EMNLP 2019 | 常识信息增强的事件表示学习
论文名称:Event Representation Learning Enhanced with External Commonsense Knowledge
论文作者:丁效,廖阔,刘挺,段俊文,李忠阳
原创作者:廖阔,丁效,李忠阳
下载链接:https://arxiv.org/pdf/1909.05190.pdf
转载须注明出处:哈工大SCIR
1. 简介
事件是现实世界中一种重要的知识,学习有效的事件表示可以提升脚本事件预测等许多下游任务的效果。事件是对客观事实的表达,然而客观事件的发生会对人类的主观情感产生影响,不同事件其背后的意图也有所不同。本文提出学习事件表示时融入人的情感及意图等外部常识知识,以更好地建模事件表示,并在事件相似度、脚本事件预测等任务上取得了优于基线方法的结果。
2. 动机
事件是一种重要的客观信息,事件表示学习将事件信息表示为可计算的低维稠密向量,是人工智能领域一项重要的工作。在之前的研究中,“加性”(Additive)模型是应用最广泛的事件表示方法之一,这一方法将事件论元的词向量相加或拼接后,通过一个网络映射到事件向量空间。进一步地,Ding等人(2015)与Weber等人(2018)提出使用Neural Tensor Network对事件论元进行语义组合,更好地捕获事件论元间的交互信息。
这一系列的工作仍然依赖于词表示学习,难以区分事件之间微妙的差别。一方面,如果两个事件单词重叠较少,如图1(a)所示,“PersonY threw bomb”(某人Y投掷炸弹)和“PersonZ attackedembassy”(某人Z袭击大使馆)会被映射为距离较远的两个向量。另一方面,如果两个事件单词重叠较多,那么即使两个事件关联很小,事件向量也容易具有很高的相似度,如图1(b)所示,“PersonX broke record”(某人X打破记录)“PersonY broke vase”(某人Y打破花瓶)会被映射为距离较近的两个向量。
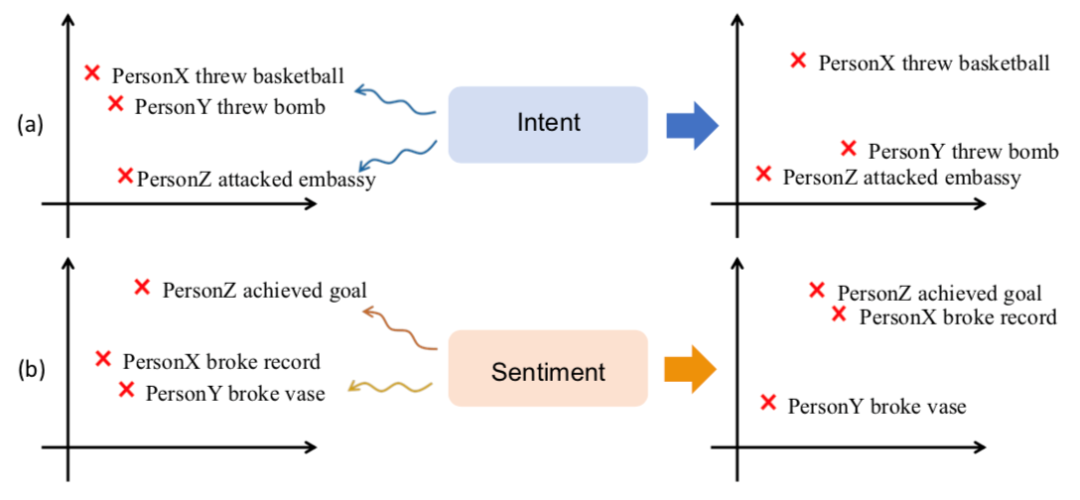
