【学界】六种GAN评估指标的综合评估实验,迈向定量评估GAN的重要一步
选自arXiv
作者:Qiantong Xu、Gao Huang、Yang Yuan、Chuan Guo、Yu Sun、Felix Wu、Kilian Weinberger
来源:机器之心
生成对抗网络的评估目前仍以定性评估和一些可靠性较差的指标为主,这阻碍了问题的细化,并具有误导性的风险。本文讨论了多个 GAN 评估指标,并从多个方面对评估指标进行了实验评估,包括 Inception Score、Mode Score、Kernel MMD、Wasserstein 距离、Fréchet Inception Distance、1-NN 分类器。实验得出了综合性的结论,选出了两个表现优越的指标,该研究在定量评估、对比、改进 GAN 的方向上迈出了重要的一步。
论文:An empirical study on evaluation metrics of generative adversarial networks

论文链接:https://arxiv.org/abs/1806.07755
摘要:评估生成对抗网络(GAN)本质上非常有挑战性。本论文重新讨论了多个代表性的基于样本的 GAN 评估指标,并解决了如何评估这些评估指标的问题。我们首先从一些使指标生成有意义得分的必要条件开始,比如区分真实对象和生成样本,识别模式丢弃(mode dropping)和模式崩塌(mode collapsing),检测过拟合。经过一系列精心设计的实验,我们对现有的基于样本的指标进行了综合研究,并找出它们在实践中的优缺点。基于这些结果,我们观察到,核最大均值差异(Kernel MMD)和 1-最近邻(1-NN)双样本检验似乎能够满足大部分所需特性,其中样本之间的距离可以在合适的特征空间中计算。实验结果还揭示了多个常用 GAN 模型行为的有趣特性,如它们是否记住训练样本、它们离学到目标分布还有多远。
1 引言
生成对抗网络(GAN)(Goodfellow et al., 2014)近年来得到了广泛研究。除了生成惊人相似的图像(Radford et al., 2015; Larsen et al., 2015; Karras et al., 2017; Arjovsky et al., 2017; Gulrajani et al., 2017),GAN 还创新性地应用于半监督学习(Odena, 2016; Makhzani et al., 2015)、图像到图像转换(Isola et al., 2016; Zhu et al., 2017)和模拟图像细化(Shrivastava et al., 2016)等领域中。然而,尽管可用的 GAN 模型非常多(Arjovsky et al., 2017; Qi, 2017; Zhao et al., 2016),但对它们的评估仍然主要是定性评估,通常需要借助人工检验生成图像的视觉保真度来进行。此类评估非常耗时,且主观性较强、具备一定误导性。鉴于定性评估的内在缺陷,恰当的定量评估指标对于 GAN 的发展和更好模型的设计至关重要。
