分享嘉宾:陈骐 美团 高级算法专家
编辑整理:毛佳豪 中国平安浙江分公司(实习)
出品平台:DataFunTalk
导读:知识图谱凭借能够以图模型描述知识和世界万物关联关系的特性,在各行业领域大放异彩。与此同时,知识图谱技术也为场景搜索带来了新的挑战与机遇,在此背景下,美团团队进行了新一轮的技术革新,将知识图谱技术应用于酒旅场景的认知中。本次的分享题目为《知识图谱在美团搜索酒旅场景认知中的应用》,主要介绍:
01
酒旅业务特点
![]()
其实美团有的不止这些,还有同样占据行业TOP的酒店和旅游业务!
酒旅业务和美团其他的本地生活服务到底有什么区别?区别在于酒旅业务的出行半径更大。美团大部分的服务如剧本杀、电影等只需要找到满足用户在当前区域或者当前城市内的商户需求即可,而对于酒旅业务,用户具有更大的出行半径。以三个例子对酒旅业务的特点做更好的解释:
某北京用户想要滑雪或者看海,用户可能会选择距离北京200多公里的质量更高的崇礼滑雪场;对于看海,因为北京当地没有相应的供给,所以用户可能前往秦皇岛的北戴河。所以,对于本地没有相应供给的服务,用户可能会去周边具有相应服务的城市甚至是寻找全国各地具有相应服务的城市,此时就需要美团为用户查找和筛选出合适的场景与适配场景的商户。
①地标/商圈
。用户围绕地标或者商圈寻找酒店,该模式更倾向于推荐的问题;
②商家/品牌。该类用户目标明确,寻找某个具体酒店或对应品牌下的酒店;
③泛场景搜索。比如用户寻找某一类的商家如青年旅社、具备某种设施的酒店又或者是具体的房型比如电竞房等等。其他搜索方式主要是围绕这三种搜索的组合进行展开的。
![]()
①行政区/地域。用户搜索某一区域或者行政区,则美团需要找出该区域内相关的景点;
②商家/品牌。该类用户同样目的明确,会直接搜索相应景点的名称如故宫、欢乐谷等等。
③泛场景搜索。用户查找某一类需求,比如滑雪、爬山,此时具有相同属性、服务项目或同类型的多个景点均可满足用户需求,该场景下,美团需要为用户做出更好的推荐。
![]()
02
酒旅场景认知
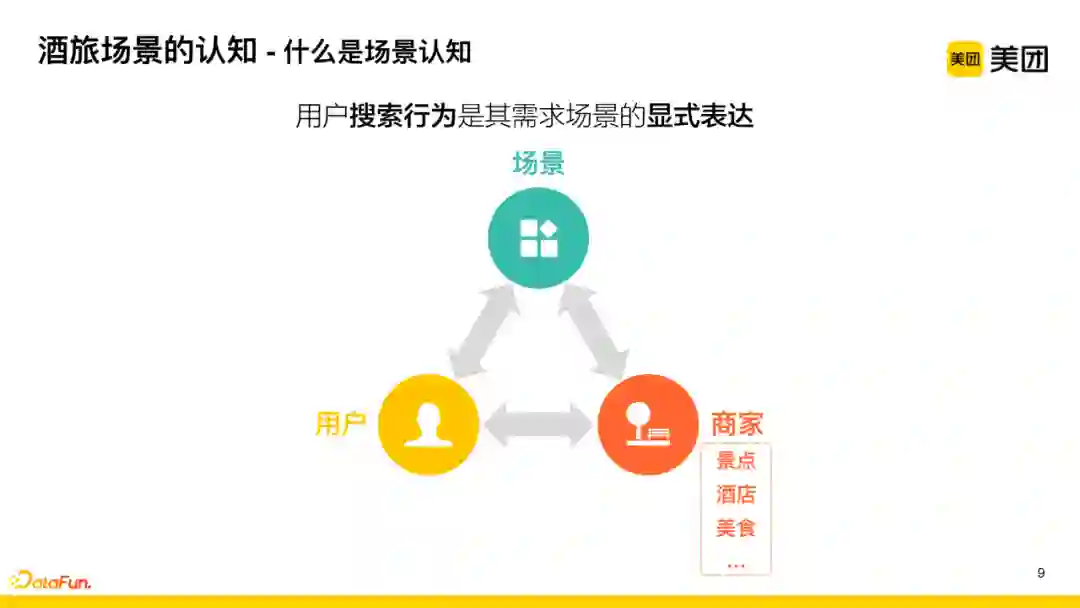
平台中存在大量不同业务类型的商家,如酒店、景点、美食等。用户在平台上发起搜索时,我们认为其搜索行为是需求场景的显式表达,即可以通过对用户搜索行为场景化的理解,去识别用户的需求场景。将用户需求场景通过标签的方式表达后再去进行商户的标签检索,由此可以将用户和能承载其需求的商家匹配起来。
![]()
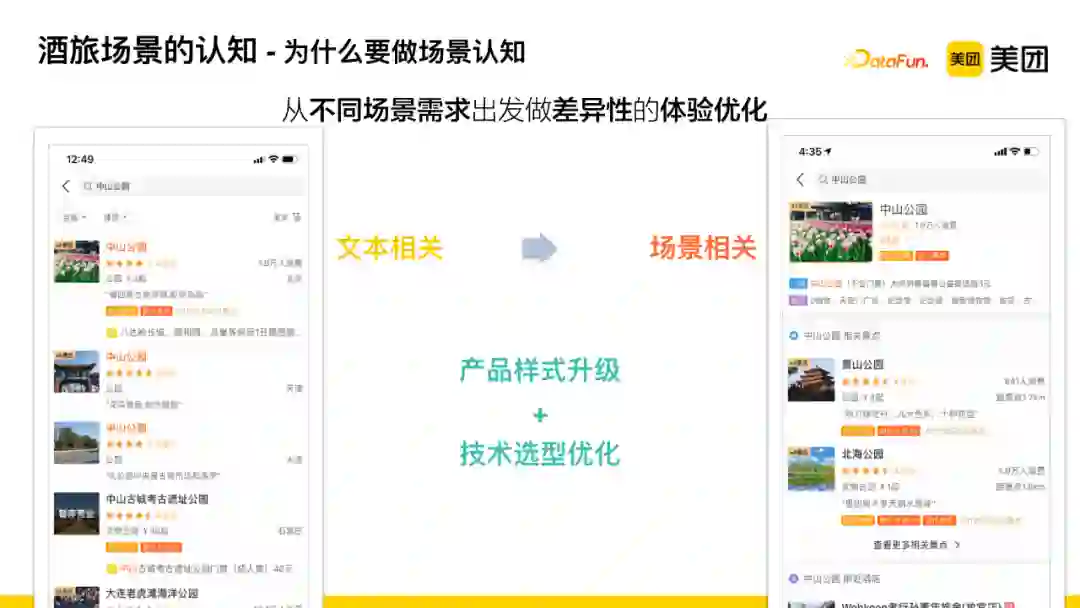
为什么要做场景认知——希望从不同场景需求出发做差异性的体验优化。
