Jupyter在美团民宿的应用实践

总第370篇
2019年 第48篇

美团民宿是美团旗下的民宿预定平台,专注为旅行者提供个性化民宿住宿体验,让年轻人“住得不一样”。本文将分享美团民宿团队的「Kaggle Kernels」——一个平台化的Jupyter,接入了大数据和分布式计算集群,主要用于业务数据分析和算法开发。希望本文的分享能为有同样需求的读者带来一些启发。
前言
对于比赛类的任务,使用Kaggle Kernels非常方便,但我们平时的主要任务还是集中在分析、处理业务数据的层面,这些数据通常比较机密并且数量巨大,所以就不能在Kaggle Kernels上进行此类分析。因此,大型的互联网公司非常有必要开发并维护集团内部的一套「Kaggle Kernels」服务,从而有效地提升算法同学的日常开发效率。
美团内部数据系统现状
现有系统与问题
魔数平台:用于执行SQL查询,下载结果集的系统。通常在数据分析阶段使用。
协同平台:用于使用SQL开发ETL的平台。通常用于数据生产。
托管平台:用于管理和运行Spark任务,用户提供任务的代码仓库,系统管理和运行任务。通常用于逻辑较复杂的ETL、基于Spark的离线模型训练/预测任务等。
调度平台:用于管理任务的依赖关系,周期性按依赖执行调度任务。
这些系统对于确定的任务完成的比较好。例如:当取数任务确定时,适合在魔数平台执行查询;当Spark任务开发就绪后,适合在托管平台托管该任务。但对于探索性、分析性的任务没有比较好的工具支持。探索性的任务有程序开发时的调试和对陌生数据的探查,分析性的任务有特征分析、Bad Case分析等等。
分析和取数工具割裂。
大数据分析可视化困难。
以Bad Case分析为例,现有的做法通常是:

这种方式存在的问题是:
分析与取数割裂,整个过程需要较多的手工操作。
分析过程不容易复现,对于多人协作式的验证以及进一步分析不利。
本地Python环境可能与分析对象的依赖有冲突,需要付出额外精力管理Python环境。
离线数据相关任务的模式通常是取数(小数据/大数据)--> Python处理(单机/分布式)--> 查看结果(表格/可视化)这样的循环。我们希望支持这一类任务的工具具有如下特质:
体验流畅:数据任务可以在统一的工具中完成,或者在可组合的工具链中完成。
体验一致:数据任务所用工具应该是一致的,不需要根据任务切换不同工具。
使用便捷:工具应是开箱即用,不需要繁琐的前置配置。
结果可复现:分析过程能够作为可执行代码保存下来,需要复现时执行即可,也应支持修改。
