微信「扫一扫识物」 的背后技术揭秘
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:breezecheng,腾讯 WXG 应用研究员
微信扫码已经深入人心, 微信扫物 12.23 日 ios 版本正式上线,从识别特定编码形态的图片(二维码/小程序码/条形码/扫翻译),到精准识别自然场景中商品图片(鞋子/箱包/美妆/服装/家电/玩具/图书/食品/珠宝/家具/其他商品),有哪些难点需要去克服? 扫物以图片(视频)作为媒介,聚合微信内部有价值的生态内容如电商,百科,资讯进行展示, 会催生哪些新的落地场景?本文将细细道来.
一. 扫一扫识物概述
1.1 扫一扫识物是做什么的?
扫一扫识物是指以图片或者视频(商品图:鞋子/箱包/美妆/服装/家电/玩具/图书/食品/珠宝/家具/其他商品)作为输入媒介来挖掘微信内容生态中有价值的信息(电商+百科+资讯,如图 1 所示),并展示给用户。这里我们基本覆盖了微信全量优质小程序电商涵盖上亿商品 SKU,可以支持用户货比 N 家并直接下单购买,百科和资讯则是聚合了微信内的搜一搜、搜狗、百度等头部媒体,向用户展示和分享与该拍摄商品相关的资讯内容。

百闻不如一试,欢迎大家更新 ios 新版本微信 → 扫一扫 → 识物自行体验,也欢迎大家通过识物界面中的反馈按键向我们提交体验反馈。图 2 即为扫物实拍展示。
图 2. 扫一扫识物实拍展示
1.2 扫一扫识物落地哪些场景?
扫一扫识物的目的是开辟一个用户直达微信内部生态内容的一个新窗口,该窗口以用户扫图片的形式作为输入,以微信生态内容中的百科、资讯、电商作为展示页提供给用户。除了用户非常熟悉的扫操作,后续我们会进一步拓展长按识图操作,将扫一扫识物打造成用户更加触手可及的运用。扫一扫识物的落地场景如下图所示,主要涵盖 3 大部分:
a.科普知识。用户通过扫物体既可以获得微信生态中关于该物体相关的百科、资讯等小常识或者趣闻,帮助用户更好的了解该物体;
b.购物场景。同款搜索功能支持用户对于见到的喜爱商品立即检索到微信小程序电商中的同款商品,支持用户扫即购;
c.广告场景。扫一扫识物可以辅助公众号文章、视频更好的理解里面嵌入的图片信息,从而更好的投放匹配的广告,提升点击率。
1.3 扫一扫识物给扫一扫家族带来哪些新科技?
对于扫一扫,大家耳熟能详的应该是扫二维码、扫小程序码,扫条形码,扫翻译。无论是各种形态的码还是文本字符,都可以将其认为是一种特定编码形态的图片,而识物则是识别自然场景图片,对于扫一扫家族来说是一个质的飞跃,我们希望从识物开始,进一步拓展扫一扫对自然场景图片的理解能力,比如扫酒,扫车,扫植物,扫人脸等等服务,如下图 3 所示。

二. 扫一扫识物技术解析
2.1 扫一扫识物整体框架
下面我们为大家重点介绍扫一扫识物的完整技术实现方案,图 4 展示的是扫一扫的整体框架示意图。该框架主要包含 4 大部分:
1)用户请求环节;
2)商检离线入库环节;
3)同款检索+资讯百科获取环节;
4)模型训练部署环节。
四大环节抽取核心技术模块可以总结为三个,即为数据构建、算法研发、平台建设,我们将一一道来。

