【机器学习】机器学习领域的突破性进展

CDA字幕组 翻译整理
本文为 CDA 数据分析师原创作品,转载需授权
机器学习的发展涉及到各个方面,从语音识别到智能回复。但这些系统中的“智能”实际上是如何工作的呢?还存在什么主要挑战?在本次讲座中将一一解答。
观看更多国外公开课,点击"阅读原文"
Google I/O 是由Google举行的网络开发者年会,Google I/O 2016 中围绕机器学习领域的突破性进展进行了探讨。
CDA字幕组对该视频进行了汉化,附有中文字幕的视频如下:
机器学习领域的突破性进展
针对不方便打开视频的小伙伴,CDA字幕组也贴心的整理了文字版本,如下:
(文末有彩蛋! )

大家好,欢迎来到讲座:关于机器学习的突破性进展。
我们探讨了谷歌对于 AI 的长期愿景,以及过去十年对机器学习的研究。这是十分重要的,因为所有用户都期待着奇迹发生。他们希望能与科技自然地交流,就像与人类交流一样。很明显,今天是不可能实现的,但是我们在向这个目标努力。
我认为人们常常忽略的是,谷歌不仅仅运用熟知的机器学习方法,致力于逐步改进产品。事实上我们有团队负责基础性工作。为了改善机器学习最先进的技术,他们在山景城以及世界各地工作。
接下来你将听到他们的一些工作成果。如果你也在探索复杂的事情,比如用Tensorflow工作,或者致力于机器学习模型,那么你可以通过这些演讲者的经验教训得到一些启示。如果你是开发人员,想使用我们提供在云的机器学习API,你会很好地理解到哪些好用,以及你如何将其应用到自己的产品中。希望你们能乐在其中。下面有请Francoise。
语音识别
大家好,我叫Francoise。我负责语音识别的工作。我在十年前加入谷歌。你可能很难想起,但十年前还没有iPhone和安卓系统。那时语音识别主要应用于呼叫中心,这有些烦人并不有意思。

我加入谷歌时有两个目标:
一、让语音识别变得有趣且实用;
二、让语音识别更好地服务全球用户。
如今过去了十年,安卓手机中约20%的查询都是通过语音,我们将这视为一项成功。我们刚发布了Cloud Speech API,这能让你们利用语音识别开发出更加有意思的产品。如今涵盖了80种语言、近40亿人口。

当然你可以问我,达到这个成果为何花了十年? 毕竟语音识别很简单,用一年就能实现,几年后就能进行转录。但是如果看到不同的用户和场景,当中有不同的需求、不同的说法。
下面我想播放一些语音片段,请点击下视频。
(片段一: "大堡礁的水母季在什么时候?")
(片段二: 匈牙利语)这个人在讲匈牙利语
(片段三:"大象会发出什么叫声?")