探索和分析类任务往往会带来可以沉淀的结果,如产生新的特征、模型、例行报告,希望可以建立起分析任务和调度任务的桥梁。
我们需要怎样的Jupyter
接入Spark:取数与分析均在Jupyter中完成,达到流畅、一致的体验。
接入调度系统:方便沉淀分析结果。
接入学城系统(内部WiKi):方便分享和复现。
预配置环境:提供给用户开箱即用的环境。
用户隔离环境:避免用户间互相污染环境。
如何搭建Jupyter平台
Jupyter项目架构
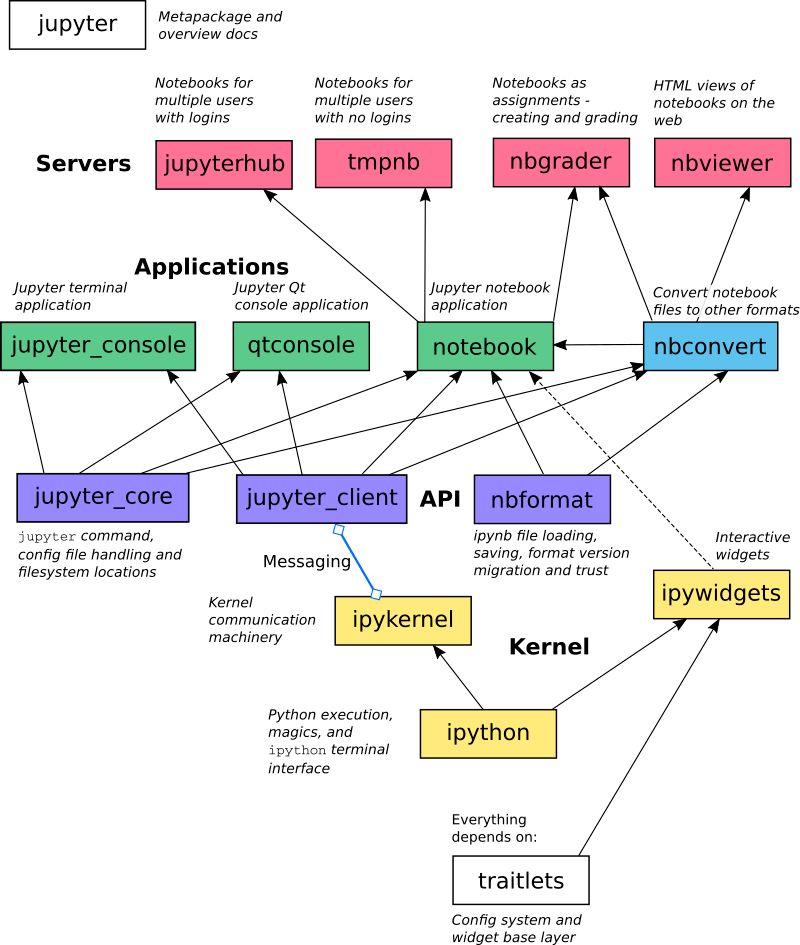
Jupyter扩展方式
JupyterLab是Jupyter全新的前端项目,这个项目有非常明确的扩展规范以及丰富的扩展方式。通过开发JupyterLab扩展,可以为前端界面增加新功能,例如新的文件类型打开/编辑支持、Notebook工具栏增加新的按钮、菜单栏增加新的菜单项等等。JupyterLab上的前端模块具有非常清楚的定义和文档,每个模块都可以通过插件获取,进行方法调用,获取必要的信息以及执行必要的动作。我们在提供分享功能、调度功能时,均开发了JupyterLab扩展。JupyterLab扩展通常采用TypeScript开发,开发文档可参考:
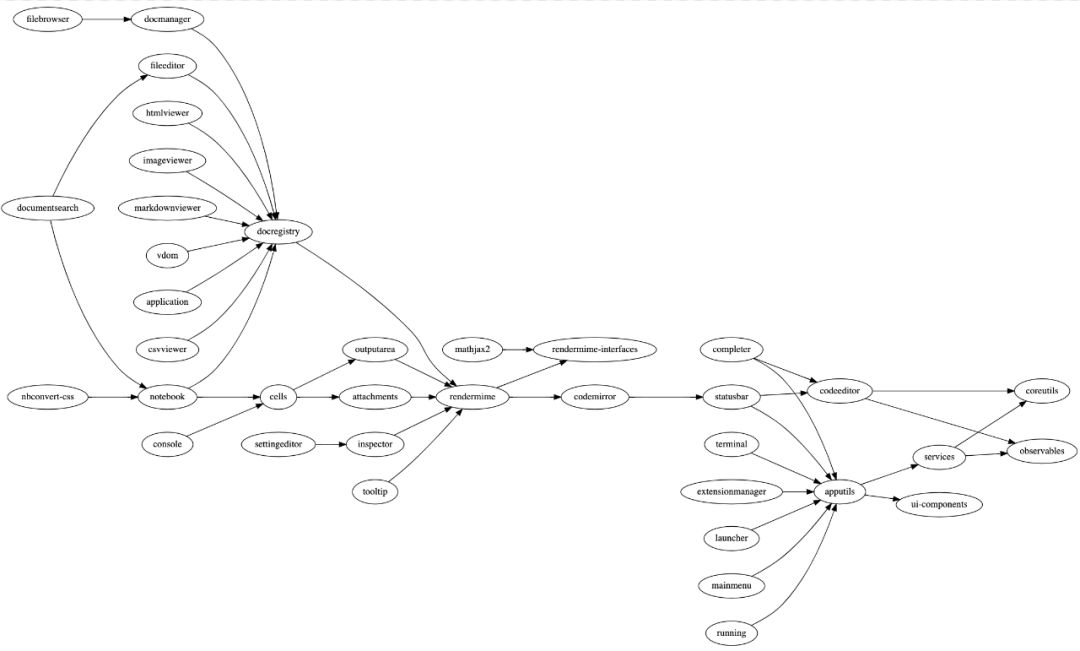
JupyterLab核心组件依赖图
Notebook Server扩展(serverextension)
为JupyterLab扩展提供对应的后端接口,用于响应一些需要由服务端处理的事件。例如调度任务的注册需要通过JupyterLab扩展发起请求,由Notebook Server扩展执行。
提供一个前端界面以及对应的后端处理服务。例如jupyter-rsession-proxy,用于在JupyterHub中使用RStudio。
Notebook Server扩展开发文档可参考:
https://jupyter-notebook.readthedocs.io/en/stable/extending/handlers.html。
IPython Magics开发文档可参考:
IPython Widgets在提供工具类型的功能增强上非常有用,基于它,我们实现了一个线上排序服务的调试和复现工具,用于展示排序结果以及指定房源在排序过程中的各种特征以及中间变量的值。IPython Widgets的开发可以通过组合现有的Widgets实现,也可以完全自定义一个,IPython Widgets开发文档可参考:
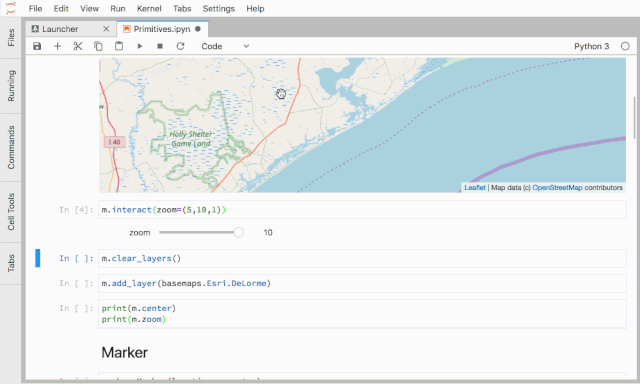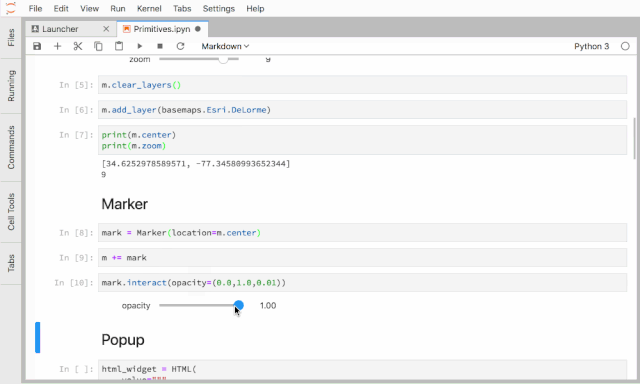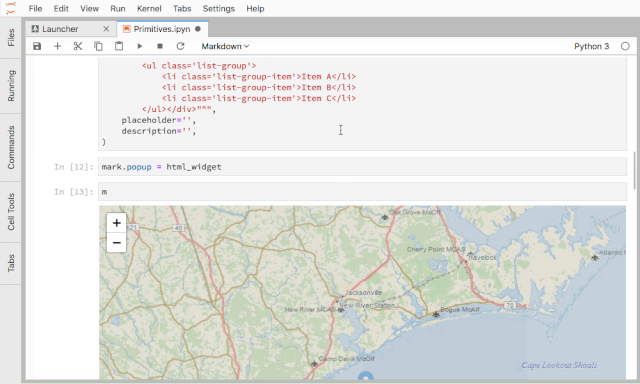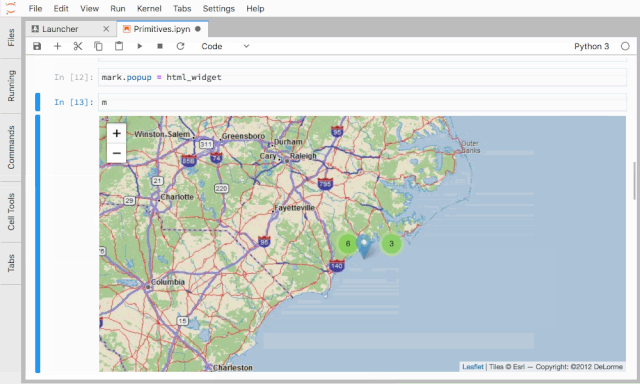
ipyleaflet
JupyterHub是一个多用户系统,登录模块可替换,通过实现新的Authenticator类并在配置文件中指定即可。通过这个扩展点,我们实现了使用内部SSO系统登录JupyterHub。Authenticator开发文档可参考:
当用户登录时,JupyterHub需要为用户启动一个用户专用Notebook Server。启动这个Notebook Server有多种方式:本机新的Notebook Server进程、本机启动Docker实例、K8s系统中启动新的Pod、YARN中启动新的实例等等。每一种启动方式都对应一个Spawner,官方提供了多种Spawner的实现,这些实现本身是可配置的。如果不符合需求,也可以自己开发全新的Spawner。由于我们需要实现Spark接入,对K8s的Pod有新的要求,所以基于KubeSpawner定制了一个Spawner来解决Spark连接集群的网络问题。Spawner开发文档可参考:
我们的定制
接入Spark:可以通过配置容器环境以及Spawner完成。
接入调度系统:需要开发JupyterLab扩展以及Notebook Server扩展。
接入学城系统:需要开发JupyterLab扩展以及Notebook Server扩展。
预配置环境:镜像配置。
用户隔离环境:通过定制Authenticators + K8s Spawner实现容器级别环境隔离。
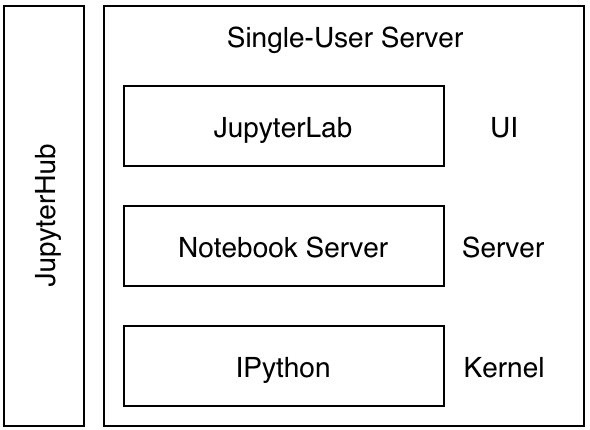
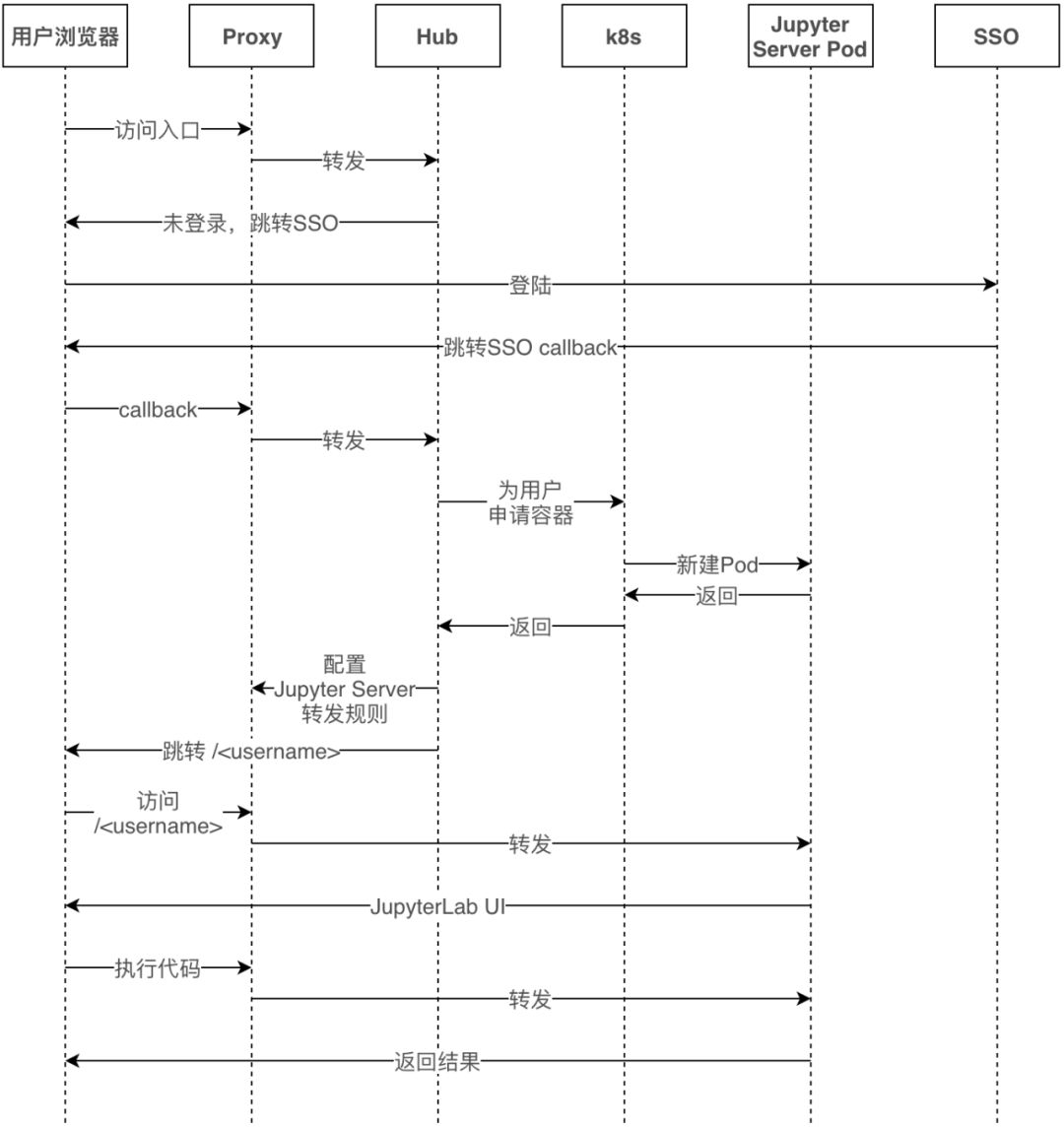
我们的方案是基于JupyterHub on K8s。下图是平台化Jupyter的架构图,从上到下可以看到三条主线:1. 分享复现、2. 探索执行、3. 调度执行。
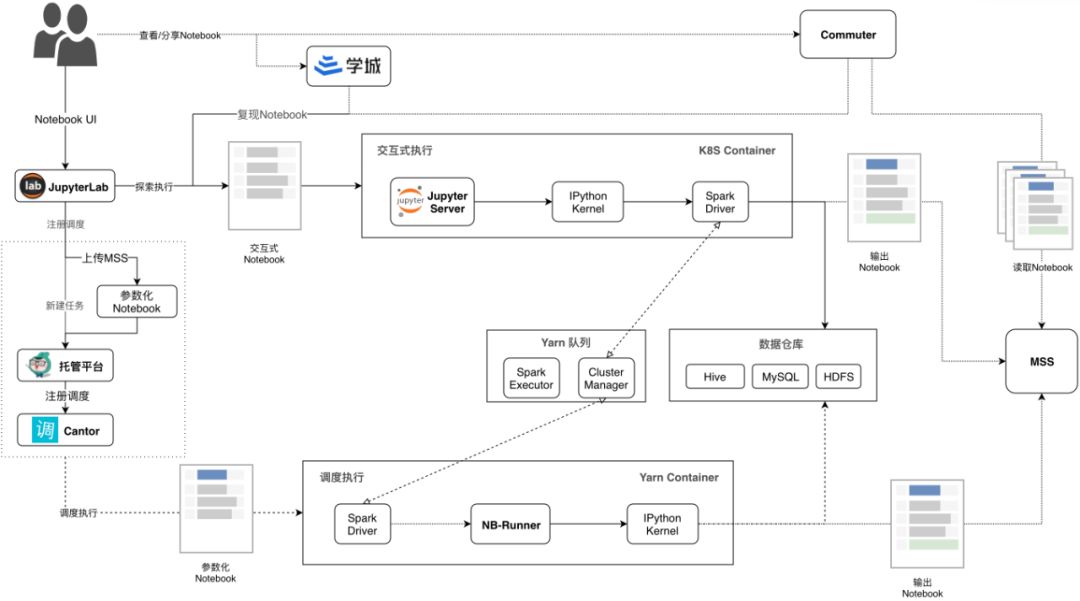
JupyterLab:交互式执行的前端,开源项目。
Jupyter Server:交互式执行的后端,开源项目。
Commuter:浏览Notebook的工具,开源项目。
K8s:容器编排系统,开源项目。
Cantor:美团调度系统,同类开源项目有AirFlow。
托管平台:美团离线任务托管平台,给定代码仓库和任务参数,为我们执行Spark-Submit的平台。
