学习偏好,北大&BOSS直聘的这个AI模型能更好的为你找工作
机器之心发布
论文作者:Rui Yan、Ran Le、Yang Song、Tao Zhang、Xianliang Zhang、Dongyan Zhao
针对互联网求职招聘场景的人岗匹配推荐问题,北大联合 BOSS 直聘的研究者们提出了一种建模求职者与招聘者双方偏好的新型深度文本匹配模型。该模型通过引入记忆模块,利用简历文档和岗位描述文档之间的信息交互来学习潜在偏好表示,并将偏好结合到匹配框架中构建端到端的深度神经网络模型。基于在线招聘平台 BOSS 直聘数据集的实验结果表明,本文提出的模型效果超过 state-of-the-art 的人岗匹配推荐方法,各评价指标均有显著提升。实验证明,互联网招聘场景中的求职者与招聘者双方确实存在历史行为偏好,并且该偏好可以用来改善人岗匹配推荐系统。目前,该论文已被数据挖掘领域顶会 KDD2019 接收。

背景介绍
在线招聘服务的产生与发展不断冲击着就业市场上的传统招聘模式。如今,互联网上存在着数亿规模的求职者简历以及岗位招聘信息。如此大规模的数据给互联网招聘带来了新的挑战:如何能够自动并准确地将合适的岗位描述文档与简历文档相匹配,以便高效地将合适的人才配置到与之相应的岗位上。因此,学习并构建完善的人岗自动匹配推荐系统显得十分重要,这既有助于招聘人员找到合适的候选人,也有助于求职者能够找到合适的岗位。
现有针对人岗匹配推荐问题的研究通常集中在学习简历文档以及岗位描述文档自身的表示后计算双方的匹配度。然而,在互联网求职招聘场景下,除了求职者与招聘者双方的文本信息之外,还存在大量的历史交互行为信息可以应用于人岗匹配推荐任务。
问题定义
在本文定义的人岗匹配推荐任务中,每个岗位文档由多句岗位职责与任职要求组成,每个简历文档由多句相关工作经验组成。在实际应用场景下,求职招聘数据中的招聘者与求职者双方天然带有历史行为记录信息。例如,一个求职者曾经面试过哪些岗位会被记录,同时一个岗位曾经面试过哪些求职者也会被记录。这些面试沟通记录可以作为标注数据供模型学习双方的偏好。本文的目标是给定一个求职者及其历史面试记录,以及一个招聘岗位及其历史面试记录作为输入,去预测求职者与招聘岗位之间的匹配分数,从而判断将求职者推荐给该岗位是否合适。
方法描述
如图所示,文本提出的模型由招聘者与求职者双边对称的表示学习网络,以及匹配网络三部分组成。
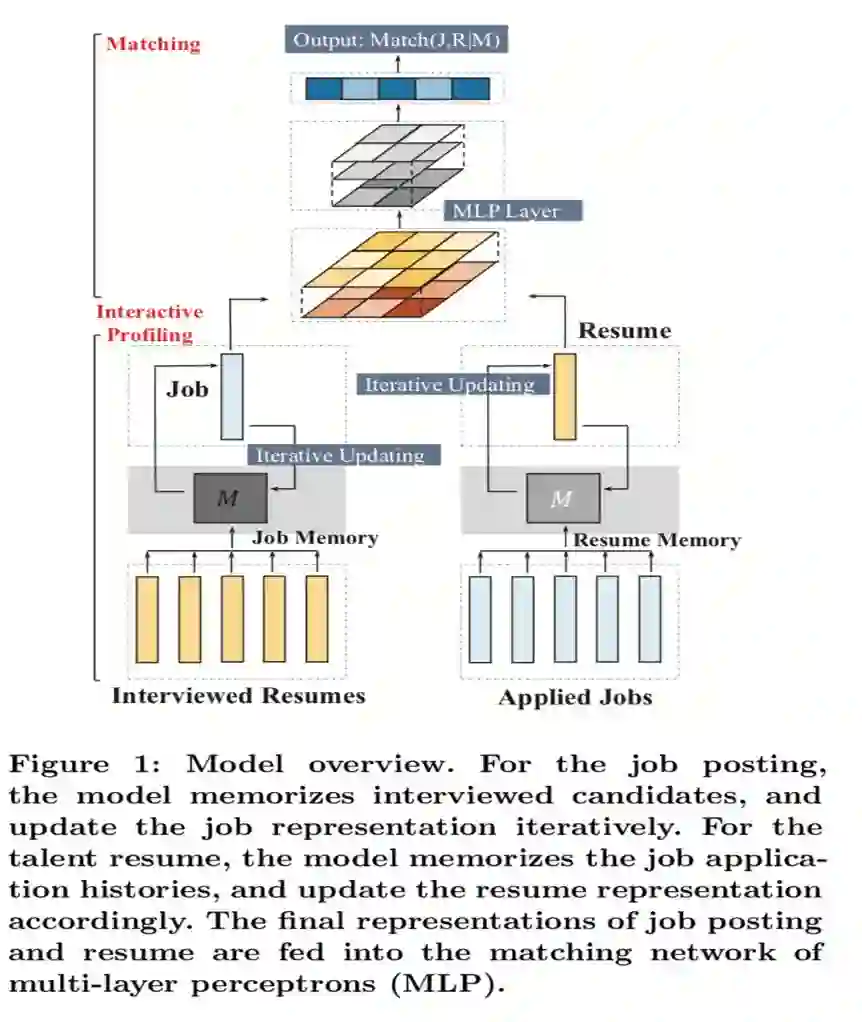
在岗位描述表示学习网络中,模型利用岗位描述文档以及该岗位历史上曾经面试过的求职者的简历文档,通过引入记忆模块来计算带有偏好的岗位向量表示。
1)初始化
初始阶段,模型首先对岗位描述文档里的各个句子,以及该岗位历史面试过的求职者的简历文档内的各个句子经过层级 GRU 网络进行编码,得到各个带有上下文信息的句子表示。
同时,模型将岗位文档中的各个带有上下文信息的句子表示作为记忆模块的初始化。
2)记忆模块迭代
给定一个岗位描述文档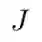
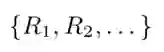
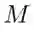
a.)利用 J 和各个 R 对 M 进行更新(记忆模块更新)。
b.)J 从 M 中读取偏好信息(记忆模块读取)。
记忆模块更新:每步迭代的更新操作中,模型利用历史面试记录中的一个简历文档对岗位文档的记忆模块进行更新。模型引入『注意力机制』计算更新到当前状态下的记忆模块里各个向量表示与岗位文档及简历文档各个句子表示的相似度,并以此来计算用来更新记忆模块的偏好信息向量。
