终于有人把服务调用说清楚了
导读:RPC,微服务,Service Mesh这些服务之间的调用是什么原理?
作者 codedump codedump.info 博主,多年从事互联网服务器后台开发工作。可访问作者博客阅读 codedump 更多文章。
本文专注于演化过程中每一步的为什么(Why)和是什么(What)上面,尽量不在技术细节(How)上面做太多深入。
服务的三要素
一般而言,一个网络服务包括以下的三个要素:
地址:调用方根据地址访问到网络接口。地址包括以下要素:IP地址、服务端口、服务协议(TCP、UDP,etc)。
协议格式:协议格式指的是该协议都有哪些字段,由接口提供者与协议调用者协商之后确定下来。
协议名称:或者叫协议类型,因为在同一个服务监听端口上面,可能同时提供多种接口服务于调用方,这时候需要协议类型(名称)来区分不同的网络接口。
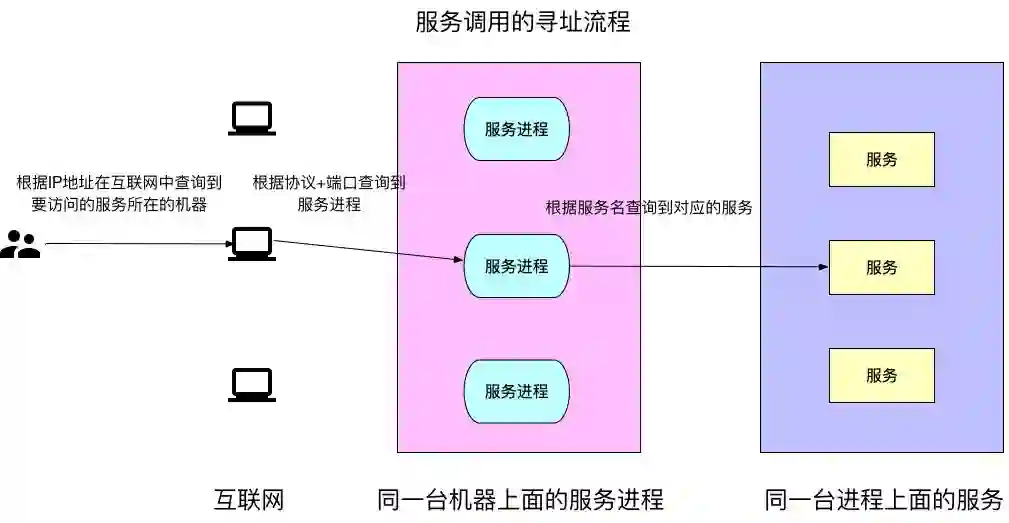
需要说明在服务地址中:
IP地址提供了在互联网上找到这台机器的凭证。
协议以及服务端口提供了在这台机器上找到提供服务的进程的凭证。
这都属于TCPIP协议栈的知识点,不在这里深入详述。
这里还需要对涉及到服务相关的一些名词做解释。
服务实例:服务对应的IP地址加端口的简称。需要访问服务的时候,需要先寻址知道该服务每个运行实例的地址加端口,然后才能建立连接进行访问。
服务注册:某个服务实例宣称自己提供了哪些服务,即某个IP地址+端口都提供了哪些服务接口。
服务发现:调用方通过某种方式找到服务提供方,即知道服务运行的IP地址加端口。
基于IP地址的调用
最初的网络服务,通过原始的IP地址暴露给调用者。这种方式有以下的问题:
IP地址是难于记忆并且无意义的。
另外,从上面的服务三要素可以看到,IP地址其实是一个很底层的概念,直接对应了一台机器上的一个网络接口,如果直接使用IP地址进行寻址,更换机器就变的很麻烦。
