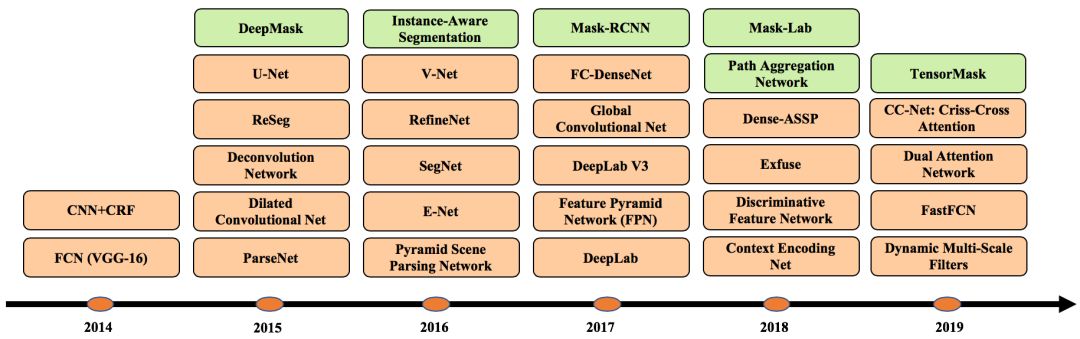
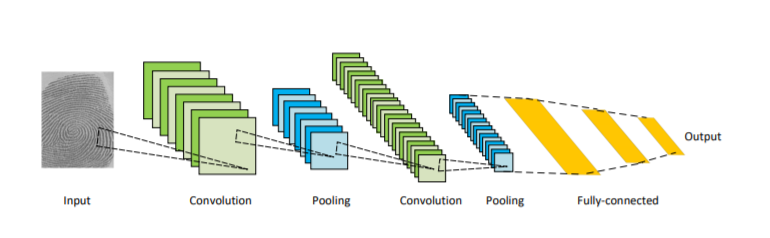
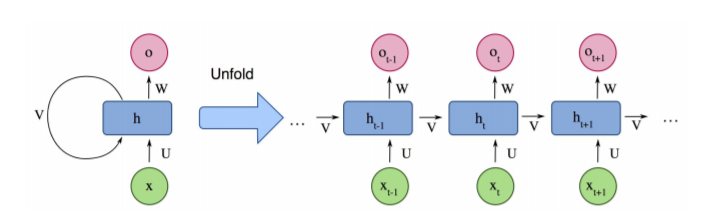
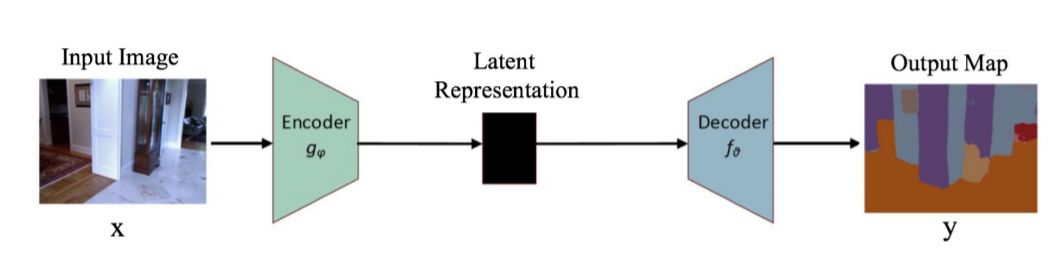
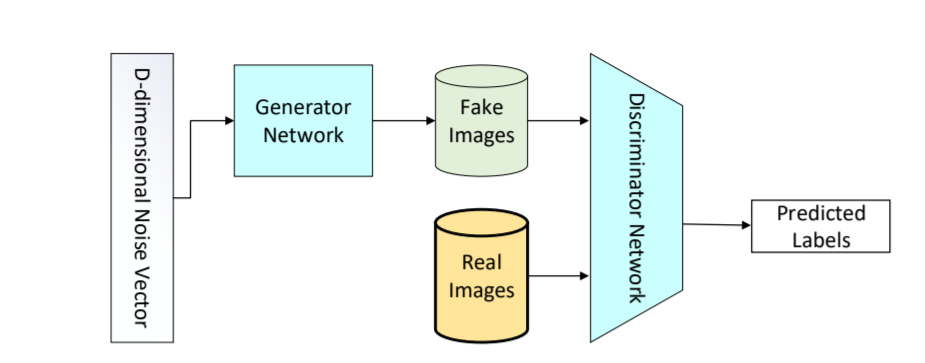
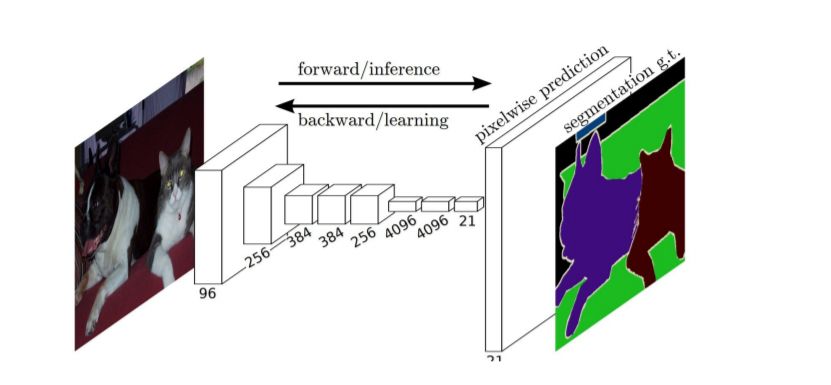
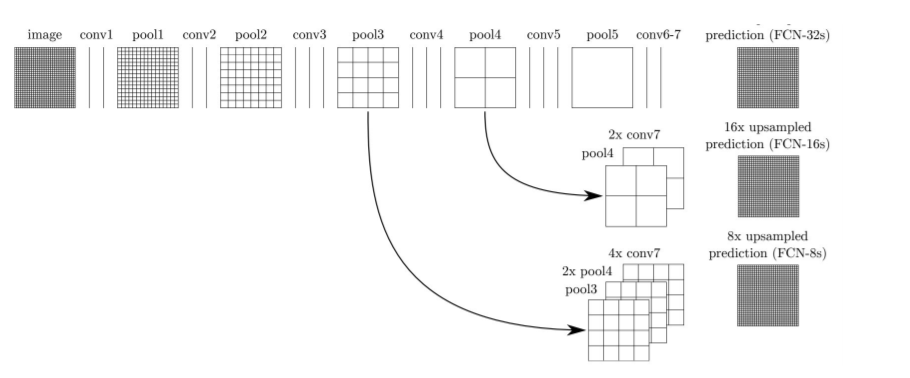
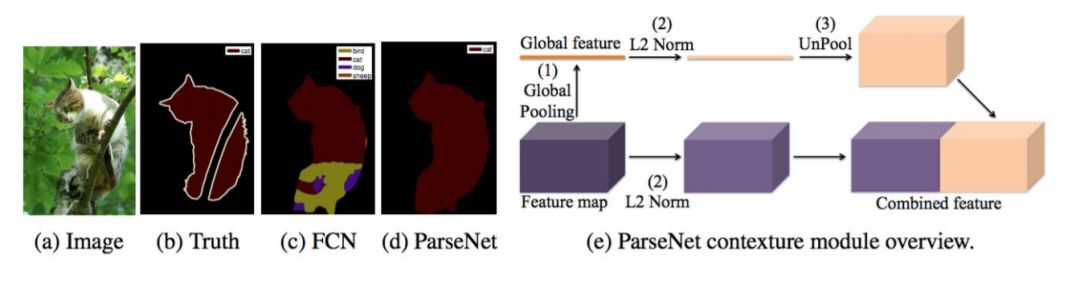
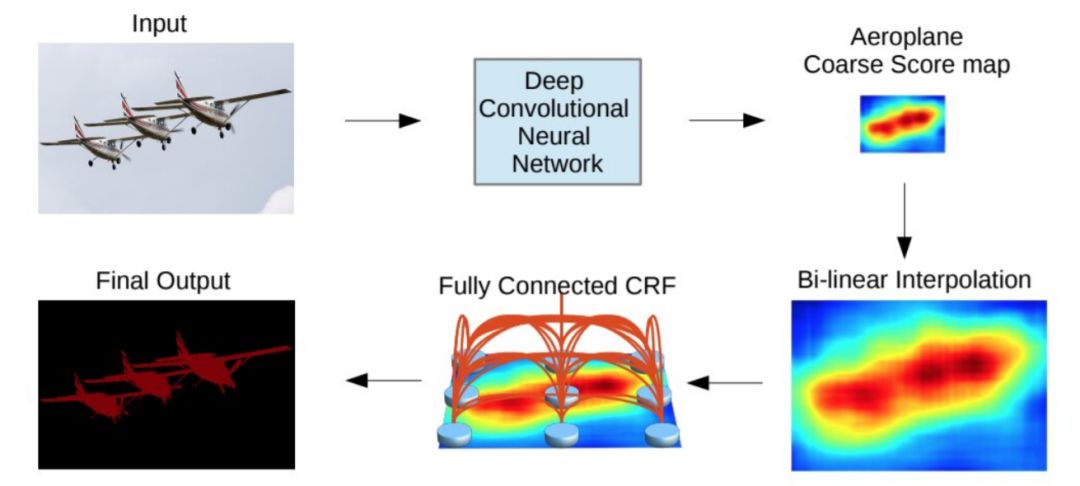
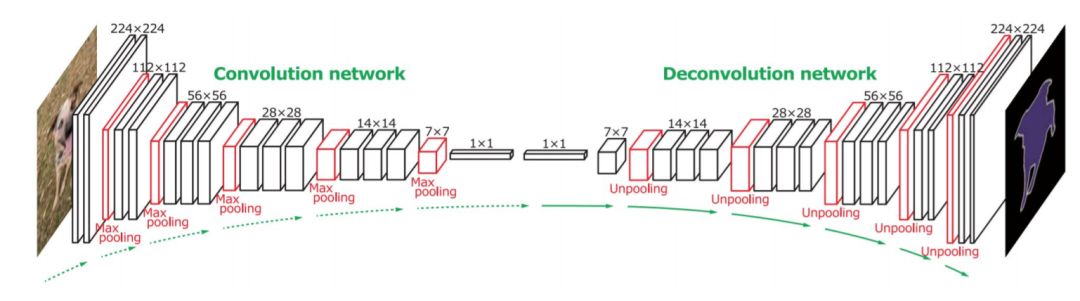
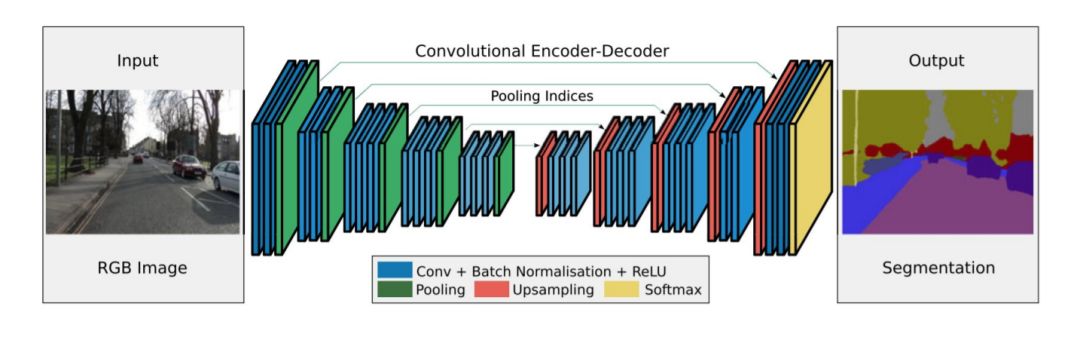
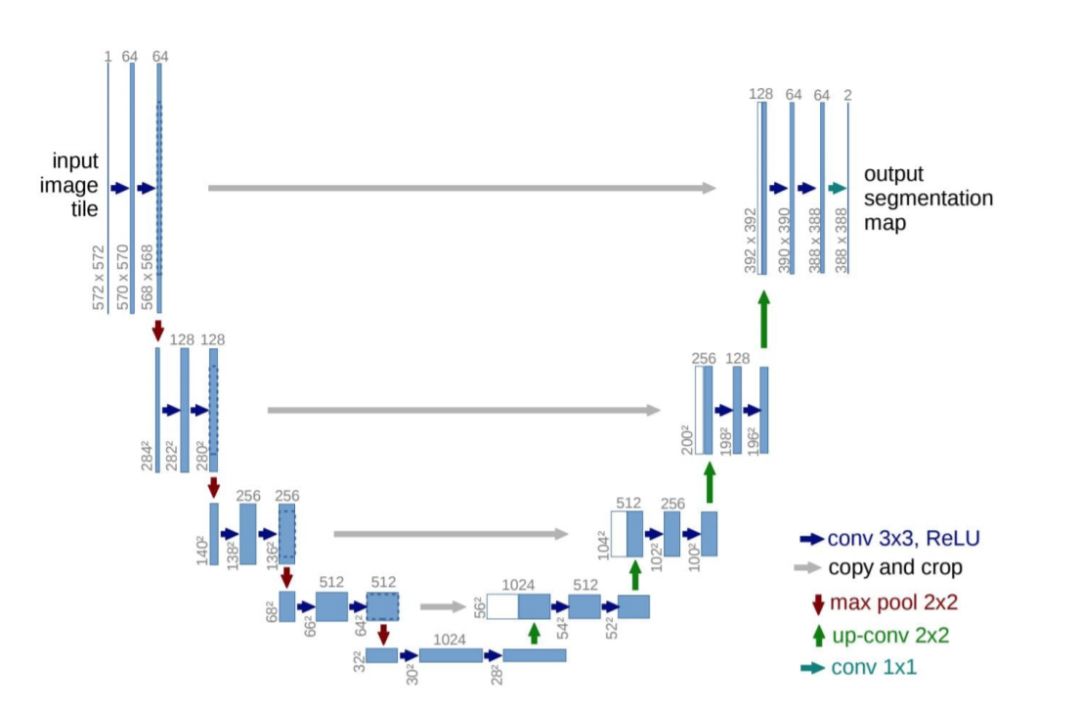
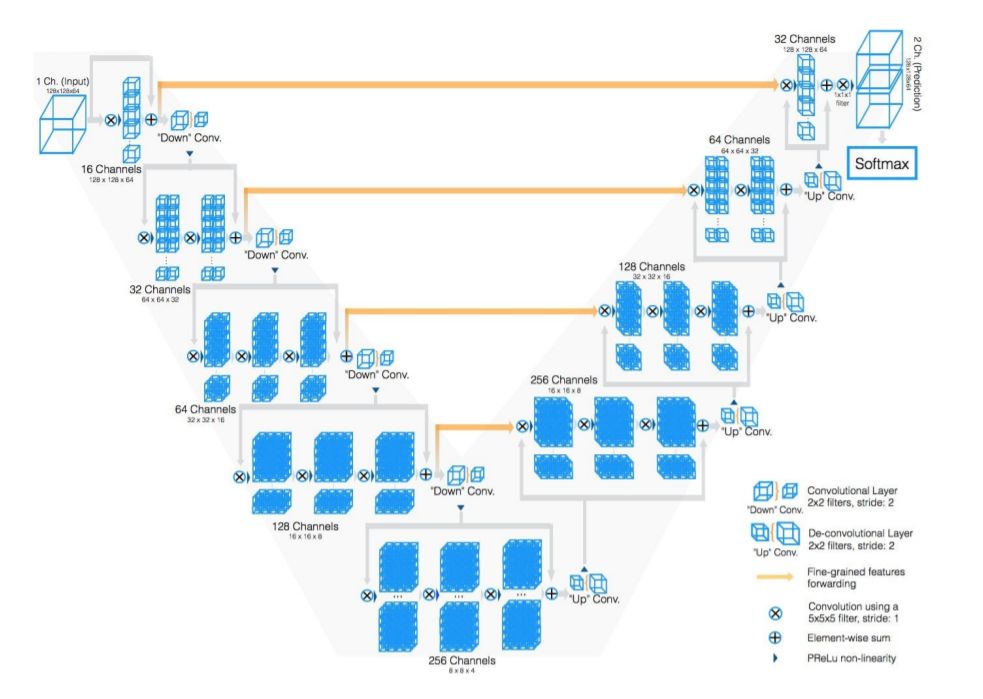
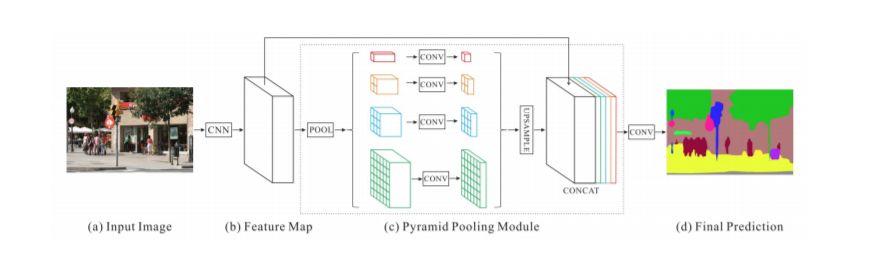
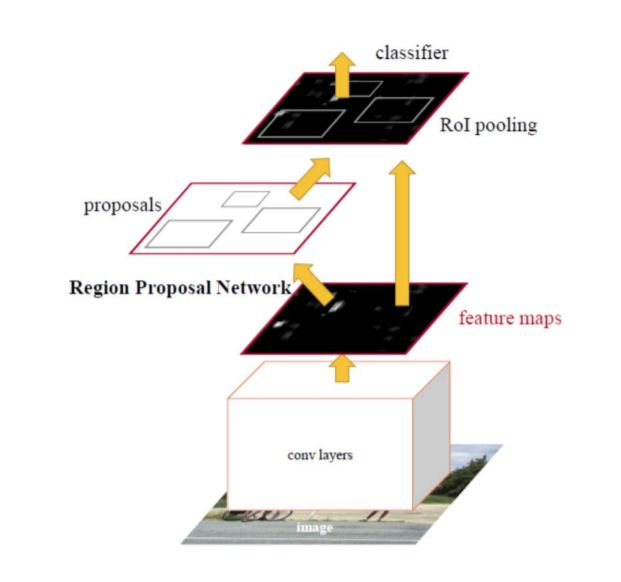
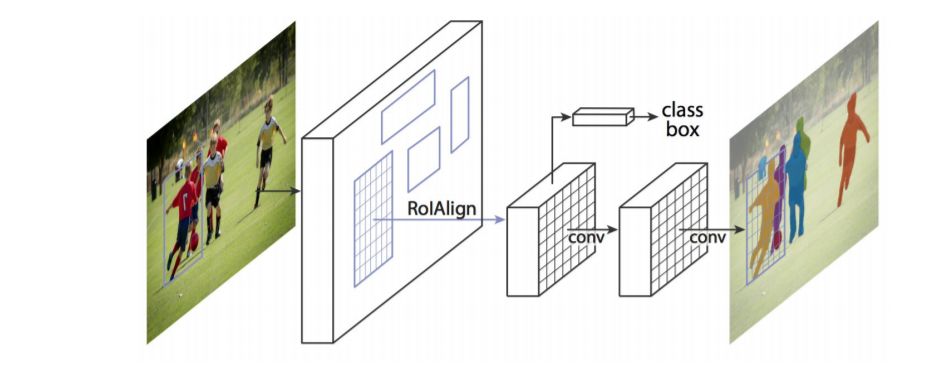