或许最流行的指标是 Inception Score(Salimans et al., 2016),它使用外部模型即谷歌 Inception 网络(Szegedy et al., 2014)评估生成图像的质量和多样性,该模型在大规模 ImageNet 数据集上训练。一些其他指标虽然应用没有那么广泛,但仍然非常有价值。Wu et al. (2016) 提出一种采样方法来评估 GAN 模型的对数似然,该方法假设高斯观测模型具备固定的方差。Bounliphone et al. (2015) 提出使用最大均值差异(MMD)进行 GAN 模型选择。Lopez-Paz & Oquab (2016) 使用分类器双样本检验方法(一种统计学中得到充分研究的工具),来评估生成分布和目标分布之间的差异。
尽管这些评估指标在不同任务上有效,但目前尚不清楚它们的分数在哪些场景中是有意义的,在哪些场景中可能造成误判。鉴于评估 GAN 非常有难度,评估评估指标则更加困难。大部分已有研究尝试通过展示这些评估指标和人类评估之间的关联性来证明它们的正当性。但是,人类评估有可能偏向生成样本的视觉质量,忽视整体分布特征,而后者对于无监督学习来说非常重要。
这篇论文综合回顾了有关基于样本的 GAN 定量评估方法的文献。我们通过精心设计的一系列实验解决了评估评估指标的难题,我们希望借此回答以下问题:(1)目前基于样本的 GAN 评估指标的行为合理特征是什么?(2)这些指标的优缺点有哪些,以及基于此我们应该优先选择哪些指标?实验观察表明 MMD 和 1-NN 双样本检验是最合适的评估指标,它们能够区分真实图像和生成图像,对模式丢弃和崩塌较为敏感,且节约算力。
最后,我们希望这篇论文能够对在实践环境中选择、解释和设计 GAN 评估指标构建合适的原则。所有实验和已检验指标的源代码均已公开,向社区提供现成工具来 debug 和改进他们的 GAN 算法。
源代码地址:https://github.com/xuqiantong/GAN-Metrics
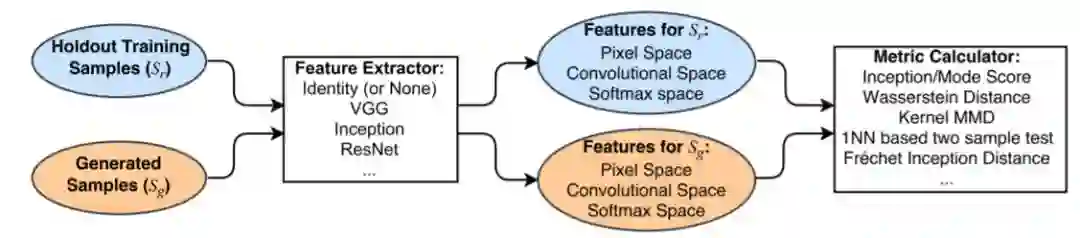
图 1:基于样本的典型 GAN 评估方法。
2.2 基于样本的距离度量
我们主要关注于基于样本的评估度量,这些度量方法都遵循图 1 所示的一般设定。度量计算子是 GAN 中的关键因素,本论文简要介绍了 5 种表征方法:Inception 分数(Salimans et al., 2016)、Mode 分数(Che et al., 2016)、Kernel MMD(Gretton et al., 2007)、Wasserstein 距离、Fréchet Inception 距离(FID,Heusel et al., 2017)与基于 1-最近邻(1-NN)的双样本测试(Lopez-Paz & Oquab, 2016)。所有这些度量方法都不需要知道特定的模型,它只要求从生成器中获取有限的样本就能逼近真实距离。