“尽量不使用过于底层的概念来提供服务”,是这个演化流程中的重要原则,好比在今天已经很少能够看到直接用汇编语言编写代码的场景了,取而代之的,就是越来越多的抽象,本文中就展现了服务调用这一领域在这个过程中的演进流程。
在现在除非是测试阶段,否则已经不能直接以IP地址的形式将服务提供出去了。
域名系统
前面的IP地址是给主机做为路由器寻址的数字型标识,并不好记忆。此时产生了域名系统,与单纯提供IP地址相比,域名系统由于使用有意义的域名来标识服务,所以更容易记忆。另外,还可以更改域名所对应的IP地址,这为变换机器提供了便利。有了域名之后,调用方需要访问某个网络服务时,首先到域名地址服务中,根据DNS协议将域名解析为相应的IP地址,再根据返回的IP地址来访问服务。
从这里可以看到,由于多了一步到域名地址服务查询映射IP地址的流程,所以多了一步解析,为了减少这一步带来的影响,调用方会缓存解析之后的结果,在一段时间内不过期,这样就省去了这一步查询的代价。
协议的接收与解析
以上通过域名系统,已经解决了服务IP地址难以记忆的问题,下面来看协议格式解析方面的演进。
一般而言,一个网络协议包括两部分:
协议包头:这里存储协议的元信息(meta infomation),其中可能会包括协议类型、报体长度、协议格式等。需要说明的是,包头一般为固定大小,或者有明确的边界(如HTTP协议中的\r\n结束符),否则无法知道包头何时结束。
协议包体:具体的协议内容。
无论是HTTP协议,又或者是自定义的二进制网络协议,大体都由这两部分组成。
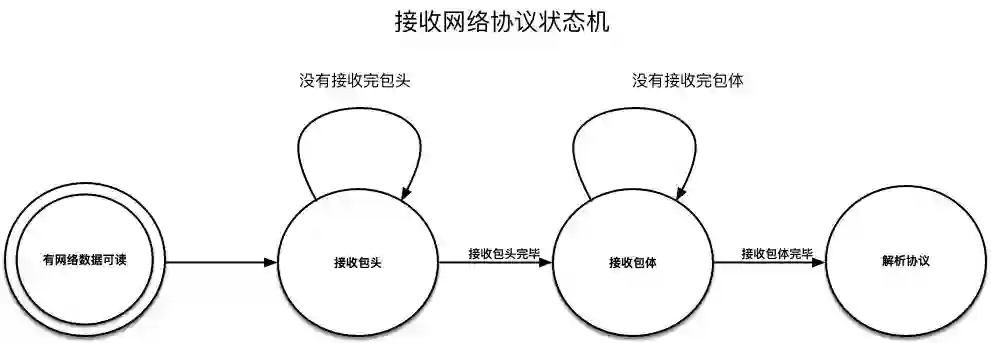
由于很多时候不能一口气接收完毕客户端的协议数据,因此在接收协议数据时,一般采用状态机来做协议数据的接收:
接收完毕了网络数据,在协议解析方面却长期停滞不前。一个协议,有多个字段(field),而这些不同的字段有不同的类型,简单的raw类型(如整型、字符串)还好说,但是遇到复杂的类型如字典、数组等就比较麻烦。
