【KDD2020】基于纳什强化学习的鲁棒垃圾邮件发送者检测

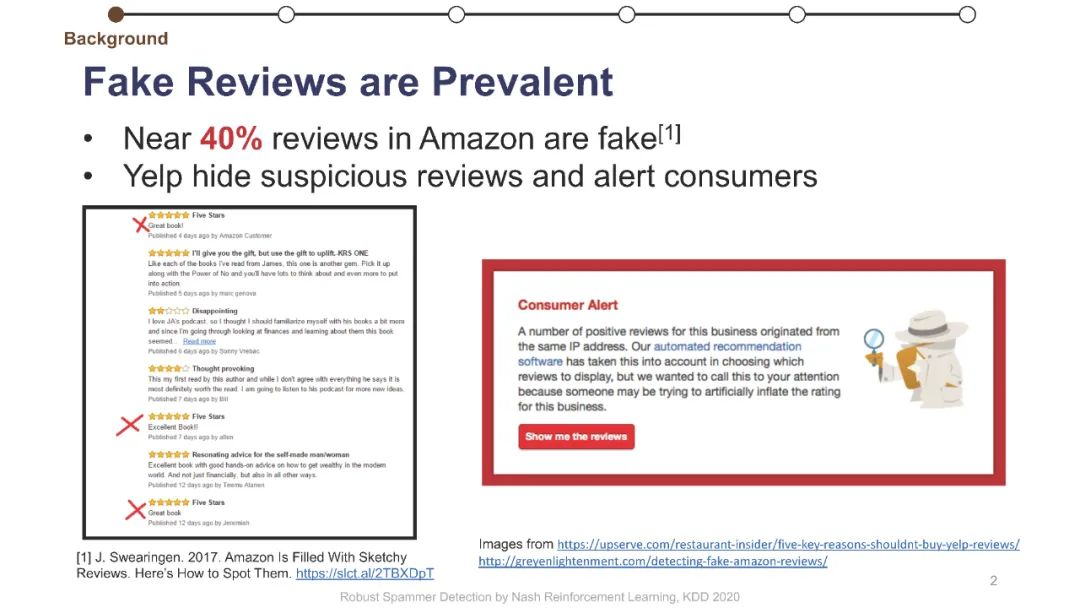
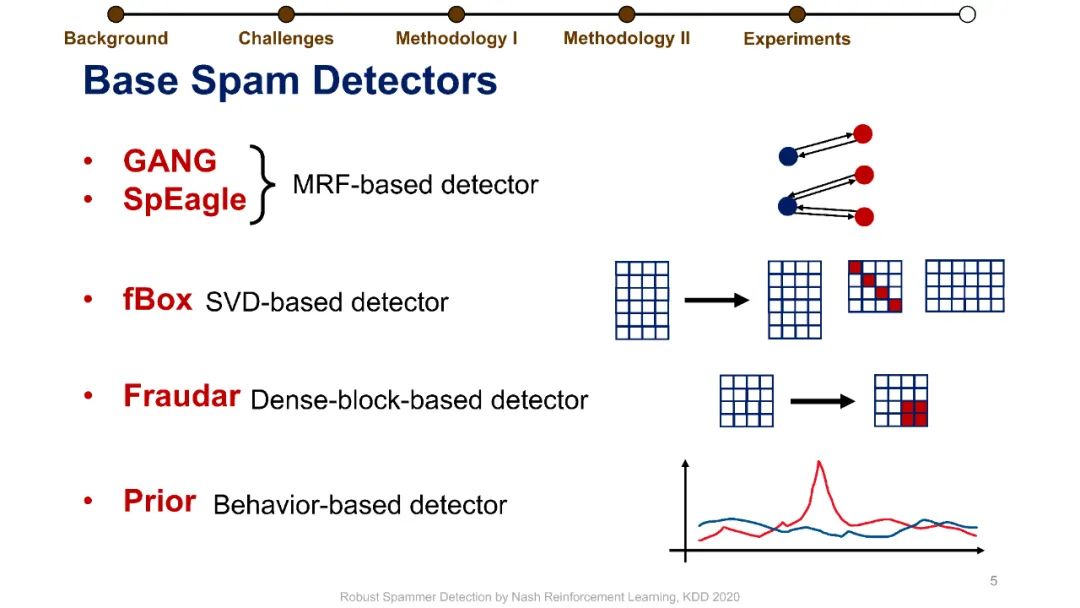
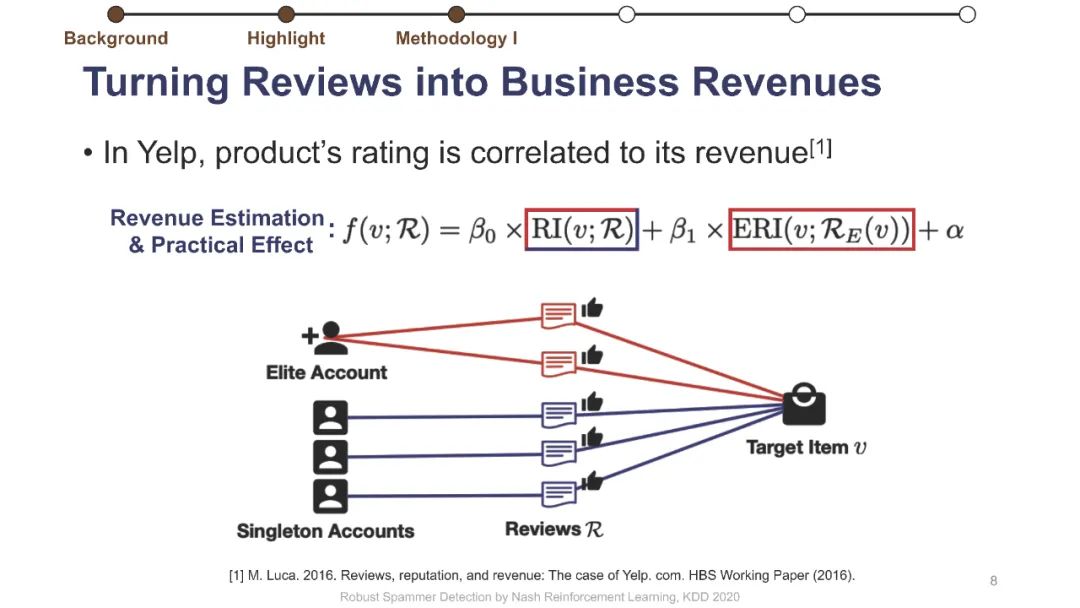
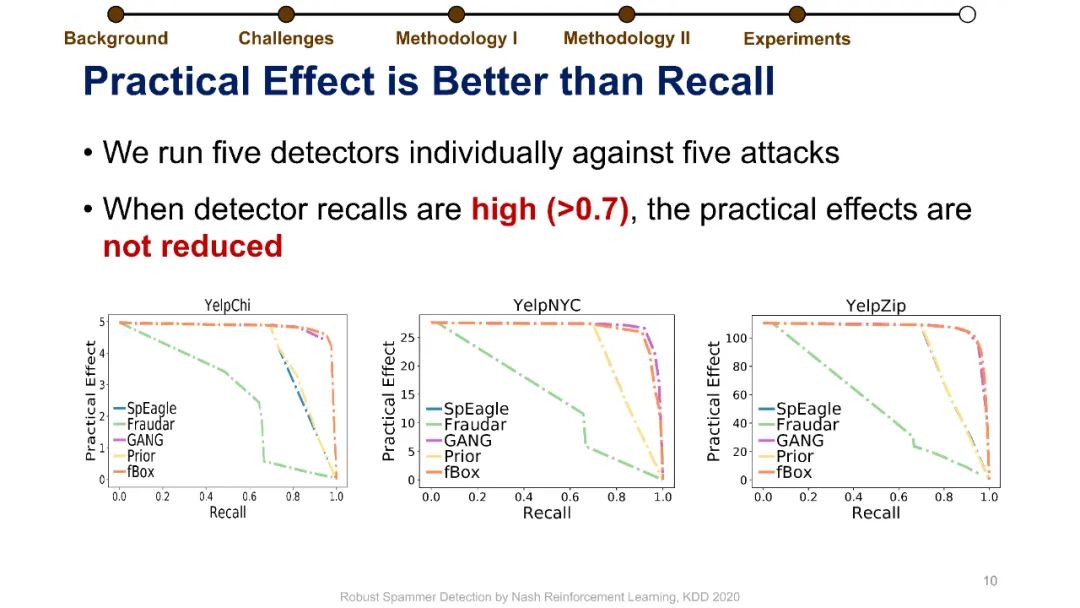
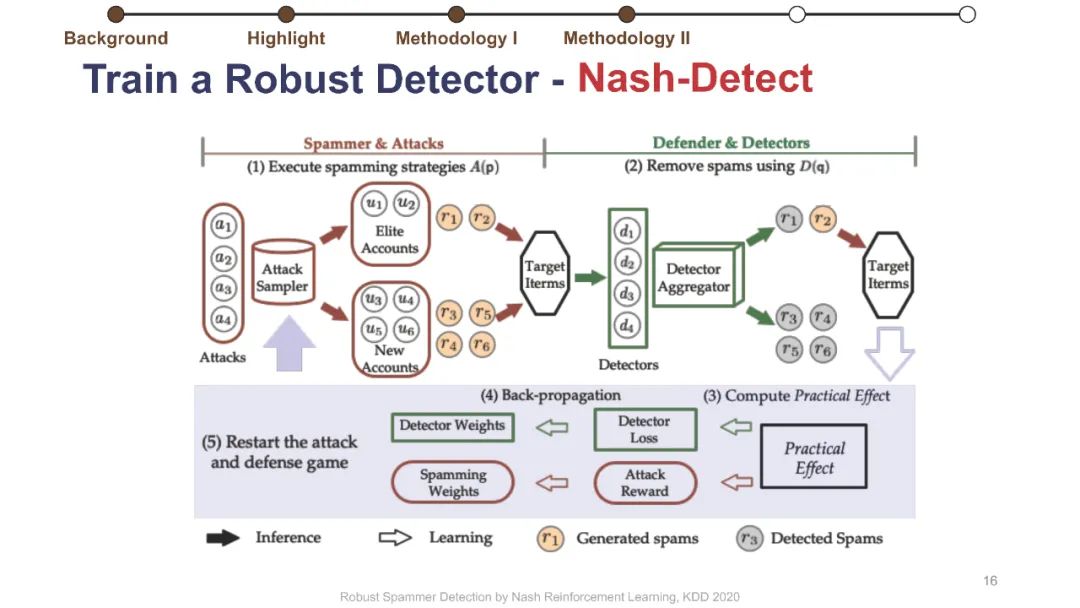