图1 意图、情感信息在判断相似事件中的作用
导致该问题的一个重要原因是缺乏有关事件参与者心理状态的常识信息。在图1(a)中,事件参与者“某人Y”和“某人Z”可能在进行恐怖袭击,因此,两个事件具有相同的意图:“造成伤亡”,这一信息可以帮助模型将两个事件映射到向量空间中较近的位置;在图1(b)中,“打破纪录”的人可能很高兴,而“打破花瓶”的人可能心情沮丧,事件中隐含着参与者的不同情感状态,可帮助将两个事件映射到向量空间中较远的位置。因此,可以使用意图和情感信息对事件表示进行增强。这些常识知识可以从Event2Mind (Rashkin等人,2018)和ATOMIC(Sap等人,2019)常识知识库中获得。因此,我们提出将外部常识知识,例如意图和情感,融入事件表示学习的过程中,以获得更好的事件表示。
3. 方法
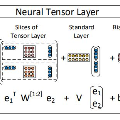
事件表示学习的目标是为事件三元组(A,P,O)学习低维稠密的向量表示,其中P为谓语,A为主语,O为宾语。事件表示模型对谓语、主语、宾语的表示进行组合。我们沿用Ding等人(2015)的方法,使用张量神经网络(Neural Tensor Network,NTN)作为事件表示模型。NTN的结构如图2所示,模型使用双线性变换显式地建模谓语与主语、谓语与宾语及三者间的交互关系。具体公式如下:
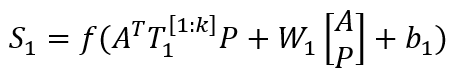
其中,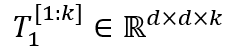
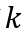

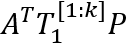
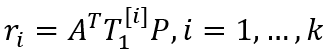
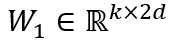
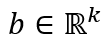