当时常见的手段有以下几种:
使用json或者xml这样的数据格式。好处是可视性强,表达起上面的复杂类型也方便,缺陷是容易被破解,传输过去的数据较大。
自定义二进制协议。每个公司做大了,在这一块难免有几个类似的轮子。笔者见过比较典型的是所谓的TLV格式(Type-Length-Value),自定义二进制格式最大的问题出现在协议联调与协商的时候,由于可视性比较弱,有可能这边少了一个字段那边多了一个字段,给联调流程带来麻烦。
上面的问题一直到Google的Protocol Buffer(以下简称PB)出现之后才得到很大的改善。PB出现之后,也有很多类似的技术出现,如Thrift、MsgPack等,不在这里阐述,将这一类技术都以PB来描述。
与前面的两种手段相比,PB具有以下的优点:
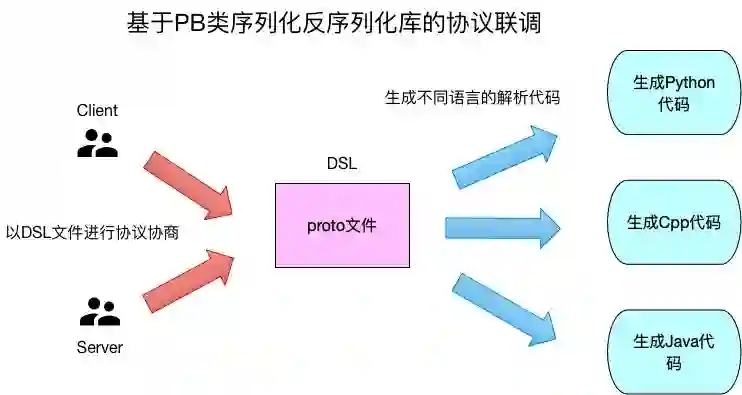
使用proto格式文件来定义协议格式,proto文件是一个典型的DSL(domain-specific language)文件,文件中描述了协议的具体格式,每个字段都是什么类型,哪些是可选字段哪些是必选字段。有了proto文件之后,C\S两端是通过这个文件来进行协议的沟通交流的,而不是具体的技术细节。
PB能通过proto文件生成各种语言对应的序列化反序列化代码,给跨语言调用提供了方便。
PB自己能够对特定类型进行数据压缩,减少数据大小。
服务网关
有了前面的演化之后,写一个简单的单机服务器已经不难。然而,当随着访问量的增大,一台机器已经不足以支撑所有的请求,此时就需要横向扩展多加一些业务服务器。
而前面通过域名访问服务的架构就遇到了问题:如果有多个服务实例可以提供相同的服务,那么势必需要在DNS的域名解析中将域名与多个地址进行绑定。这样的方案就有如下的问题:
如何检查这些实例的健康情况,同时在发现出现问题的时候增删服务实例地址?即所谓的服务高可用问题。
把这些服务实例地址都暴露到外网,会不会涉及到安全问题?即使可以解决安全问题,那么也需要每台机器都做安全策略。