这是我们需要预想到的数据,不是么?我们想要为这些用户提供服务,无论他们是谁。我们竭尽所能,但有时候也会出错。
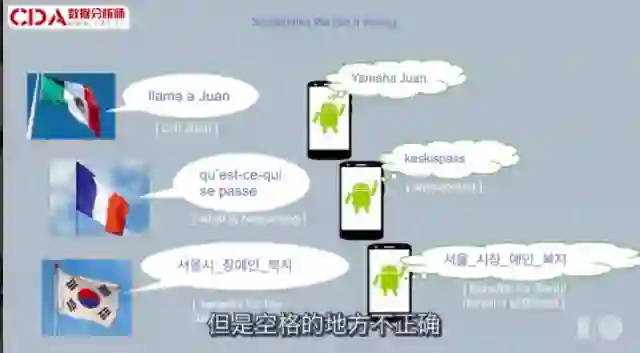
这是最近报告给我们的一个例子,一位用户说的是西班牙语。他想表达的是 "打电话给朋友”,但我们识别成了他想要买钢琴之类的。
再看下一个例子,你可能猜到了,我讲法语。因此我用法语来测试我的产品。我跟识别器说"发生什么了?"却得到这个结果。虽然听起来一样,但是拼写完全不一样。
随后我在韩语也遇到这种情况,如果看到这些字符串,实际上它正确识别了每个韩文字符,但是空格的地方不正确。这就很不一样了,从翻译结果就能知道。
我们犯错了,但是这可是语言识别。语音识别就是机器学习,所以我们能解决这个问题。但在我们探讨如何纠正错误之前,我想向你们展示语音识别的工作原理。
首先将语音波形图输入系统,你希望从中得出句子。
系统中有三个模型:第一个是语音模型,负责提取语音片段,尝试找出音素的分布概率以及语言中每个发音;第二个是发音模型,它从音素得出单词;第三个是语言模型,通过概率将单词连接起来。
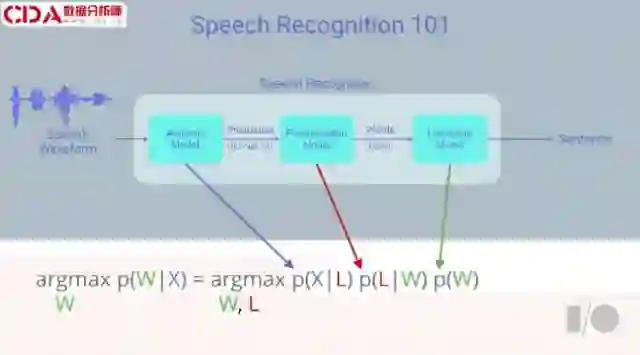
这是一个等式,表明根据语音观测我们试图得出的最大概率的词序列。通过一些数学基础,对应不同的模型你能将其分解成三个概率。这些都在表明这是统计模型,由三个不同模型组成 ,当中的一切都是可统计的。
我想多讲讲第一个语音模型,因为几十年来我们在用一种称为高斯混和模型的技术。多年来语音识别领域都用到该技术。但在2012年,我们改为使用神经网络。这花了一些时间,因为神经网络需要时间进行训练。它很庞大,想从系统中得到正确的特点需要做很多优化工作。但最终我们完成了。

通过转为使用神经网络,准确度得到了大幅度的改善。除此以外,它重启了该领域的变革。用了基础设施我们开始创新神经网络的结构。我们使用它每个月我们都会推出新的结构,并且比过去的版本更加强大。
我们从深度神经网络过渡到LSTM(长短期记忆)递归神经网络。然后我们开始添加卷积层,这能让我们更好地处理噪音和回响。之后是CTC(connectionist temporal classification)。这个我将会仔细说明。这些类型的进步带来了质量的改善,因此在2015年对于不同的语言组,我们大大改善了准确度。
回到CTC,就像我所说的。CTC能减少语音识别器的延迟,意味着当你对识别器说话时你将更快地得到回复,这种感觉很好。有时候事情很复杂,作为谷歌中研究语音识别的团队,我们在生活中也得到了很多教训。但为了让你们从那些经验教训中获益,我需要多讲讲语音识别的原理。

正如我所说我们使用大量的数据训练模型,它们来源各不相同, 将用来训练模型。模型进入识别器,然后用识别器得出的数据,反馈回到模型。因为那些数据很匹配我们要做的事情。问题在于数据有时会出现拼写错误,各种各样的错误。数据并不干净,这会导致之前遇到的问题。
有一天,我们看到识别器输出中出现了韩语单词"keu-a”。我们并不是了解当中的原因,于是开始分析。我们发现那是小孩子的声音。人们在进行语音查询,背景出现了小孩子的声音。对于这些背景的高音识别器不知道如何处理,所以它找到重元音的单词就像"keu-a”。然后它会选出那个词,进行识别。由于之前向你们展示的反馈环路,它会反馈到系统中。如此反复。
但在我们解决这个问题之前,我们在英式英语中开始看到"kdkdkd"这个词。你们能猜到它的由来吗? 有人回答说是来自火车或地铁。所以是人们在火车和地铁上使用手机,伴随着"tick tick"的声音,然后识别器不知道如何处理。
最后一个有些说不出口,是这个词 "f*ck”。我们分析后发现是由于人们拿起手机然后讲话,会先吸气呼吸。这是吹气的声音。

我意识解决这个问题需要向系统输入更多的人类知识。因此我们投入更多语言学家和人力资源,以解决这类问题。从而对数据更好地格式化,然后正确地转录数据。我们建立了很复杂的准则,为了正确地转录数据。通过三百万注释的波形,我们可以训练语言模型,从数据中学习新的发音,增加语言模型训练集,这些都会带来改善。
通过三百万波形我们可以做很多工作,如果是三千万呢? 因此我们开始努力转录3万3千小时的人类语音,需要600人在合理时间内完成。通过这些数据我们希望实现更加复杂、更加紧密的结构。因此我们能够使用,并且实现语音识别的梦想,即让它服务到地球上的每个人。
谢谢,下面有请 Andrew。