学城:美团文档系统。
MSS:美团对象存储。
NB-Runner:Notebook Runner,在nbconvert的基础上增加了参数化和Spark支持。
在定制Jupyter中,最为关键的两个是接入Spark以及接入调度系统,下文中将详细介绍这两部分的原理。
让Jupyter支持Spark
Jupyter代码执行原理
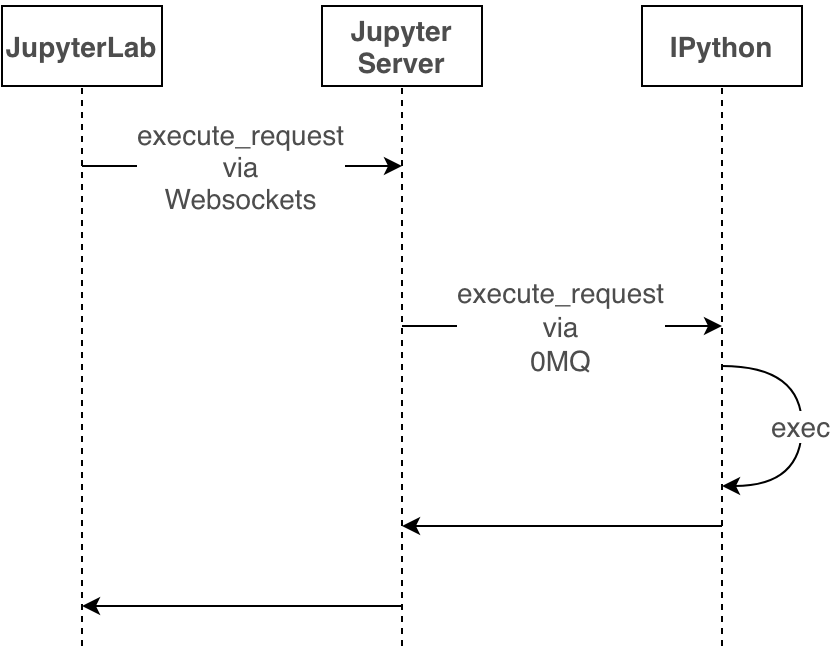
Jupyter执行代码时序图
这里,需要在IPython的exec阶段支持PySpark。
PySpark原理
方案一:PySpark命令启动,内部执行了spark-submit命令。
方案二:任意Python shell(Python、IPython)中执行Spark会话创建语句。
这两种启动方式有什么区别呢?
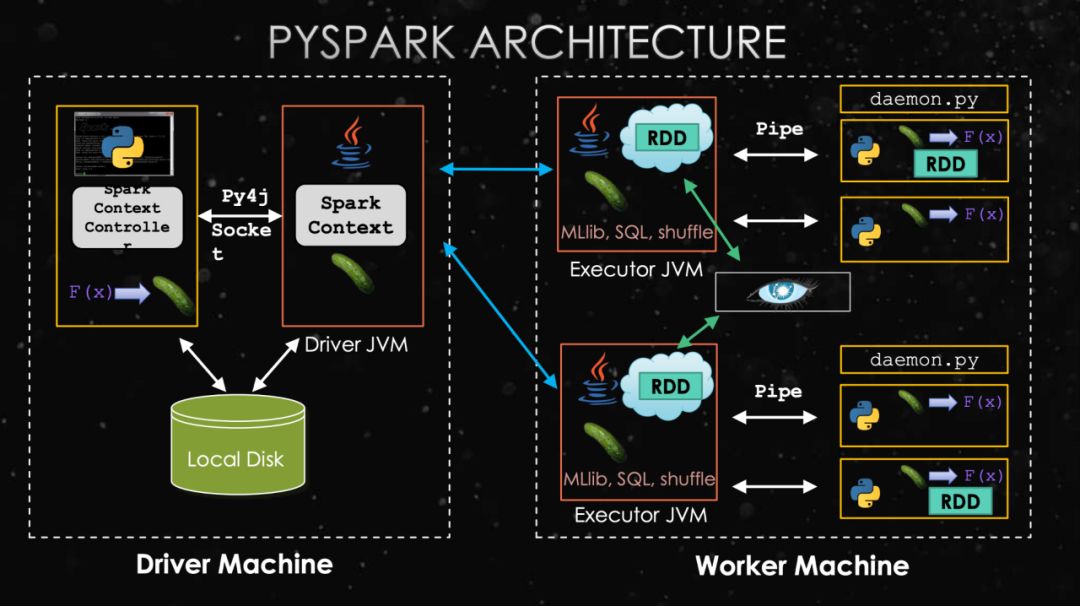
PySpark架构图,来自SlideShare
与Spark的区别是,多了一个Python进程,通过Py4J与Driver JVM进行通信。
PySpark方案启动流程
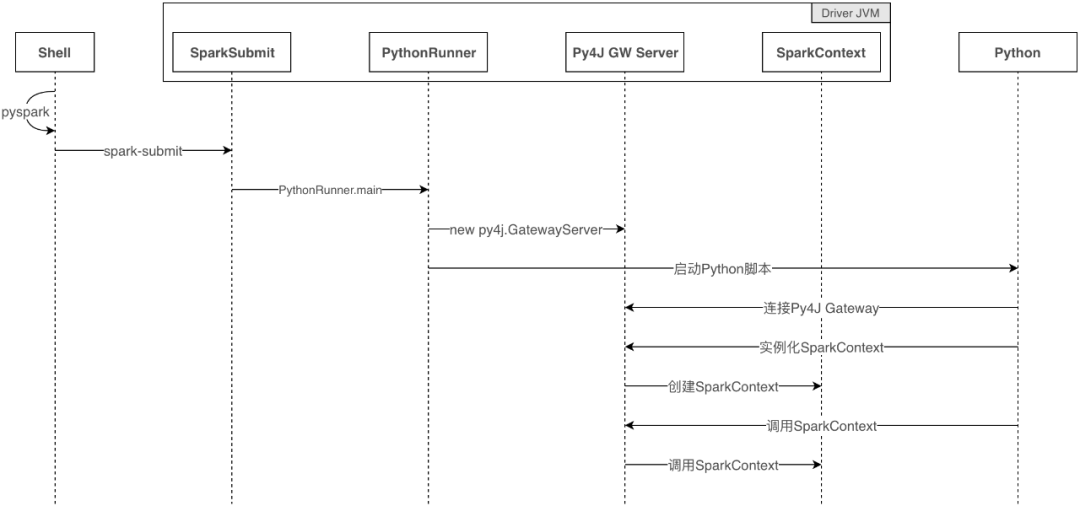
PySpark启动时序图
IPython方案启动流程
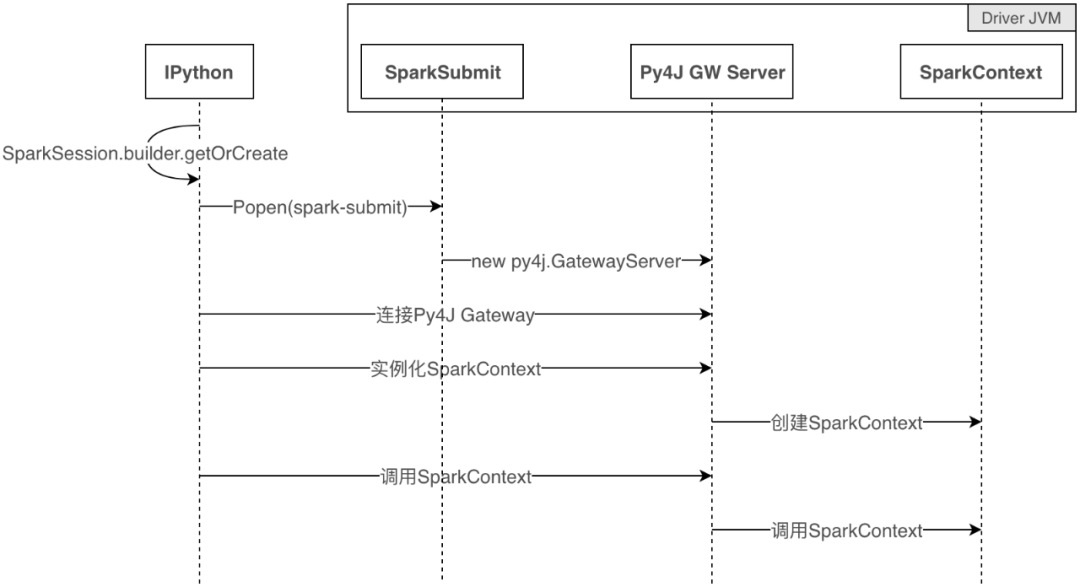
实际的IPython中启动Spark时序图
Toree采用的是类似方案一的方式,脚本中调用spark-submit执行特殊版本的Shell,内置了Spark会话。我们不希望这么做,是因为如果这样做的话就会:
多了一个PySpark专供的Kernel,我们希望Kernel应该是统一的IPython。
PySpark启动参数是固定的,配置在kernel.json里。希望PySpark任务是可以按需启动,可以灵活配置所需的参数,如Queue、Memory、Cores。
因此我们采用方案二,只需要一些环境配置,就能顺利启动PySpark。另外为了简化Spark启动工作,我们还开发了IPython的Magics,%spark和%sql。
环境配置
JAVA_HOME:Java安装路径,如/usr/local/jdk1.8.0_201。
HADOOP_HOME:Hadoop安装路径,如/opt/hadoop。
SPARK_HOME:Spark安装路径,如/opt/spark-2.2。
PYTHONPATH:额外的Python库路径,如$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.4-src.zip。