数据构建
AI 时代数据为王,数据构建的目的就是为了更好的服务于 AI 算法,比如对于用户请求图、商家入库图都需要进行主体检测、类目预测、特征提取,都需要有高质量的训练数据来支撑检测模型、分类模型以及检索模型。一言以蔽之,数据决定了整个扫一扫识物性能上限。
算法研发
算法研发是为了充分的利用已有的数据,为识物的每一个环节如检测、类目预测,检索特征提取都在精度、速度上到达最优的折中,从而实现用户任意商品请求都能获得精准的同款召回,以及更加相关的资讯展示。算法研发的好坏决定了扫一扫识物的性能下限。
平台建设
无论是数据建设,算法研发,模型上线都离不开一个好的平台支持,我们为扫一扫识物从数据清洗,模型训练,部署,上线打造了一个完整的平台。可以说,平台建设关乎研发效率,决定了扫一扫识物能否实现上线。
2.2 扫一扫识物数据建设
扫一扫识物数据构建分为两大块,一大块是用于模型训练的训练数据建设,另一大块则是支撑用户任意商品检索请求的线上检索库构建。
模型训练数据库构建 训练数据库主要是支援模型训练,如同款检索中需要的物体检测模型,类目预测模型以及同款检索模型等,在百科资讯搜索中则需要训练商品标题文本分类模型,命名实体识别模型等。本篇文章我们重点关注视觉语义这一块的算法策略,对于百科资讯用到 NLP 算法我们在下一篇文章中详细阐述。2.3 章节中我们将阐述数据构建中用到的图片去重,检测数据库标注用到的半监督学习算法,以及检索数据构建提出的半自动同款去噪+合并算法。
")
在线检索数据库构建 在线检索数据库的覆盖范围至关重要,决定了能否支持用户的任意商品搜索请求。我们采用定向导入、长尾加爬、访问重放、主动发现四种策略不断扩展我们的商家图规模,目前已覆盖 95%+常见商品。这一数字还在不断上涨中,我们希望后续对用户的任意商品请求都能够精确召回同款商品。
2.2.1 图片去重
无论是检测数据库还是检索数据库,第一步都是清理掉重复图片,这样既可以降低存储压力,也能够降低模型训练压力。常用的图片去重算法有如下 2 种:
1)MD5 去重,去除完全相同的图片;
2)哈希去重,除完全重复图外,还能去除在原图上进行了些简单加工的图片,如改变原图的亮度、尺度、对比度、边沿锐化、模糊、色度以及旋转角度,这些图片保留意义也不大,因为在模型训练中采用数据增强策略可以覆盖到。常用的哈希去重主要有 aHash,dHash,pHash 等,详细理解可以参阅相关文章[1,2],我们重点对比各个去重算法的速度和鲁棒性,如下图 6 所示。

对比图 6 中的数字可知,dHash 的去重速度最快,因为只需要计算临近像素的亮度差异,非常简单易处理,而且对于图片简单的 ps 操作具有较好的容忍程度,除图片旋转外,诸如亮度、尺度、对比度、边沿锐化、模糊、色度等较小改变都具有很好的抗干扰能力,有助于我们清理更多的无效图片。最终我们也是采用 dHash 对我们训练库进行去重操作,11 类全量爬虫商品库中,大概清理掉了 30%的重复图片,累计有 300w 左右。
2.2.2 检测数据库构建
从图 4 展示的整体框架可知,扫一扫识物的首要步骤就是主体检测,即先定位用户感兴趣的区域,去除掉背景对后续环节的干扰。主体检测基本是大部分以图搜图产品的公认首要操作,如下图 7 所示的阿里的拍立淘,百度的拍照识图,以及微软的识花小程序。当然主体检测的算法各有差异,如拍立淘采用的是物体检测算法,百度识图采用的是显著性区域预测,微软识花需要用户配合定位。为了解放用户,我们希望算法能够自动定位商品区域,考虑到显著性区域预测很难处理多个商品出现在视野的情况,类似拍立淘,我们采用更加精确的物体检测算法来定位商品位置,并选择置信度最高的商品进行后续的商品检索以及资讯百科展示。

当然物体检测模型离不开检测数据库的支撑,这里我们对比三种标注物体 boundbox 位置和类别的方法,即人工检测标注,弱监督检测标注以及半监督学习检测标注。
人工检测标注 常用的人工检测标注工具 labelimg 如下图所示,我们需要标注爬虫的商品库中 11 类商品出现的位置以及对应的类别标签。考虑到人工标注的时间和金钱成本都非常巨大,我们只采用该策略标注少量的样本,更多的采用后续的算法进行自动检测框标注。