由于DNS协议的特点,增删服务实例并不是实时的,有时候会影响到业务。
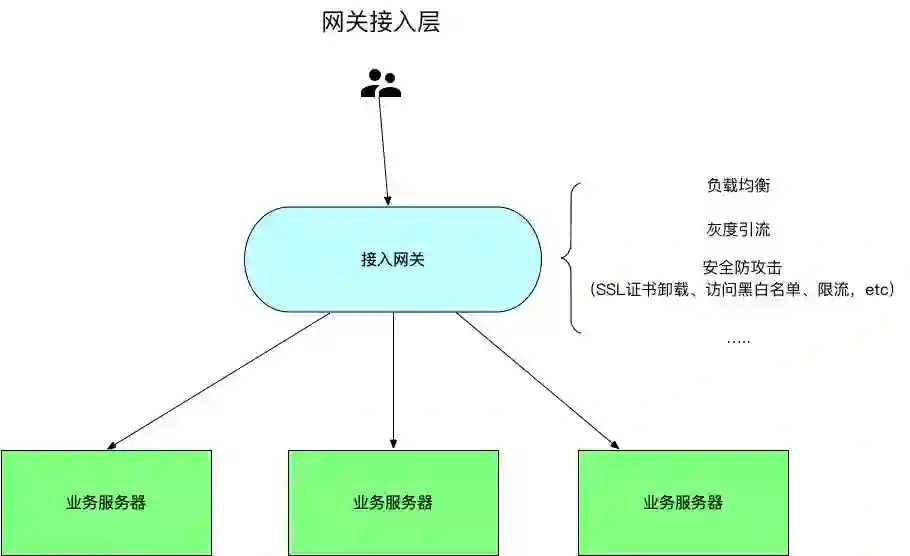
为了解决这些问题,就引入了反向代理网关这一组件。它提供如下的功能:
负载均衡功能:根据某些算法将请求分派到服务实例上。
提供管理功能,可以给运维管理员增减服务实例。
由于它决定了服务请求流量的走向,因此还可以做更多的其他功能:灰度引流、安全防攻击(如访问黑白名单、卸载SSL证书)等。
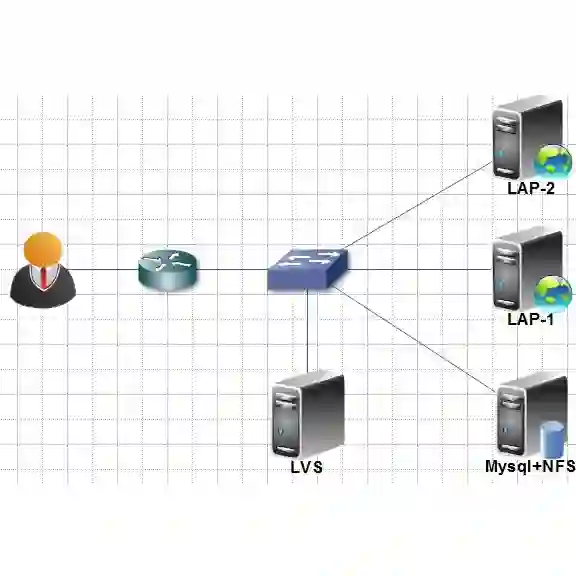
有四层和七层负载均衡软件,其中四层负载均衡这里介绍LVS,七层负载均衡介绍Nginx。
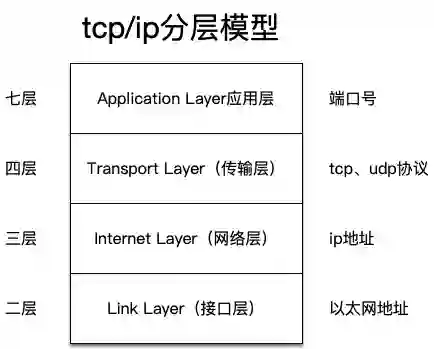
上图是简易的TCPIP协议栈层次图,其中LVS工作在四层,即请求来到LVS这里时是根据四层协议来决定请求最终走到哪个服务实例;而Nginx工作在七层,主要用于HTTP协议,即根据HTTP协议本身来决定请求的走向。需要说明的是,Nginx也可以工作在四层,但是这么用的地方不是很多,可以参考nginx的stream模块。
做为四层负载均衡的LVS
(由于LVS有好几种工作模式,并不是每一种我都很清楚,以下表述仅针对Full NAT模式,下面的表述或者有误)
LVS有如下的组成部分:
Direct Server(以下简称DS):前端暴露给客户端进行负载均衡的服务器。
Virtual Ip地址(以下简称VIP):DS暴露出去的IP地址,做为客户端请求的地址。
Direct Ip地址(以下简称DIP):DS用于与Real Server交互的IP地址。
Real Server(以下简称RS):后端真正进行工作的服务器,可以横向扩展。
Real IP地址(以下简称RIP):RS的地址。
Client IP地址(以下简称CIP):Client的地址。
