在Java中如何加快大型集合的处理速度

本文讨论了 Java Collections Framework 背后的目的、Java 集合的工作原理,以及开发人员和程序员如何最大限度地利用 Java 集合。
尽管 Java 已经过了 25 岁生日,仍然是当今最受欢迎的编程语言之一。超过 100 万个网站通过某种形式在使用 Java,超过三分之一的软件开发人员的工具箱中有 Java。
Java 在它的整个生命历程中经历了重大的演变。一个早期的进步出现在 1998 年,当时 Java 引入了 Collections Framework(Java Collection Framework,JCF),简化了操作 Java 对象的任务。JCF 为集合提供了标准化的接口和通用方法,减少了编程工作,并提升了 Java 程序的运行速度。
理解 Java 集合和 Java Collections Framework 之间的区别是至关重要的。Java 集合只是表示一组 Java 对象的数据结构。开发人员可以像处理其他数据类型一样处理集合,执行搜索或操作集合内容等常见任务。
Set 接口(java.util.Set)就是 Java 集合的一个例子。Set 是一种集合,不允许出现重复元素,也不以任何特定的顺序存储元素。Set 接口继承了 Collection(java.util.Collection)的方法,并且只包含这些方法。
除了集合之外,还有队列(java.util.Queue) 和 Map(java.util.Map)。Map 并不是真正意义上的集合,因为它们没有继承集合接口,但开发人员可以像操作集合一样操作 Map。集合、队列、列表和 Map 都有后代,比如排序集合(java.util.SortedSet)和可导航 Map(java.util.NavigableMap)。
在使用集合时,开发人员需要熟悉和理解一些特定的集合相关术语。
可修改与不可修改——正如这些术语表面上所表明的,不同的集合可能支持也可能不支持修改操作。
可变集合与不可变集合——不可变集合在创建后不能被修改。虽然在某些情况下,不可修改的集合仍然可能由于其他代码的访问而发生变化,但不可变集合会阻止这种变更。不可变集合是指能够保证 Collection 对象中不会有任何变更的集合,而不可修改的集合是指不允许“add”或“clear”等修改操作的集合。
固定大小与可变大小——这些术语仅与集合的大小有关,与集合是可修改还是可变无关。
随机访问与顺序访问——如果一个集合允许为每一个元素建立索引,那么它就是可随机访问的。在顺序访问集合中,必须通过所有前面的元素到达指定的元素。顺序访问集合更容易扩展,但搜索时间更长。初学者可能会难以理解不可修改集合和不可变集合之间的区别。不可修改集合不一定是不可变的。实际上,不可修改集合通常是可修改集合的包装器,其他代码仍然可以访问和修改被包装的可修改集合。通常需要使用集合一些时间才能在一定程度上理解不可修改集合和不可变集合。
例如,我们将创建一个可修改的按市值排名前五的加密货币列表。你可以使用 java.util.Collections.unmodifiableList() 方法创建底层可修改列表的不可修改版本。你仍然可以修改底层列表,它只是被包装成不可修改列表,但你不能直接修改不可修改的版本。
import java.util.*;public class UnmodifiableCryptoListExample {public static void main(String[] args) {List<String> cryptoList = new ArrayList<>();Collections.addAll(cryptoList, "BTC", "ETH", "USDT", "USDC", "BNB");List<String> unmodifiableCryptoList = Collections.unmodifiableList(cryptoList);System.out.println("Unmodifiable crypto List: " + unmodifiableCryptoList);// 尝试在可修改列表中再添加一种加密货币,并显示在不可修改列表中cryptoList.add("BUSD");System.out.println("New unmodifiable crypto List with new element:" + unmodifiableCryptoList);// 尝试添加并显示一个额外的加密货币到不可修改列表中——unmodifiableCryptoList.add将抛出一个未捕获的异常,println代码将无法被执行unmodifiableCryptoList.add("XRP");System.out.println("New unmodifiable crypto List with new element:" + unmodifiableCryptoList);}}