弱监督检测标注 该算法的核心思想是标注图片中所含物体的类别相比标注框+类别的时间成本要低很多,如何只利用全图类别信息来自动推断物体的位置信息,从而完成自动检测标注呢?学术界和工业界有大量的研究者对这一方向进行了研究和探索,主要思路都是挖掘图片中的局部显著性区域,用其来表征全图的类别语义信息,如图 9 列举了几篇代表性文章。图 9 左下角算法重点阐述下,它是业内第一篇用深度学习来做弱监督检测的文章,实验室师兄研发,我们还基于该算法参加过 ImageNet14 的竞赛,拿了一个小分支的冠军。尽管愿景很美好,弱监督检测算法有个严重的缺陷,就是很容易拟合到局部区域,比如从大量猫的图片中拟合到的位置是猫脸区域,而很难定位到完整的猫的位置,这对于我们同款商品检索来说是难于接受的,我们需要精确召回同一款商品(细粒度检索),所有信息量都非常重要,因而该算法基本被我们 pass 掉了。

半监督检测标注 相比弱监督检测算法,半监督检测算法更加贴近任务本身:基于少量的人工标注检测框+检测开源数据库初始化检测模型,然后用该模型去自动标注剩下的商品数据库,并用增加的标注来重新更新检测模型,之后迭代进行模型更新和自动标注。当然为了控制上述环节持续正向激励,我们为对置信度较低的标注样本进行人工校正,算法示意图如下所示。基于该算法,我们完成了整个商品检测数据库的标注,11 类全量商品库标注了上百万个检测框,其中人工启动标注只有十几万,其他的基本都是基于算法自动标注,大大节省了标注的时间和金钱成本。

2.2.3 检索数据库构建
完成了图片去重和主体检测之后,大家一个自然的想法就是,能否直接用这批抠图后的商品图结合 SKU 货号进行检索模型的训练,答案是否定的,抠图之后的商品图还存在两大问题:1.同款噪声问题,即同一个 SKU 下面存在非同款的图片,这可能是由于用户上传错误图片、商家展示的是局部细节图、检测抠图错误等因素导致;2.同款合并问题,不同的 SKU 可能对应的是同一个款式商品,不加以合并,会导致分类类别数目急剧膨胀,而且模型难于收敛。因此,在训练检索模型之前,我们需要完成同款去噪和同款合并两个环节,我们提出了基于自动聚类的同款去噪算法和基于混淆分类矩阵的同款合并算法,如下图 11 所示。后续我们将分别对这个算法进行解析。

2.2.3.1 同款去噪
我们采用聚类算法来自动去除每个商品 SKU 中存在的噪声图片。我们研究了常用的聚类算法,如下图 12 所示,

关于这些算法的理论及实现流程,大家感兴趣可以参阅[7]。我们在图 13 中对上述聚类算法在常见指标上进行了对比分析,考虑到商品 SKU 聚类的特性,我们更加关注聚类算法的抗噪声能力,对不同 SKU 特征分布的适应性以及处理速度,综合分析实践后,我们选择了 DBSCAN 作为我们的聚类算法,并对其进行改造来更加适配商品的聚类去噪,我们称其为层次法 DBSCAN。

层次法 DBSCAN 主要分为两个环节,分别为 step1.寻找距离最紧致的最大类簇,以及 step2.重访噪声样本, 捞回同款困难样本,增加多样性。下面我简要介绍这两个步骤。
层次法 DBSCAN 步骤 1 该步骤的目的是挑选 SKU 中距离最紧致的最大类簇,因为 SKU 中的同款样本相对噪声样本分布更有规律,数目也一般会更多。算法示意图如下图 14 所示,我们邻域内最小样本数目设置为 2,将所有的核心点联通后,假设有多个类簇,我们选择数目最多的类簇作为我们挑选的商品图片,剩下的样本作为噪声样本。

图 15 展示了某个实际 SKU 的步骤一聚类效果,从中我们可以发现最大聚类由于控制的阈值很严格,样本分布很单一化,而在噪声中实际有一些误为噪声的困难正样本(用红圈示意)。这些困难的正样本对于提升检索模型的鲁棒性和泛化能力非常重要,因而我们需要把噪声中的困难正样本捞回到左边的最大类簇中来,即为步骤 2 完成的事情。

层次法 DBSCAN 步骤 2 为了将噪声样本中的困难正样本捞回,提升训练样本的丰富性,我们需要重访噪声样本,计算噪声样本和最大类簇的距离,并将满足阈值条件的近距离噪声样本重新分配给最大类簇,如下图 16 所示。

