如何造一个“钉钉”?谈谈消息系统架构的实现

阿里妹导读:消息类场景是表格存储(Tablestore)主推的方向之一,因其数据存储结构在消息类数据存储上具有天然优势。为了方便用户基于Tablestore为消息类场景建模,Tablestore封装Timeline模型,旨在让用户更快捷的实现消息类场景需求。在推出Timeline(v1、v2两个版本)模型以来,受到了大量用户关注。但依然会有用户困惑,“框架、结构、模型等概念介绍了这么多,该如何基于Timeline模型,实现具体场景呢?”。本文详细讲解如何实现一个简易的IM系统。

梗概
功能模块
消息存储
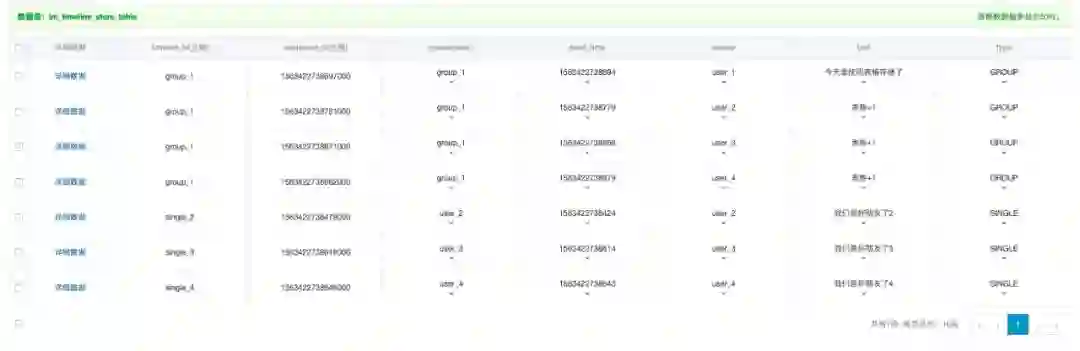
存储库
★ 功能:会话窗口消息展示
public List<AppMessage> fetchConversationMessage(String timelineId, long sequenceId) { TimelineStore store = timelineV2.getTimelineStoreTableInstance();
TimelineIdentifier identifier = new TimelineIdentifier.Builder() .addField("timeline_id", timelineId) .build();
ScanParameter parameter = new ScanParameter() .scanBackward(sequenceId) .maxCount(30);
Iterator<TimelineEntry> iterator = store.createTimelineQueue(identifier).scan(parameter);
List<AppMessage> appMessages = new LinkedList<AppMessage>(); while (iterator.hasNext() && counter++ <= 30) { TimelineEntry timelineEntry = iterator.next(); AppMessage appMessage = new AppMessage(timelineId, timelineEntry);
appMessages.add(appMessage); }
return appMessages; }
![]()
存储库的消息需要永久保存,是整个应用的全量消息存储。存储库数据过期时间(TTL)需要设为-1。
★ 功能:多维组合、全文检索
public List<AppMessage> fetchConversationMessage(String timelineId, long sequenceId) { TimelineStore store = timelineV2.getTimelineStoreTableInstance();
TimelineIdentifier identifier = new TimelineIdentifier.Builder() .addField("timeline_id", timelineId) .build();
ScanParameter parameter = new ScanParameter() .scanBackward(sequenceId) .maxCount(30);
Iterator<TimelineEntry> iterator = store.createTimelineQueue(identifier).scan(parameter);
List<AppMessage> appMessages = new LinkedList<AppMessage>(); int counter = 0; while (iterator.hasNext() && counter++ <= 30) { TimelineEntry timelineEntry = iterator.next(); AppMessage appMessage = new AppMessage(timelineId, timelineEntry);
appMessages.add(appMessage); }
return appMessages;}
![]()
另外,为了做消息的权限管理,仅允许用户检索自己有权限查看的消息,可在消息体字段中扩展接收人ID数组,这样对所有群做检索时,需要增加接收人字段为自己的用户ID这一必要条件,即可实现消息内容的权限限制。样例中没有实现这一功能,用户可根据需求自己增加、修改。

同步库
★ 功能:新消息即时统计
public List<AppMessage> fetchSyncMessage(String userId, long lastSequenceId) { TimelineStore sync = timelineV2.getTimelineSyncTableInstance();
TimelineIdentifier identifier = new TimelineIdentifier.Builder() .addField("timeline_id", userId) .build();
ScanParameter parameter = new ScanParameter() .scanForward(lastSequenceId) .maxCount(30);
Iterator<TimelineEntry> iterator = sync.createTimelineQueue(identifier).scan(parameter);
List<AppMessage> appMessages = new LinkedList<AppMessage>(); int counter = 0; while (iterator.hasNext() && counter++ <= 30) { AppMessage appMessage = new AppMessage(userId, iterator.next()); appMessages.add(appMessage); }
return appMessages;}