以搜索“中山公园”为例:原来的搜索方案会从文本的角度召回文本相关的结果,但这并不能满足用户的需求。我们通过对用户行为数据的分析,发现大部分在北京发起“中山公园”搜索行为的用户往往会围绕北京本地的中山公园及其周围的场景发起后续动作。
这本质上代表了一类用户的场景需求,为了更好地满足这一场景需求,我们采用了图中右侧所示的推荐方法。首先发现用户查找的主点,然后围绕主点为用户推荐其他的服务,如相关景点、附近美食等等,更好地满足用户多元化的需求,并且通过该主点模版样式为用户提供更多能够帮助决策的信息。
![]()
对于酒旅业务,可大致将场景分为两大类:精确的商家搜索、泛场景搜索。
-
单主点搜索
,如故宫、北京昆泰酒店即只有唯一对应的主点,可以围绕该主点为用户推荐服务和商家。
-
多主点搜索
,如方特。全国有多家方特欢乐世界,此时便可用多主点的样式为用户提供信息。
-
地标+X
,如“鸟巢附近的青年旅社”,此时需要为用户推荐主点鸟巢附近的青年旅社;
-
本地+X
,如在北京的城市页面下搜索“爬山”,此时需要推荐本地以及周边范围内能够满足用户需求场景的商户;
-
全国+X
,如搜索三山五岳,该场景下需要帮用户召回全国各地符合用户场景需求的结果。
![]()
最基本的问题是对需求场景的理解需要依托于底层大量的领域知识
。基础的结构化数据并不会携带场景类表达,因此需要做额外的挖掘和理解,举例说明:
(1)搜索和珅府。搜索和珅府应该出现恭王府这个POI,此时便需要挖掘出和珅府是恭王府的别名;
(2)搜索安静的酒店。此类搜索为泛场景搜索,首先需要在B端对酒店做知识挖掘,挖掘酒店是否具有良好的隔音特点;其次,需要将线上的query和已有的B端知识进行准确地关联,比如“安静”的表达映射到的底层的知识标签是“隔音好”。
03
酒旅知识图谱
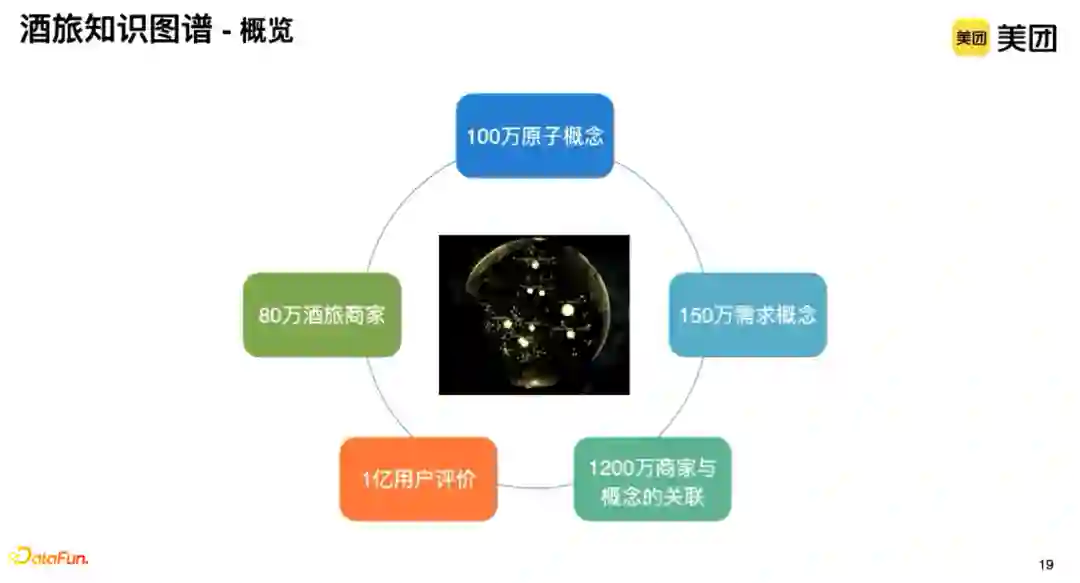
美团酒旅知识图谱大概覆盖80万的酒旅商家、1亿条用户评价、积累100万原子概念以及组合后的150万的需求概念、1200万商家与概念的关联关系。
![]()
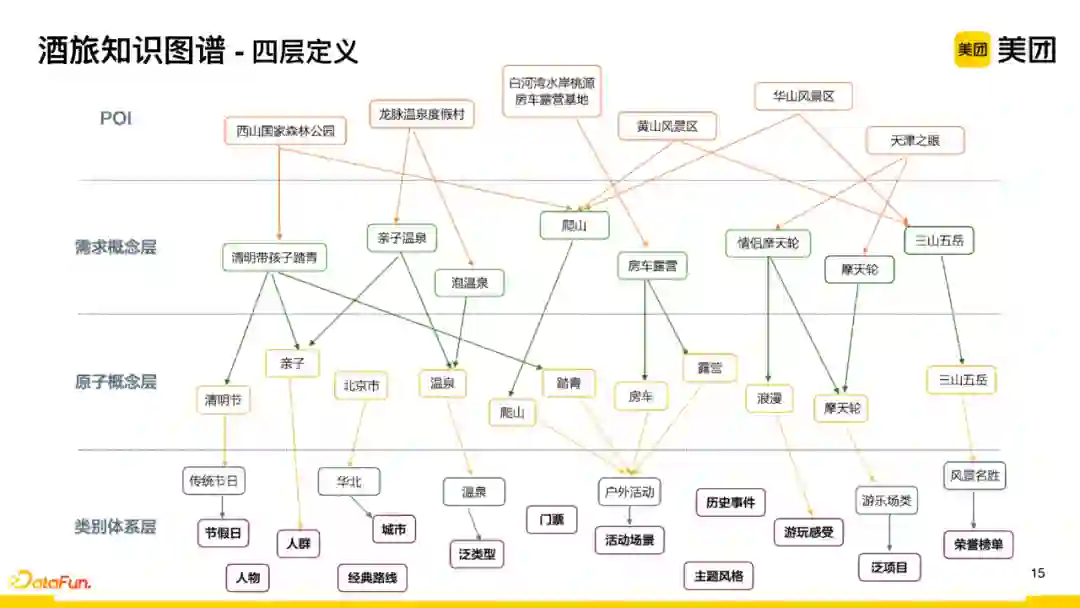
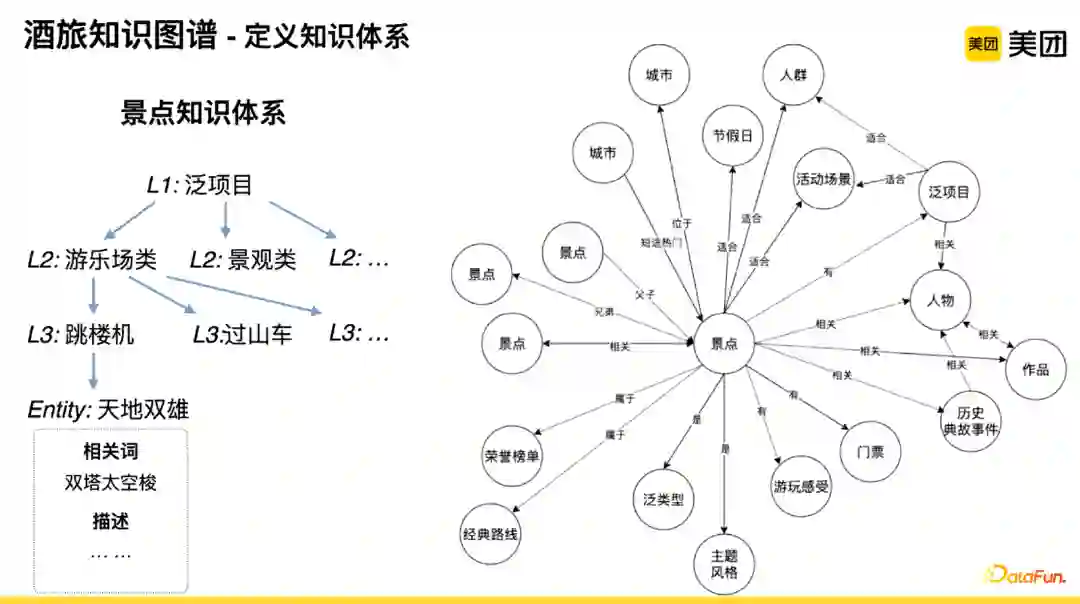
在图谱应用过程中,根据用户需求应用维度,将图谱分为四层:
-
类别体系层
:结合不同业务特点,进行类目的划分。以旅游为例,定义了15个一级类目,在此基础上再拆分二级和三级的具体类别体系;
-
原子概念层
:从用户评论、商户信息中挖掘和抽取出原子概念层;
-
需求概念层
