撕掉“Hadoop”标签,Cloudera 未来还可期吗?

2000 年初,Google 的三篇论文奠定了最近二十年大数据的技术发展基调,也催生了 Hadoop 生态的发展和繁荣。借助 Hadoop 的东风,一批大数据企业成长了起来,Cloudera 便是代表之一。不过,Hadoop 势弱、Spark 和云计算快速崛起后,Cloudera 等大数据企业面临着或淘汰或转型的命运。
2009 年到 2013 年是 Hadoop 的繁盛时期,也是 Cloudera 快速发展的时期。
Cloudera 成立于 2008 年,次年便推出了首个 Hadoop 发行版 CDH。2014 年,Cloudera 完成了一轮 9 亿美元的融资,此轮融资包括英特尔投资的 7.4 亿美元和 T. Powe Price 领投、Google Ventures 等跟投的 1.6 亿美元。Cloudera 在此轮融资中的估值约 41 亿美元,牢牢坐稳了 Hadoop 发行商的头把交椅。Cloudera 共计为 Hadoop 贡献了五六十个组件。
成本节约和分析性能是 Hadoop 在 2010 年代最吸引人的两个点。但随着企业需求的变化,这两个优势转变成制约企业发展的因素。本地硬件扩容虽然可以满足高峰期的使用需求,但大多数时间这些资源都会被闲置。本地 Hadoop 环境中无法将存储和计算分离,因此成本也会随着数据集的增加而增加。此时,云成了企业们的首选。
2016 年,Cloudera 试图转型成云计算大数据服务提供商,但由于资金等问题未能实现。不过,Cloudera 次年还是在纳斯达克上市了。招股书显示,在截至 2017 年 1 月 31 日的财年内,Cloudera 营收为 2.61 亿美元,亏损 1.87 亿美元。
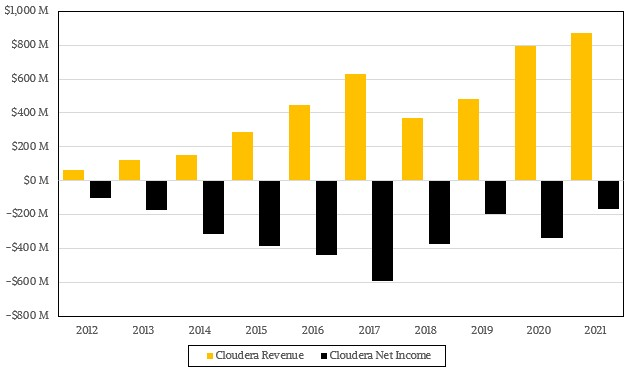
随着 Hadoop 风光不再,Hadoop 提供商们也各寻出路。2018 年,Cloudera 与 Hortonworks 合并;2019 年,MapR 被 HPE 收购;2021 年 6 月 Cloudera 退市,完成私有化。今年 4 月,Apache 软件基金会宣布从 Hadoop 生态系统中淘汰掉 10 个项目。
不过,这些能够说明 Hadoop 已死吗?在 Cloudera 大中华区技术总监刘隶放看来,判断一个产品“生死”的标准是其是否还在解决用户的真实需求。
Cloudera 和 Hortonworks 创始人们当初投身 Hadoop 的重要原因是,他们在原公司使用 Hadoop 平台做数仓改造后,发现成本得到大规模降低。而在刘隶放看来,Hadoop 为数仓建设带来的这一优势,短时间内并不会改变。
企业需要处理的数据量越来越大。数据数仓管理有“3+1”、“6+1”的说法,即数仓管理着一个月的流动数据加上三个月或六个月的存储数据,时间一过,数据便将以离线存储形式转出。现在,转出数据改为近线存储,数据转出后形成历史数据再对外服务,这个基础之上又形成了数据集市。现在为了获得更高的有效数据使用能力,企业们将目光投向了数据湖。
如此大量的数据处理,首先需要足够的存储空间,其次要有足够的算力。在使用 Hadoop 对数仓进行优化后,企业可以直接将数据存储在 HDFS 上,之后再进行 ETL 处理。