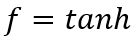
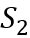
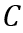
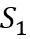
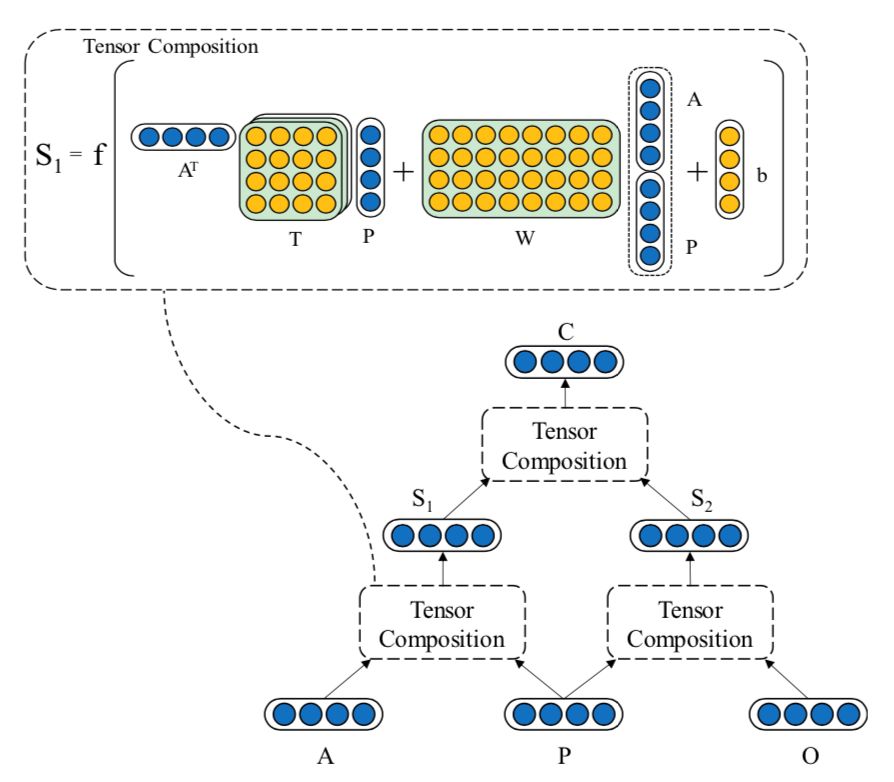
图2 NTN结构
NTN的一个问题是“维度灾难”,因此我们使用low-rank tensor decomposition来模拟高阶tensor以减少模型的参数数量。Low-rank tensor decomposition的过程如图3所示。具体地,将原来张量神经网络中的张量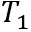
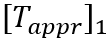
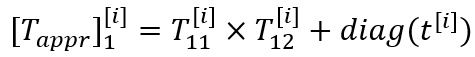
其中,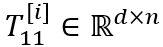
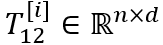
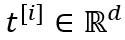
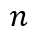
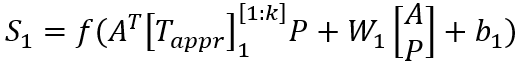
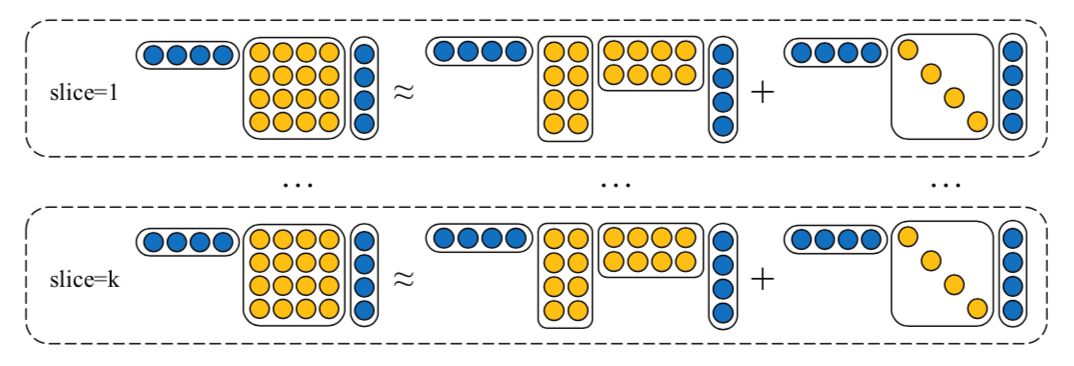
图3 Low-rank tensor decomposition
对于训练集中出现的事件,我们随机将事件的一个论元替换为另一个单词。我们假设原始事件应比替换后的事件具有更高的得分,并计算两个事件的合页损失:
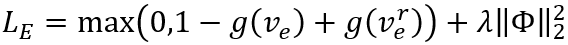
其中,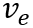