★ 功能:异步写扩散
元数据管理
★ 用户元数据

★ 功能:用户检索
-
通过用户ID:主键查询; -
二维码(含用户ID信息):主键查询; -
用户姓名:多元索引,用户名字段设置分词字符串; -
用户标签:多元索引,数组字符串索引提供签检索、嵌套索引提供多标签打分检索排序; -
附近的人:多元索引,GEO索引查询附近、特定地理围栏的人;
★ 会话元数据
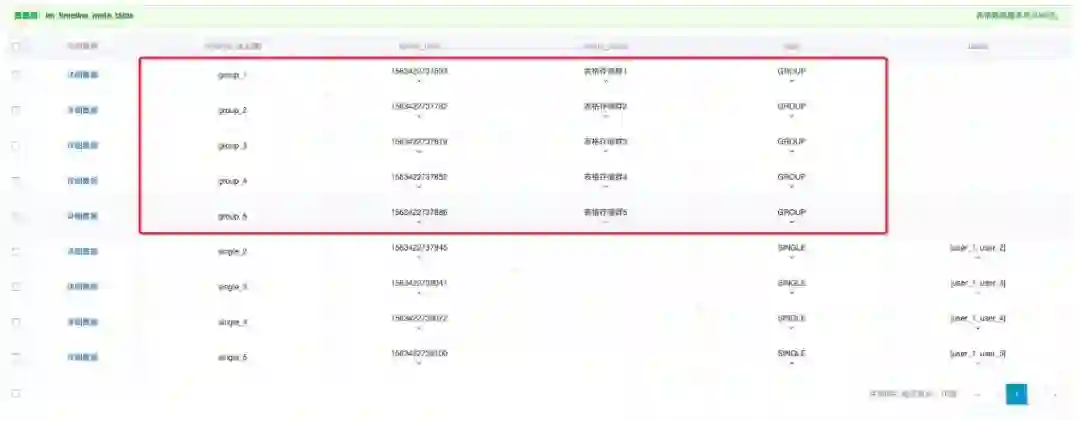
★ 功能:群检索
-
群ID:主键查询; -
二维码(含用户ID信息):主键查询; -
群名:多元索引,用户名字段设置分词字符串; -
群标签:多元索引,数组字符串索引提供签检索、嵌套索引提供多标签打分检索排序;
关系维护
单聊关系
★ 功能:人与单聊会话的关系
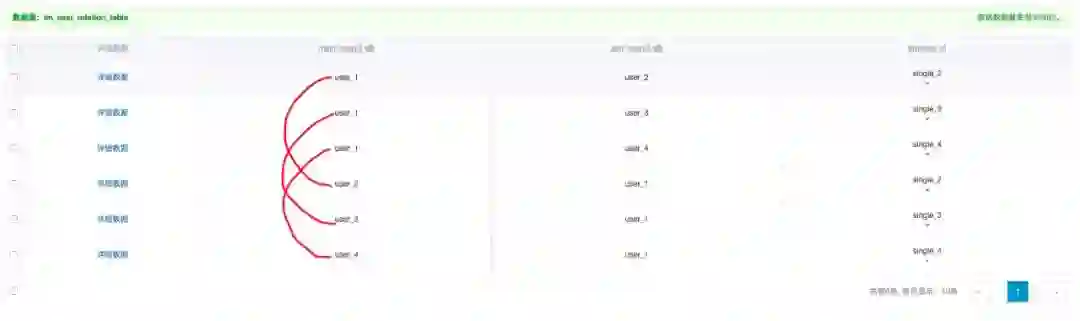
★ 功能:人与人的关系
public void establishFriendship(String userA, String userB, String timelineId) { PrimaryKey primaryKeyA = PrimaryKeyBuilder.createPrimaryKeyBuilder() .addPrimaryKeyColumn("main_user", PrimaryKeyValue.fromString(userA)) .addPrimaryKeyColumn("sub_user", PrimaryKeyValue.fromString(userB)) .build();
RowPutChange rowPutChangeA = new RowPutChange(userRelationTable, primaryKeyA); rowPutChangeA.addColumn("timeline_id", ColumnValue.fromString(timelineId));
PrimaryKey primaryKeyB = PrimaryKeyBuilder.createPrimaryKeyBuilder() .addPrimaryKeyColumn("main_user", PrimaryKeyValue.fromString(userB)) .addPrimaryKeyColumn("sub_user", PrimaryKeyValue.fromString(userA)) .build();
RowPutChange rowPutChangeB = new RowPutChange(userRelationTable, primaryKeyB); rowPutChangeB.addColumn("timeline_id", ColumnValue.fromString(timelineId));
BatchWriteRowRequest request = new BatchWriteRowRequest(); request.addRowChange(rowPutChangeA); request.addRowChange(rowPutChangeB);
syncClient.batchWriteRow(request);}
public void breakupFriendship(String userA, String userB) { PrimaryKey primaryKeyA = PrimaryKeyBuilder.createPrimaryKeyBuilder() .addPrimaryKeyColumn("main_user", PrimaryKeyValue.fromString(userA)) .addPrimaryKeyColumn("sub_user", PrimaryKeyValue.fromString(userB)) .build();
RowDeleteChange rowPutChangeA = new RowDeleteChange(userRelationTable, primaryKeyA);
PrimaryKey primaryKeyB = PrimaryKeyBuilder.createPrimaryKeyBuilder() .addPrimaryKeyColumn("main_user", PrimaryKeyValue.fromString(userB)) .addPrimaryKeyColumn("sub_user", PrimaryKeyValue.fromString(userA)) .build();
RowDeleteChange rowPutChangeB = new RowDeleteChange(userRelationTable, primaryKeyB);
BatchWriteRowRequest request = new BatchWriteRowRequest(); request.addRowChange(rowPutChangeA); request.addRowChange(rowPutChangeB);
syncClient.batchWriteRow(request);}
![]()
群聊关系