数仓不仅贵,对精简性要求也高,数据太多可能导致性能不够。出于成本考虑,很多企业选择了数仓一体机。刘隶放表示,虽然企业不会快速将这些机器下线,但对 Hadoop 的接受程度越来越高。原因是这些海量数据中,有一部分并不需要进入数仓进行处理,大数据平台也可以做出很多数仓的固定报表。当这部分数据越来越多时,企业首先想到的会是大数据平台,而非数仓。
无论是对数仓的优化还是替换上,Hadoop 都可以做很多事情。
另外,在历史数据查询方面,国内银行、电信、监管等领域的企业仍在用 Hadoop 做数仓前端的加工和处理。没有 Hadoop 之前,数据存储在属于内容管理的库,通过分级存储然后添加索引的方式实现。内容存储也存在成本高,性能会随着数据量增加而大幅下降的问题。Hadoop 生态中的 HBase,天然适合做这种超大规模数据的检查,越来越多企业选择用 HBase 管理库。
大数据讲究数量、多样性和速度,即可以快速处理大量各种类型的数据。Hadoop 靠“量”起家,这点在很多企业系统里仍发挥着很重要的作用。
此外,Hadoop 也在不断演化。Hadoop 3.0 版本拥抱 Kubernetes 做容器化编排,加入了 Airflow、Flink 等新组件,部分缺乏“生命力”的组件也会被淘汰掉。
在刘隶放看来,Hadoop 在变得更好、更全面。只要数据还在增长,Hadoop 体系就无可替代。在当前的大数据平台里,只有 Hadoop 生态圈可以把控这样的大数据计算能力。
然而不得不承认,没有弹性资源供给、扩展成本快速增加等问题已经成为企业发展的主要矛盾,但 Hadoop 无法完全解决。
Hadoop 已经过了技术生命周期的高峰时段,进入低谷期。幸存的 Cloudera 只有改进产品满足早期用户需求才能继续。换句话说,Hadoop 即使不死,也不会再是 Cloudera 的主打产品。
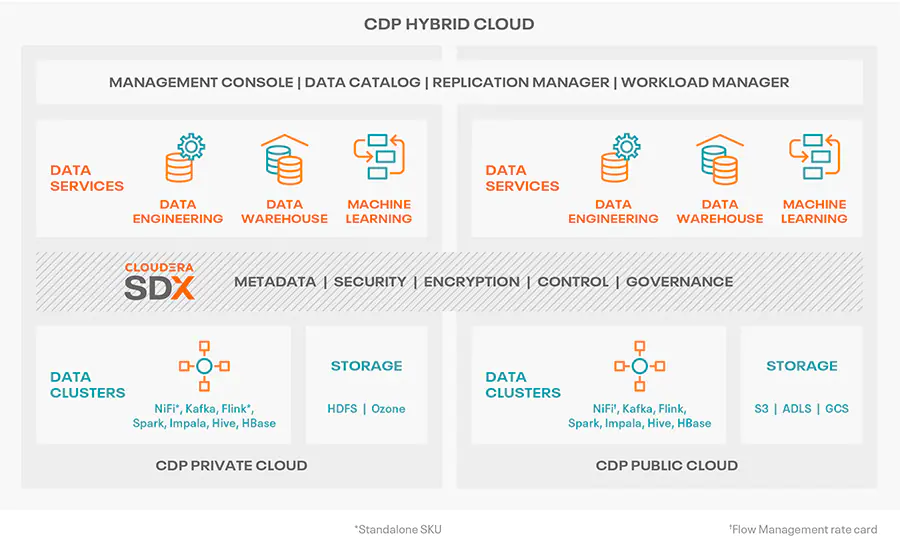
2019 年,Cloudera 与 Hortonworks 合并后,彻底完成了转型。Cloudera 果断宣布,对 CDH 和 HDP 两条产品线将仅支持到 2022 年。对于两个产品高度重合的部分会做删减和融合,结果就是推出新的数据平台 CDP (Cloudera Data Platform)。2022 年后,原 CDH 和 HDP 用户会被转移到 CDP 上。
2019 年,Cloudera 推出了 CDP 公有云平台,2020 年又推出了 CDP 私有云平台。Cloudera 希望通过统一的平台界面,对数据进行整个生命周期管理,并提供一致的安全和治理服务。
CDP 是 CDH 和 HDP 的大融合。数仓工具 Hive 和查询系统 Impala 会被保留下来,而两家都有的工具,如 HDP 的管理工具 Ambari 和 CDH 的 Cloudera Manager 则只保留一个,标准就是看生态是否鲜活。
现在,Cloudera 做选择时会倾向更加开放的生态。“今年我们淡出了很多项目,包括之前两家公司主导的项目,首先是因为项目本身发展不够快,新发展起来的项目可以替代它们。”刘隶放说道,“其次,有些相似产品虽然只保留一个名字,但两个产品背后的研发小组是融合的,各自产品的优势也被保留了下来。”此外,也有新的组件融合进 CDP ,比如 Flink、Airflow 等。
目前,CDP 总共引入了三十多个开源组件,这些组件构成了 CDP 的五大模块:
数据仓库(CDW,Cloudera Data Warehouse)。计算引擎包括 Hive、Impala 等。
机器学习(CML - Cloudera Machine Learning)。Spark 也是机器学习的利器。CDP 集成了 Spark 3.0 的 RAPIDS 加速器,加速数据管道并大幅提升数据和机器学习工作流。