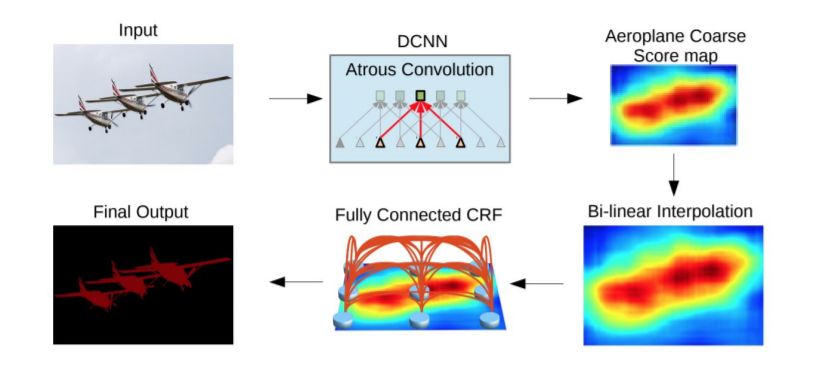
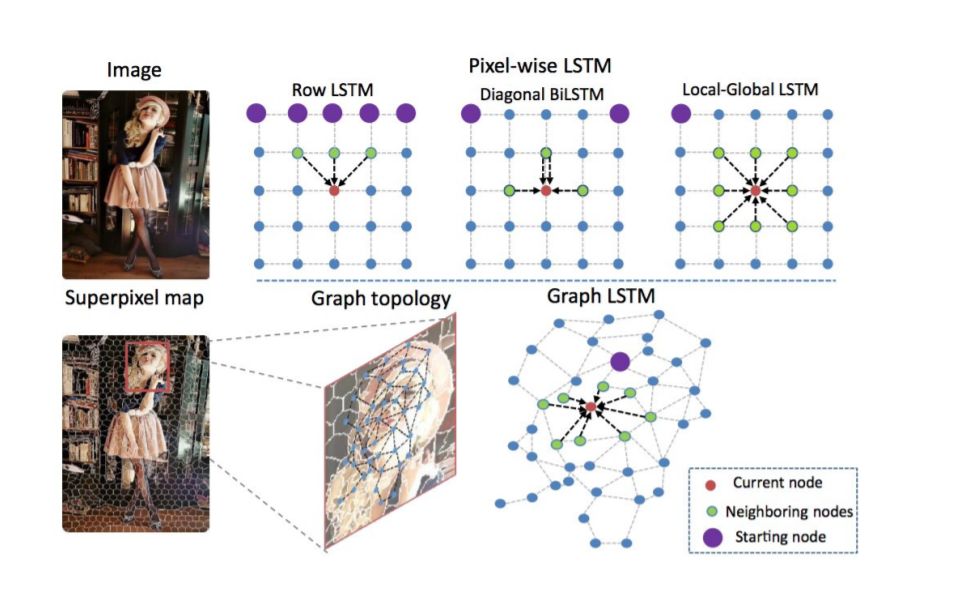
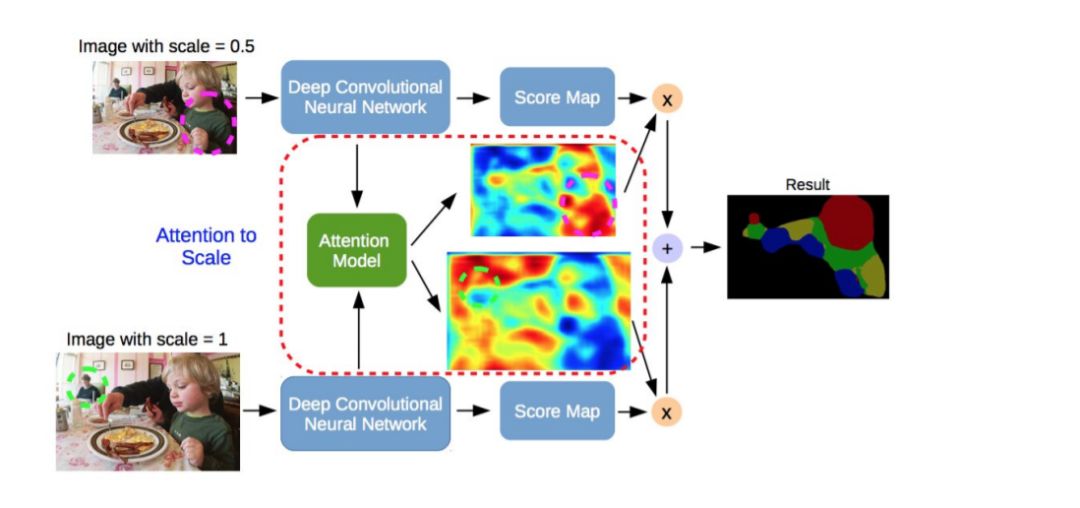
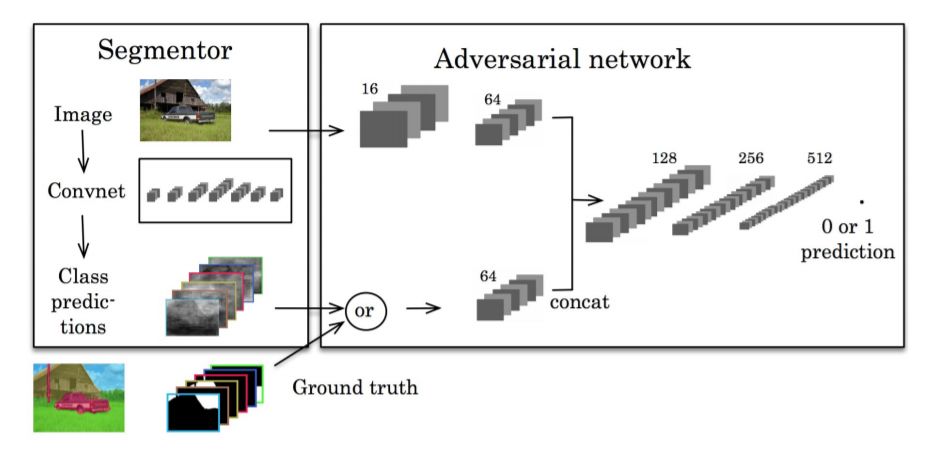
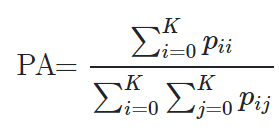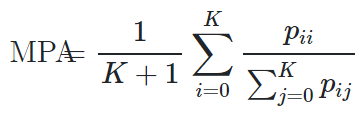图像分割(Image Segmentation)是计算机视觉的经典问题之一,受到了广泛关注,每年在各大会议上都有大量的相关文章发表。在前深度学习时代有大量的方法提出,比如分水岭、GraphCut等。随着深度学习的兴起,大量的算法提出如R-CNN、Mask-RCNN等。 最近来自纽约大学、滑铁卢大学、UCLA等学者发布了深度学习图像分割最新综述论文<Image Segmentation Using Deep Learning: A Survey>,涵盖20页pdf168篇参考文献,调研了截止2019年提出的100多种分割算法,共分为10类方法。对近几年深度学习图像分割进行了全面综述,对现有的深度学习图像分割研究进行梳理使其系统化,并提出6方面挑战,帮助读者更好地了解当前的研究现状和思路。可作为相关领域从业者的必备参考文献。 基于深度学习的二维图像分割算法的时间轴。