:对原子概念层的数据进行筛选以及符合语义维度的组合,构建面向搜索需求的概念层数据。比如原子概念层中的爬山,在需求概念层中具有直接映射的标签,而对于亲子和温泉两个独立的语义,当有真实的用户需求场景时,便会组合出一个更准确维度的“亲子温泉”标签。这解决了线上搜索query,如果只用最细粒度原子标签进行召回时会出现的语义漂移问题。所以在成本允许情况下,采用基于组合的需求概念层的效果会更好。
-
POI层
:判断当前的商户是否具备需求概念层的标签或知识所代表的属性以及特点。
![]()
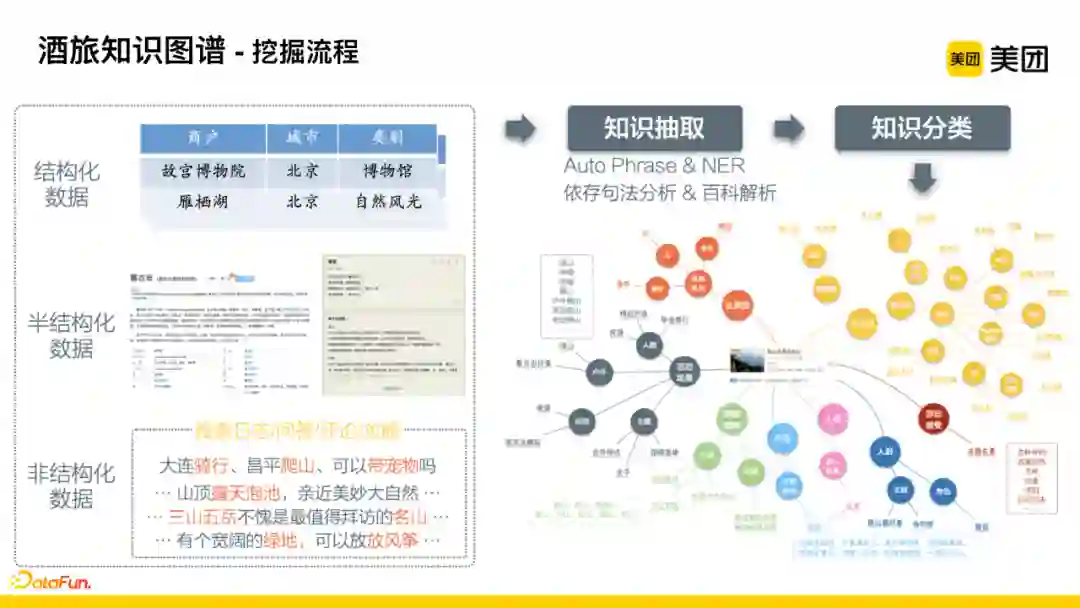
数据来源主要有三类:结构化数据、半结构化数据、非结构化数据。从这些数据源中进行知识抽取,初期没有足够的标注数据时,采用基于半监督的方法做Auto Phrase、依存句法分析等;有了知识积累后,采用NER的方法进行更好的抽取。
将知识片段根据前面所提到的一二三分级的知识体系进行分类。下图所示,将知识库与泰山风景区相关的类目以及最底层所关联的知识片段进行关联。对于泰山风景区,最底层数据只有自然风光,但是我们希望能够将其语义理解到更细粒度,比如自然风光中有峡谷、瀑布、山等等,此时需要注意泰山风景区拥有哪些自然风光类型。同样地,泰山风景区适合哪些活动,在人群角度,比如适合情侣约会、毕业旅行;场景事件角度,适合户外类的爬山、日出日落。这些数据可以为后续query的理解、链接、推荐理由的生成奠定基础。
![]()
构建垂直领域的知识图谱时,需要结合领域知识进行业务的定义。以景点为例,大概有15个一级类目,每个一级类目下还存在二、三级类目,三级的分类体系就能较好满足面向搜索的需求。
![]()
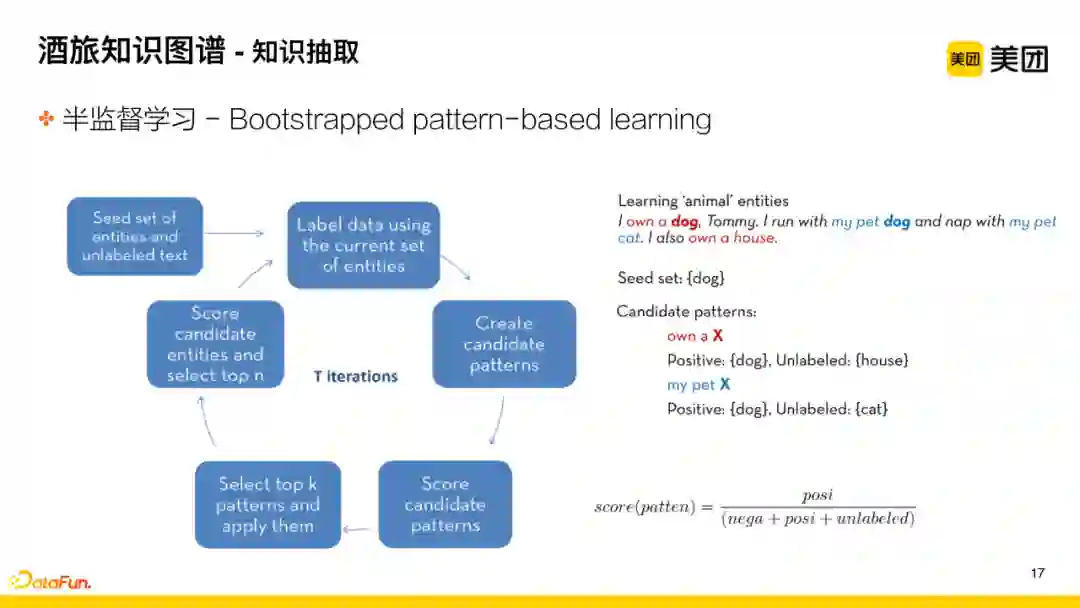
业务初期,采用半监督的学习方法即Bootstrapped pattern-based learning积累知识,以挖掘动物相关实体为例,大致流程为:
-
Step1: 构建种子实体词,在该例子中为dog;
-
Step2: 根据实体词dog,从语料中挖掘出dog前述的pattern:own a、my pet;
-
Step3: 用候选的pattern进一步挖掘与上述pattern相匹配的实体知识片段:house、cat;
-
Step4: 评估house和cat哪一个和dog相同,属于动物这一类型。
经过几轮迭代后,发现对于动物相关的实体词,my pet是更好的pattern,因此便用该pattern去挖掘扩展出更多的实体,前期用这种方式可以快速积累数据。
![]()
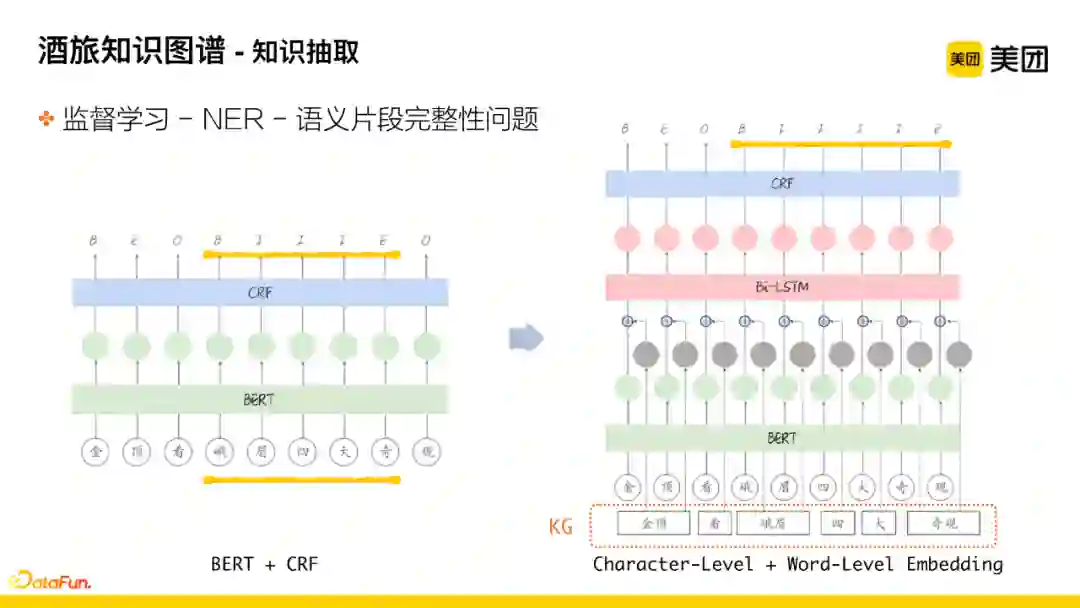
