高级软件工程师教会我的那些事儿



计算机科学有两个难点: 缓存失效,给变量命名,以及差一错误。 ——Leon Bambrick
“软件的主要价值不在于产生的代码,而在于产生它的人所积累的知识。”——Li
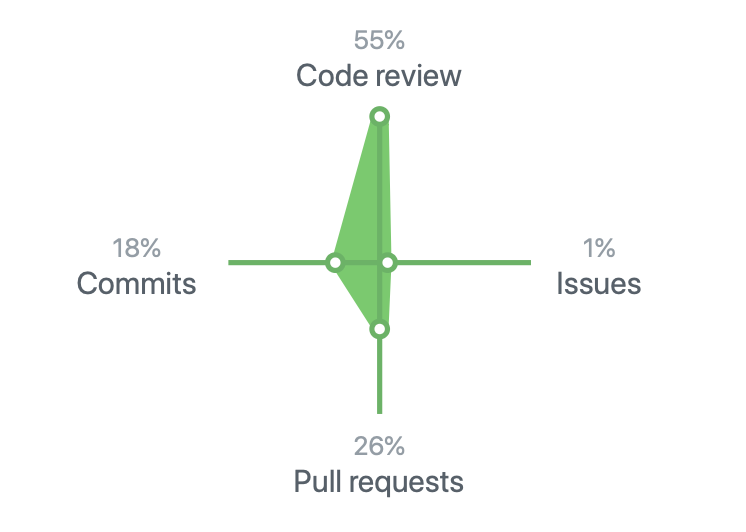
我的Github数据

演示如何使用我正在测试的类/函数/系统;
展示出所有我认为可能会出错的内容。

这锁好使(吗?)
首先是你用来开发的机器(所有“它在我的机器上能正常工作!”这类meme(梗)的来源);
其次是你用来测试的机器(可能与你用来开发的机器相同);
最后,有你用来部署的机器(请不要让它与你用来开发的机器相同)。


使用数量是多少?
有多少用户?预期的增长是多少?(这将转化为多少个数据库行)
未来的失误可能是什么?
本地开发将如何运作?
我们将如何打包和部署?
我们如何进行端到端测试?
我们将如何对这项新服务进行压力测试?
我们将如何管理秘密?
CI / CD集成?
你不能把它们放在代码中,不然任何人都可以看到它们了。
把它们作为环境变量,就像12 factor app那样?这是个好主意。但是你要怎么把它们放在那里?(每次机器启动时访问PROD机器来填充环境变量都很痛苦)
部署为秘密文件?文件来自哪里?它是如何填充的?
保持业务逻辑和基础架构分离:通常退化的是基础架构——使用量增加,框架变得过时,零日漏洞的出现等等。
围绕维护来构建流程。对新的部分和旧的部分进行相同的更新,可以防止新旧之间的差异,并使整个代码保持“现代”。
确保你一直在修剪所有不需要的、旧的东西。

部署是否需要花费太多时间?
Code review会变得更加不容易吗?
如果其中一个有bug,就会自发阻止一个功能。
这样做违背了降低风险的原则,或者说是增加了出错的风险。

机器开启了吗?
是否装好了正确的代码?
配置到位了吗?
<代码特定配置>,就像代码中的路由是否正确?
架构版本是否正确?
然后,进入代码部分。




从抽象还是实现的角度思考?
我应该对如何做事有强烈意见吗?也许是因为以前吃过亏?我以前做过的工作是否为自己赢得了话语权?
开发工作流程。如果因紧急情况或事件需要改变工作方式——那么这个流程是否会被破坏?它需要被修理好吗?
utils(你放置随机东西的文件夹,不放在这里的话,你不知道该放在哪里)是代码味道(code smell)吗?
如何处理代码和工作流的文档?
如何监控UI才能知道什么时候出问题了?
花时间设计完美的API /代码合同,以及自己写出代码并反复迭代选出最优的那个之间,哪一种更好?
简单的方式vs正确的方式?我不觉得正确的方法永远是优越的。
自己做事vs教那些不会的人如何做事。前者完成速度快,后者意味着你以后就很少需要自己亲自动手了。
当重构和防止巨大问题时:“如果我先改变了所有的测试,那么我会看到我有52个文件需要修改,这显然太大了,但是我先去管代码而不是测试吧。”分开处理值得吗?
在降低风险(derisking)方面做进一步探索。有哪些策略可以降低项目的风险?
收集需求的有效方法有哪些?
如何降低系统退化率?


☞【只有光头才能变强,文末有xx】分享一波Lambda表达式
☞从4个维度深度剖析闪电网络现状,在CKB上实现闪电网络的理由 | 博文精选
☞一文了解超级账本DLT、库、开发工具有哪些, Hyperledger家族成员你认识几个?
![]()
你点的每个“在看”,我都认真当成了喜欢