橙色块表示语义块,绿色块表示实例块。 题目:Image Segmentation Using Deep Learning: A Survey作者:Shervin Minaee, Yuri Boykov, Fatih Porikli, Antonio Plaza, Nasser Kehtarnavaz, and Demetri Terzopoulos 参考链接:https://arxiv.org/abs/2001.05566https://www.zhuanzhi.ai/paper/7a4653117ddaec48f376ae2ed6bf3e31 摘要 图像分割是图像处理和计算机视觉领域的一个重要课题,其应用领域包括场景理解、医学图像分析、机器人感知、视频监控、增强现实和图像压缩等。研究者们提出了各种图像分割算法。最近,由于深度学习模型在广泛的视觉应用中取得了成功,已经有大量的工作致力于开发使用深度学习模型的图像分割方法。在本次综述中,我们全面回顾了撰写本文时的论文,涵盖了语义级和实例级分割的广泛先驱工作,包括全卷积像素标记网络、编码器-解码器架构、基于多尺度和金字塔的方法、递归网络、视觉注意力模型和在对抗环境下的生成模型。我们调研了这些深度学习模型的相似性、优势和挑战,研究了最广泛使用的数据集,报告了性能,并讨论了该领域未来的研究方向。 1. 引言 图像分割是许多视觉理解系统的重要组成部分。它涉及到将图像(或视频帧)分割成多个段或对象[1]。