2.2.3.2 同款合并
同款合并的目的是为了将不同 SKU 但是同一款式的商品进行合并,从而得到实际有效的款式类目。我们采用分类混淆矩阵来完整自动同款合并。基于合并前的数据我们可以训练初始分类模型,并计算任意两个 SKU 之间的混淆概率。混淆概率定义为 p_ij=c_ij/n_i,其中 p_ij 为第 i 类预测为第 j 类的混淆概率,c_ij 为模型将第 i 类预测为第 j 类的样本个数,n_i 为第 i 类样本的实际个数。某个 SKU 的混淆概率矩阵如下所示,可知,当两个 SKU 实际为同一个款式时,如图 17 左中类目 1 和 3,那么他们之间很难区分,混淆的概率就会偏大。通过设定合并同款的分数阈值,我们能够将同款 SKU 进行合并。实际操作过程中,我们采用下图右边的迭代步骤进行,即先采用高的阈值合并置信度最高的同款,然后更新优化分类模型,并降低阈值合并更多的同款 SKU,上述步骤迭代进行,直到没有同款 SKU 需要合并。

合并完同款之后,我们得到的训练检索数据库的规模如下图所示,总共为 7w+多类目,1kw+训练样本,相比目前主流的开源数据库如 ImageNet(1000 类,130w+)和 OpenImage(6000 类,900w+),在类别和数目上都要更加丰富。
2.2.3.2 成本收益
这里我们对采用算法进行同款去噪+同款合并,和采用纯人工清理进行对比在时间和金钱上都有巨大的收益提升,加快了整个项目的迭代速度。
2.3 扫一扫识物算法研发
兵马未动,粮草先行,上一章节我们已经讲述了如何备好粮草(清洗高质量的训练数据),那么这一章节自然而然就是亮兵器了(高效利用现有训练数据的算法模型)。按照扫一扫识物整体框架,我们重点介绍视觉同款搜索涉及到的三大模块,即为物体检测、类目预测和同款检索。
2.3.1 物体检测
物体检测是扫一扫识物的第一个环节,我们需要有效的定位用户拍摄图片中的商品位置,剔除掉背景对后续同款检索的干扰。学术界和工业界对物体检测展开了大量的研究,如下图 18 所示,研究者从不同角度对检测算法进行优化,如从速度考虑分为 one-stage 和 two-stage 检测;从 anchor 出发分为 anchor-based、anchor-free、guided anchors,近期 anchor 又开始崛起,在性能上匹配 two-stage,速度上匹配 one-stage;还有从类别不平衡出发,不同尺度物体检测等等出发。

考虑商品检测中,主要重视三个问题:1.速度问题;2.检测标注类别不平衡;3.物体尺度变化差异大,综合这三个问题,我们选择图 19 中的 retinanet [8]作为我们的检测器。众所周知,retinanet 属于 one-stage 检测器,从原图出发直接回归物体的位置和类别,因而速度快,其次它采用金字塔架构,有效的适配多尺度物体检测,最后,retinanet 提出了 focal loss 可以有效的适应类别不平衡问题,以及样本难易问题。后续我们会采用 anchor-free 的策略进一步优化 retinanet 的 head 部分,进一步加速模型的检测速度,这里不展开介绍。

我们将 retinanet-resnet50fpn 和经典的单阶段检测器 yolov3,和两阶段检测器 faster-rcnn-resnet50-fpn 进行对比,如下表格 20 所示。评测数据采用的是外包采集的 7k 张图片,涵盖了 11 大类,对比表格结果可知,retinanet 在速度和精度上达到了很好的折中效果。后续我们会通过 tensorRT 进一步优化 retinanet 的前向速度,剧透下最快可以达到 80FPS。

2.3.1 类目预测
类目预测是为了确定检测抠图中物体的类别,从而方便后续用指定类目的模型进行特征提取和同款索引。大家可能会有所疑虑,因为前面检测器已经识别出了商品的位置和类目,为何不直接用检测器的类目,而是要重新来过一次类目预测呢?原因如下图 21 所示:训练检测器的数据有限,而用户上传的图片可能千奇百怪,那么训练库未出现的子类很容易造成检测器分类错误,其次是类间混淆性也会带来分类错误。

