自动文本摘要研究综述

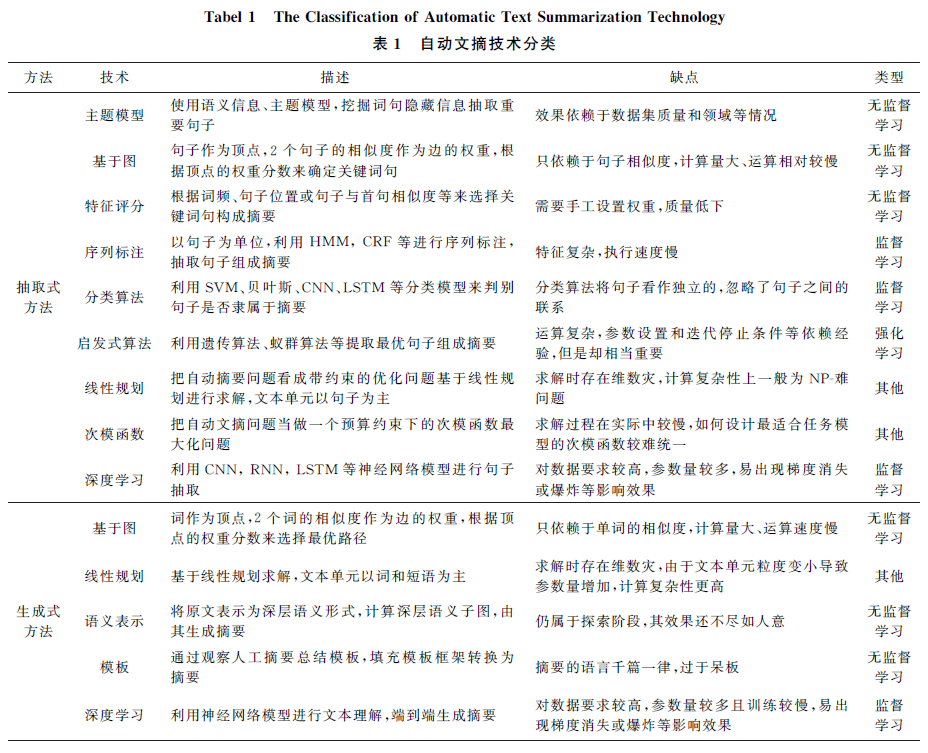
近年来,互联网技术的蓬勃发展极大地便利了人类的日常生活,不可避免的是互联网中的信息呈井喷式爆发,如何从中快速有效地获取所需信息显得极为重要.自动文本摘要技术的出现可以有效缓解该问题,其作为自然语言处理和人工智能领域的重要研究内容之一,利用计算机自动地从长文本或文本集合中提炼出一段能准确反映源文中心内容的简洁连贯的短文.探讨自动文本摘要任务的内涵,回顾和分析了自动文本摘要技术的发展,针对目前主要的2种摘要产生形式(抽取式和生成式)的具体工作进行了详细介绍,包括特征评分、分类算法、线性规划、次模函数、图排序、序列标注、启发式算法、深度学习等算法.并对自动文本摘要常用的数据集以及评价指标进行了分析,最后对其面临的挑战和未来的研究趋势、应用等进行了预测.
http://crad.ict.ac.cn/CN/10.7544/issn1000-1239.2021.20190785
21世纪互联网快速发展,文本数据呈指数级增长,用户如何快速有效地从海量信息中提炼出所需的有用资料,已经成为一个亟待解决的问题.自动文本摘要(automaticsummarization)技术,又被称为自动文摘,它的出现恰逢其时,为用户提供简洁而不丢失原意的信息,可以有效地降低用户的信息负担、提高用户的信息获取速度,将用户从繁琐、冗余的信息中解脱出来,节省了大量的人力物力,在信息检索、舆情分析、内容审查等领域具有较高的研究价值.
早期的文本摘要普遍是通过人工来完成的,文本数据量的激增使得这项工作日渐繁重且效率低下,逐渐不能满足用户的需求.近年来,随着对非结构化文本数据研究的进展,自动文摘任务得到了广泛的关注和研究,其已成为自然语言处理领域的研究热点之一.学术界涌现出大量围绕算法技术、数据集、评价指标和系统的相关工作,这些工作在一定程度上取得了较好的效果,快速应用到金融、新闻、医学、媒体等各个领域,如社交媒体摘要[1]、新闻摘要[2]、专利摘要[3]、观点摘要[4]以及学术文献摘要[5].尽管如此,目前计算机自动产生的摘要还远不能达到人工摘要的质量,在该任务上还有很大的提升空间,仍需要相关研究者进一步探索有效的自动文摘技术.
目前已有一些文献对自动文摘任务进行了调研和评估.在早期的工作中,万小军等人[6]首次将自动文摘的研究工作从内容表示、权重计算、内容选择、内容组织4个角度进行了深度剖析,并对发展趋势进行了展望,为之后的研究工作打下了良好的基础.王俊丽等人[7]则主要针对抽取式自动文摘的图排序算法进行了介绍.曹洋等人[8]重点分析了3种主要的机器学习算法在自动文摘中的应用.此外,还有一些相关的研究工作,但他们基本仅针对自动文摘中的单个技术方向进行详细综述,经过调研发现目前尚缺乏对自动文摘任务进行全面的研究综述.
基于此,为了便于研究者在现有研究工作的基础上取得更好的进展,非常有必要对目前自动文摘的研究成果进行全面的分析和总结.因此,我们查阅整理了近年来学术界相关的研究工作,包括自然语言处理、人工智能等相关领域的国际会议和学术期刊,对这些研究成果按照摘要产生的技术算法进行了详细的分类以及优缺点的对比与总结.除此之外,本文对自动文本摘要研究常用的数据集、评价方法进行归纳总结,最后对自动文摘任务未来的研究趋势进行展望与总结.
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“文本摘要” 可以获取《自动文本摘要研究综述》专知下载链接索引




