赛灵思硅谷创新日现场:AI芯片瓶颈凸显,ACAP是破局之法吗?
看点:上周,芯片巨头赛灵思在美国硅谷举行了其首届创新日(Innovation Day),智东西受邀来到现场报道。


8月的硅谷,好不热闹。
在芯片顶会Hotchip结束的第一天,芯片巨头赛灵思同样在美国硅谷举行了其首届创新日(Innovation Day),智东西与少数全球媒体一同受邀参与。

在创新日上,赛灵思CTO兼高级副总裁Ivo Bolsens、赛灵思Fellow Ralph Wittig等一众技术大咖对赛灵思ACAP架构、数据处理与扩展系统架构的未来发展方向、晶体管/封装/互联等话题进行了分享。
这是赛灵思首次将过去10年间对于架构创新与IC设计的创新积累与媒体分享,也是赛灵思CTO及CTO办公室的技术大咖们首次系统性地对外发声,可以说是把不少“压箱底”的干货都拿出来了。

旧神已老,新神未立,架构创新迎来黄金时代

▲赛灵思CTO Ivo Bolsens
赛灵思CTO Ivo Bolsens说,现在业内有一部分人说“摩尔定律死了”,另一部分人说“摩尔定律没死”,双方都有他们的道理。但总的来说,如今芯片厂商在摩尔定律上的投入产出比例已经不如以前了,这是个不争的事实。
摩尔定律既不是一个物理定律、也不是一个自然法则,它只是一条对产业发展前景的预测。
摩尔定律相当于给所有集成电路厂商指明了一条赚钱的方向,它“承诺”,只要集成电路厂商持续投入半导体技术研发,那么每隔18-24个月,就一定能让产品性能提升一倍。
因此,无数厂商愿意为此砸钱、砸资源、重金投入半导体产业研发。毫不夸张地说,在过去50年里,摩尔定律推动着整个半导体产业的创新与发展。
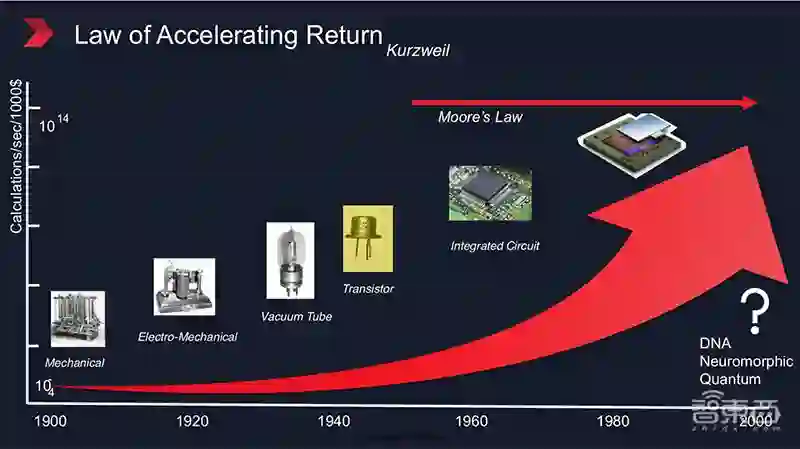
▲摩尔定律的未来在何方?
这也是为什么,近年来围绕着“摩尔定律死了没?”的讨论会让整个半导体产业都陷入一场无休止的口水战。
如果承认摩尔定律不再有效,那也就意味着,当前整个半导体产业都失去了一条明确的增长方向,集体陷入迷茫。以前知道投入这方面研究就一定能赚钱,现在不知道投入哪方面研究才能确保赚钱。
但也正如赛灵思CTO Ivo Bolsens说,无论大家认为摩尔定律是否死了,如今在摩尔定律放缓已经是不争的事实——如今,厂商要投入成倍的资源才能得到原来的性能增长。