PYSPARK_PYTHON:集群中使用的Python路径,如./ARCHIVE/notebook/bin/python。集群中使用Python通常需要虚拟环境,通过spark.yarn.dist.archives带上去。
PYSPARK_DRIVER_PYTHON:Spark Driver所用的Python路径,如果你用Conda管理Python环境,那这个变量应为类似/opt/conda/envs/notebook/bin/python的路径。
为了方便,建议设置各bin路径到PATH环境变量中:$SPARK_HOME/sbin:$SPARK_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH。
import pyspark
spark = pyspark.sql.SparkSession.builder.appName("MyApp").getOrCreate()
在Spark任务中执行Notebook
# Import:首先我们import nbconvert和ExecutePreprocessor类:
import nbformat
from nbconvert.preprocessors import ExecutePreprocessor
# 加载:假设notebook_filename是notebook的路径,我们可以这样加载:
with open(notebook_filename) as f:
nb = nbformat.read(f, as_version=4)
# 配置:接下来,我们配置notebook执行模式:
ep = ExecutePreprocessor(timeout=600, kernel_name='python')
# 执行(preprocess):真正执行notebook的地方是调用函数preprocess:
ep.preprocess(nb, {'metadata': {'path': 'notebooks/'}})
#保存:最后,我们保存notebook执行结果:
with open('executed_notebook.ipynb', 'w', encoding='utf-8') as f:
nbformat.write(nb, f)
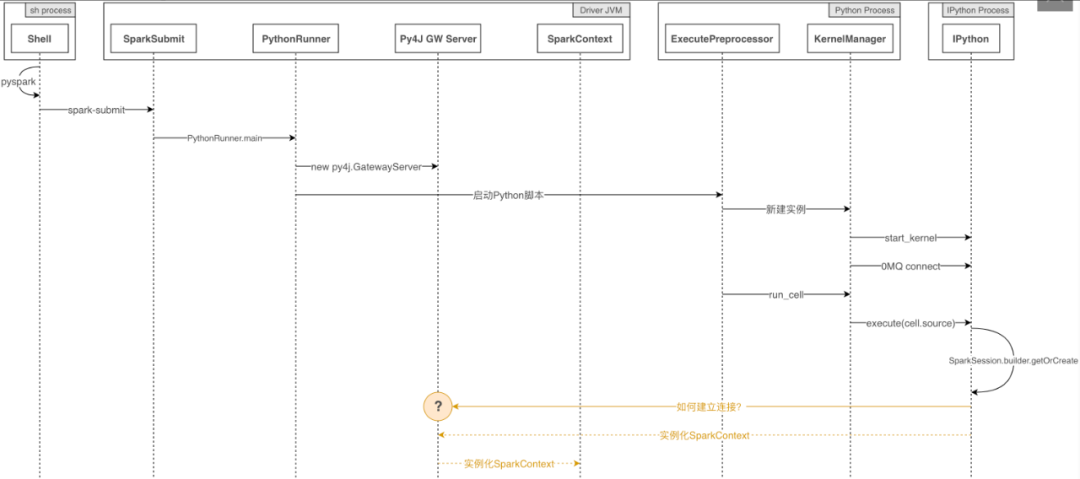
当Notebook中存在Spark相关代码时,Python NB-Runner.py能否正常执行?