★ 功能:群聊会话与人的关系
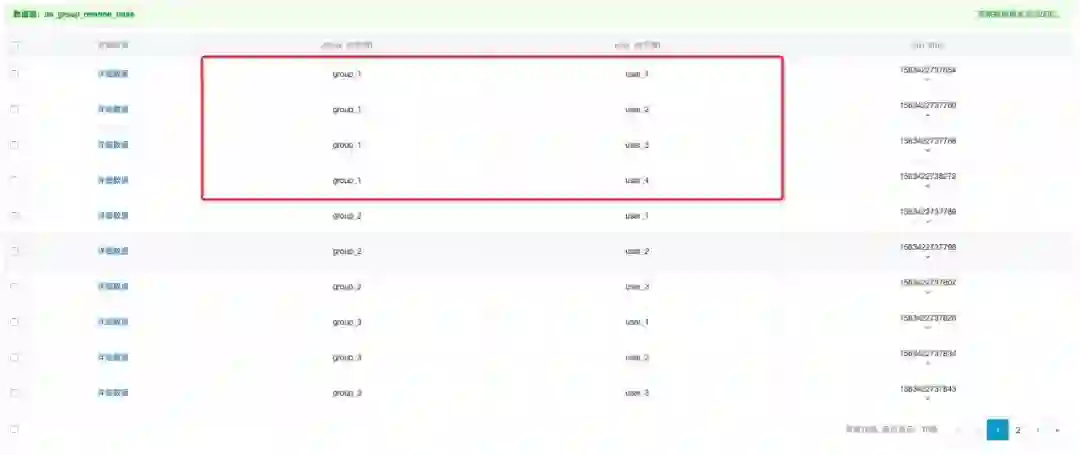
public List<Conversation> listMySingleConversations(String userId) { PrimaryKey start = PrimaryKeyBuilder.createPrimaryKeyBuilder() .addPrimaryKeyColumn("main_user", PrimaryKeyValue.fromString(userId)) .addPrimaryKeyColumn("sub_user", PrimaryKeyValue.INF_MIN) .build();
PrimaryKey end = PrimaryKeyBuilder.createPrimaryKeyBuilder() .addPrimaryKeyColumn("main_user", PrimaryKeyValue.fromString(userId)) .addPrimaryKeyColumn("sub_user", PrimaryKeyValue.INF_MAX) .build();
RangeRowQueryCriteria criteria = new RangeRowQueryCriteria(userRelationTable); criteria.setInclusiveStartPrimaryKey(start); criteria.setExclusiveEndPrimaryKey(end); criteria.setMaxVersions(1); criteria.setLimit(100); criteria.setDirection(Direction.FORWARD); criteria.addColumnsToGet(new String[] {"timeline_id"});
GetRangeRequest request = new GetRangeRequest(criteria); GetRangeResponse response = syncClient.getRange(request);
List<Conversation> singleConversations = new ArrayList<Conversation>(response.getRows().size());
for (Row row : response.getRows()) { String timelineId = row.getColumn("timeline_id").get(0).getValue().asString(); String subUserId = row.getPrimaryKey().getPrimaryKeyColumn("sub_user").getValue().asString(); User friend = describeUser(subUserId);
Conversation conversation = new Conversation(timelineId, friend);
singleConversations.add(conversation); }
return singleConversations;}
![]()
★ 功能:人与群聊会话的关系