有了标注数据后,就可以采用NER的监督学习方法进行更好地泛化识别。最初采用BERT+CRF的模型进行抽取,但该模型容易将知识实体的语义片段切碎。如下图所示,评论为“金顶看峨眉四大奇观”,抽取到的是“峨眉四大奇”,但我们希望片段能够尽量完整。后来通过引入KG相关信息的方法解决了该问题,首先将需要抽取的文本进行分词,同时引入了Character-level粒度和Word-level粒度的两层向量信息,辅助判定片段切分的边界,这样能有效解决片段被切碎的问题。
![]()
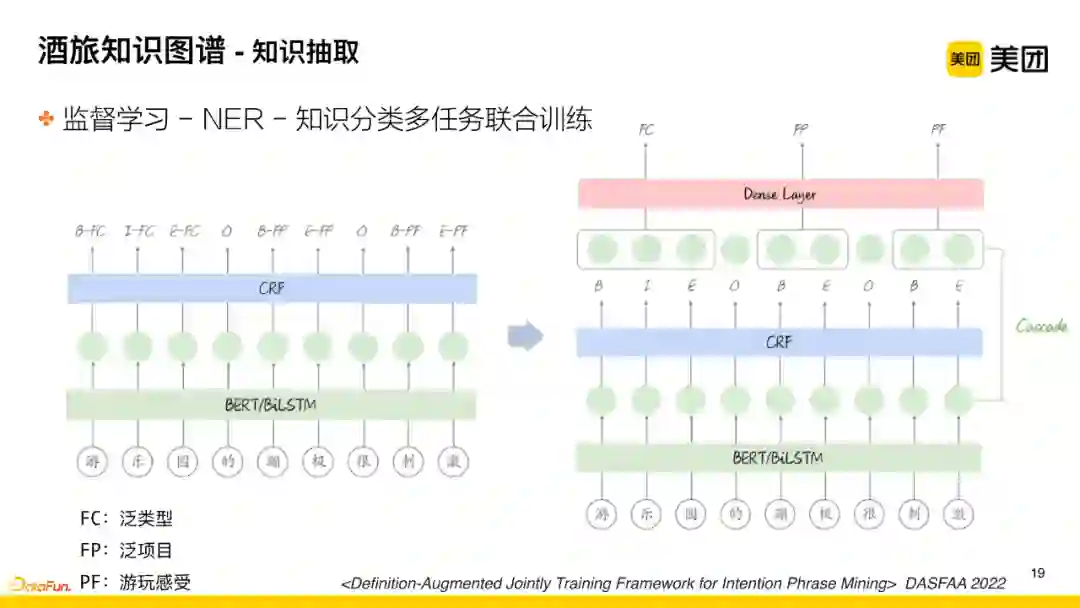
起初为了效率,对前面提到的15个一级类目中的每个类目进行单独地抽取,后续为了提升准确率,便将相关的大类放在一起进行综合的知识抽取,在该过程中会存在知识分类不准确的问题,进一步优化考虑的是采用多任务联合训练的方法,即将知识分类的任务和NER任务融合起来。
大致思路是
:通过第一层编码(采用BERT或BiLSTM编码)之后的向量信息,再用传统的CRF进行NER切分,之后采用casecade级联的思路将向量信息引入分类层进行识别和处理。该工作对整体的准确率和召回率都有比较好的提升(发表于2022的DASFAA会议中)。
![]()
将知识进行一级类目的初分后,需要将知识进行更细粒度的分类,但是因为业务特点,很多知识片段会属于多个二级或者三级类目中的节点,所以这里采用了多标签分类的任务对原始的文本分类片段。比如对于VR项目“飞越地平线”,将片段“飞越地平线”使用BERT进行编码并直接进行识别时,很容易将其分类为过山车的项目,因为形如“飞越XXX”的表达词在更多情况下指的并不是VR项目而是过山车或者其他项目。
为了更好地解决该问题,抽取到该片段后,在模型中引入该片段的上下文信息,丰富上下文表达。同时,在搜索日志和评论日志中进行特征工程处理,添加人工构建的特征,并将这些特征融合,统一进行分类,这样就可以解决单独文本会产生语义偏移的问题。
![]()
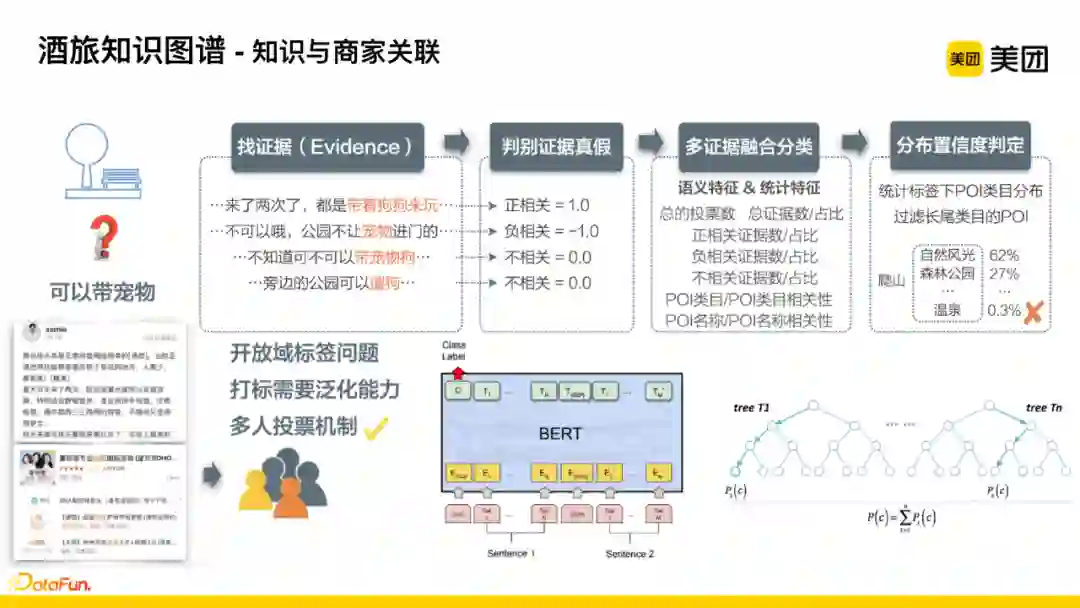
抽取到知识片段并分类后,需要解决知识(标签)与平台商家进行关联的问题。
首先,需要明确的是上述问题不是封闭域标签问题而是开放域标签问题,即并不是单纯进行类目体系的分类挂载问题,因为标签会随着业务的发展以及挖掘不断累积和新增,我们需要对这些新标签和知识进行分类,所以打标需要具有一定的泛化能力。
结合平台进行说明:平台主体是商户,我们需要找到具备知识或者标签的商户。商户具有很多用户评价以及下挂商品,我们直观能得到的是每一条评价和知识的相关性以及每个商品与知识的相关性,反馈到商户的相关性,中间多了一层聚合的过程。