那么该如何提升类目识别的精度呢?这里我们利用海量的线上检索库来提升类目预测的精度。即为我们将用户 query 在检索库中进行一次检索,查询最近邻的 top-20 所属的类目,结合检测器的预测类目,来重新加权投票得到物体的最终类目。最终,通过检测+检索,我们能极大提升类目预测的精度,将近 6 个点的提升。
2.3.2 同款检索
同款检索是扫一扫识物的灵魂。不同于一般的以图搜图,只需要找出相似的图片即可,同款检索属于细粒度检索,需要检索出 query 的精确同款,比如华为 watch GT2 需要搜出来的就是该款手表,不能是其他牌子的手表,这就导致同款检索的挑战非常大,下图 22 列出了同款检索的难点与挑战:1.类间混淆性问题,即如何区分相似款和同款;2.同款召回问题,即同款本身存在较大差异,如何有效的检索出同款。考虑到这些难点,我们提出了 9 大方向来优化我们的同款检索模型。下面一一解释。

2.3.2.1 同款检索之分类模型
这是我们的 baseline 模型。我们使用的分类模型如下图 23 左侧所示。众所周知,分类模型采用 softmax 将逻辑值映射为类目的概率值,下图右上角表格所示,softmax 能很好的放大逻辑值的差异,将正确类目的概率逼近 1,有利于模型快速收敛。下图中我们还展示了 softmax 分类模型的决策边界,以及在 mnist-10 类目上学习得到的特征分布[9,10]。观察可知,softmax 分类器学习到的特征空间有 3 大特征:
1)特征空间呈现扇形分布,因而用余弦距离检索会优于欧式距离,后面我们会固定采用余弦距离进行同款检索;
2)不同类目分布不均衡。事实上我们希望同等重视各个类目,他们能均匀的分割整个特征空间,有利于模型泛化能力;
3)边界样本检索不准确,从特征图可知,边界样本距离临近类的余弦距离很可能小于该样本到同类之间的距离,造成检索错误。下面,我们重点修整分类模型的所存在的问题。

2.3.2.2 同款检索之分类模型改进 1 归一化操作
归一化包括两种,对图 23 中的分类权重 W 进行归一化,以及对特征 x 进行归一化。那么归一化的作用是什么呢?先来说说权重 W 的模长和特征空间分布不均衡的关系。有研究者[10]表明,训练数据库中样本多的类目对应的 W 的模长也会越长,表征模型越重视该类的分类正确程度,而忽视了其他样本数目少的类目,如图 24 所示,MNIST 和 WebFace 两个数据库都验证了上述的映射关系。而实际上我们希望的是每一类都能被平等的重视,特征空间中每一类能够均衡的划分整个空间,因而我们需要对 W 进行归一化,让所有类别的权重一致,即
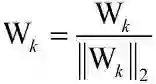
:

特征归一化的操作类似,即为:

回顾 softmax 分类的决策边界:
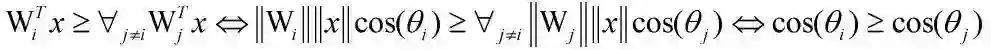
我们将 W 和 x 都进行归一化,因而决策边界只取决于角度,迫使模型训练收敛后特征分布更加扇形化,有利于余弦检索。但是两者同时归一化,会造成模型难于收敛,大家可以思考一番为何?参考图 23 中的 softmax 特性,由于权重和特征都进行了归一化,分类逻辑值最大为 1,最小为-1,同样的三类分类学习中 gt 类目对应的 softmax 概率最大只到 0.78,远小于 1,导致模型仍有较大 loss,不好收敛。解决方法比价简单,对逻辑值乘以一个尺度值 s 即可,扩大差异化,有利于模型收敛。
2.3.2.3 同款检索之分类模型改进 2 角度 Margin
增加角度 Margin 的核心目的是让 softmax 分类的扇形分布更加有利于检索:即为同类更加聚集,不同类更加远离。常见的 3 种增加角度 margin 的策略入下图 25 所示:乘性 margin[10,11],加性余弦 margin[12],加性角度 margin[13]。