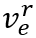
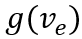
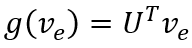
类似地,对于训练集中的每个事件,有一个人工标注的正确意图,我们从所有意图中随机采样一个错误的意图,认为正确的意图应该比错误的意图具有更高的得分。具体地,我们使用双向LSTM得到意图文本的向量表示,并使用意图与事件向量的余弦相似度作为意图得分,计算合页损失:
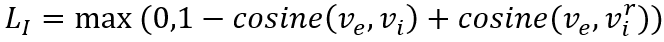
其中,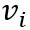
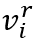
同时,对于训练集中的每个事件,有一个标注的情感极性标签(0-消极,1-积极)。我们将事件表示作为特征输入分类器,训练该分类器预测正确情感标签的能力,从而使事件表示中带有情感极性信息,计算情感分类的交叉熵损失:
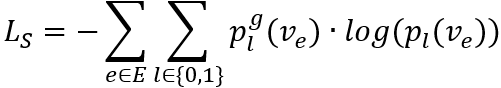
其中,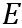
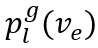
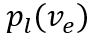
最终的优化目标为三部分损失的加权和:
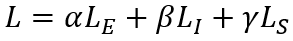
模型的整理架构如图4所示。
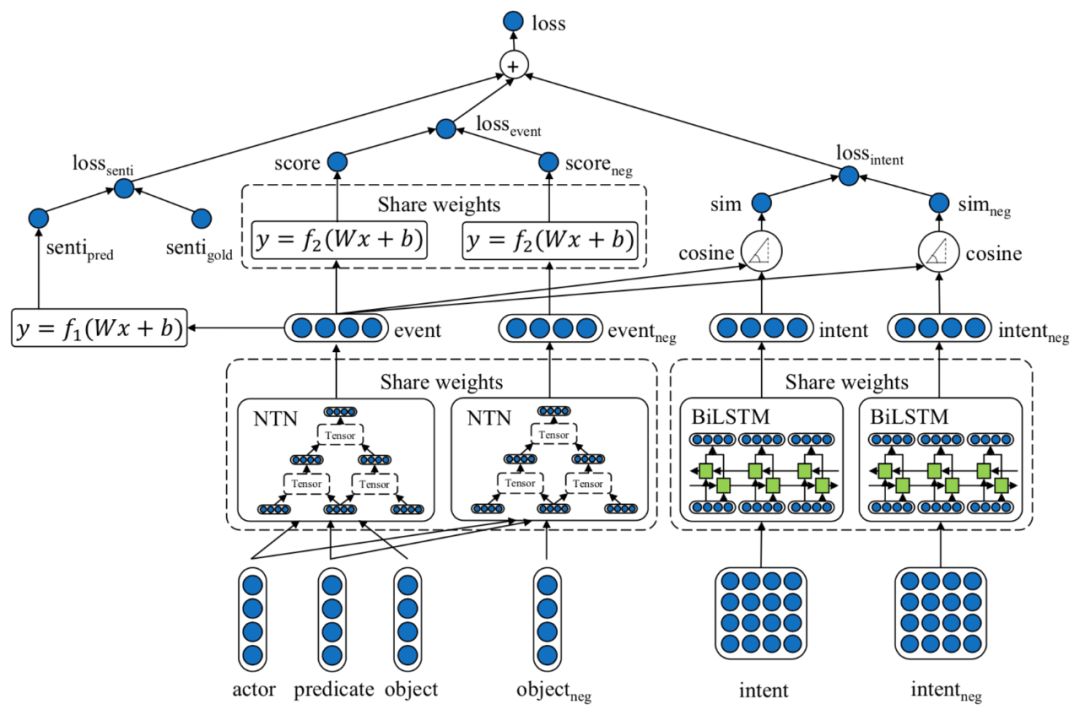
图4 融合意图、情感信息的事件表示模型架构
4. 实验
4.1 事件相似度
我们在Hard Similarity和Transitive Sentence Similarity两个事件相似度任务上对比了模型与基线方法的效果。