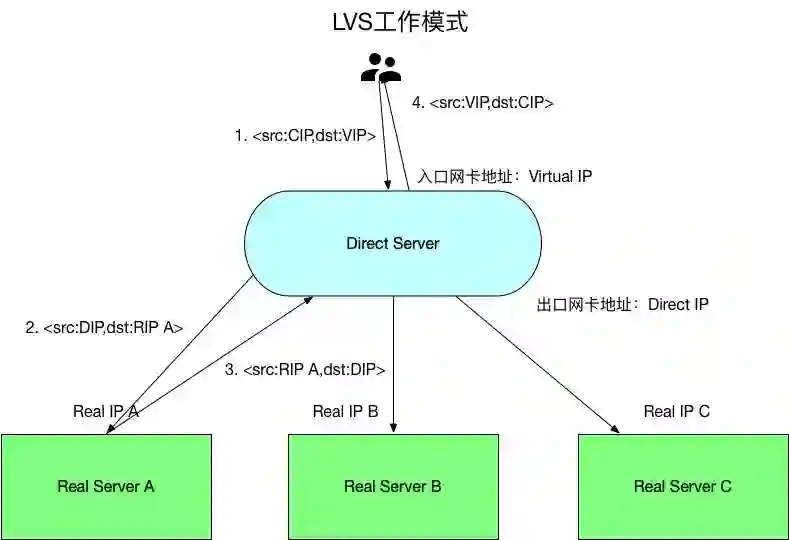
客户端进行请求时,流程如下:
使用VIP地址访问DS,此时的地址二元组为<src:CIP,dst:VIP>。
DS根据自己的负载均衡算法,选择一个RS将请求转发过去,在转发过去的时候,修改请求的源IP地址为DIP地址,让RS看上去认为是DS在访问它,此时的地址二元组为<src:DIP,dst:RIP A>。
RS处理并且应答该请求,这个回报的源地址为RS的RIP地址,目的地址为DIP地址,此时的地址二元组为<src:RIP A,dst:DIP>。
DS在收到该应答包之后,将报文应答客户端,此时修改应答报文的源地址为VIP地址,目的地址为CIP地址,此时的地址二元组为<src:VIP,dst:CIP>。
做为七层负载均衡的Nginx
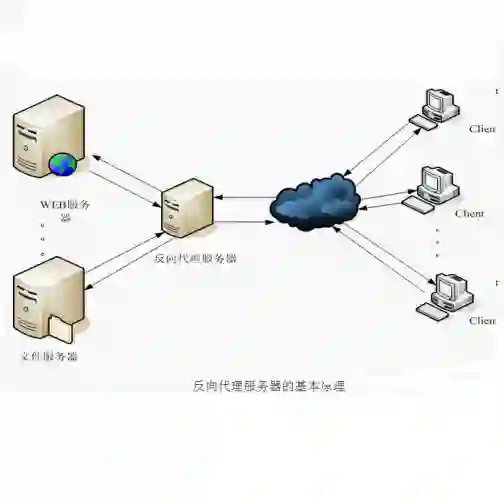
在开始展开讨论之前,需要简单说一下正向代理和反向代理。
所谓的正向代理(proxy),我的理解就是在客户端处的代理。如浏览器中的可以配置的访问某些网站的代理,就属于正向代理,但是一般而言不会说正向代理而是代理,即默认代理都是正向的。
而反向代理(reverse proxy)就是挡在服务器端前面的代理,比如前面LVS中的DS服务器就属于一种反向代理。为什么需要反向代理,大体的原因有以下的考量:
负载均衡:希望在这个反向代理的服务器中,将请求均衡的分发到后面的服务器中。
安全:不想向客户端暴露太多的服务器地址,统一接入到这个反向代理服务器中,在这里做限流、安全控制等。
由于统一接入了客户端的请求,所以在反向代理的接入层可以做更多的控制策略,比如灰度流量发布、权重控制等等。
反向代理与所谓的gateway、网关等,我认为没有太多的差异,只是叫法不同而已,做的事情都是类似的。
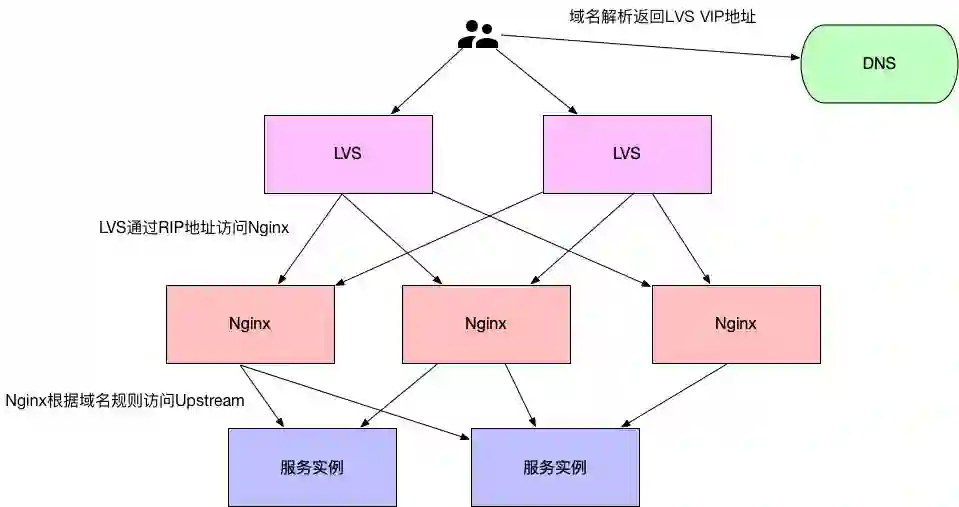