增加 margin 后,softmax 分类模型得到的类内特征更加紧凑,如下图 26 所示。这里多说几句,相比乘性 margin,加性 margin 更加容易训练,这是因为乘性 margin 将余弦的单调区间从[0,π]缩小为[0,π/m],梯度更新区间变小了,而加性 margin 单调区间不变,有利于模型收敛。

2.3.2.4 同款检索之分类模型改进 3 排序损失
分类模型的学习目的是类别可区分,和检索任务还是有一定区别,引入排序损失的目的就是显示的去优化检索任务,即为欧式空间中同类样本的距离要小于不同类。一般排序损失和分类损失叠加使用效果要更好,我们设计的模型结构如下图 27 所示:

图 27 中右边展示的是常用的排序损失函数,如 contrastive loss, triplet loss, lifted structure loss 等。图中重点展示了三元组损失函数以及优化的可视化目标,即同类距离要比不同类距离小于一个 margin。
2.3.2.5 同款检索之分类模型及其改进后性能对比
此处我们对分类模型和其改进版本在商品检索任务上进行性能对比。评测集合是我们收集的 11 大类商品库,其中用户评论图作为查询样本,检索样本为同款商家图和非该款式的噪声集合组成,可以较好的模拟线上检索库。图 28 展示了分类模型及其改进版本在珠宝类目上的性能对比,可知:1)增加归一化和角度加性 margin 后,即为 ArcFace[13],检索性能要优于常用 softmax 分类模型;2)在分类模型基础上增加排序损失,如 Hard Triplet Loss,检索性能优于常用 softmax 分类模型;3)分类+归一化+角度 margin+排序,如最后两行所示,性能进一步提升,但是提升幅度不是特别大。

2.3.2.6 同款检索之多任务模型
为了进一步提升检索模型的特征表达能力,我们探索让检索特征捕捉更加丰富的商品特性,如在款式的类别上,加上视角、品牌等商品属性,如下图 29 所示。

为了适应多属性标注标注的学习,我们设计如下图 30 的多任务协同学习模型。多任务协同学习模型的好处非常明显,可以更好的利用属性之间的相关性,有利于网络的优化收敛,以及提升模型的泛化能力,这样得到的检索特征更加有利于商品同款检索。这里有个问题,不同任务权重如何设计?当然我们可以手工设置每个任务的权重,但这需要对各个任务理解较为深入加上大

量调参得到,另外的策略是自动得到各个任务的权重,有许多研究者对此进行了研究,这里我们采用验证集趋势算法[14]来自动计算得到各个任务的权重,如下图 31 所示。该算法思想比较直接,即为人工设置高权重用于主任务,如款式分类,其他任务基于其优化难易程度来得到权重,如难优化(损失波动大且绝对值高)的任务权重大,易优化的权重小。使用多任务协同学习后,模

型的检索性能相比单任务模型有较大的提升,如下图 32 所示。

2.3.2.7 同款检索之注意力模型
在图 22 中我们讲述了同款检索的一个巨大的挑战即为相似款对同款检索的混淆。为了更好的区分同款和相似款,我们希望更加关注一些显著的区域,如下图 33 中手表的 logo,刻写的文字,鞋子的 logo,花纹等。常用的注意力模型分为三种[15],有特

特征空间注意力,特征通道注意力,以及 2 种注意力相结合。通过实验对比可知,增加特征空间注意力后,模型检索性能提升,但是增加特征通道注意力,检索性能反而下降,如下图 34 所示。我们认为空间注意力有利于强化模型重视显著空间区域,而特征通道注意力可能造成了模型过拟合,性能反而有所下降。

2.3.2.8 同款检索之层级困难感知模型
同样针对同款检索的两大难点和挑战,即类间混淆性和类内差异性,我们采用层级困难感知模型来充分重视这两大难题,如下图 35 所示的包包。尽管是同款,其相似程度可能有很大差异,如该款式包包由于拍摄视角、遮挡等造成的变化,对于非同款的负样本,也有非常相似的其他款式包包,和差异比较大的其他商品入酒类、口红等。

层级困难感知模型模型[16]结构如下图 36 所示,其排序损失按层级分布,第一层级针对所有的正负样本进行排序学习,第二层负责较为困难的正负样本对,而第三层则负责更加困难的正负样本对,并且对于越困难的样本对,模型网络设计的越深。