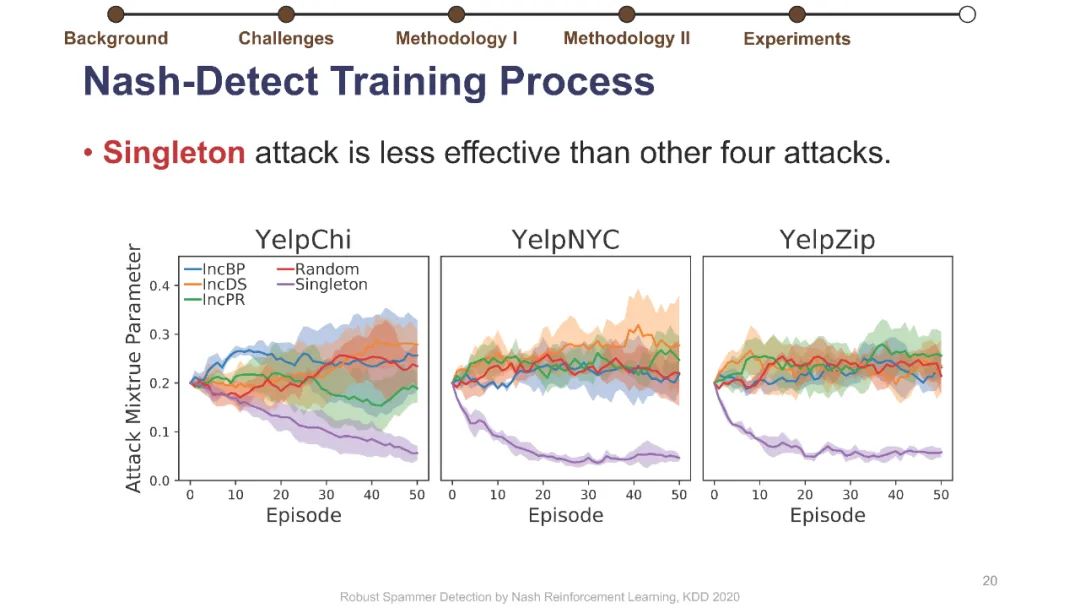
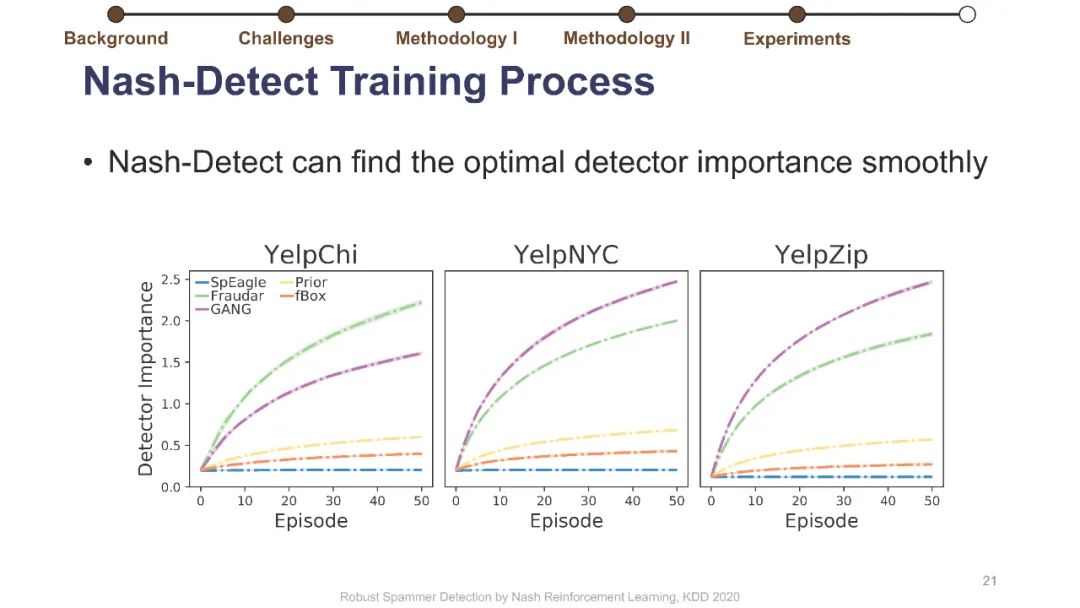
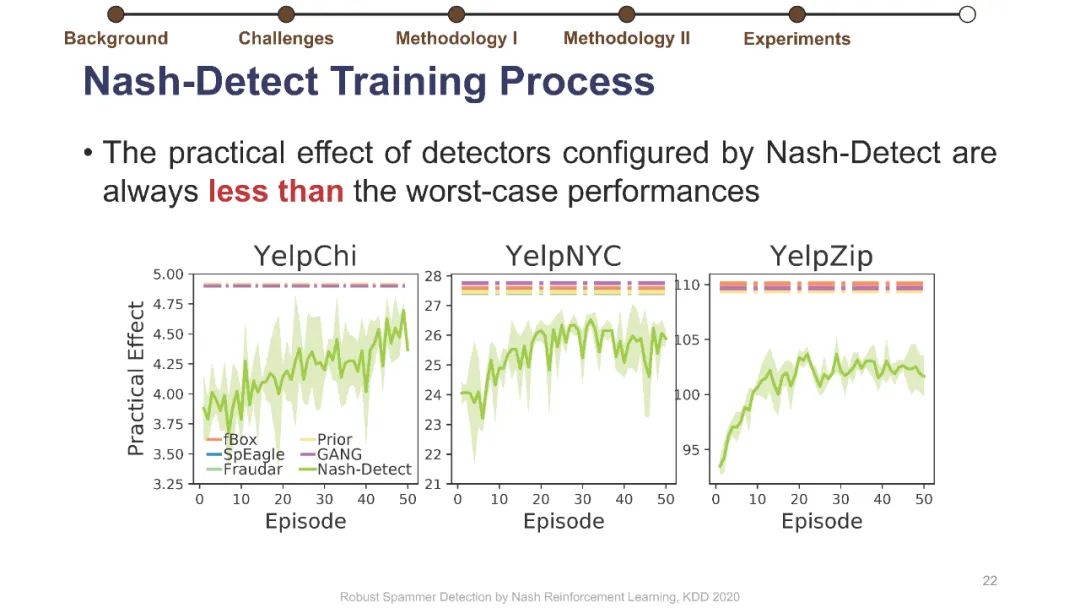
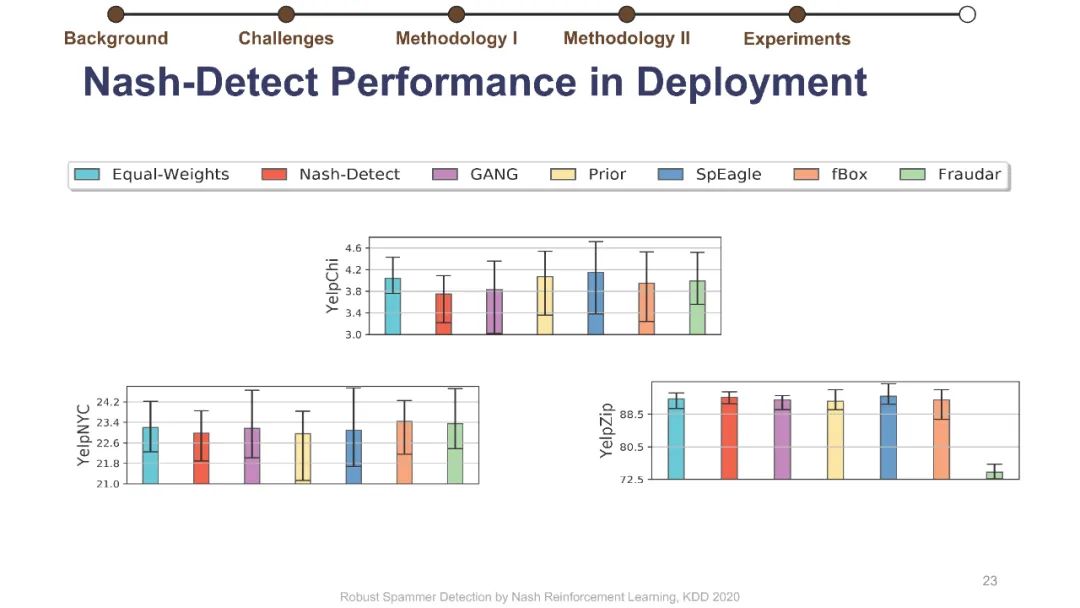
在线评论为客户提供产品评估以做出决策。不幸的是,这些评估可能会被专业的垃圾邮件发送者使用虚假的评论(“垃圾邮件”)来操纵,而这些专业的垃圾邮件发送者通过适应部署的检测器,已经学会了越来越阴险和强大的垃圾邮件发送策略。