Inception 分数可以说是文献中采用最多的度量方法。它使用一个图像分类模型 M 和在 ImageNet(Deng et al., 2009)上预训练的 Inception 网络(Szegedy et al., 2016),因而计算:
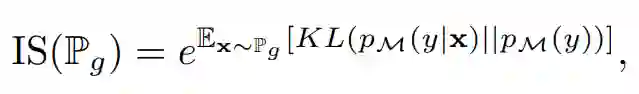
其中 p_M(y|x) 表示由模型 M 在给定样本 x 下预测的标签分布,
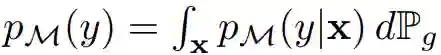
即边缘分布 p_M(y|x) 在概率度量 P_g 上的积分。p_M(y|x) 上的期望和积分都可以通过从 P_g 中采样的独立同分布(i.i.d.)逼近。更高的 IS 表示 p_M(y|x) 接近于点密度,这只有在当 Inception 网络非常确信图像属于某个特定的 ImageNet 类别时才会出现,且 p_M(y) 接近于均匀分布,即所有类别都能等价地表征。这表明生成模型既能生成高质量也能生成多样性的图像。Salimans et al. (2016) 表示 Inception 分数与人类对图像质量的判断有相关性。作者强调了 Inception 分数两个具体的属性:1)KL 散度两边的分布都依赖于 M;2)真实数据分布 P_r 甚至是其样本的分布并不需要使用。
Mode 分数是 Inception 分数的改进版。正式地,它可以通过下式求出:
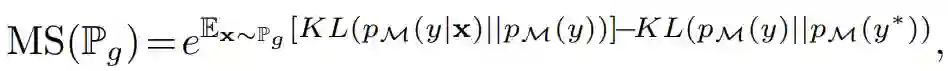
其中
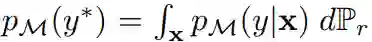
为在给定真实样本下边缘标注分布在真实数据分布上的积分。与 Inception 分数不同,它能通过 KL(p_M(y) || p_M(y*))散度度量真实分布 P_r 与生成分布 P_g 之间的差异。
Kernel MMD(核最大均值差异)可以定义为:
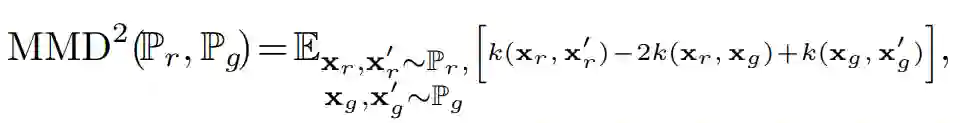
在给定一些固定的和函数 k 下,它度量了真实分布 P_r 与生成分布 P_g 之间的差异。给定分别从 P_r 与 P_g 中采样的两组样本,两个分布间的经验性 MMD 可以通过有限样本的期望逼近计算。较低的 MMD 表示 P_g 更接近与 P_r。Parzen window estimate (Gretton et al., 2007) 可以被视为 Kernel MMD 的特例。
P_r 与 P_g 分布之间的 Wasserstein 距离(推土机距离)可以定义为:
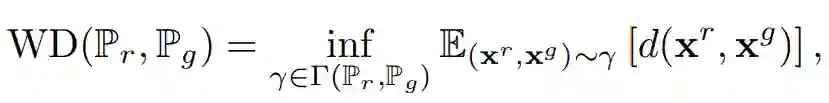
其中 Γ(Pr, Pg) 表示边缘分布分别为 Pr 与 Pg 的所有联合分布(即概率耦合)集合,且 d(x^r, x^g) 表示两个样本之间的基础距离。对于密度为 pr 与 pg 的离散分布,Wasserstein 距离通常也被称为推土机距离(EMD),它等价于解最优传输问题:
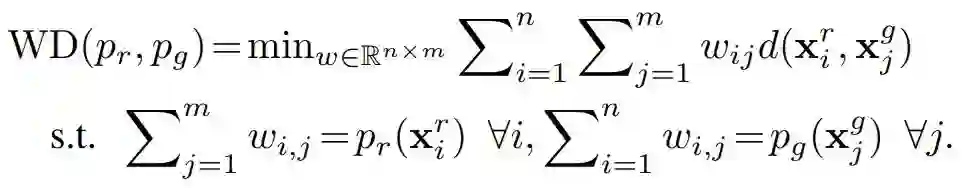