层级困难感知模型通过层级设计,匹配正负样本对的层级分布特性,能够有效的提升模型的同款检索性能,如下图 37 的实验所示。

2.3.2.9 同款检索之互学习模型
众所周知,一般竞赛中大家都会融合多个模型的结果来提升精度。但是在实际的项目落地,我们需要同时考虑部署模型的精度和速度,融合多个模型会占用更多计算资源,降低前向速度。那么怎么既然融合多个模型结构的优势,又不增加计算资源呢?这就是互学习模型的核心思想,如下图所示,互学习模型通过 KL 散度 loss 来吸收其他模型的结构优势,部署的时候只需要部署一个模型即可,不增加计算资源。

实验中,我们利用 resnet152 和 inceptionv4 进行互学习,实际部署采用 resnet152 进行检索,其性能如下图 39 所示。互学习除了增加模型训练时间,对模型上线不增加任何负担,但是精度能够较为显著的增加。

2.3.2.10 同款检索之局部显著性擦除
通过上述所有策略来提升模型的同款检索性能后,我们发现仍然存在一个问题,就是深度学习模型会过分关注图像的纹理区域,而忽视物体的形状。比如在行旅箱的同款检索中,返回的是印有相同图案的书包,钱包等,而非行旅箱。如何让模型在关注

纹理的同时,也关注下物体的形状信息呢?我们采用局部显著性擦除技术来破坏原图的纹理,迫使模型来关注物体的形状。常见的局部显著性擦除有 3 种,如下图 41 所示,分别为随机擦除,伯努利擦除,对抗擦除。这里我们重点对比了前两者,对抗擦除后

续有时间再补上其性能,实验结果如下图 42 所示,局部显著性擦除能够极大的提升模型的同款检索精度。

2.3.2.11 同款检索之互 k 近邻编码重排序
前面我们讲述的都是优化检索模型,这里我们讲述的是如何进一步优化检索模型的检索结果,即重排序。在重排序里面,我个人非常欣赏互 k 近邻算法[17],非常简单高效。互 k 学习算法最早被提出来用于行人再检索,如下图 43 所示,其核心发现是,对于 query 样本,其检索的 top-10 样本中,正样本(和 query 为同一人)换做查询样本时,其 k 近邻中有原始的 query 样本,而负样本(和 query 非同一个人),其 k 近邻中没有原始 query 样本,基于该发现,作者在马氏距离的基础上,增加了基于互 k 近邻的距离度量,如图中下方所示,基于该度量可以有效的对原排序进行重排序,将正样本挪前,将负样本挪后。

但是实际上,我们无法直接利用该算法用于商品同款检索,原因在于我们的 query 是用户评论图,而检索图是商家图,他们存在很大的差异,造成互 k 近邻会失效,后续我们重点是如何优化特征度量空间,让模型的域差异减小,然后再利用互 k 近邻来进行重排序。
2.3.2.12 竞品对比
最后,我们基于用户上传的 7k 张图片进行 11 类检测准确度评测, 运行环境 NVIDIA GPU P4,来对比不同竞品的精度差异。对比试验可知,我们的算法要优于京东,接近拍立淘。
2.4 扫一扫识物平台建设
正所谓磨刀不误砍柴工,平台建设对于我们的数据构建,模型学习,模型部署都是至关重要。下面我们一一介绍。
2.4.1 数据清理平台
为了加快人工校验以及人工标注的速度,我们开发了一系列工具来辅助标注和检验模型精度,这里不做过多解释。
2.4.2 模型训练平台
这几年,机器学习平台发展迅猛,很多公司拥有自己的深度学习平台,我们人少钱少,主要是基于开源的深度学习平台来开发符合商品同款检索的特有平台。我们主要是开发了 caffe 和 pytorch 两套同款检索平台,后续重点介绍。