在运行代码时,你将看到对底层可修改列表添加的内容显示为对不可修改列表的修改。
但这与你创建了一个不可变列表并试图修改底层列表不同。有许多种方法可以基于现有的可修改列表创建不可变列表,下面我们使用 List.copyOf() 方法创建了一个不可变列表。
import java.util.*;public class UnmodifiableCryptoListExample {public static void main(String[] args) {List<String> cryptoList = new ArrayList<>();Collections.addAll(cryptoList, "BTC", "ETH", "USDT", "USDC", "BNB");List immutableCryptoList = List.copyOf(cryptoList);System.out.println("Underlying crypto list:" + cryptoList)System.out.println("Immutable crypto ist: " + immutableCryptoList);// 尝试添加更多的加密货币到可修改列表,但不可变列表并没有显示变化cryptoList.add("BUSD");System.out.println("New underlying list:" + cryptoList);System.out.println("New immutable crypto List:" + immutableCryptoList);// 尝试添加并显示一个新的加密货币到不可修改的列表中immutableCryptoList.add("XRP");System.out.println("New unmodifiable crypto List with new element:" + immutableCryptoList);}}
修改底层的列表后,不可变列表不显示变更。尝试修改不可变列表会直接导致抛出 UnsupportedOperationException。

在引入 JCF 之前,开发人员可以使用几个特殊的类,即 Array、Vector 和 Hashtable。但这些类有很大的局限性,除了缺乏公共接口之外,它们还难以扩展。
JCF 提供了一个用于处理集合的通用架构。集合接口包含了几个不同的组件。
公共接口——主要集合类型的表示,包括集合、列表和 Map;
实现——集合接口的特定实现,从通用的到特殊的再到抽象的。此外,还有一些与旧的 Array、Vector 和 Hashtable 类相关的遗留实现;
算法——用于操作集合的静态方法;
基础结构——对各种集合接口的底层支持。与之前相比,JCF 为开发人员提供了许多好处。值得注意的是,JCF 降低了开发人员对自己编写数据结构的需求,从而提高了 Java 编程的效率。
但是,JCF 也从根本上改变了开发人员使用 API 的方式。JCF 通过提供一组新的公共接口来处理不同的 API,简化了开发人员学习、设计和实现 API 的过程。此外,API 的互操作性也大大提升了。Eclipse Collections 就是一个例子,它是一个完全兼容不同 Java 集合类型的开源 Java 集合库。
由于 JCF 提供了更容易重用代码的结构,从而进一步提升了开发效率。其结果就是开发时间缩短了,程序质量也得到了提升。
JCF 有一个定义良好的接口层次结构。java.util.Collection 扩展了超接口 Iterable,Collection 有许多子接口和子类,如下所示。
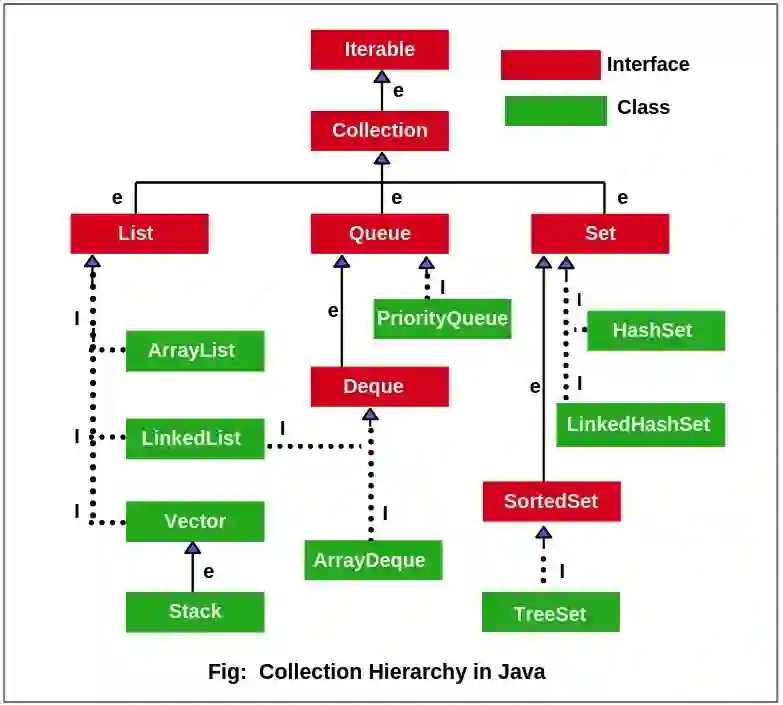
如前所述,集合是唯一性对象的无序容器,而列表是可能包含重复项的有序集合。你可以在列表中的任何位置添加元素,但其他部分仍然保留了顺序。
队列也是集合,元素被添加到一端,并在另一端被删除。也就是说,它是一种先进先出(FIFO)接口。Deque(双端队列)允许从任意一端添加或删除元素。
JCF 中的每一个接口,包括 java.util.Collection,都提供了特定的方法用于访问和操作集合的各个元素。集合提供的常用的方法有:
size()——返回集合中元素的个数;