该式表示实践中 WD(P_r, P_g) 的有限样本逼近。与 MMD 相似,Wasserstein 距离越小,两个分布就越相似。
Fréchet Inception 距离(FID)是最近由 Heusel et al. (2017) 引入并用来评估 GAN 的度量方法。对于适当的特征函数φ(默认为 Inception 网络的卷积特征),FID 将 φ(P_r) 和 φ(P_g) 建模为高斯随机变量,且其样本均值为 µ_r 与 µ_g、样本协方差为 C_r 与 C_g。两个高斯分布的 Fréchet 距离(或等价于 Wasserstein-2 距离)可通过下式计算:
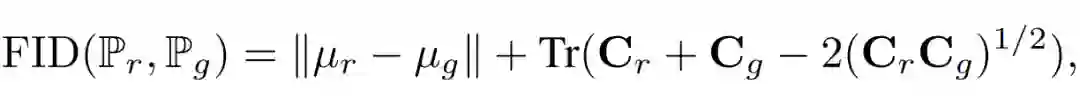
1-最近邻分类器用于成对样本检验以评估两个分布是否相同。给定两组样本
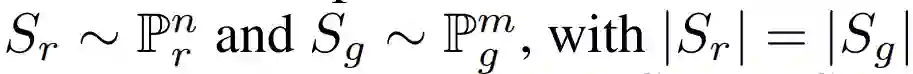
,我们可以计算在 S_r 和 S_g 上进行训练的 1-NN 分类器的留一(LOO)准确率,其中 S_r 全部标注为正样本、S_g 全部标注为负样本。与常用的准确率不同,但|S_r|=|S_g|都非常大时,1-NN 分类器应该服从约为 50% 的 LOO 准确率,这在两个分布相匹配时能够达到。当 GAN 的生成分布过拟合真实采样分布 Sr 时,LOO 准确度将低于 50%。在理论上的极端案例中,如果 GAN 记忆住 Sr 中的每一个样本,并精确地重新生成它,即在 S_g=S_r 时,准确率将为零。因为 Sr 中的每一个样本都将有一个来自 S_g 的最近邻样本,它们之间的距离为零。1-NN 分类器成对样本检验族,理论上任意二元分类器都能采用这种方法。我们只考虑 1-NN 分类器,因为它不需要特殊的训练并只需要少量超参数调整。
Lopez-Paz & Oquab (2016) 认为 1-NN 准确率主要作为成对样本检验的统计量。实际上,将其分为两个类别来独立地分析能获得更多的信息。例如典型的 GAN 生成结果,由于 mode collapse 现象,真实和生成图像的主要最近邻都是生成图像。在这种情况下,真实图像 LOO 1-NN 准确率可能会相对较低(期望):真实分布的模式通常可由生成模型捕捉,所以 Sr 中的大多数真实样本周围都充满着由 Sg 生成的样本,这就导致了较低的 LOO 准确率;而生成图像的 LOO 准确度非常高(不期望的):生成样本倾向于聚集到少量的模式中心,而这些模式由相同类别的生成样本包围,因此会产生较高的 LOO 准确率。
3 GAN 评估指标实验
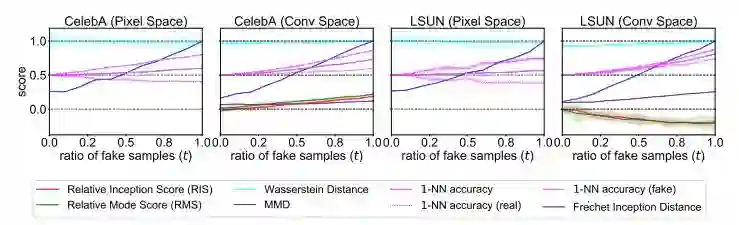
图 2:从真实图像和 GAN 生成图像的混合集合中区分出真实图像。对于有判别力的指标,其分数应该随着混合集合中 GAN 生成样本数量增加而增加。RIS 和 RMS 失败了,因为在 LSUN 上它们的分数随着 S_g 中的 GAN 生成样本数量增加而减少。在像素空间中 Wasserstein 和 1-NN accuracy (real) 也失败了,因为它们的分数没有增加反而下降了。