分割在[2]的广泛应用中起着核心作用,包括医学图像分析(如肿瘤边界提取和组织体积测量),自动驾驶车辆(如可导航的表面和行人检测),视频监控,增强现实等。从最早的阈值化[3]、基于直方图的分组、区域生长[4]、k-means聚类[5]、分水岭[6]等算法,到更先进的主动轮廓[7]、图割[8]、条件和马尔科夫随机域[9]、稀疏[10]-[11]等算法,文献中已经出现了许多图像分割算法。然而,在过去的几年里,深度学习(DL)网络已经产生了新一代的图像分割模型,其性能有了显著的提高——通常在流行的基准测试中获得了最高的准确率——致使许多人认为的该领域的范式转变。例如,图1展示了一个著名的深度学习模型DeepLabv3[12]的样本图像分割输出。 图1: DeepLabV3[12]对样本图像的分割结果。 图像分割可以表示为带有语义标签的像素分类问题(语义分割)或单个对象的分割问题(实例分割)。语义分割是对所有图像像素进行一组对象类别(如人、车、树、天空)的像素级标记,因此通常比图像分类更难,因为后者预测整个图像的单个标签。实例分割进一步扩展了语义分割的范围,通过检测和描绘图像中每个感兴趣的对象(例如,对个人的分割)。 我们的调研涵盖了图像分割的最新文献,并讨论了到2019年提出的一百多种基于深度学习的分割方法。我们对这些方法的不同方面提供了全面的回顾和见解,包括培训数据、网络架构的选择、损失功能、培训策略以及它们的关键贡献。我们对所述方法的性能进行了比较总结,并讨论了基于深度学习的图像分割模型的几个挑战和未来可能的方向。 我们将基于深度学习的工作根据其主要技术贡献分为以下几类:
表一: PASCAL VOC测试集上分割模型的准确性 6 挑战与机遇 毫无疑问,图像分割已经从深度学习中受益良多,但仍存在一些挑战。接下来,我们将介绍一些有前景的研究方向,我们相信这将有助于进一步推进图像分割算法。 6.1 更具挑战性的数据集 为了实现图像的语义分割和实例分割,建立了多个大规模的图像数据集。然而,仍然需要更有挑战性的数据集,以及不同类型的图像数据集。对于静态图像,具有大量对象和重叠对象的数据集非常有价值。这可以使训练模型更好地处理密集的对象场景,以及在真实场景中常见的对象之间的大量重叠。 随着三维图像分割尤其是医学图像分析的日益普及,对大规模三维图像数据集的需求也越来越大。这些数据集比它们的低维度副本更难创建。现有的用于三维图像分割的数据集通常不够大,有些是合成的,因此更大、更具挑战性的三维图像数据集可能非常有价值。 6.2 可解释的深度模型 虽然基于dll的模型在具有挑战性的基准测试上取得了良好的性能,但是这些模型仍然存在一些问题。例如,深度模型究竟在学习什么?我们应该如何解释这些模型学到的特征?什么是最小的神经结构,可以达到一定的分割精度,在一个给定的数据集?虽然可以使用一些技术来可视化这些模型的学习卷积内核,但是缺乏对这些模型的底层行为/动态的具体研究。更好地理解这些模型的理论方面可以使模型朝着各种细分场景发展。 6.3 弱监督和非监督学习 弱监督学习和无监督学习正成为非常活跃的研究领域。