Nginx应该是现在用的最多的HTTP 七层负载均衡软件,在Nginx中,可以通过在配置的server块中定义一个域名,然后将该域名的请求绑定到对应的Upstream中,而实现转发请求到这些Upstream的效果。
如:
upstream hello {server A:11001;server B:11001;}location / {root html;index index.html index.htm;proxy_pass http://hello;}
这是最简单的Nginx反向代理配置,实际线上一个接入层背后可能有多个域名,如果配置变动的很大,每次域名以及对应的Upstream的配置修改都需要人工干预,效率会很慢。这时候就要提到一个叫DevOps的名词了,我的理解就是开发各种便于自动化运维工具的工程师。
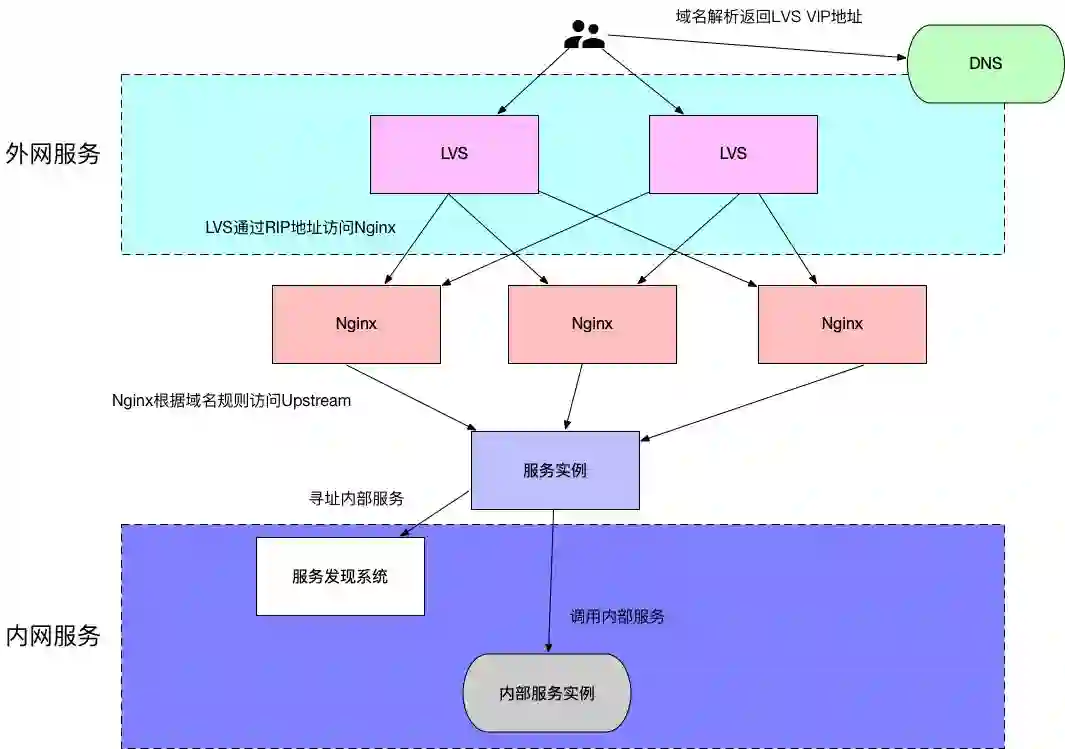
有了上面的分析,此时一个提供七层HTTP访问接口的服务架构大体是这样的:
服务发现与RPC
前面已经解决单机服务器对外提供服务的大部分问题,来简单回顾:
域名系统解决了需要记住复杂的数字IP地址的问题。
PB类软件库的出现解决协议定义解析的痛点。
网关类组件解决客户端接入以及服务器横向扩展等一系列问题。
然而一个服务,通常并不见得只由本身提供服务就可以,服务过程中可能还涉及到查询其他服务的流程,常见的如数据类服务如Mysql、Redis等,这一类供服务内调用查询的服务被成为内部的服务,通常并不直接暴露到外网去。
面向公网的服务,一般都是以域名的形式提供给外部调用者,然而对于服务内部之间的互相调用,域名形式还不够,其原因在于:
DNS服务发现的粒度太粗,只能到IP地址级别,而服务的端口还需要用户自己维护。
对于服务的健康状况的检查,DNS的检查还不够,需要运维的参与。
DNS对于服务状态的收集很欠缺,而服务状态最终应该是反过来影响服务被调用情况的。
DNS的变更需要人工的参与,不够智能以及自动化。