数据工程(CDE,Cloudera Data Engineering)。主要包括 Spark 等在数据工程方面能力很强的组件。其中 Spark 是 Cloudera 的重点项目,但在方向上会做一些调整。
数据流式处理(CDF,Cloudera Data Flow)。主要包括 Kafka 来保证数据加工传输,Flink 做流式数据计算,Nifi 在边缘(Edge)节点上做加工处理。
操作型数据库(COD,Cloudera Operational Database)。主要是 HBase 负责历史数据海量存储和查询。目前 HBase 版本已更新至 2.2,支持 Phoenix 二级索引等功能。
此外,在存储上,CDP 公有云上支持 对象存储 S3 和 ADSL;私有云上支持传统的 Kudu、HDFS、HBase 和对象存储 Ozone。
安全问题并不是一家企业刚开始发展时的首要考虑因素,但却是企业规模越来越大后不得不面对的问题。最初纯封闭式管理就可以满足需要,但随着业务量的增加,数据对外服务需求也越来越多。此时,企业如果没有很好的数据安全方案就无法放心对外。
如果只追求单节点性能,机器几乎就会处于裸奔状态。产品的安全性如果较差,企业无法直接在自己的大数据平台上进行数据处理,只能让提供商单独处理,这样会造成整个数据使用的割裂。因此,企业最开始选择的平台是非常重要的。
在刘隶放看来,数据全生命周期管理首先要保证的就是数据安全,具体包括对数据的传输和存储加密、加工处理和调研服务过程中严格约束文件系统访问权限、确保整个行为可追溯等。
企业经营中,如果财务、业务等各部门能看到所有数据,那对开发者来说并不友好。有的企业为了避免测试人员看到敏感信息,可能就会放弃测试。为避免泄露,数据利用方面也会大打折扣。因此,更细粒度的权限认证是必要的。
针对安全问题,Cloudera 提出了 SDX(Shared Data Experience)框架。SDX 独立于计算和存储层,可以对元数据的全生命周期进行统一治理。SDX 目前采用了 Atlas 来解决之前遇到的性能瓶颈,企业不用在乎节点数量,只需要跟着机器做水平扩展就可以。SDX 被用在 CDP 中,成为整个跨私有云、跨公有云以及跨混合云平台的基础。
由于 CDP 还引用了第三方库,如果不能及时更新维护也可能导致安全问题。Cloudera 通过版本更新、第三方服务等方式,主动维护产品安全和帮助用户解决问题。刘隶放提到,有些竞品品拿了 Cloudera 发布的老版本做二次开发,设置上自己的壁垒后就对外服务,但竞品的提供商可能不清楚哪些地方如何引用了第三方库,也就没办法做针对性的修复,这也是潜在的安全问题。
据刘隶放透露,Cloudera 主张的大数据全生命周期安全治理方案,即从生产端捕获数据后进行数据加工、转换和分析,最终成为可对外服务的数据,已经吸引了金融等对数据管控要求较高的企业。
目前,有的企业已经将业务全部迁移到 CDP 上,有的企业则根据自身某方面的需求使用 CDP 私有云等平台。今年,CDP 也入驻了阿里云,逐步在国内建立自己的公有云服务体系。
“云原生是一个不能回避的话题,我们要去拥抱云原生,把云原生支持做好。”刘隶放表示。
企业对公有云和私有云有不同的需求。公有云适合爆发性增长业务,私有云更适合规模比较固定的业务。因此,混合云是一个必然趋势。不过,各大厂商早已纷纷推出了自己的混合云解决方案,这个市场不缺混合云产品。