当Notebook中存在Spark相关代码时,Spark-Submit NB-Runner.py能否正常执行?
之所以会出现问题2,是因为我们的调度系统只能调度Spark任务,所以必须使用Spark-Submit的方式来启动NB-Runner.py。
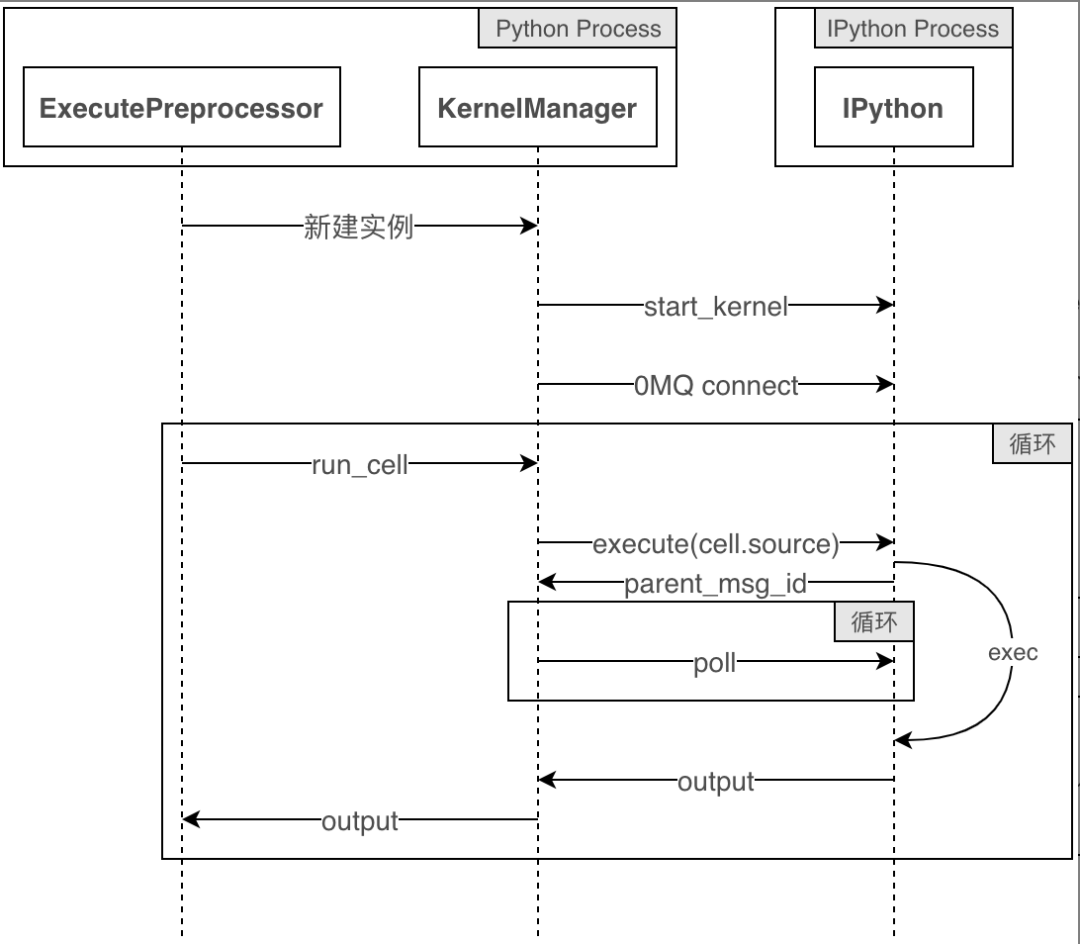
nbconvert执行时序图
问题1从原理上看,是可以正常执行的。实际测试也是如此。对于问题2,答案似乎并不明显。结合“PySpark启动时序图”、“实际的IPython中启动Spark时序图”与“nbconvert执行时序图”:
def launch_gateway(conf=None):
"""
launch jvm gateway
:param conf: spark configuration passed to spark-submit
:return:
"""
if "PYSPARK_GATEWAY_PORT" in os.environ:
gateway_port = int(os.environ["PYSPARK_GATEWAY_PORT"])
else:
SPARK_HOME = _find_spark_home()
# Launch the Py4j gateway using Spark's run command so that we pick up the
# proper classpath and settings from spark-env.sh
on_windows = platform.system() == "Windows"
script = "./bin/spark-submit.cmd" if on_windows else "./bin/spark-submit"
...