Hard Similarity任务由Weber等人(2018)提出,该任务构造了两种类型的事件对,第一种事件对中,两个事件语义相近,但几乎没有单词上的重叠;第二种对事件中,两个事件单词上重叠程度较高,但语义相差较远。对每种事件表示方法,我们计算每个事件对的余弦相似度作为得分,并以相似事件对得分大于不相似事件对得分的比例作为模型的准确率。
Transitive SentenceSimilarity数据集(Kartsaklis与Sadrzadeh,2014)包含了108个事件对,每个事件对带有由人工标注的相似度得分。我们使用Spearman相关系数评价模型给出的相似度与人工标注的相似度的一致性。
表1 事件相似度实验结果
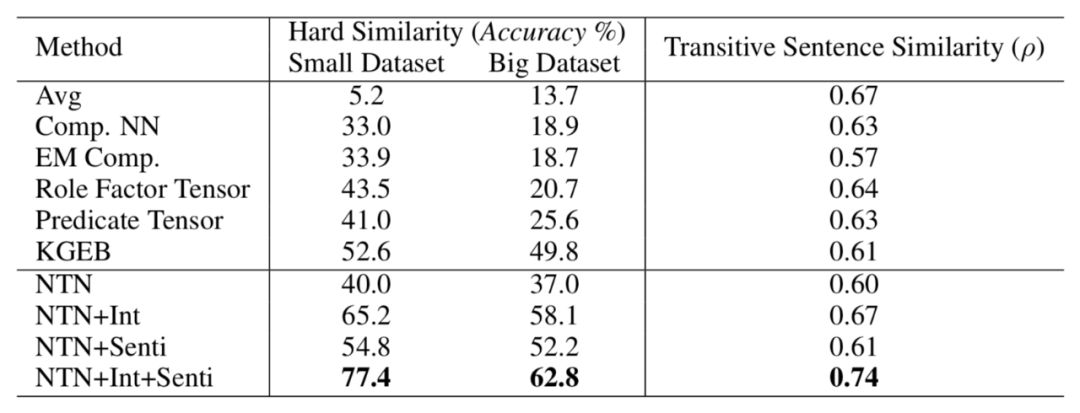
两个任务的结果如表1所示。我们发现:
(1) 在Transitive SentenceSimilarity任务上,词向量均值的方法取得了很好的结果,但在Hard Similarity任务上结果很差。这主要是因为HardSimilarity数据集是专门为了区分“重叠词较多但语义不相似”“重叠词较少但语义相似”的情况。显然,在这一数据集上,词向量均值的方法无法捕获事件论元间的交互,因此无法取得较好的效果。
(2) 基于Tensor 组合的模型(NTN, KGEB, RoleFactor Tensor, Predicate Tensor)超过了加性(Additive)模型(Comp.NN, EM Comp.),表明基于Tensor组合的方法可以更好地建模事件论元的语义组合。
(3) 我们的常识知识增强的事件表示方法在两个数据集上均超过了基线方法(在Hard Similarity小数据集和大数据集上分别取得了78%和200%的提升),表明常识知识对于区分事件具有重要的作用。
表2展示了Hard Similarity任务上加入常识信息前(oScore)/后(mScore)事件相似度的变化。
表2 加入常识信息前后事件相似度变化

4.2 脚本事件预测