这个问题的解决思路是多人投票机制
,即商户下挂的每一条信息,都是一个用户的反馈,判断相关还是不相关又或者是其他观点,将这些信息进行聚合以及投票的方式就能得到商户具不具备这个知识或标签。
-
-
Step2:判断抽取的短片段的真假,主要分为正相关、不相关、负相关;
-
Step3:多证据融合分类,除了前面得到的证据相关性,又根据语义特征和统计特征抽象出很多维的特征信息,比如POI本身信息的文本相关性,该过程主要使用BERT模型进行文本相关性的匹配。
-
Step4:分布置信度判定,将前两步得到的相关性喂入树模型,最终得到分类结果,即是否相关。
若是线上进行知识分类,对准确率存在要求,允许一定召回上的损失,但是需要保证结果是准确的,这样才能在线上给用户更好的体验。所以在最后一步增加了分布置信度判定的过程,即将打标结果中的商户类目做分布统计,过滤长尾类目的POI,比如用户搜索爬山时,经过类目统计后,在个别判定错误的情况下,存在温泉类目占比0.3%的情况,根据阈值将这一类结果进行过滤。
![]()
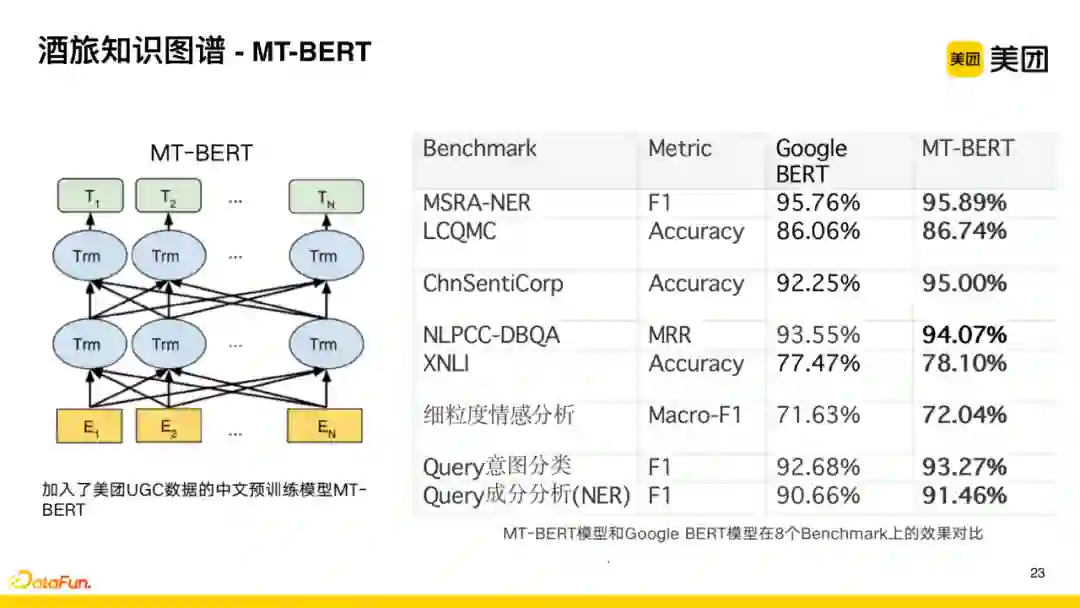
不论是知识抽取还是知识分类,都用到了BERT模型,美团主要用自研的MT-BERT,其特点是引入了美团业务场景下的大量用户评论信息以及商户下挂的业务类信息,对模型进行更好的适应。
![]()
MT-BERT加入了美团UGC数据之后,在一些公开的数据、内部的query意图分类以及成分分析任务上都有比较显著的提升。
![]()
04
-
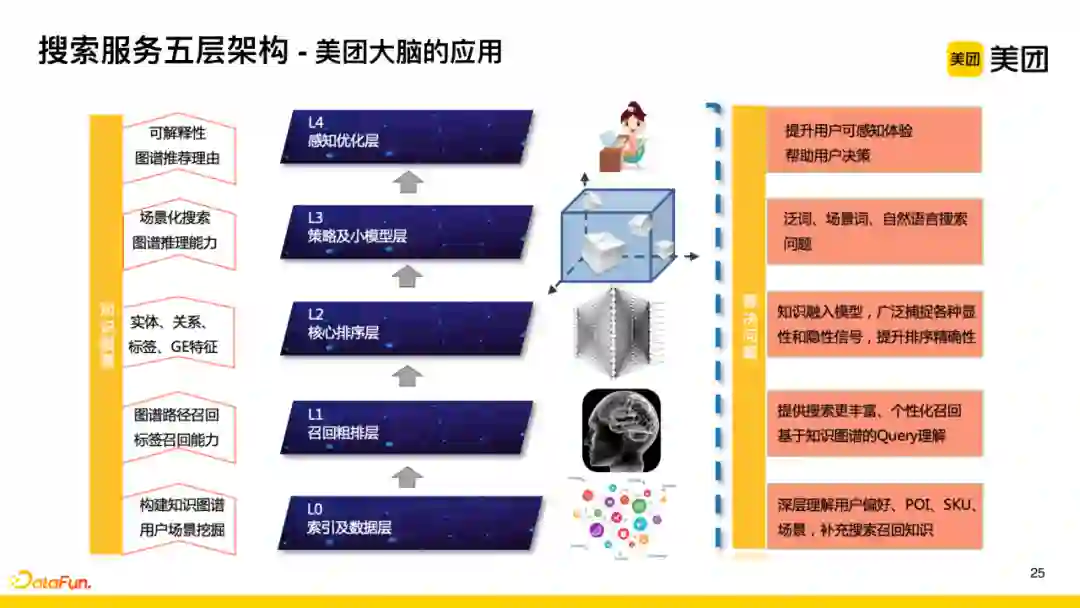
-
L1层
:识别与理解用户query,进行结构化召回;
-
L2层
:基于召回结果,对列表进行深度学习模型排序;
-
L3层
:在不同的业务场景下,进行针对性的策略调整;
-
L4层
:给呈现列表时,提供标签、推荐理由、榜单等可解释信息,强化感知。
![]()
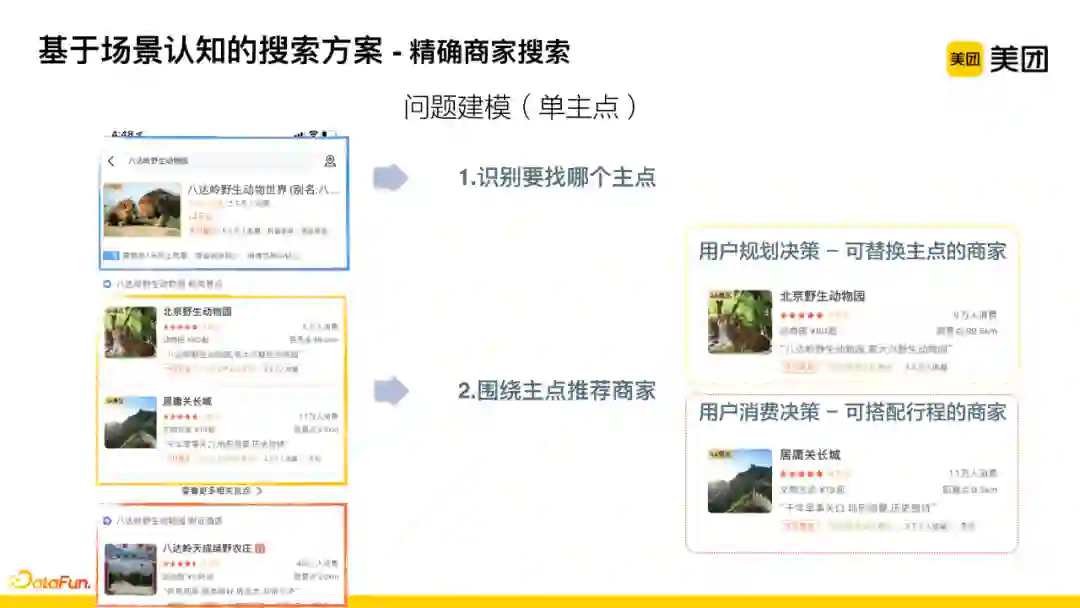
对问题进行建模:首先,识别主点;其次,围绕主点推荐相关商家,包括景点以及附近的酒店等等。第二步再具体细分:当用户处于规划决策环节时,可以为用户推荐可替换主点的商家;当用户已经确定要在某主点进行消费时,可以给用户推荐可搭配行程的商家
![]()
-
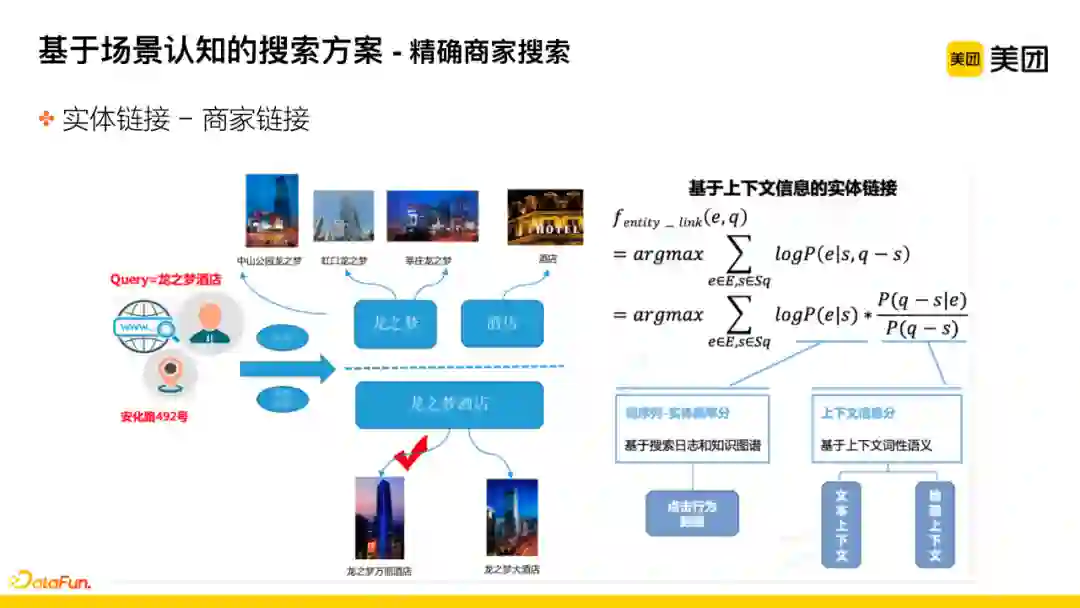
如何识别主点,内部叫商家链接或主点链接即实体链接的变种。
-
采用基于上下文信息的实体链接方案