在刘隶放看来,混合云服务需要完成从数据生产到分析服务的完整闭环。比如工业领域,随着机器更加数字化,前端能够捕获的数据越来越多,相关数据分析可以直接在前端进行,后端管控整个过程,并对前端做指导。
不过,目前大部分解决方案有个问题:厂商是将其公有云方案中的一部分做线下的部署和输出,即线上和线下的技术路线完全相同。这导致的结果就是企业很容易被锁定在一家供应商中,从而议价权越来越低。
为了避免被锁定,国内外很多企业即使上了公有云,但依然会用标准的 IaaS,尤其是在大数据领域,因为只选择裸机和 VM 服务可以在未来跨平台迁移时变得容易。
针对这种情况,Cloudera 提出了跨云服务。企业可以在任何私有云或 AWS、Azure 和 Google Cloud 等公共云以及任何格式的数据上进行各种分析。跨云平台之间的迁移主要是应用迁移和数据迁移。不同云平台的界面和操作相同,应用迁移很简单。针对比较复杂的数据迁移,Cloudera 研发了迁移工具,企业也只需要在 BDR 中进行配置就可以完成。
刘隶放表示,PaaS、SaaS 平台将是 Cloudera 未来的重点之一。今年 6 月,Cloudera 宣布收购了两家公司:Datacoral 和 Cazena。Datacoral 完全托管服务通过多租户 SaaS 架构可以快速完成数据转换和集成,Cazena 的 Instant Cloud Data Lake 将分析时间和 AI/ML 从几个月缩短到了几分钟。
具有趋势性的技术背后,都映射着企业不断发展过程中需要解决的一些具体问题。比如,计算资源和存储资源并不需要 1 : 1 匹配,其中一方过多就会资源浪费,因此出现了存储计算分离。之前物理紧耦合的系统,一个组件升级其他组件也必须跟着一起升级,但不同组件可能来自不同的厂商,未升级的厂商只能单开一个集群运行,长期下来就会造成集群数据重复和存储冗余。因此私有云、公有云做了存储计算分离之后,企业可以按需使用资源,也可以自由选择计算组件的新旧版本。
刘隶放表示,“Cloudera 一定会跟进趋势技术,如果不推陈出新就一定会被市场淘汰。”
“Cloudera 现在就是抓紧时间把产品做得更好。”刘隶放说道。
产品迭代快是这个时代赋予的机会,也是挑战。在刘隶放看来,任何产品都有时代的局限性,企业使用产品时指出来的问题也有时效性,因此产品也随之不断地在迭代、演进。站在现在的时间点上去批判多年前的产品是不合适的。
今年 6 月, Cloudera 被 CD&R 和 KKR 以 53 亿美元的金额收购。现在的 Cloudera 不缺资金和业务经验,但缺少能够成为爆款的产品。对此,面对各个层面上所谓的竞品,刘隶放表示,“我们会把每个模块的性能做好,不怕大家在性能上做比较。”
嘉宾介绍:
刘隶放,Cloudera 大中华区技术总监,2016 年 1 月加入 Cloudera 公司,管理大中华区产品售前支持团队。售前工作期间,负责支持国内重要客户的交易系统搭建和电信行业经营分析系统的平台建设工作;同时肩负软件部重要合作伙伴的支持工作,包括在 SAP 客户领域中推广 IBM 信息管理软件产品。
今日好文推荐
Log4j 持续爆雷,啥时候是个头?
从混合包开发到100%纯鸿蒙应用还有多远?优酷鸿蒙版的开发实践与思考 | 卓越技术团队访谈录
数千个数据库、遍布全国的物理机,京东物流全量上云实录 | 卓越技术团队访谈录
知名开源公司上市造就亿万富翁,创始人不做CEO只想做码农

点个在看少个 bug 👇