综上,内网间的服务调用,通常而言会自己实现一套“服务发现”类的系统,其包括以下几个组件:
服务发现系统:用于提供服务的寻址、注册能力,以及对服务状态进行统计汇总,根据服务情况更改服务的调用情况。比如,某个服务实例的响应慢了,此时分配给该实例的流量响应的就会少一些。而由于这个系统能提供服务的寻址能力,所以一些寻址策略就可以在这里做,比如灰度某些特定的流量只能到某些特定的实例上,比如可以配置每个实例的流量权重等。
一套与该服务系统搭配使用的RPC库,其提供以下功能:
服务提供方:使用RPC库注册自己的服务到服务发现系统,另外上报自己的服务情况。
服务调用方:使用RPC库进行服务寻址,实时从服务发现系统那边获取最新的服务调度策略。
提供协议的序列化、反序列化功能,负载均衡的调用策略、熔断限流等安全访问策略,这部分对于服务的提供方以及调用方都适用。
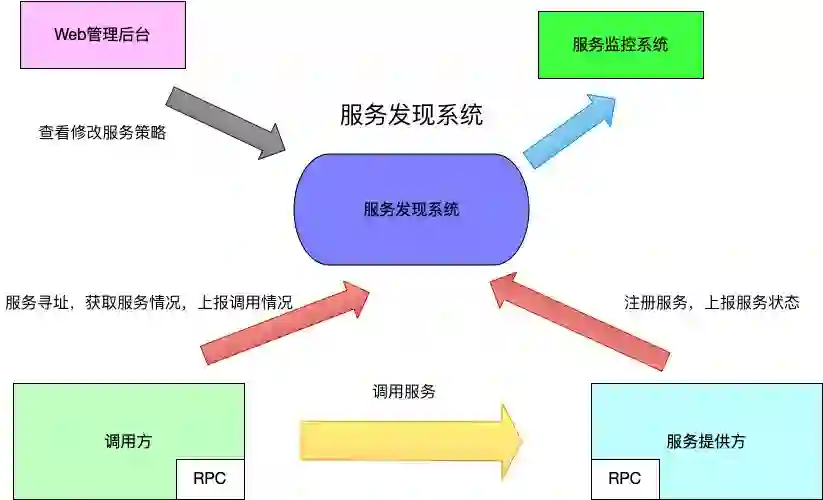
有了这套服务发现系统以及搭配使用的RPC库之后,来看看现在的服务调用是什么样的。
写业务逻辑的,再也不用关注服务地址、协议解析、服务调度、自身服务情况上报等等与业务逻辑本身并没有太多关系的工作,专注于业务逻辑即可。
服务发现系统一般还有与之搭配的管理后台界面,可以通过这里对服务的策略进行修改查看等操作。
对应的还会有服务监控系统,对应的这是一台实时采集服务数据进行计算的系统,有了这套系统服务质量如何一目了然。
服务健康状态的检查完全自动化,在状况不好的时候对服务进行降级处理,人工干预变少,更加智能以及自动化。
现在服务的架构又演进成了这样:
ServiceMesh
架构发展到上面的程度,实际上已经能够解决大部分的问题了。这两年又出现了一个很火的概念:ServiceMesh,中文翻译为“服务网格”,来看看它又能解决什么问题。
前面的服务发现系统中,需要一个与之配套的RPC库,然而这又会有如下的问题:
如果需要支持多语言,该怎么做?每个语言实现一个对应的RPC库吗?