2.4.2.1 caffe
我们开发的第一个模型训练平台是 caffe。caffe 平台的核心架构如下图 45 所示,caffe 平台现在主要是工业界用的多,现在学术界用的少些。我们开发的 caffe 同款检索平台,具有如下特点:
1)支持丰富的数据增广策略;2)支持多类型数据加载;3)支持蒸馏学习/互学习算法;4)支持困难感知模型算法;5)支持排序模型算法;6)支持 batchsize 扩充。
caffe 的优缺点非常明显,其优点有:1)训练快,结果稳定;2)基于 prototxt 快速试验各种多模型/多标签/多数据源任意组合。其缺点有:1)新算法开发慢;2)调试不灵活;3)显存优化不好;4)学术前沿方法更新少。第 4 个缺点是较为致命的,我们无法快速跟进学术前言,因而我们后续决定开发 pytorch 检索平台。

2.4.2.2 pytorch
我们开发的 pytorch 检索架构如下图 46 所示,基本支持 caffe 检索平台的所有特点:1)支持丰富的数据增广策略;2)支持多类型数据加载;3)支持蒸馏学习/互学习算法;4)支持排序模型算法;5)支持更多主流网络 EfficientNet;6)支持数据去噪/合并同款/检索;7)支持混合精度训练。pytorch 优缺点也非常明显,其优点:1)自动求导,算法开发效率高;2)动态图,Python 编程,简单易用;3)Tensorboard 可视化方便;4)Github 资源多,紧跟前沿;5)Pytorch1.3 支持移动端部署。当然 pytorch 也不是完美无缺的,相比 caffe 有其缺点:1)在多任务自由组合不如 caffeprototxt 方便。

2.4.3 模型部署平台
模型训练我们可以不在乎模型运行时间代价,但是在模型部署时候我们得要充分重视模型的资源占用情况,尽量提升模型的并发能力,如 GPU 部署时候优化显存,适配硬件,加快速度。这里我们重点介绍后台 GPU 部署使用的 tensorRT 和手机端部署使用的 ncnn。

2.4.3.1 模型部署平台:tensorRT
tensorRT 是英伟达开发的部署平台,能够有效的降低模型显存,加速模型前向速度。这里我们不展开细节,大家可以关注下面的检测模型和检索模型,通过 tensorRT 量化加速后,显存和速度都有了巨大的飞跃。

2.4.3.2 模型部署平台:ncnn
移动端部署,我们用腾讯自己开发的 ncnn 架构,其优点如下图 49 左图所示,demo 如右图所示。

2.4.4 任务调度系统平台
任务调动平台由我们的后台大神们开发,主要用于各个任务的有效调用,考虑到我们的检索库是上亿的数据库,需要保证平台具有较好的容错、容灾,以及鲁棒机制。如下图 50 所示,当然这里展示的只是冰山一角,后面等后台大神们在 KM 里给大家详细解释。

三. 扫一扫识物展望
最后,我们对我们的扫一扫识物进行未来展望,还是那句话,我们期待扫一扫识物成为大家的一个生活习惯:扫一扫,知你所看;扫一扫,新生活,新姿势。

参考文献
[1] 公司内部文档
[2] https://blog.csdn.net/Notzuonotdied/article/details/95727107
[3] Learning Deep Features for Discriminative Localization,CVPR16
[4] Weakly Supervised Object Localization with Latent Category Learning, ECCV14
[5] Weakly Supervised Deep Detection Networks, arXiv16
[6] Seed, Expand and Constrain: Three Principles for Weakly-Supervised Image Segmentation, arXiv16
[7] https://scikit-learn.org/stable/modules/clustering.html
[8] Focal Loss for Dense Object Detection, arXiv18
[9]https://zhuanlan.zhihu.com/p/76391405
[10] SphereFace: Deep Hypersphere Embedding for Face Recognition,arXiv18
[11] Large-Margin Softmax Loss for Convolutional Neural Networks, arXiv17
[12] CosFace: Large Margin Cosine Loss for Deep Face Recognition, arXiv18
[13] ArcFace: Additive Angular Margin Loss for Deep Face Recognition, arXiv18
[14] Adaptively Weighted Multi-task Deep Network for Person A!ribute
Classification, MM17
[15] Concurrent Spatial and Channel ‘Squeeze & Excitation’ in Fully
Convolutional Networks, arXiv18
[16] Hard-Aware Deeply Cascaded Embedding, ICCV17
[17] Re-ranking Person Re-identification with k-reciprocal Encoding, CVPR17
[18] 公司内部文档
重磅!CVer-学术交流群已成立
扫码可添加CVer助手,可申请加入CVer大群和细分方向群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!