使用案例
数据分析与可视化
%%sql <var> [--preview] [--cache] [--quiet]
SELECT field1, field2
FROM table1
WHERE field3 == field4
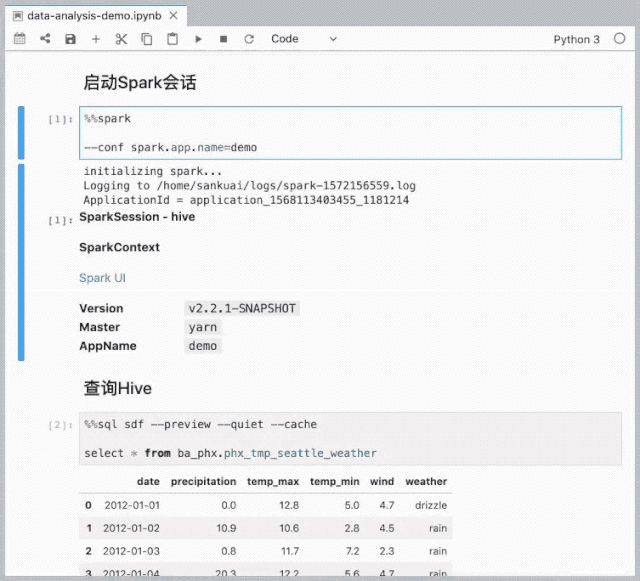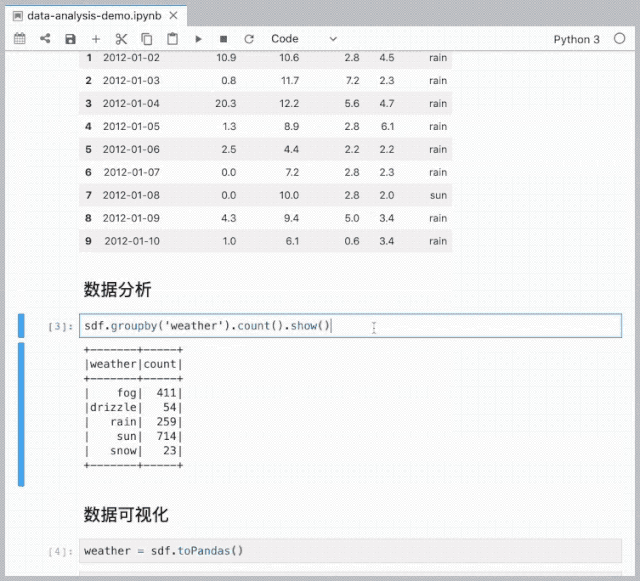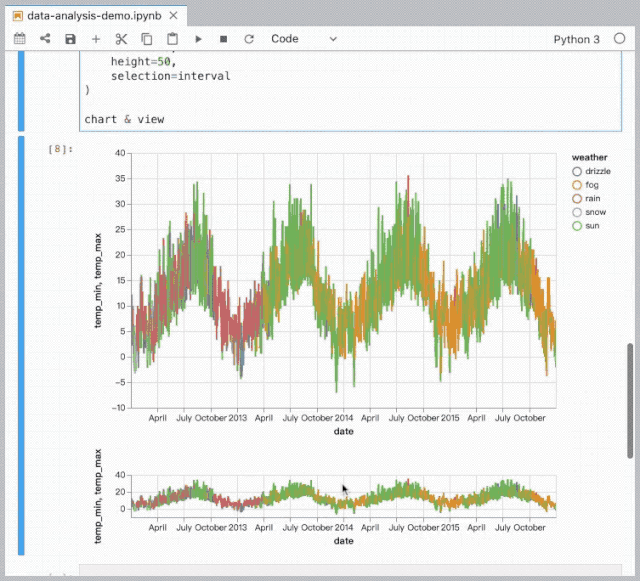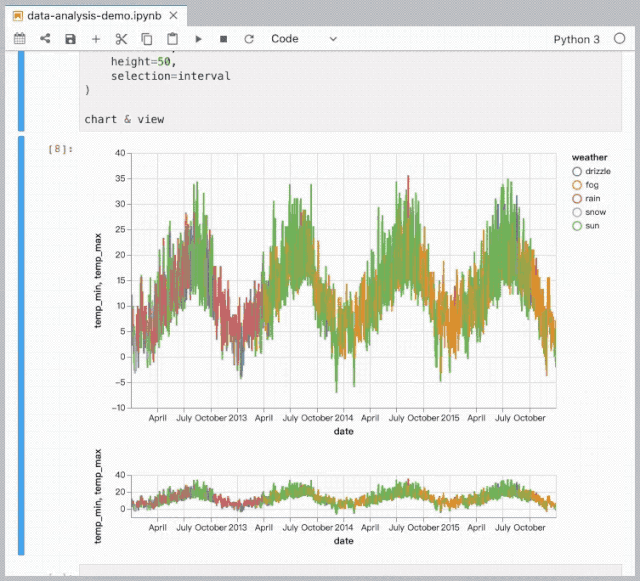
数据分析与可视化
Notebook分享

一键分享
上述数据分析分享到内部学城的效果如下图所示:

Notebook分享效果
模型训练
%%spark
[--conf <property-name>=<property-value>]
[--conf <property-name>=<property-value>]
...