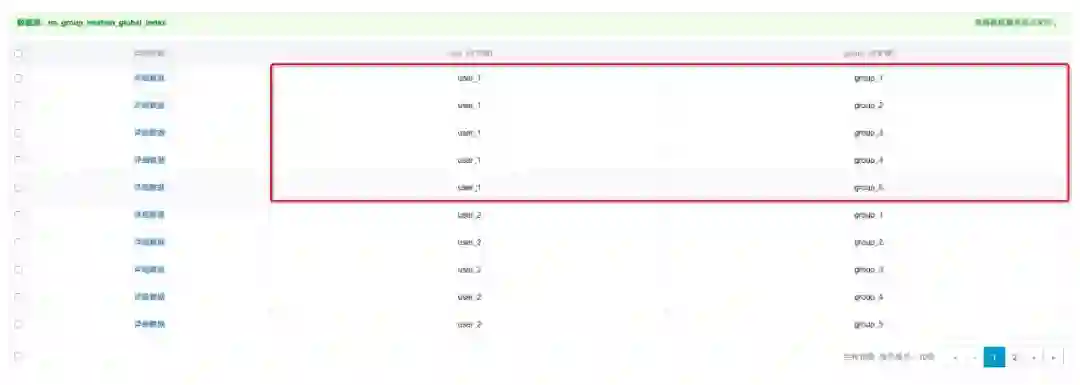
public List<Conversation> listMyGroupConversations(String userId) { PrimaryKey start = PrimaryKeyBuilder.createPrimaryKeyBuilder() .addPrimaryKeyColumn("user_id", PrimaryKeyValue.fromString(userId)) .addPrimaryKeyColumn("group_id", PrimaryKeyValue.INF_MIN) .build();
PrimaryKey end = PrimaryKeyBuilder.createPrimaryKeyBuilder() .addPrimaryKeyColumn("user_id", PrimaryKeyValue.fromString(userId)) .addPrimaryKeyColumn("group_id", PrimaryKeyValue.INF_MAX) .build();
RangeRowQueryCriteria criteria = new RangeRowQueryCriteria(groupRelationGlobalIndex); criteria.setInclusiveStartPrimaryKey(start); criteria.setExclusiveEndPrimaryKey(end); criteria.setMaxVersions(1); criteria.setLimit(100); criteria.setDirection(Direction.FORWARD); criteria.addColumnsToGet(new String[] {"group_id"});
GetRangeRequest request = new GetRangeRequest(criteria); GetRangeResponse response = syncClient.getRange(request);
List<Conversation> groupConversations = new ArrayList<Conversation>(response.getRows().size());
for (Row row : response.getRows()) { String timelineId = row.getPrimaryKey().getPrimaryKeyColumn("group_id").getValue().asString(); Group group = describeGroup(timelineId);
Conversation conversation = new Conversation(timelineId, group);
groupConversations.add(conversation); }
return groupConversations;}

即时感知
会话池方案
其他
多端同步
添加好友、入群申请
样例实操
-
开通服务、创建实例 -
获取AK -
设置样例配置文件 -
实例支持二级索引(需要主动申请);
开源地址
关注“阿里技术”官方公众号,并在对话框内回复“IM”,即可获得 Github 下载链接、了解更多详情。

样例配置
# mac 或 linux系统下:/home/userhome/tablestoreCong.json# windows系统下: C:\Documents and Settings\%用户名%\tablestoreCong.json{"endpoint": "http://instanceName.cn-hangzhou.ots.aliyuncs.com","accessId": "***********","accessKey": "***********************","instanceName": "instanceName"}
accessId:AK的ID,获取AK链接提供;
accessKey:AK的密码,获取AK链接提供;
instanceName:使用的实例名;
样例入口

项目结构
阿里巴巴在 AI 路上
有哪些重大突破?
关注“阿里机器智能”,
了解 AI 大事,
扫我 ↓。


你可能还喜欢
点击下方图片即可阅读

亿级规模的 Feed 流系统,如何轻松设计?

咱们从头到尾说一次 Java 的垃圾回收

我在阿里找到了技术人的成长模式

关注「阿里技术」
把握前沿技术脉搏
登录查看更多
相关内容

IM:IFIP/IEEE International Symposium on Integrated Network Management。
Explanation:综合网络管理国际研讨会。
Publisher:IFIP/IEEE
SIT: http://dblp.uni-trier.de/db/conf/im/index.html



相关VIP内容
相关资讯
相关论文