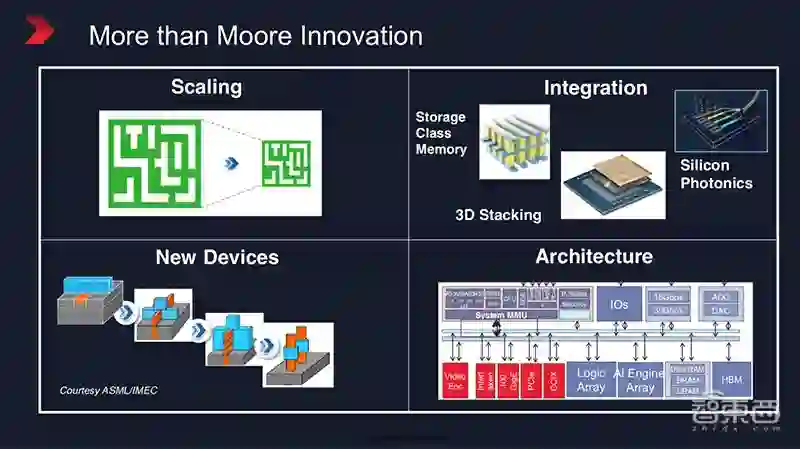
▲新技术层出不穷
为了找到下一个“摩尔定律”,当前所有的芯片巨头都在进行多方面的技术研发,新架构、新材料、新封装技术层出不穷。
尤其是架构创新方面,随着AI算力需求的飙升,以冯诺伊曼“内存墙”(数据存取速度赶不上计算速度)为首的问题进一步凸显,赛灵思、英伟达、英特尔、华为达芬奇、阿里平头哥、以及一大批国内外芯片玩家都开始注重芯片的架构创新,体系结构的新老架构开始交替。
旧神已老,新神未立。这是架构创新的黄金时代。
Ivo Bolsens是赛灵思负责高级技术开发、研究实验室与大学项目的CTO兼高级副总裁,在半导体技术行业有着数十年的经验与积累,为人非常和蔼热情,并且对中国市场抱有极大的肯定。
虽然摩尔定律放缓了,但Ivo Bolsens认为,现在正是最好的时候,“因为以前大家在关注下一个工艺节点,而不愿意尝试新架构。可是现在下一个工艺节点遇到发展困难后,大家开始愿意尝试新技术、新架构,我们那些疯狂的(crazy)、创新的好主意就有了产品化的机会。”
Ivo Bolsens嘴里这个“疯狂的、创新的好主意”,就是赛灵思去年推出的ACAP。
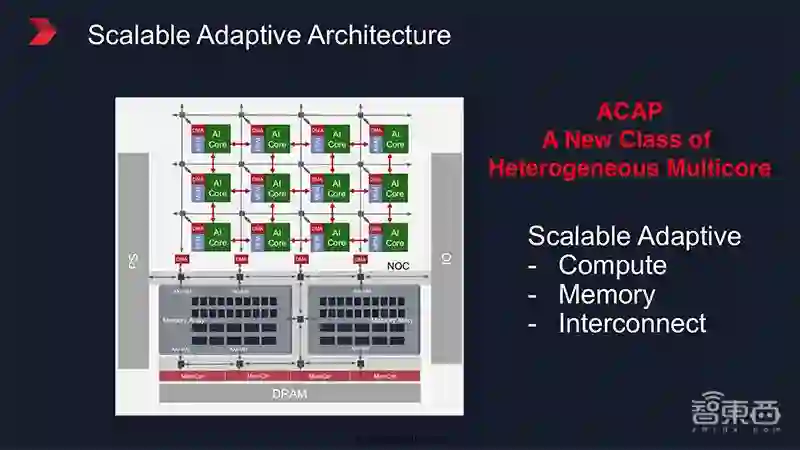
ACAP(念法是“A-CAP”),全称Adaptive Compute Acceleration Platform,翻译过来是“自适应计算加速平台”。这是一款高度集成的多核异构计算平台,与CPU、GPU、FPGA一样,是一类产品的总称。
据赛灵思总裁兼CEO Victor Peng在发布会上表示,ACAP是赛灵思历时4年,动用了1500名工程师,投入超过10亿美元研发而成的。
去年年底,赛灵思首次推出了ACAP架构的首款7nm产品,Versal。今年6月,该款产品正式出货。
“内存墙”问题凸显
在赛灵思的首届创新日(Innovation Day)上,赛灵思Fellow Ralph Wittig对ACAP架构的设计理念进行了深度介绍,其中包括以数据流驱动的多核计算、近内存计算、存储器采用RAM而非Cache等等。