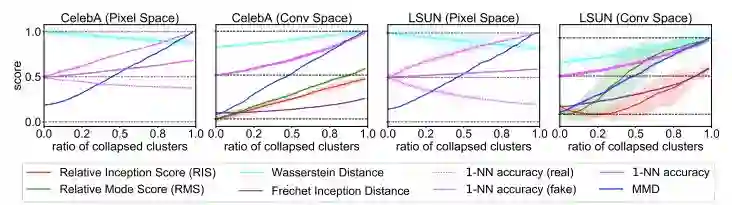
图 3:模拟模式崩塌实验。指标分数应该增加,以反映随着更多模式向聚类中心崩塌真实分布和生成分布之间的不匹配。所有指标在卷积空间中都作出了正确的响应。而在像素空间中,Wasserstein distance 和 1-NN accuracy (real) 失败了,因为它们的分数没有增加反而下降了。
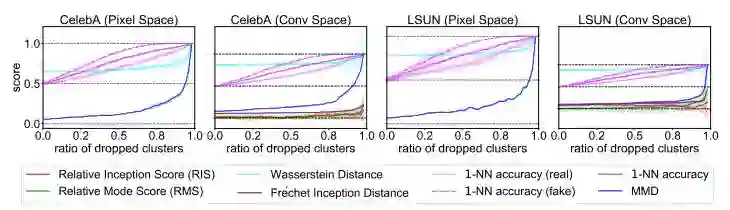
图 4:模拟模式丢弃实验。指标分数应该增加,以反映随着更多模式丢弃真实分布和生成分布之间的不匹配。所有指标(除了 RIS 和 RMS)都作出了正确的响应,因为在几乎所有模式都丢弃时它们仍然有轻微的上升。
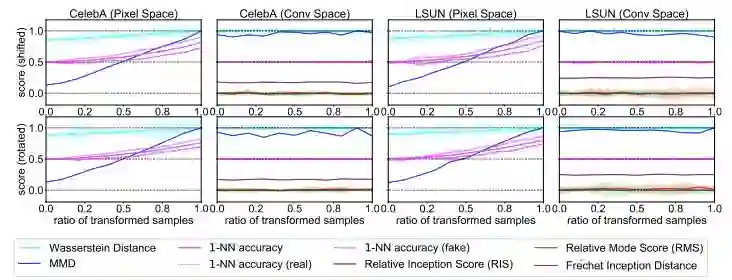
图 5:关于每个指标对小量变换(旋转和平移)的鲁棒性的实验。所有指标应该对真实图像和变换后的真实样本保持不变,因为变换不会改变图像语义。所有指标都在卷积空间中作出了正确的响应,但不是像素空间。该实验证明像素空间中距离的不适应性。
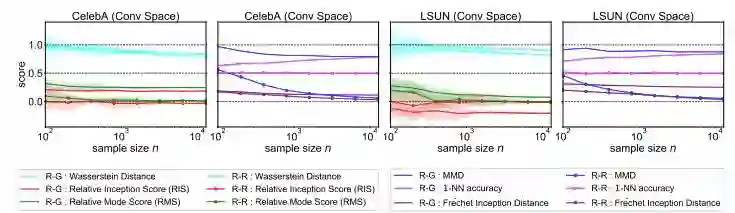
图 6:不同指标在样本数作为 x 轴的函数上的分数。完美指标应该带来 real-real
和 real-fake
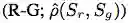
曲线之间的巨大差距,以利用尽可能少的样本区分真实分布和伪分布。与 Wasserstein 距离相比,MMD 和 1-NN accuracy 判别真实图像和生成图像所需的样本量更少,而 RIS 在 LSUN 上完全失败,因为其在生成图像上的分数甚至优于(低于)真实图像。
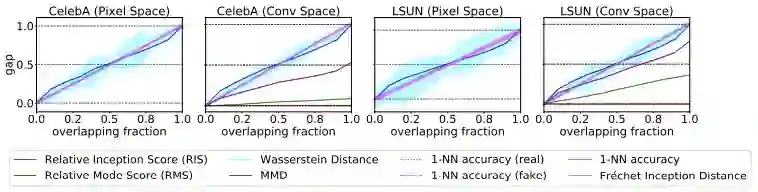
图 8:检测生成样本过拟合的实验。随着更多的生成样本与训练集中的真实样本重叠,验证得分和训练得分之间的差距应该增加至信号过拟合(signal overfitting)。所有指标的行为都是正确的,除了 RIS 和 RMS,因为这两个的分数不会随着重叠样本数量的增加而增加。
4 讨论和结论
基于以上分析,我们可以总结这六个评估指标的优势和本质缺陷,以及它们在什么条件下可以生成有意义的结果。使用部分指标,我们能够研究过拟合问题(详见 Appendix C)、在 GAN 模型上执行模型选择,并基于精心挑选的样本对比不同模型(详见 Appendix D),无需使用人类评估。
Inception Score 展示出生成图像的质量和多样性之间的合理关联,这解释了其在实践中广泛应用的原因。但是,它在大部分情况下并不合适,因为它仅评估 P_g(作为图像生成模型),而不是评估其与 P_r 的相似度。一些简单的扰动(如混入来自完全不同分布的自然图像)能够彻底欺骗 Inception Score。因此,它可能会鼓励模型只学习清晰和多样化图像(甚至一些对抗噪声),而不是 P_r。这也适用于 Mode Score。此外,Inception Score 无法检测过拟合,因为它无法使用留出验证集。