机器学习与图像
谢谢 Francoise。大家好,我是 Andrew。

这张是机器学习常见的图,图中有一些红点和蓝点。我们尝试得出能够区分红点和蓝点的模型。当我们拿到新的输入数据,模型便可推测输入的是红点还是蓝点。

在接下来的10分钟里,我们将讲些不一样的内容。这个是我,这张照片里只有我一个人。很难仅凭这点猜测我喜欢做什么。可能我喜欢戴帽子。但是你可以收集一些特征,训练模型,从而预测我喜欢做什么。
讲讲另外一种做法。不仅仅通过这个数据,如果我把它和数据集中的相邻数据一同考虑,添加关联性。在这个例子中是加上我的孩子们。现在可以推断,也许我喜欢跟孩子们一起参加万圣节活动。

通过这种直觉,并不是独立地对数据对象分类。我们可以利用不同数据点间的关系。
谷歌有个叫做Expander的基础设施,专门完成这类任务。这是利用数据对象间关联性的平台。

举个例子,很明显我喜欢万圣节的"trick-or-treating”。那么如果我能识别出南瓜将会很有用。在谷歌我们有个很棒的图像理解系统,这是它的工作原理。输入一组带有训练标签的图像,接着它学习深度网络。这种学习能使它识别新图像,也能识别出未来的物体和图像。
现在我们给它没有标签的图像,运用模型给这些图像贴标签。你可能会问我们最开始用到的那些标签怎么样。它们不错,但不是特别好。
左边的一个图是南瓜,右边的是南瓜汤。如果你使用神经网络,学习南瓜的形状,并接收这些输入信息是很难的。
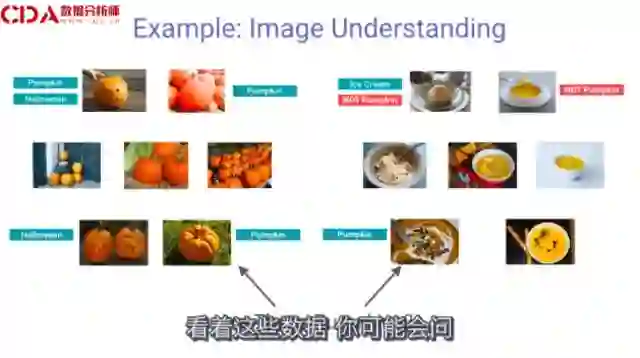
这是一个混合系统,它以图片为基础,学习关联性,从而区分正确的训练数据。并在这个基础之上,应用深度网络学习来辨识出正确的模型。
我们该怎么做呢? 我们已知这些数据对象的关系,在这些像素阵列之间,我们可以捕捉两个图形间相似点的嵌入映射。即这两个图像有多大几率包括相同的物体。
我们已知是南瓜的物体,通过这些关联线确认我们最初的判断,即物体为南瓜。当我们看到右边的图片,我们也可以做同样的操作。可以拓展两个不是南瓜的例子。通过这些图片得出结论,之前标记为南瓜汤的对象不太准确。
我们可以使用这种方法,减少训练数据里约40%的数据。这样图像分类的度量标准提高了9%。

让我们看看它的工作原理,这个是图像传播的一种等式形式。我们写一个罚函数(penalty function)得出数据中的相邻关联的效果。看到有lu-lv的部分,这指数据集中U和V 节点数据相距多远。Wuv为权重,代表它们的关联强度,然后加总整个数据集。这指具有相似信息的关联线条语句匹配度的差距。然后我试着减少这个差距。