。用该方案的原因是:美团业务中,搜索同样的query词,在不同的地理位置,所需要的结果可能是有所差别的。举例说明,在上海安化路492号即龙之梦酒店附近搜索龙之梦酒店时,用户大概率想找的就是他附近的龙之梦酒店。
具体策略中主要分为两个分数
:第一个分数为词序列,即当前能够链接到某一实体的序列片段和该实体之间的概率预测分数,基于搜索日志以及知识图谱对商户的别名表达,来得到综合评分;第二个分数为结合上下文的信息得分,结合业务特点将该得分分为两部分,首先为文本语义本身的上下文的语义得分;其次为地理上下文得分,即根据用户和商户之间的距离计算分数。
![]()
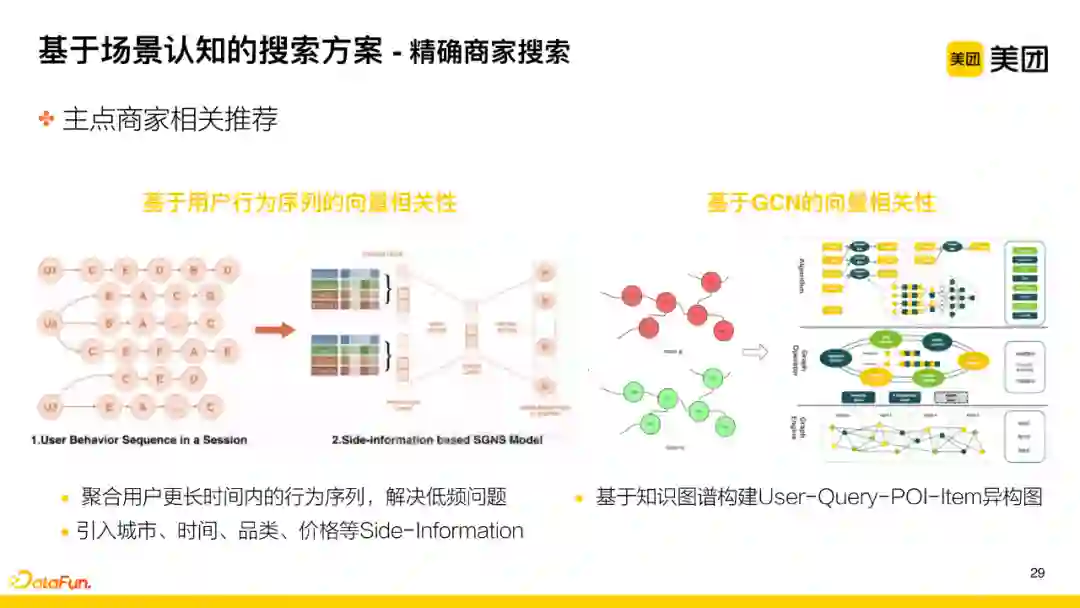
将用户点击过的所有POI构成序列,并基于skip-gram进行编码得到POI向量,再跟主点的POI向量进行计算,得到跟其相似的头部POI。值得注意的是我们根据业务特点进行了针对性调整:首先,酒旅业务是相对低频的业务,所以我们会聚合用户更长时间内的行为序列,重点解决低频问题。其次,随着季节性、不同城市行为特点的差异性,我们引入了城市、时间、品类、价格等等side-information来更好地计算向量的相关性。
每个POI都具有相关知识,我们构建了User-Query-POI-Item(知识)的异构图,通过图学习的方法得到POI的向量。
![]()
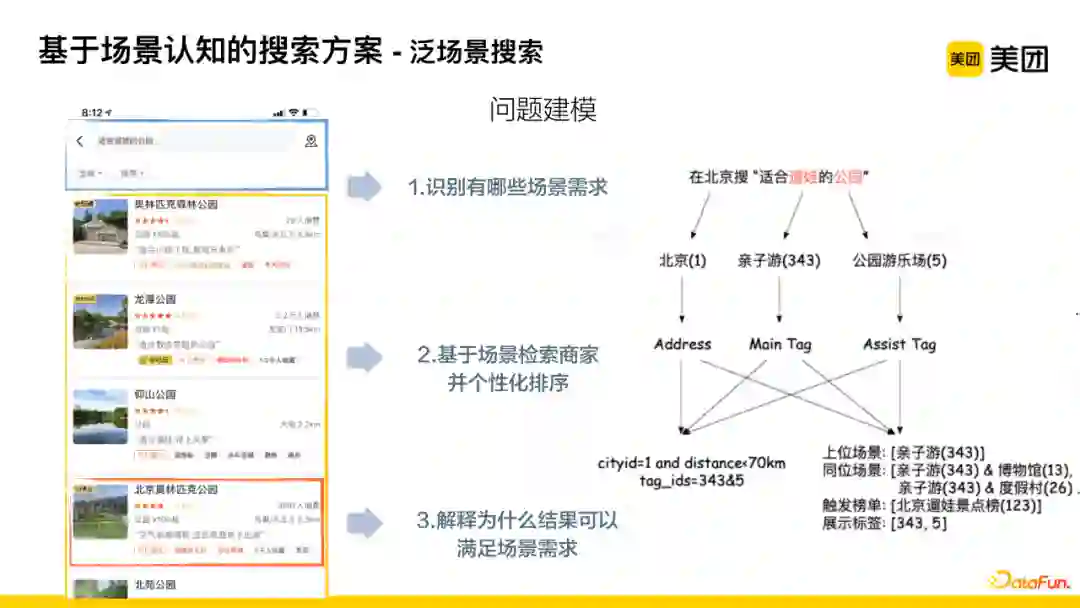
对问题进行建模:首先,识别有哪些场景需求;其次,基于场景检索商家并个性化排序;最后,解释为什么结果可以满足场景需求。
举例说明,在北京搜索“适合遛娃的公园”,则要找的区域是北京,query中不同的文本片段会链接到不同的标签,而标签之间也存在主从概念,因此可以推理出上位场景、同位场景、触发的榜单以及需要展示的标签,最后拼成召回语法进行后续处理。
![]()
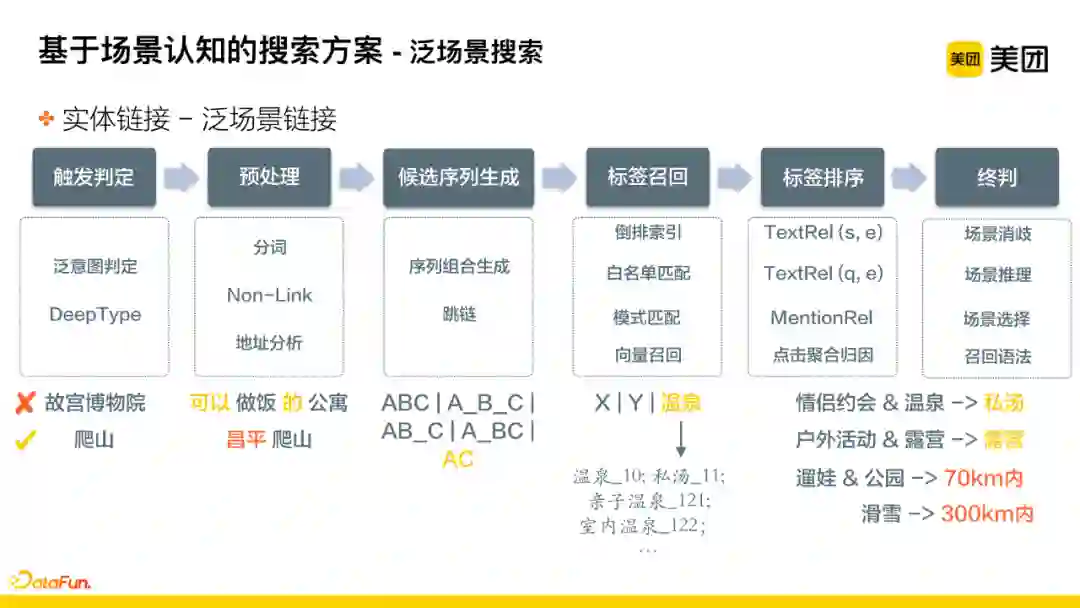
对query进行识别,即对场景标签进行链接。该过程主要在线上进行,并且分为六个步骤:
-
Step1: 触发判定,判断当前query是否是泛场景搜索的类型。比如故宫博物院是精确搜索而不是泛场景搜索,爬山便是泛场景搜索。同时这一步还需要识别相关意图,比如判断搜索意图是景点、酒店还是餐饮等等;
-
Step2: 对query做预处理的工作,包括分词、Non-Link以及对目标区域的识别;
-
Step3: 根据处理后的片段生成候选序列,进行多元组合,也会用到跳链的技术。比如现有A、B、C三个片段,可能会生成如下的ABC、AB_C、A_B_C、AC的序列;
