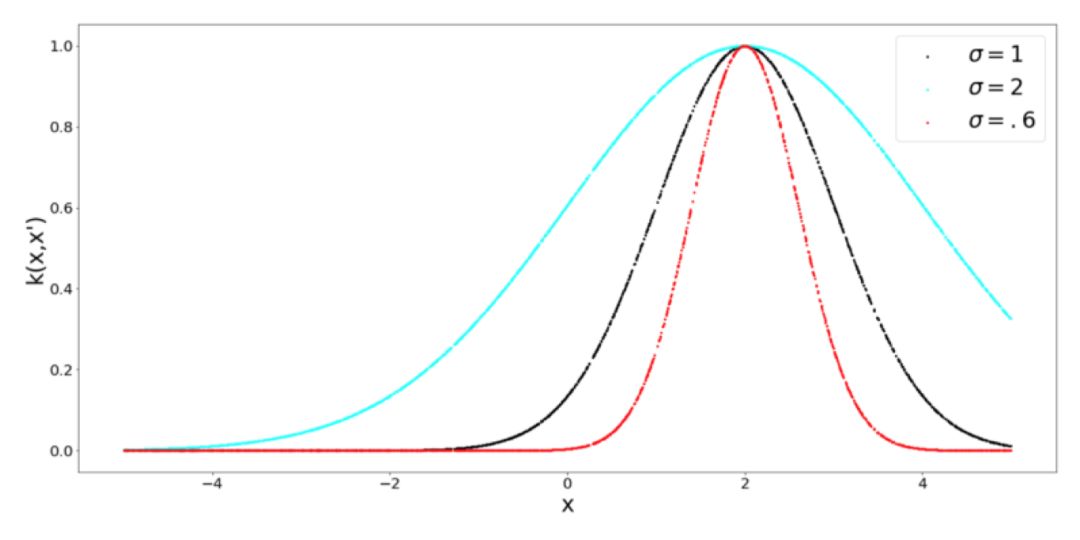
这是一个非常有名的,并经常使用的 Kernel。注意,由于指数中负指数的存在,所以指数的取值要在 0 到 1 范围之间,这是一个不错的特性,因为我们可以说 1 表示非常相似,或者相同,而接近 0 的值则表示完全不同。指数中的参数 σ 控制着 Kernel 的灵敏度。对于较低的 σ 值,我们只期望那些非常接近的点是相似的。对于较大的 σ 值,我们放宽了相似性标准,因为越远的点就越相似。
当然,Kernel 看起来是这样,因为我们把 x 设置为 0,并改变了 x’,逻辑上我们想要计算点之间整个 X 域的相似性。这就得出了一个平面,正是这个平面,才是描述一个 Kernel 的例子:
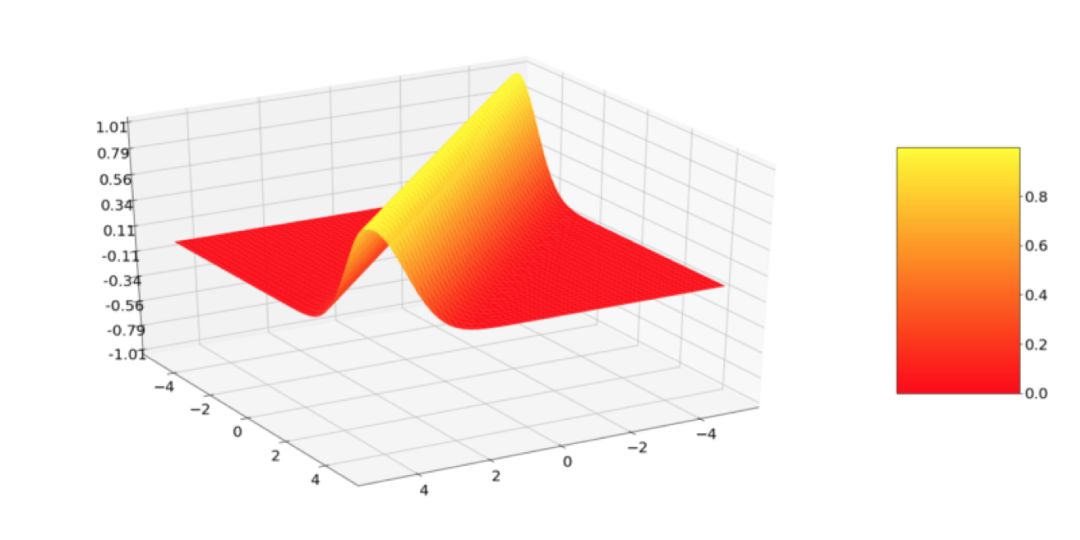
如图所示,Kernel 的值在对角线处最高,其中 x 和 x' 是相同的。
周期 Kernel
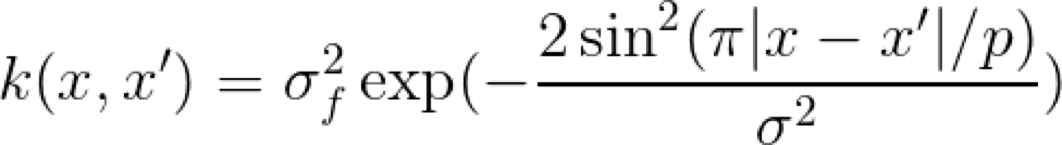
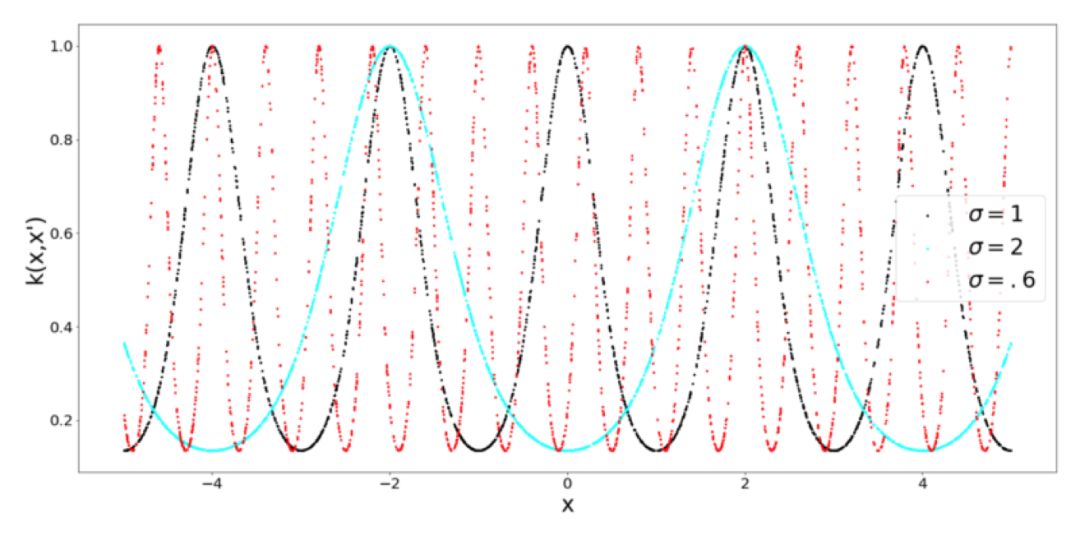