下面的这个等式表明,如果对每个数据对象进行操作,使用相邻对象的标签更新标签,对图片中的所有数据都如此操作,如此重复。信息在图片中传递,并得出收敛到成本函数的最佳分配。以上是算法方面。
还有系统方面,构建这些系统是为了同时处理亿万量级的数据。我们想在图片上进行这样的操作,使用这些技术我们开发了相应的工具。
另外两个例子。比如短信智能回复。这个图片里的顶点是你可能会发送回复。线条代表相似信息,即这些回复可用于相似语境。或者是词汇式相似,即词语相同。或者词语嵌入为基础的相似。
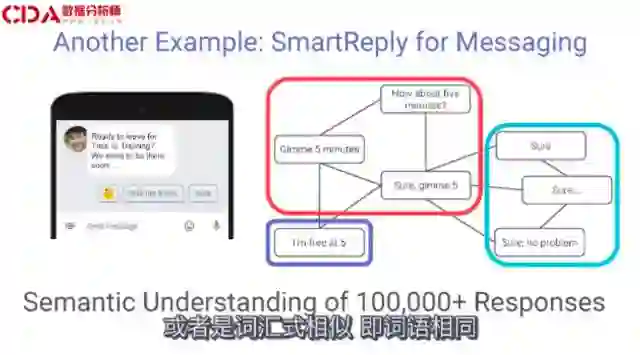
有这张图之后我们就可以运行扩展器来生成簇。这将返回相同意思的相似词组。还可以针对特定用户,根据语境选出合适选项,对于不同簇的理解,可以确保我们提供多样的选择。因此我们并不是选择三种方式表达相同的意思。
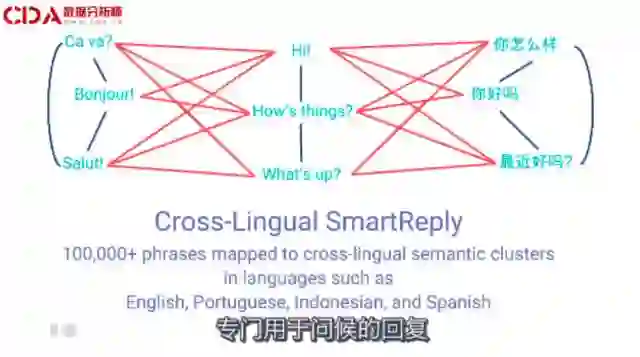
这在英语中运用得很好,我们也可以在其他语言中做相同操作。比如专门用于问候的回复。在英语中我可能会说 "Hi!""How's things?" "What's up?”,这些句子之间有关联。
在法语中我可能会说"Ca Va?" "Salut!”,我可以用谷歌翻译的模型构建法语变量和英语变量间的关联。
我们能够在其他语言中构建智能回复功能的数据结构,比如葡萄牙语、印度尼西亚语、西班牙语,甚至是印度英语中。
再举个例子,搜索查询。我很喜欢万圣节"trick-or-treating”。我想给我的孩子讲一些万圣节的故事,于是我向谷歌问一些问题,希望谷歌能够返回直接回答我问题的文字。
这里是一张图片,其各个顶点代表查询需求。线条则表示两个查询能够以相同的信息回复。实线是我确定的内容,虚线则是不太确定的内容。完成之后,我们就可以自动解答亿万条搜索查询中语义相等的问题了。

我们在图片中使用机器学习来理解自然语言、搜索查询、图像和其他媒体对象。你们可能还听过照片回复,即用图像回复,这是用的相同的技术。我们可以使用相同的技巧生成简要的模型,并实际应用在安卓产品设备上。