库的升级很麻烦,比如RPC库本身出了安全漏洞,比如需要升级版本,一般推动业务方去做这个升级是很难的,尤其是系统做大了之后。
可以看到,由于RPC库是嵌入到进程之中的组件,所以以上问题很麻烦,于是就想出了一个办法:将原先的一个进程拆分成两个进程,如下图所示。
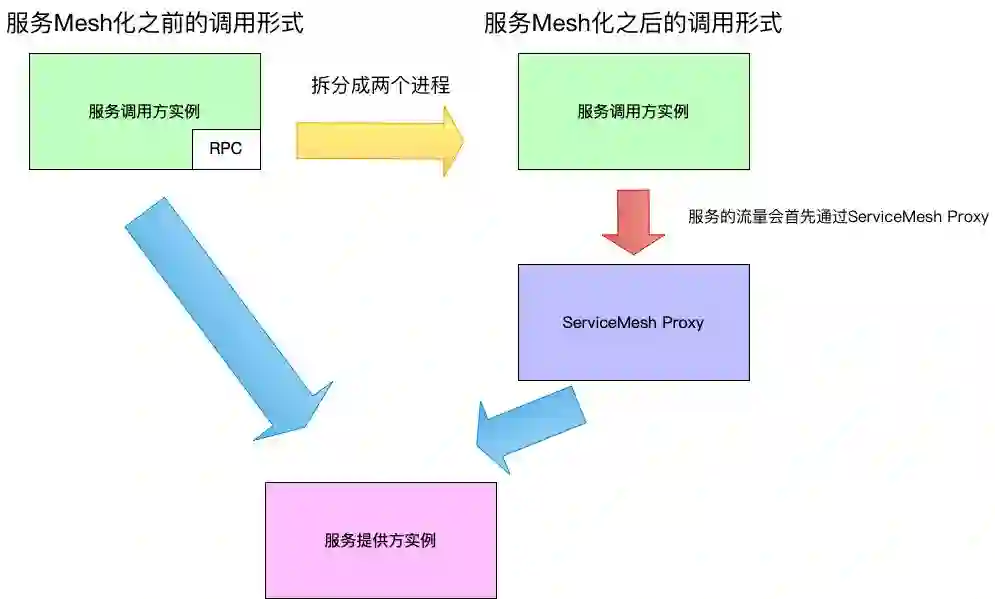
在服务mesh化之前,服务调用方实例通过自己内部的RPC库来与服务提供方实例进行通信。
在服务mesh化之后,会与服务调用方同机部署一个local Proxy也就是ServiceMesh的proxy,此时服务调用的流量会先走到这个proxy,再由它完成原先RPC库响应的工作。至于如何实现这个流量的劫持,答案是采用iptables,将特定端口的流量转发到proxy上面即可。
有了这一层的分拆,将业务服务与负责RPC库作用的Proxy分开来,上面的两个痛点问题就变成了对每台物理机上面的mesh proxy的升级维护问题,多语言也不是问题了,因为都是通过网络调用完成的RPC通信,而不是进程内使用RPC库。
然而这个方案并不是什么问题都没有的,最大的问题在于,多了这一层的调用之后,势必有影响原来的响应时间。
截止目前(2019.6月),ServiceMesh仍然还是一个概念大于实际的产品。
从上面的演进历史可以看到,所谓的“中间层理论”,即“Any problem in computer science can be solved by another layer of indirection(计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决)”在这个过程中被广泛使用,比如为了解决IP地址难于记忆的问题,引入了域名系统,比如为了解决负载均衡问题引入了网关,等等。然而每引入一个中间层,势必带来另外的影响,比如ServiceMesh多一次到Proxy的调用,如何权衡又是另外的问题了。
另外,回到最开始的服务三要素中,可以看到整个演化的历史也是逐渐屏蔽了下层组件的流程,比如:
域名的出现屏蔽了IP地址。
服务发现系统屏蔽协议及端口号。
PB类序列化库屏蔽了使用者自己对协议的解析。
可以看到,演进流程让业务开发者更加专注在业务逻辑上,这类的演进流程不只发生在今天,也不会仅仅发生在今天,未来类似的演进也将再次发生。
参考阅读:
技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。转载请注明来自高可用架构「ArchNotes」微信公众号及包含以下二维码。
高可用架构
改变互联网的构建方式

长按二维码 关注「高可用架构」公众号