-
Step4: 用组合出的序列,进行倒排索引的召回,中间还包括白名单匹配、模式匹配、向量召回等等去扩展相关的标签;
-
Step5: 标签排序,对上述召回结果进行排序。该过程有几个重要特征,包括当前实体和序列的相关性、query和实体的相关性、mention信息以及点击聚合归因后的统计特征,把这些糅合在一起进行分类,在不同业务中分别选取topN的标签进行应用;
-
Step6: 终判环节,对识别出的多个片段链接的不同标签进行消歧和推理的工作。
![]()
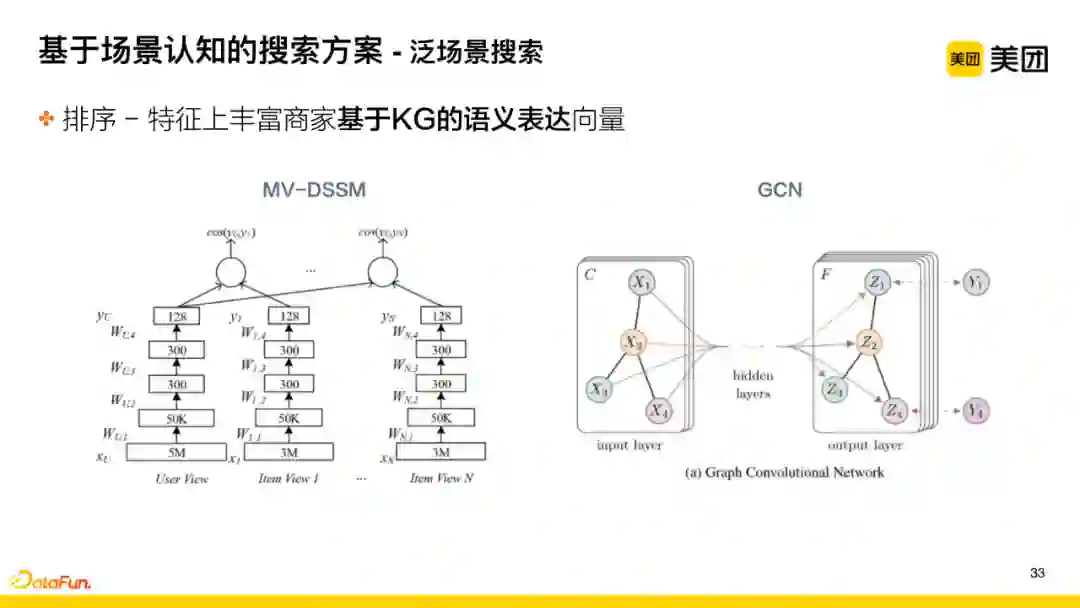
该技术点考虑的是如何更好地进行基于场景类搜索的个性化的排序。泛搜索类的表达在POI名称维度的语义上是缺少语义相关性的,所以需要在模型中补充知识维度的信息。
首先,在特征层面,要丰富商家基于KG的语义表达向量,主要采用以下方法:
-
-
采用GCN的结构,训练得到POI和query之间的向量,将向量引入到后续模型中。
![]()
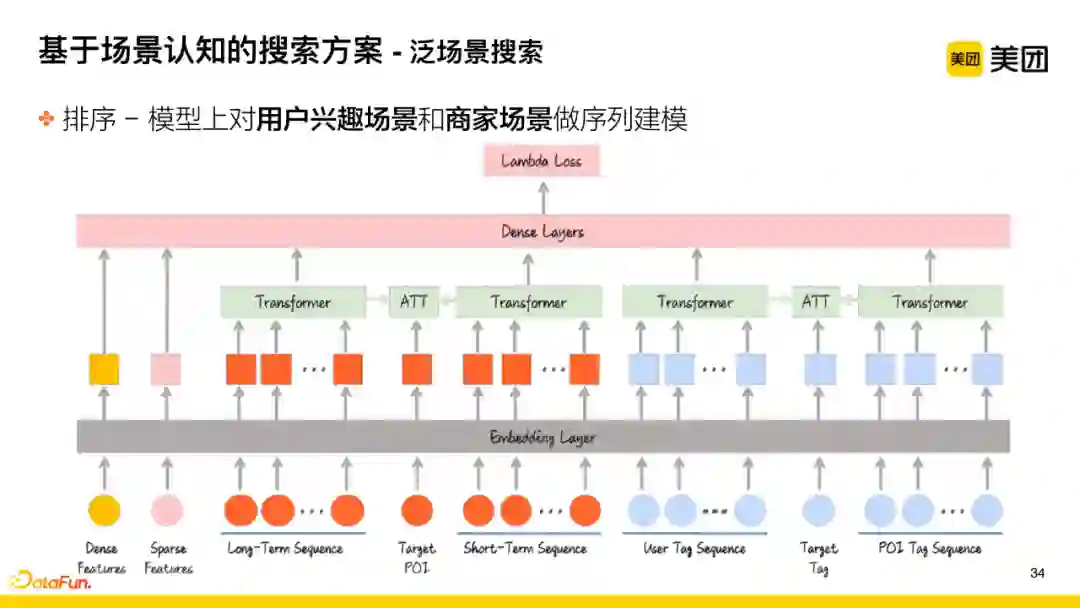
其次,在模型结构上,对用户兴趣场景和商家场景做序列建模。该工作中的创新点:
-
当前在排的POI与跟用户的long-time sequence以及short-time sequence的attention工作,其中,long-time sequence以及short-time sequence指的是用户更长时间内点击过的POI的行为列表以及更短期的行为列表所生成的序列编码;
-
引入了tag的序列。将识别出的当前用户要找的需求场景的标签,与用户之前有过行为的商户的tag进行聚合,变成序列;POI本身挂载的tag的知识信息同样是序列,将这两个序列编码后做attention工作,能够更好地捕捉到泛场景搜索下,用户的需求场景标签与商户场景序列以及用户兴趣序列之间的相关性。
![]()
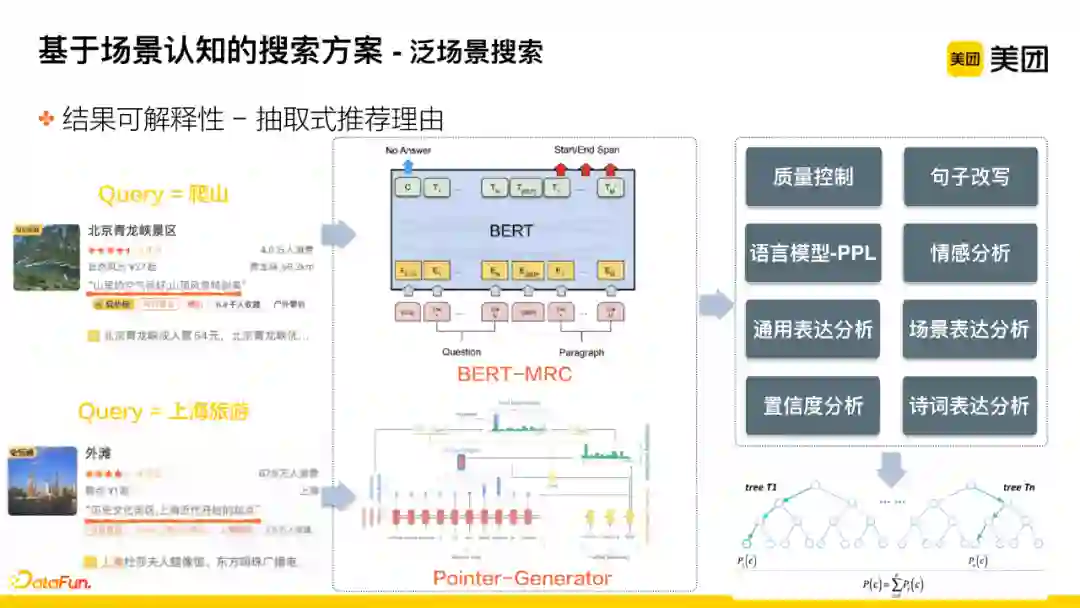
该技术点考虑的是如何更好地向用户解释为何当前结果和搜索场景是相关的。该问题一部分通过推荐理由实现。推荐理由有两种实现方法:抽取式推荐理由、生成式推荐理由。
该方法通过抽取的方式挖掘相关的推荐理由,抽取时主要分为两大场景:
第一类,如搜索“爬山”。该类query属于具体的场景,在该具体场景下,我们希望给用户提供的推荐语是直接跟场景有关的,即其他用户来该景点时,对该地适合爬山的表达。对于这一类推荐理由,采用文本匹配并结合BERT-MRC的思路对候选句子进行召回。