人工智能赛博物理操作系统
AI-CPS OS
“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能)分支用来的今天,企业领导者必须了解如何将“技术”全面渗入整个公司、产品等“商业”场景中,利用AI-CPS OS形成数字化+智能化力量,实现行业的重新布局、企业的重新构建和自我的焕然新生。
AI-CPS OS的真正价值并不来自构成技术或功能,而是要以一种传递独特竞争优势的方式将自动化+信息化、智造+产品+服务和数据+分析一体化,这种整合方式能够释放新的业务和运营模式。如果不能实现跨功能的更大规模融合,没有颠覆现状的意愿,这些将不可能实现。
领导者无法依靠某种单一战略方法来应对多维度的数字化变革。面对新一代技术+商业操作系统AI-CPS OS颠覆性的数字化+智能化力量,领导者必须在行业、企业与个人这三个层面都保持领先地位:
重新行业布局:你的世界观要怎样改变才算足够?你必须对行业典范进行怎样的反思?
重新构建企业:你的企业需要做出什么样的变化?你准备如何重新定义你的公司?
重新打造自己:你需要成为怎样的人?要重塑自己并在数字化+智能化时代保有领先地位,你必须如何去做?
AI-CPS OS是数字化智能化创新平台,设计思路是将大数据、物联网、区块链和人工智能等无缝整合在云端,可以帮助企业将创新成果融入自身业务体系,实现各个前沿技术在云端的优势协同。AI-CPS OS形成的数字化+智能化力量与行业、企业及个人三个层面的交叉,形成了领导力模式,使数字化融入到领导者所在企业与领导方式的核心位置:
精细:这种力量能够使人在更加真实、细致的层面观察与感知现实世界和数字化世界正在发生的一切,进而理解和更加精细地进行产品个性化控制、微观业务场景事件和结果控制。
智能:模型随着时间(数据)的变化而变化,整个系统就具备了智能(自学习)的能力。
高效:企业需要建立实时或者准实时的数据采集传输、模型预测和响应决策能力,这样智能就从批量性、阶段性的行为变成一个可以实时触达的行为。
不确定性:数字化变更颠覆和改变了领导者曾经仰仗的思维方式、结构和实践经验,其结果就是形成了复合不确定性这种颠覆性力量。主要的不确定性蕴含于三个领域:技术、文化、制度。
边界模糊:数字世界与现实世界的不断融合成CPS不仅让人们所知行业的核心产品、经济学定理和可能性都产生了变化,还模糊了不同行业间的界限。这种效应正在向生态系统、企业、客户、产品快速蔓延。
AI-CPS OS形成的数字化+智能化力量通过三个方式激发经济增长:
创造虚拟劳动力,承担需要适应性和敏捷性的复杂任务,即“智能自动化”,以区别于传统的自动化解决方案;
对现有劳动力和实物资产进行有利的补充和提升,提高资本效率;
人工智能的普及,将推动多行业的相关创新,开辟崭新的经济增长空间。
给决策制定者和商业领袖的建议:
超越自动化,开启新创新模式:利用具有自主学习和自我控制能力的动态机器智能,为企业创造新商机;
迎接新一代信息技术,迎接人工智能:无缝整合人类智慧与机器智能,重新
评估未来的知识和技能类型;
制定道德规范:切实为人工智能生态系统制定道德准则,并在智能机器的开
发过程中确定更加明晰的标准和最佳实践;
重视再分配效应:对人工智能可能带来的冲击做好准备,制定战略帮助面临
较高失业风险的人群;
开发数字化+智能化企业所需新能力:员工团队需要积极掌握判断、沟通及想象力和创造力等人类所特有的重要能力。对于中国企业来说,创造兼具包容性和多样性的文化也非常重要。
子曰:“君子和而不同,小人同而不和。” 《论语·子路》云计算、大数据、物联网、区块链和 人工智能,像君子一般融合,一起体现科技就是生产力。
如果说上一次哥伦布地理大发现,拓展的是人类的物理空间。那么这一次地理大发现,拓展的就是人们的数字空间。在数学空间,建立新的商业文明,从而发现新的创富模式,为人类社会带来新的财富空间。云计算,大数据、物联网和区块链,是进入这个数字空间的船,而人工智能就是那船上的帆,哥伦布之帆!
新一代技术+商业的人工智能赛博物理操作系统AI-CPS OS作为新一轮产业变革的核心驱动力,将进一步释放历次科技革命和产业变革积蓄的巨大能量,并创造新的强大引擎。重构生产、分配、交换、消费等经济活动各环节,形成从宏观到微观各领域的智能化新需求,催生新技术、新产品、新产业、新业态、新模式。引发经济结构重大变革,深刻改变人类生产生活方式和思维模式,实现社会生产力的整体跃升。
产业智能官 AI-CPS
用“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能),在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的认知计算和机器智能;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。


长按上方二维码关注微信公众号: AI-CPS,更多信息回复:
新技术:“云计算”、“大数据”、“物联网”、“区块链”、“人工智能”;新产业:“智能制造”、“智能农业”、“智能金融”、“智能零售”、“智能城市”、“智能驾驶”;新模式:“财富空间”、“数据科学家”、“赛博物理”、“供应链金融”。
官方网站:AI-CPS.NET
本文系“产业智能官”(公众号ID:AI-CPS)收集整理,转载请注明出处!
版权声明:由产业智能官(公众号ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。部分文章推送时未能与原作者取得联系。若涉及版权问题,烦请原作者联系我们,与您共同协商解决。联系、投稿邮箱:erp_vip@hotmail.com