▲赛灵思Fellow Ralph Wittig
这里面既有ACAP当中已经存在的技术,也有赛灵思技术人员正在努力的研发方向。其中,以数据流驱动的自适应多核计算(Adaptable Dataflow Multi-Core)与分布式近内存计算尤为值得关注。
近年来,随着AI算力需求不断飙升,以串行计算为主的CPU难以满足需求,各类巨头/创企纷纷下海进军AI芯片。
随着近年来各类AI芯片、AI计算引擎、神经网络IP的不断发展,现在芯片的AI计算速度已经有了提高了。可是此时,人们进一步发现,传统冯诺伊曼芯片架构的“内存墙”问题开始凸显——AI计算资源丰富,但存储及数据搬运效率低下,导致整体计算效率下降。
数据流驱动+分布式近内存计算
为了解决这一问题,芯片界提出了众多解决方案,其中优化数据搬运路线与近内存计算是当前受到较多认可的两种方式,也是赛灵思ACAP架构的两大亮点。
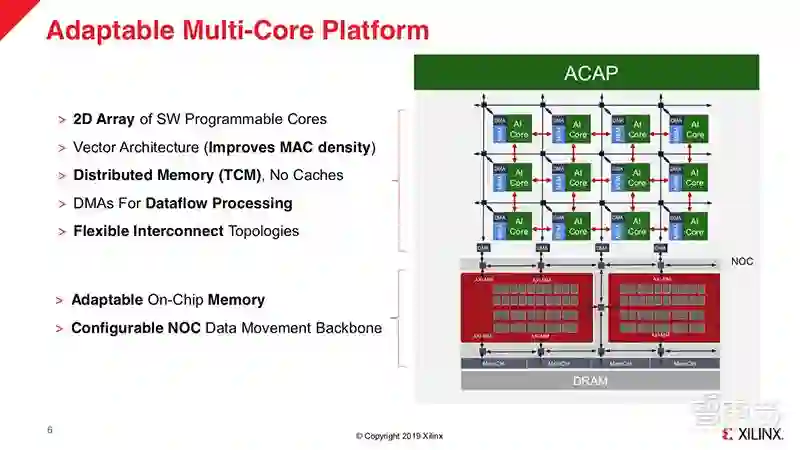
上图是赛灵思ACAP的架构示意图。从图中我们可以看到,它是由多个可编程核心组成的2D Mesh网络,每个可编程核心中都包含了AI主核、本地存储、DMA,并通过片上网络(NoC)实现互连。
传统多核架构是基于Cache的,而在演讲中,Ralph Wittig强调了ACAP中基于RAM的优势,通过这种分布式存储(Distributed Memory)的设计,数据能够通过不同路径,灵活、快速地进行搬运,极大地提高效率。
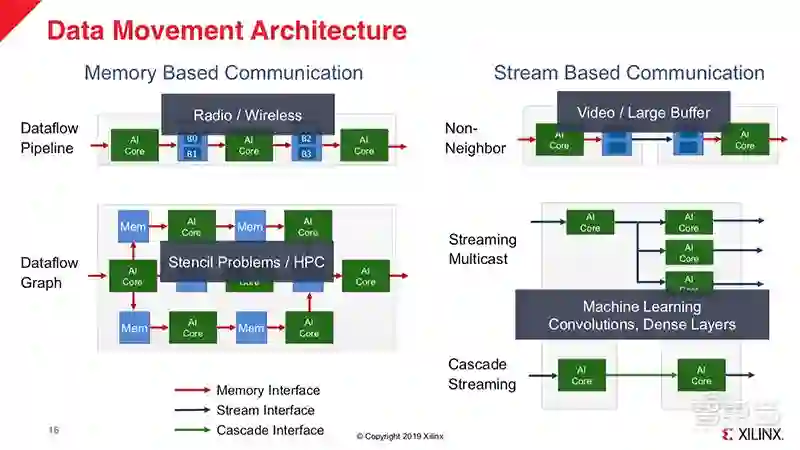
此外,Ralph Wittig还展示了几种不同的数据搬运路径,分别适合用来处理音频、高性能计算、视频、机器学习等。
同时,Ralph Wittig还强调,赛灵思ACAP的“数据流”设计思路是将数据“推(Push)”进计算资源里,而不是让计算资源在使用时才去调取数据。

结语:新型技术百花齐放
无论是进内存计算还是数据流优化,都是当前AI芯片界大热的概念。随着芯片AI计算资源的进一步丰富,如今的行业开始越来越关注数据的搬运效率。除了赛灵思之外,谷歌、Wave Computing、以及国内的探境科技等一众AI芯片企业都在进行这方面的研究。
除了这两项技术外,在创新日上,赛灵思副总裁Ken Chang博士、副总裁Xin Wu、高级总监Patrick Lysaght、赛灵思Fellow Kees Vissers等还对3D-ICs、数据处理与扩展系统架构、晶体管/封装/互联、机器学习与区块链技术、芯片工具及软件生态链等话题进行了深度分享。
正如前文提及的,旧神已老,新神未立。在摩尔定律放缓的当下,各个芯片厂商都在寻找属于自己的路径来推动产业继续发展——尤其是在架构创新方面。当前,赛灵思、英伟达、英特尔、华为达芬奇、阿里平头哥、以及一大批国内外芯片玩家都开始注重芯片的架构创新,体系结构的新老架构开始交替。
这是架构创新的黄金时代。
(本账号系网易新闻·网易号“各有态度”签约帐号)