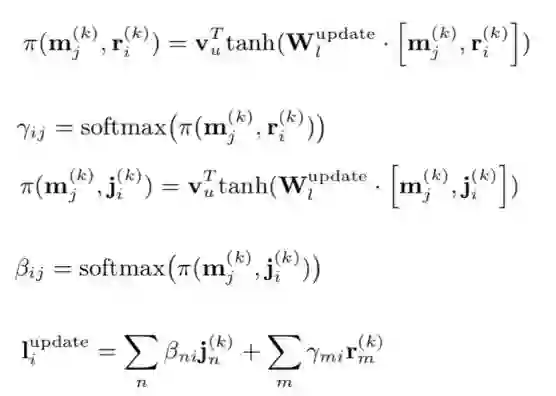
更新计算中,模型利用记忆模块中当前状态下的各个向量表示,以及每个向量表示对应的当前步骤的偏好信息向量,通过 『门控机制』 对记忆模块中各个向量表示进行更新。
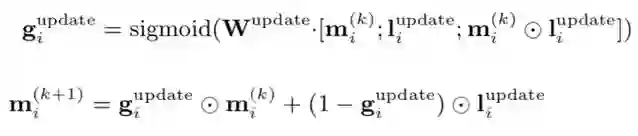
记忆模块读取:在每轮迭代的记忆模块更新操作后,岗位描述文档的各个带上下文信息的句子向量表示从记忆模块中读取偏好信息。读取操作采用与更新操作中相似的『注意力机制』来计算偏好信息向量。
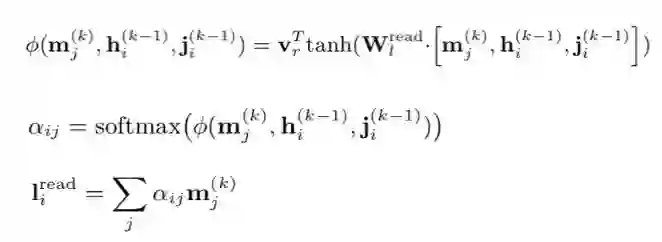
并且利用『门控机制』来完成信息读取。
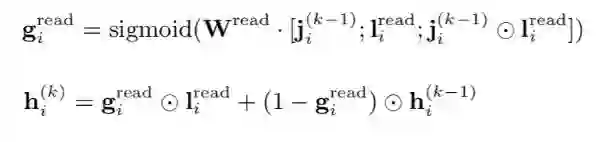
通过对记忆模块的更新与读取的迭代操作,得到最终带有偏好信息的岗位描述表示。
采用对称的方式,在求职者的简历文档的表示学习中,模型遍历该求职者历史曾经面试过的岗位描述文档,得到最终的简历表示。
3)匹配
对记忆模块的更新读取迭代操作完成后,模型对求职者的简历文档中各个带有上下文信息的句子表示通过 max-pooling 得到简历的文档向量表示。采用同样的方式可以得到带有偏好信息的岗位描述文档表示。以上述两个文档表示为输入,模型利用 MLP 网络计算匹配分数。优化的目标是极大化发生面试的岗位描述与简历文档之间的得分,极小化不匹配样本对之间的得分。
实验效果
本文基于在线招聘平台 BOSS 直聘的数据集对所提出的模型进行实验验证,比较的方法包括:
1)LR:逻辑回归模型
2)DT:决策树模型
3)NB:朴素贝叶斯模型
4)RF:随机森林模型
5)GBDT:梯度提升决策树模型
上述模型是基于传统机器学习的方法,此外我们还引入了基于深度匹配模型的方法 PJFNN[1] 和 AAPJF[2] 进行实验比较。
6)HRNNM:基于层级 GRU 编码的文档匹配模型
7)PJFNN:[1] 中提出的基于卷积神经网络的匹配模型
8)AAPJF:[2] 中提出的基于层级注意力机制的匹配模型
实验结果显示本文提出的模型在各个指标上均优于 state-of-the-art 的模型,并且指标的提升通过了显著性检验。此外,对记忆模块的消融实验进一步验证了对求职者与招聘者的历史行为偏好建模均有助于提升人岗匹配推荐系统的效果。
参考文献
[1] Zhu C, Zhu H, Xiong H, et al. Person-Job Fit: Adapting the Right Talent for the Right Job with Joint Representation Learning[J]. ACM Transactions on Management Information Systems (TMIS), 2018, 9(3): 12.
[2] Qin C, Zhu H, Xu T, et al. Enhancing person-job fit for talent recruitment: An ability-aware neural network approach[C]//The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. ACM, 2018: 25-34.
本文为机器之心发布,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com