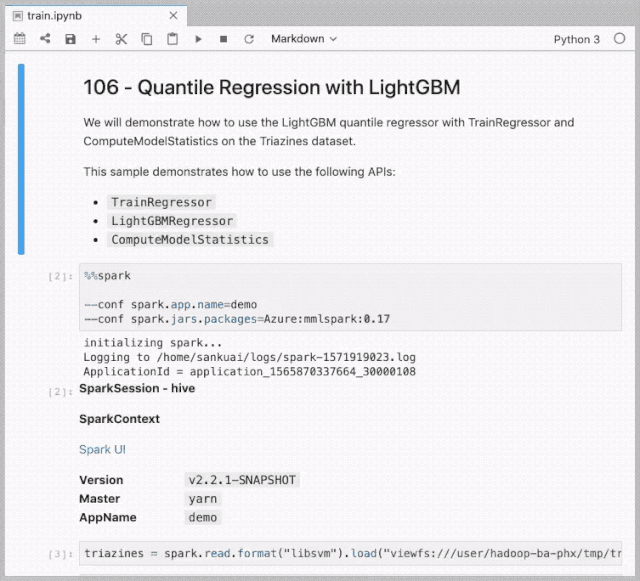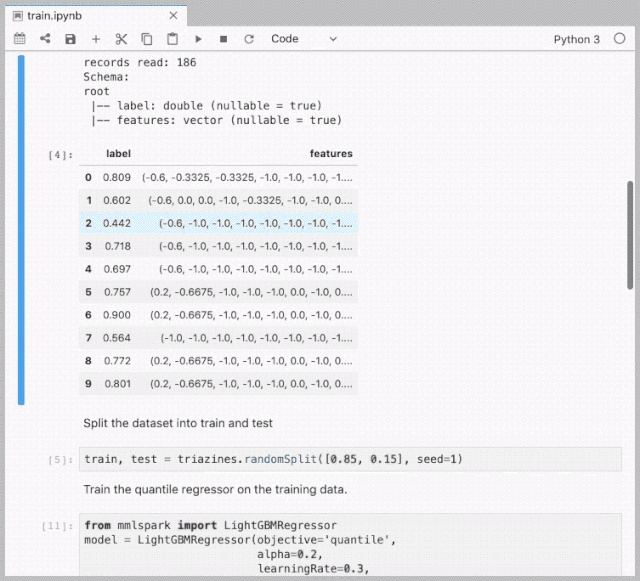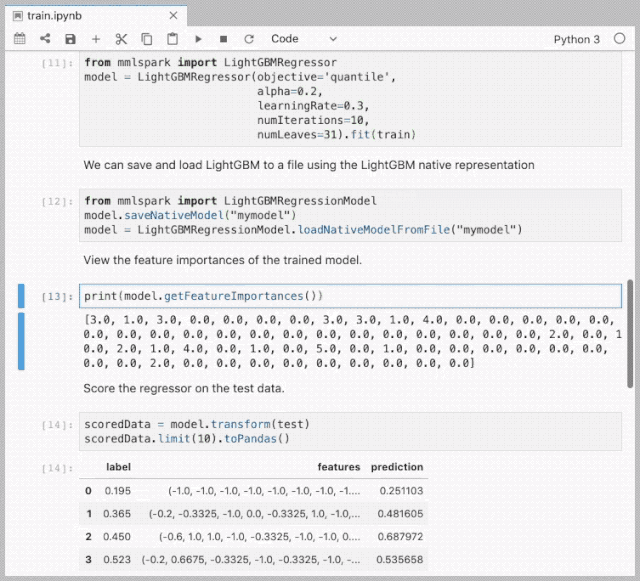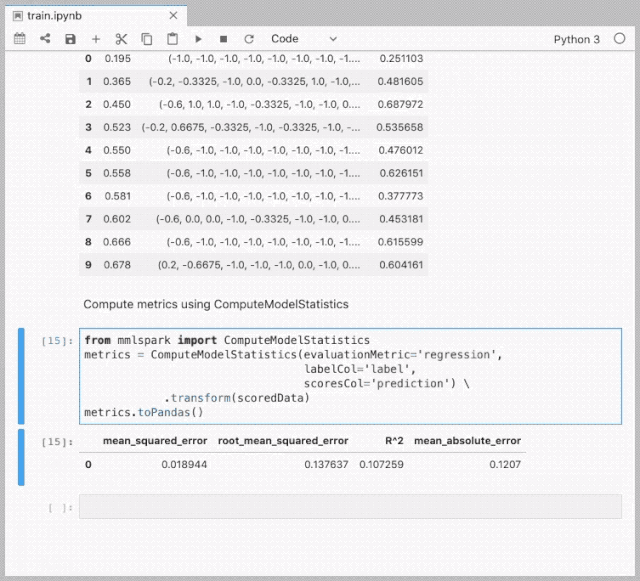
LightGBM on Spark Demo
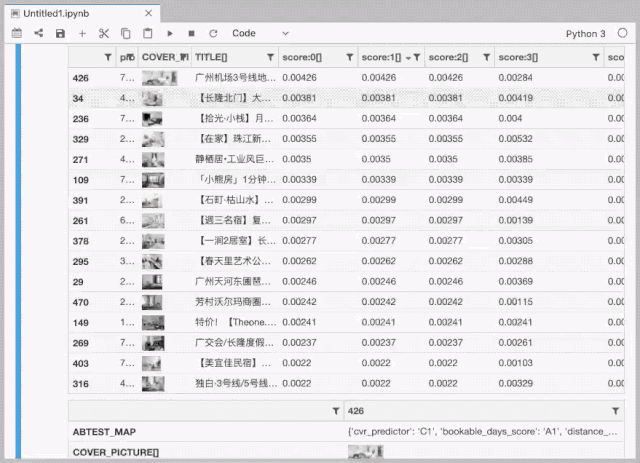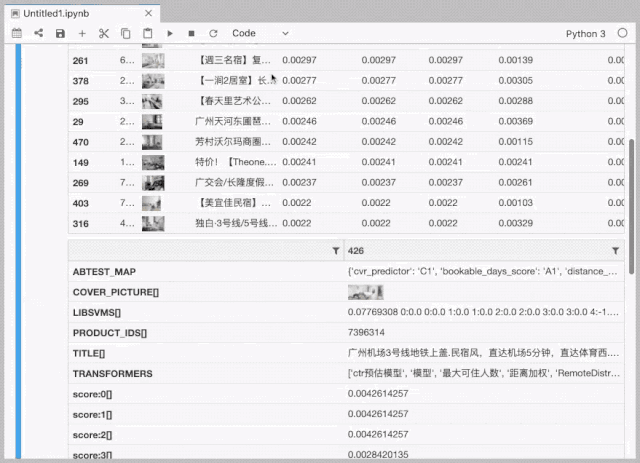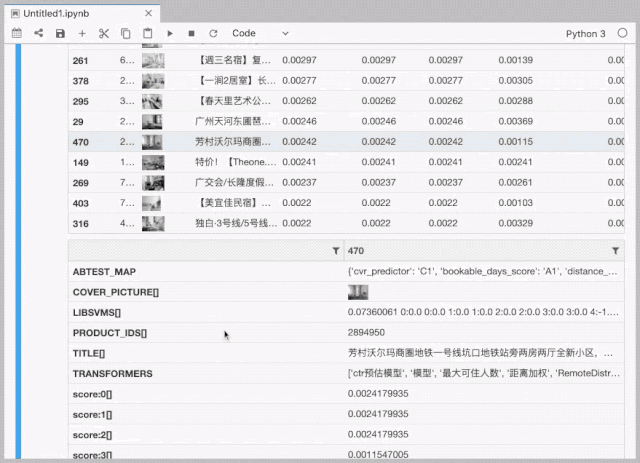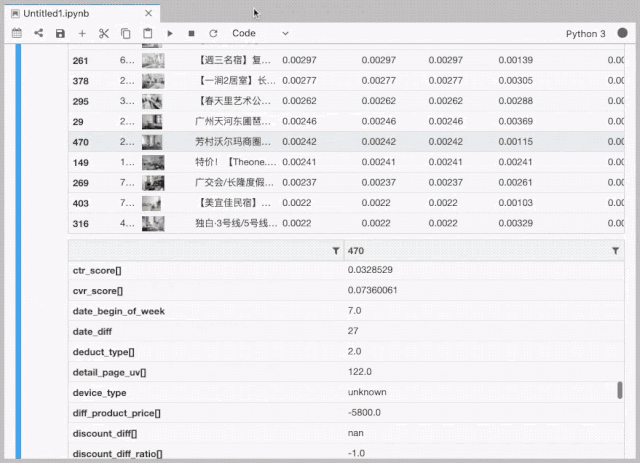
排序策略调试
总结与展望
作者简介
文龙,美团民宿研发团队工程师。
颖艺,美团民宿研发团队工程师。
---------- END ----------
招聘信息
美团民宿研发团队诚招数据系统研发工程师,Base厦门,欢迎有兴趣的同学投递简历到 tech@meituan.com 。