垃圾邮件策略很难捕捉,因为随着时间的推移,它们会迅速变化,垃圾邮件发送者和目标产品之间也会不同,更重要的是,在大多数情况下,它们仍然是未知的。此外,现有的大多数检测器关注的是检测精度,这与保持产品评价的可信度的目标不是很一致的。为了解决这些挑战,我们制定了一个极大极小游戏,垃圾邮件发送者和垃圾邮件检测器在他们的实际目标上相互竞争,而不仅仅是基于检测的准确性。博弈的纳什均衡导致稳定的检测器,对于任何混合检测策略都是不可知的。然而,对于典型的基于梯度的算法来说,该博弈没有封闭形式的解,不可微。我们将博弈转化为两个依赖的马尔可夫决策过程(MDPs),以实现基于多武装强盗和政策梯度的高效随机优化。我们在三个大型综述数据集上使用各种最新的垃圾邮件发送和检测策略进行了实验,结果表明,该优化算法能够可靠地找到一种均衡检测器,能够有效地防止使用任何混合垃圾邮件发送策略的垃圾邮件发送者达到他们的实际目标。我们的代码可以在https://github.com/YingtongDou/Nash-Detect获得。
https://www.zhuanzhi.ai/paper/a9e46ee7f8597a7005abbdf77b9db5a7












专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“NRL” 可以获取《【KDD2020】基于纳什强化学习的鲁棒垃圾邮件发送者检测》专知下载链接索引


登录查看更多
相关内容
Arxiv
13+阅读 · 2019年11月14日
Arxiv
5+阅读 · 2018年1月17日



相关VIP内容
相关资讯