脚本事件预测(Chambers与Jurafsky,2008)任务定义为给定上下文事件,从候选事件中选出接下来最有可能发生的事件。我们在标准的MCNC数据集(Granroth-Wilding与Clark,2016)上验证模型的效果。我们沿用Li等人(2018)的SGNN的模型,仅仅用我们的事件表示模型代替SGNN中的事件表示部分。表3中的实验结果显示,我们的方法在单模型上取得了1.5%的提升,在多模型ensemble上取得了1.4%的提升,验证了更好的事件表示在该任务上的重要性。我们观察到,仅仅融入意图的事件表示超过了其他基线方法,表明捕获参与者的意图信息可以帮助推理他们的后续活动。另外,我们发现只融入情感信息的事件表示也取得了比原始SGNN更好的效果,这主要是因为顺承事件间情感的一致性也可以帮助预测后续的事件。
表3 脚本事件预测实验结果

4.3 股市预测
前人的研究显示新闻事件会对股价的涨跌产生影响(Luss与d’Aspremont,2012)。我们对比了使用不同事件表示作为特征预测股市涨跌的结果,如图5所示。该实验结果显示了事件中的情感信息在股市预测任务上的有效性(取得了2.4%的提升)。
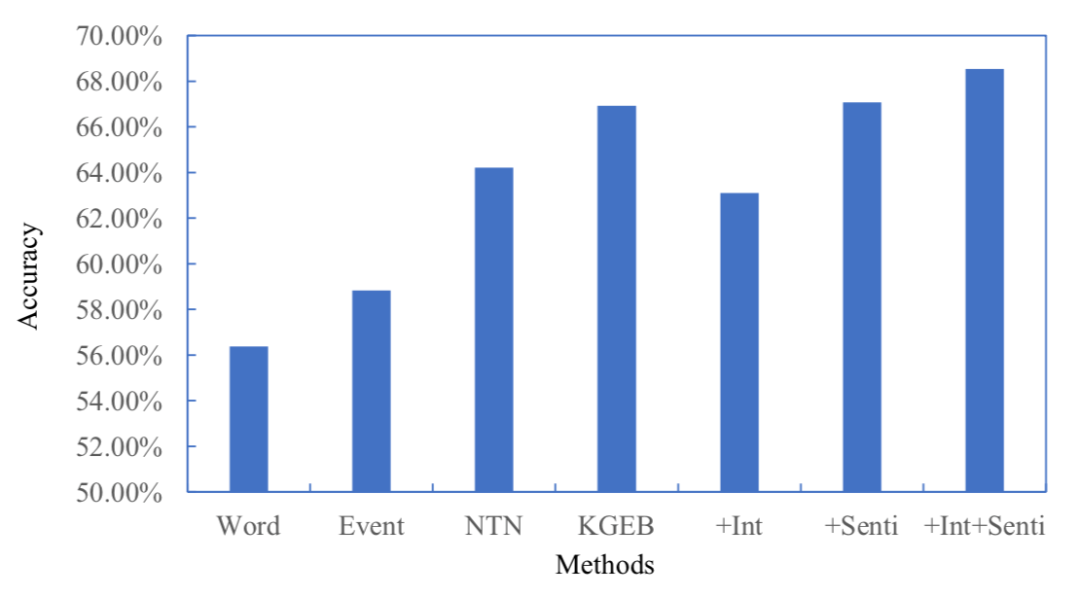
图5 股市预测实验结果
5. 结论
要让计算机充分理解事件,需要将常识信息融入事件表示之中。高质量的事件表示在脚本事件预测、股市预测等许多下游任务上具有重要的作用。本文提出了一个简单而有效的事件表示学习框架,将意图、情感常识信息融入事件表示的学习之中。事件相似度、脚本事件预测、股市预测三个任务上的实验结果表明,我们的方法可以有效提高事件表示的质量,并为下游任务带来提升。
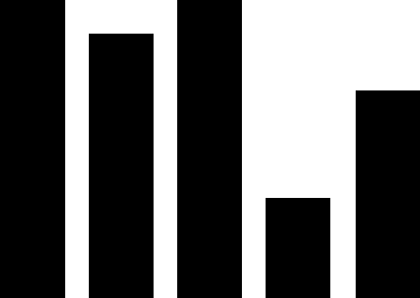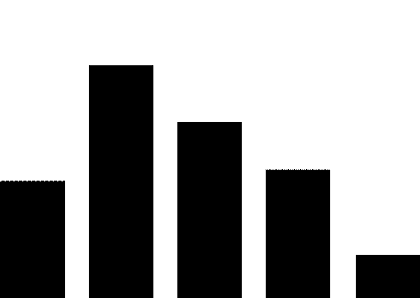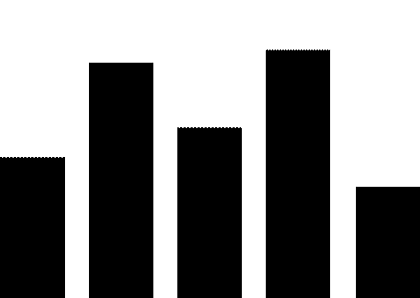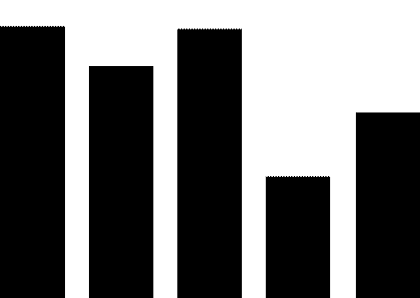
更多内容