add(Collection element) / remove(Collection object)——这些方法用于修改集合的内容。需要注意的是,当集合中有重复元素时,移除只会影响元素的单个实例;
equals(Collection object)——比较对象与集合是否等价;
clear()——删除集合中的所有元素。每个子接口也可以有其他方法。例如,尽管 Set 接口只包含来自 Collection 接口的方法,但 List 接口包含了许多用于访问特定列表元素的方法。
get(int index)——返回指定索引位置的元素;
set(int index, element)——设置指定索引位置的元素;
remove(int,index)——移除指定索引位置的元素。
随着集合元素数量的增长,它们可能会出现明显的性能问题。事实证明,集合类型的选择和集合的相关设计也会极大地影响集合的性能。
随着需要处理的数据量不断增加,Java 引入了新的处理集合的方法来提升整体性能。在 2014 年发布的 Java 8 引入了 Streams——旨在简化和提高批量处理对象的速度。自从推出以来,Streams 已经有了许多改进。
需要注意的是,流本身并不是数据结构,而是“对流中的元素进行函数式操作(例如对集合进行 map-reduce 转换)的类。”
Streams 使用方法管道来处理从数据源(如集合)接收到的数据。Streams 的每一个方法要么是一个中间方法(返回可以进一步处理的流),要么是一个终端方法(在此之后不可能进行其他流处理)。管道中的中间方法是惰性的,也就是说,它们只在必要时才进行求值。
并行执行和串行执行都存在于流中。默认情况下,流是串行的。
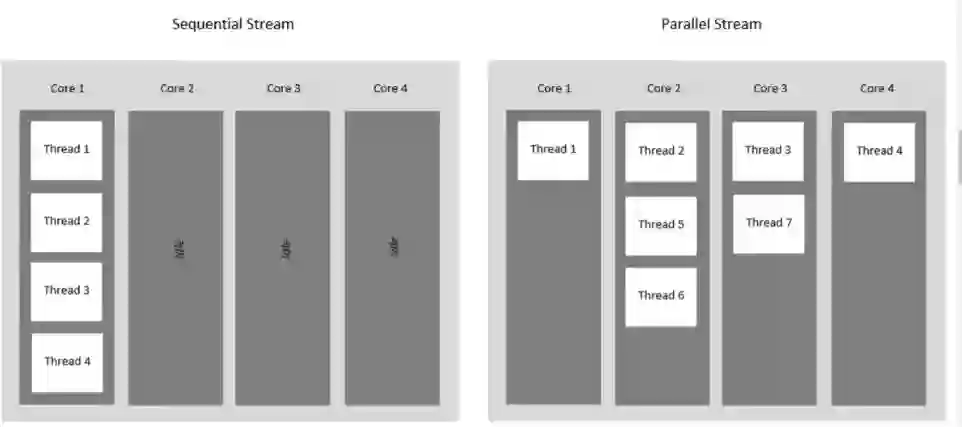
在 Java 中处理大型集合可能很麻烦。虽然 Streams 简化了大型集合的处理和编码工作,但并不总是能保证性能上的提升。事实上,程序员经常发现使用 Streams 反而会减慢处理速度。
众所周知,网站用户只会等待几秒钟的加载时间,然后他们就会离开。因此,为了提供最好的用户体验并维护开发人员提供高质量产品的声誉,开发人员必须考虑如何优化大型数据集合的处理。虽然并行处理并不总能保证提高速度,但至少是有希望的。
并行处理,即将处理任务分解为更小的块并同时执行它们,提供了一种在处理大型集合时减少处理开销的方法。但是,即使并行流处理简化了代码编写,也会导致性能下降。本质上,多线程管理开销会抵消并行运行线程所带来的好处。
因为集合不是线程安全的,并行处理可能会导致线程干扰或内存不一致(当并行线程看不到其他线程所做的修改,对相同的数据有不同的视图时)。Collections Framework 试图通过使用同步包装器在并行处理期间防止线程不一致。虽然包装器可以让集合变成线程安全的,从而实现更高效的并行处理,但它可能会产生不良的性能影响。具体来说,同步可能会导致线程争用,从而导致线程执行得更慢或停止执行。
Java 有一个用于集合的元素并行处理函数 Collection.parallelstream。默认的串行处理和并行处理之间的一个显著区别是,串行处理时总是相同的执行和输出顺序在并行处理时可能会有不同。
因此,在处理顺序不影响最终输出的场景中,并行处理会特别有效。但是,在一个线程的状态可能会影响另一个线程状态的场景中,并行处理可能会有问题。
我们来考虑一个简单的示例,在这个示例中,我们为包含 1000 个客户创建了一个应收账款列表。我们想要知道这些客户中有多少人的应收账款超过 25000 美元。我们可以按照串行或并行的处理方式检查这个列表。
import java.util.Random;import java.util.ArrayList;import java.util.List;class Customer {static int customernumber;static int receivables;Customer(int customernumber, int receivables) {this.customernumber = customernumber;this.receivables = receivables;}public int getCustomernumber() {return customernumber;}public void setCustomernumber(int customernumber) {this.customernumber = customernumber;}public int getReceivables() {return receivables;}public void setReceivables() {this.receivables = receivables;}}public class ParallelStreamTest {public static void main( String args[] ) {Random receivable = new Random();int upperbound = 1000000;List < Customer > custlist = new ArrayList < Customer > ();for (int i = 0; i < upperbound; i++) {int custnumber = i + 1;int custreceivable = receivable.nextInt(upperbound);custlist.add(new Customer(custnumber, custreceivable));}long t1 = System.currentTimeMillis();System.out.println("Sequential Stream count: " + custlist.stream().filter(c ->c.getReceivables() > 25000).count());long t2 = System.currentTimeMillis();System.out.println("Sequential Stream Time taken:" + (t2 - t1));t1 = System.currentTimeMillis();System.out.println("Parallel Stream count: " + custlist.parallelStream().filter(c ->c.getReceivables() > 25000).count());t2 = System.currentTimeMillis();System.out.println("Parallel Stream Time taken:" + (t2 - t1));}}
代码执行结果表明,在处理数据集合时,并行处理可能会提升性能:
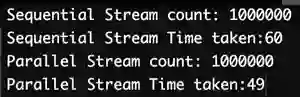
但需要注意的是,每次执行代码时,你可能获得不同的结果。在某些情况下,串行处理仍然优于并行处理。
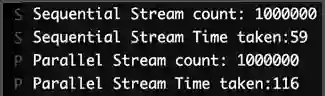
在本例中,我们使用 Java 的原生进程来分割数据和分配线程。
不幸的是,对于上述两种情况,Java 的原生并行处理并不总是比串行处理更快。实际上,经常会更慢。
例如,并行处理对于链表没有什么用。虽然 ArrayList 很容易被分割成并行处理,但 LinkedList 却不是这样的。TreeMap 和 HashSet 介于两者之间。
Oracle 的 NQ 模型是决定是否使用并行处理的一种方法。在 NQ 模型中,N 表示需要处理的数据元素数量,Q 表示每个数据元素所需的计算量。在 NQ 模型中,计算 N 和 Q 的乘积,数值越大,说明并行处理提高性能的可能性越大。
在使用 NQ 模型时,N 和 Q 之间存在反比关系,即每个元素所需的计算量越高,并行处理的数据集就越小。经验法则是,对于较低的计算需求,包含 10000 个元素的数据集是使用并行处理的基线。
除此之外,还有其他更高级的方法来优化 Java 集合中的并行处理。例如,高级开发人员可以调整集合中数据元素的分区,以最大化并行处理性能。还有一些第三方的 JCF 插件和替代品可以提升性能。但是,初学者和中级开发人员应该重点了解哪些操作可以从 Java 的原生并行处理特性中受益。
在大数据世界里,想要创建高性能的网页和应用程序,必须找到改进大量数据处理的方法。Java 提供了内置的集合处理特性帮助开发人员改进数据处理,包括 Collections Framework 和原生并行处理功能。开发人员需要熟悉如何使用这些特性,并了解可以时候可以使用原生特性,什么时候应该使用并行处理。
作者简介:
Nahla Davies 是一名软件开发人员和技术作家。在全职从事技术写作之前,她曾在一家体验式品牌企业担任首席程序员,该组织的客户包括三星、时代华纳、Netflix 和索尼。
原文链接:
https://www.infoq.com/articles/java-collections-streams/
点击底部阅读原文访问 InfoQ 官网,获取更多精彩内容!
NGINX 局限太多,Cloudflare 最终放弃它并用 Rust 自研了全新替代品
CEO 们突然介入到 IT 建设, 企业纷纷迁出 VM 虚拟机基础设施