第二类,如搜索“上海旅游”。该类的query的范围比较泛,因此在该场景下,会给用户推荐默认的特点,即景点本身的特点描述。对于这一类可以直接代表商户特点的推荐语,采用短句的组合以及结合pointer-generator网络抽取的思路,生成候选的句子。
当有了候选推荐语后,不论是用户的推荐语还是商户本身的推荐语,都会统一进入判定的模块,对候选的句子进行一系列质量的判定,包括句子的改写、表达通顺度、表达情感等等,通过这些模块得到多维的分数,最终作为特征喂入树模型中进行整体的质量判定,得到终判分数。
![]()
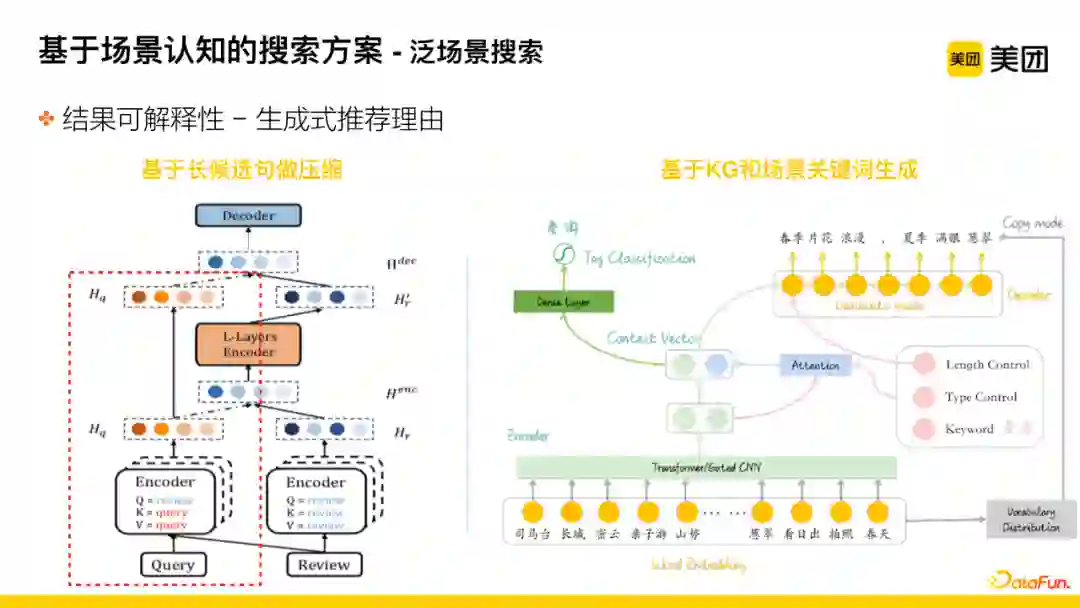
抽取式推荐理由能解决大部分问题,但也存在一些问题:
句子表达的意思正确但偏长,而前端给用户展示时存在句子长度限制。所以为了能够更好地利用偏长的句子或者意思没有问题,但表达比较生涩、没有亮点的句子,采用基于transformer的网络结构对部分句子进行压缩,让其符合句子长度的限制。
此外,很多POI下面的评论本身比较少,而且用户的表达质量较差,并且我们对推荐语的整体把控比较严格,所以导致挖掘不到与场景相关的推荐语。
此时,便考虑基于商户已有知识生成推荐语,进行数据扩展。该思路基于KG和场景关键词生成的方案进行实现。存在两个要点,举例说明:首先,“司马台长城”在Word embedding层中存在与POI相关的标签;其次,对tag进行控制,控制根据“春游”标签产出的相关推荐语。通过这两个维度综合进行编码,最后得到生成的片段,encoder后得到 “春季片花浪漫,夏季满眼葱翠”。基于这个句子进行前文提到的句子质量判断。用该方法补充召回,再统一产出最终推荐语的离线候选。
![]()
上述介绍的是在离线环节生成推荐理由的相关候选,不论是抽取式还是生成式,部署到了线上后,还会涉及到具体线上流量的分发。即当列表中都是符合用户场景需求的内容时,需要进一步考虑:首先,推荐语和query具有相关性;其次,列表中的推荐语不能过多的同质化,要穿插多样的表达方式;最后,要保持内容新颖等等。
![]()
总体来说,从底层数据层到上游展示层,整体架构会分很多层,具体结构如下:
![]()
![]()
2015年硕士毕业于中国科学院计算技术研究所,同年加入美团,参与了酒旅搜索和推荐从0到1的搭建与技术演进过程,有很强的业务建模能力,现担任场景搜索和旅游搜索方向技术负责人,主要关注语义理解、知识图谱、数据挖掘和深度学习排序等技术在业务场景下的落地与算法优化。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。
![]()
点击阅读原文,进入 OpenKG 网站。