当你考虑周期性的时候,就会马上想到周期函数,比如正弦函数和余弦函数。从逻辑上讲,周期 Kernel 中有正弦函数。Kernel 的超参数 σ 还是表示了相似性的灵敏度,但是我们还有表示正弦函数周期的参数 p。另外,还要注意径向基 Kernel 和周期 Kernel 之间的相似性,它们都被限定为输出 0 到 1 范围之间的值。
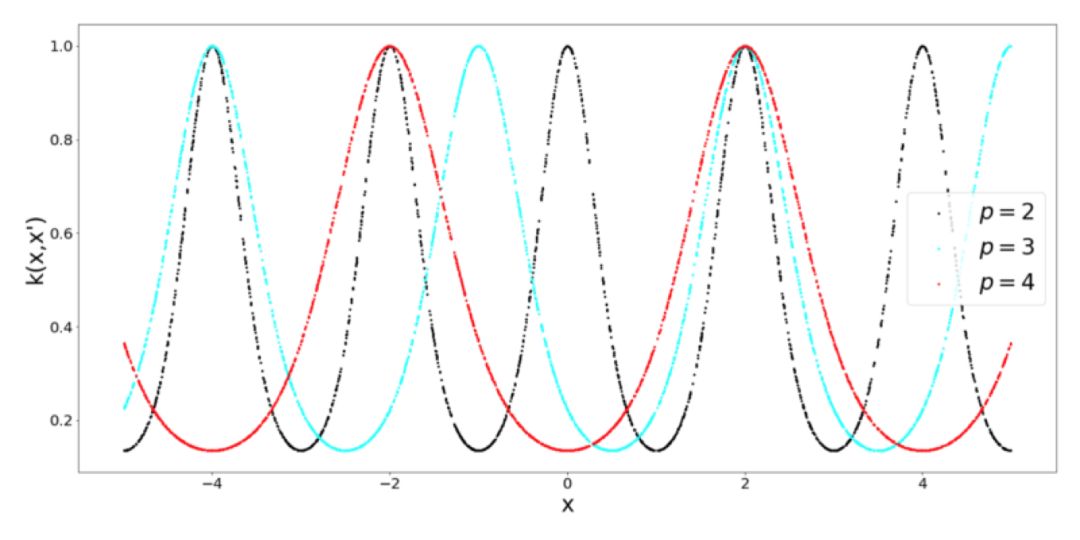
什么时候使用周期 Kernel?这是非常合乎逻辑的,假设你想要为一个类正弦函数建模,从这个函数中取 2 个点,它们相对于欧式距离比较远,这并不意味着函数的值有什么不同。为了解决这类问题,就需要周期 Kernel。为了完整性起见,看看当我们调整周期 Kernel 的周期性时会发生什么(什么也没有):
局部周期 Kernel
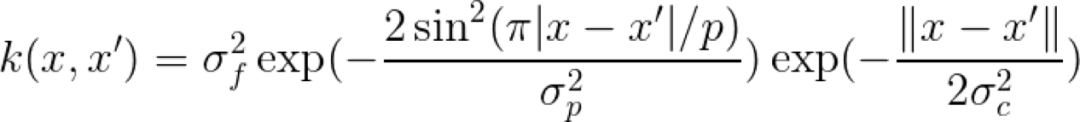
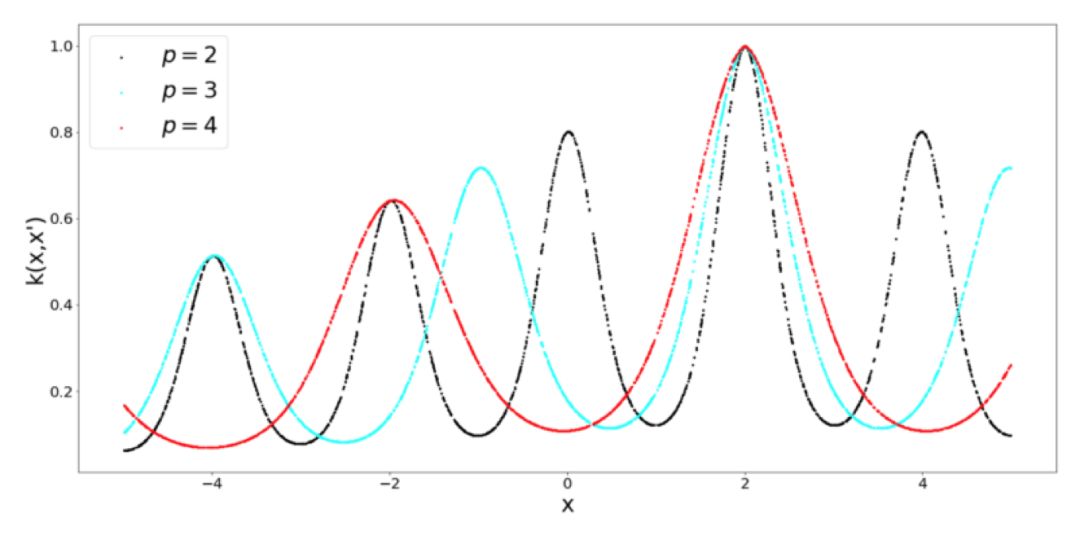
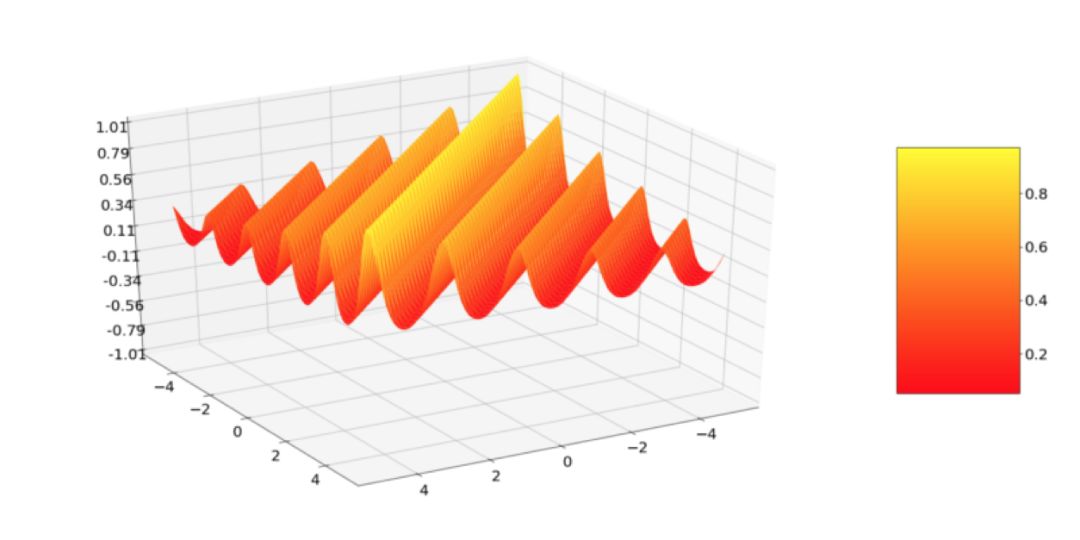
我们基本上是通过径向基 Kernel 与周期 Kernel 的乘积得到了局部周期 Kernel。我们用这个方法得到的结果是,得到的 Kernel 的值随 x 和 x' 之间距离的变化而变化,而不仅仅是随距离的周期性变化而变化,这就导致了所谓的局部周期性。