这些技术有望成为图像分割的特别有价值的,因为收集标记样本分割问题在许多应用领域是有问题的,特别是在医学图像分析。转移学习方法是在一组大的标记样本(可能来自公共基准)上训练一个通用的图像分割模型,然后在一些特定目标应用程序的几个样本上微调该模型。自监督学习是另一个很有前途的方向,它在各个领域都很有吸引力。在自我监督学习的帮助下,图像中有许多细节可以用来训练分割模型,而训练样本要少得多。基于增强学习的模型也可能是另一个潜在的未来方向,因为它们在图像分割方面还没有得到足够的重视。例如,MOREL[168]提出了一种用于视频中移动目标分割的深度强化学习方法。 6.4 各种应用的实时模型 在许多应用中,准确性是最重要的因素; 然而,在一些应用中,分割模型也很重要,它可以运行在接近实时,或至少接近普通的相机帧率(至少每秒25帧)。这对于部署在自动驾驶汽车上的计算机视觉系统很有用。目前的大多数模型都远远达不到这一帧率;例如,FCN-8处理低分辨率图像大约需要100毫秒。基于扩展卷积的模型在一定程度上提高了分割模型的速度,但仍有很大的改进空间。 6.5 记忆效能模型 许多现代的分割模型甚至在推理阶段都需要大量的内存。到目前为止,许多努力都是为了提高这些模型的准确性,但是为了使它们适用于特定的设备,例如移动电话,网络必须简化。这可以通过使用更简单的模型来实现,也可以通过使用模型压缩技术来实现,甚至可以训练一个复杂的模型,然后使用知识蒸馏技术将其压缩成一个更小的、内存效率更高的网络来模拟复杂的模型。 