Kernel MMD 在预训练 ResNet 的特征空间中运行时,性能惊人地好。它总是能够识别生成/噪声图像和真实图像,且它的样本复杂度和计算复杂度都比较低。鉴于这些优势,即使 MMD 是有偏的,但我们仍推荐大家在实践中使用它。
当距离在合适的特征空间中进行计算时,Wasserstein 距离的性能很好。但是,它的样本复杂度很高,Arora 等人 2017 年也发现了这一事实。另一个主要缺陷是计算 Wasserstein 距离所需的实践复杂度为 O(n^3),且随着样本数量的增加而更高。与其他方法相比,Wasserstein 距离在实践中作为评估指标的吸引力较差。
Fréchet Inception Distance 在判别力、鲁棒性和效率方面都表现良好。它是 GAN 的优秀评估指标,尽管它只能建模特征空间中分布的前两个 moment。
1-NN 分类器几乎是评估 GAN 的完美指标。它不仅具备其他指标的所有优势,其输出分数还在 [0, 1] 区间中,类似于分类问题中的准确率/误差。当生成分布与真实分布完美匹配时,该指标可获取完美分数(即 50% 的准确率)。从图 2 中可以看到典型 GAN 模型对真实样本(1-NN accuracy (real))的 LOO 准确率较低,而对生成样本(1-NN accuracy (fake))的 LOO 准确率较高。这表明 GAN 能够从训练分布中捕捉模型,这样分布在模式中心周围的大部分训练样本的最近邻来自于生成图像集合,而大部分生成图像的周围仍然是生成图像,因为它们一起崩塌。该观测结果表明模式崩塌问题在典型 GAN 模型中很普遍。但是,我们还注意到这个问题无法通过人类评估或广泛使用的 Inception Score 评估指标来有效检测到。
总之,我们的实证研究表明选择计算不同指标的特征空间至关重要。在 ImageNet 上预训练 ResNet 的卷积空间中,MMD 和 1-NN accuracy 在判别力、鲁棒性和效率方面都是优秀的指标。Wasserstein 距离的样本效率较差,而 Inception Score 和 Mode Score 不适合与 ImageNet 差异较大的数据集。我们将发布所有这些指标的源代码,向研究者提供现成的工具来对比和改进 GAN 算法。
基于这两个主要指标 MMD 和 1-NN accuracy,我们研究了 DCGAN 和 WGAN(详见 Appendix C)的过拟合问题。尽管人们广泛认为 GAN 对训练数据过拟合,但我们发现这只在训练样本很少的情况下才会发生。这提出了一个关于 GAN 泛化能力的有趣问题。我们希望未来的研究能够帮助解释这一现象。

☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【干货】DeepMind 提出 GQN,神经网络也有空间想象力
☞【前沿】谷歌提出Sim2Real:让机器人像人类一样观察世界
☞【深度】何恺明CVPR演讲:深入理解ResNet和视觉识别的表示学习(41 PPT)