只是因为我很好奇,用 3D 模式来绘制了这个 Kernel,并得到以下这个还不错的形状:
构建新 Kernel
到现在为止,我们接触到了一些 Kernel 的例子。问题来了,我们拿什么来构建新的 Kernel 呢?Kernel 有以下两个很好的特性:
1. 添加一个带有 Kernel 的 Kernel 会产生一个新的 Kernel;
2. 多个 Kernel 的乘积会产生一个新的 Kernel;
以上两个特性基本上可以让你在不做太多数学运算的情况下构建新的 Kernel,也是非常直观的。乘积可以看作是一个与运算,特别是在考虑 0 和 1 范围之间的 Kernel 时。于是,我们可以将周期 Kernel 与径向基函数 Kernel 相结合,得到一个局部周期 Kernel。
这几个例子,可以让你开始 Kernel 之旅。当然,也还有一些没有被提及的 Kernel。针对实际问题进行的 Kernel 设计是一项非常重要的任务,要想学好它,需要一定的经验。此外,在机器学习中有一个专门用于学习 Kernel 函数的领域。
由于算法上的要求,Kernel 设计也比较复杂。由于许多基于 Kernel 的算法都涉及到一种反向的被称为“Gram”的矩阵,因此我们要求 Kernel 是正定的,但这是我将来要探讨的内容。
现在我们已经了解了一些有用的 Kernel,可以更深入地研究 Hilbert 空间的理论以及它们与Kernel 的关系,但是这必须要等到下一篇文章了。
原文链接:
(上)https://towardsdatascience.com/Kernel-secrets-in-machine-learning-2aab4c8a295f
(下)https://towardsdatascience.com/Kernel-secrets-in-machine-learning-pt-2-16266c3ac37c
(*本文为 AI科技大本营编译文章,转载请微信联系 1092722531)
◆
精彩推荐
◆
想跟NVIDIA专业讲师学习TensorRT吗?扫码进群,获取报名地址,群内优秀提问者可获得限量奖品(定制T恤或者技术图书,包邮哦~)
NVIDIA TensorRT是一种高性能深度学习推理优化器和运行时加速库,可以为深度学习推理应用程序提供低延时和高吞吐量。通过TensorRT,开发者可以优化神经网络模型,以高精度校对低精度,最后将模型部署到超大规模数据中心、嵌入式平台或者汽车产品平台中。


推荐阅读
面试阿里技术岗,竟然挂在第4 轮……