6.6 三维点云分割 大量的工作集中在二维图像分割,但很少有涉及到三维点云分割。点云分割在三维建模、自动驾驶汽车、机器人、建筑建模等领域有着广泛的应用。处理三维无序和非结构化数据(如点云)带来了几个挑战。例如,在点云上应用CNNs和其他经典深度学习架构的最佳方式还不清楚。基于图的深度模型可能是点云分割的一个潜在探索领域,从而支持这些数据的附加工业应用。 7 结论 我们调查了最近100多种基于深度学习模型的图像分割算法,这些算法在各种图像分割任务和基准测试中都取得了令人印象深刻的成绩。我们将这些算法分为10类:CNN和FCN、RNN、R-CNN、dilated CNN、基于注意力的模型、生成型模型和对抗型模型等。我们总结了这些模型在一些流行基准上的定量性能分析,如PASCAL VOC、MS COCO、Cityscapes和ADE20k数据集。最后,我们讨论了一些开放的挑战和未来几年图像分割的潜在研究方向。 参考文献: [1] R. Szeliski, Computer vision: algorithms and applications. Springer Science & Business Media, 2010.[2] D. Forsyth and J. Ponce, Computer vision: a modern approach. Prentice Hall Professional Technical Reference, 2002.[3] N. Otsu, “A threshold selection method from gray-level histograms,” IEEE transactions on systems, man, and cybernetics, vol. 9, no. 1, pp. 62–66, 1979.[4] R. Nock and F. Nielsen, “Statistical region merging,” IEEE Transactions on pattern analysis and machine intelligence, vol. 26, no. 11, pp. 1452–1458, 2004.[5] N. Dhanachandra, K. Manglem, and Y. J. Chanu, “Image segmentation using k-means clustering algorithm and subtractive clustering algorithm,” Procedia Computer Science, vol. 54, pp. 764–771, 2015.[6] L. Najman and M. Schmitt, “Watershed of a continuous function,” Signal Processing, vol. 38, no. 1, pp. 99–112, 1994.