业界 | 图鸭科技获CVPR 2018图像压缩挑战赛单项冠军,技术解读端到端图像压缩框架
机器之心报道
参与:晓坤、路
CHALLENGE ON LEARNED IMAGE COMPRESSION 挑战赛由 Google、Twitter、Amazon 等公司联合赞助,是第一个由计算机视觉领域的会议发起的图像压缩挑战赛,旨在将神经网络、深度学习等一些新的方式引入到图像压缩领域。据 CVPR 大会官方介绍,此次挑战赛分别从 PSNR 和主观评价两个方面去评估参赛团队的表现。
不久之前,CLIC 挑战赛比赛结果公布:在不同基准下,来自国内创业公司图鸭科技的团队 TucodecTNGcnn4p 在 MOS 和 MS-SSIMM 得分上获得第一名,腾讯音视频实验室和武汉大学陈震中教授联合团队 iipTiramisu 在 PSNR(Peak Signal-to-Noise Ratio,峰值信噪比)指标上占据领先优势,位列第一。xvc,评分较高的团队中,xvc 的解码速度最快。

比赛结果:http://www.compression.cc/results/
在这篇文章中,我们对第一名图鸭科技的解决方案进行了编译介绍,内容采自论文《Variational Autoencoder for Low Bit-rate Image Compression》。
论文:Variational Autoencoder for Low Bit-rate Image Compression

地址:http://openaccess.thecvf.com/CVPR2018_workshops/CVPR2018_W50.py#
摘要:我们展示了一种用于低码率图像压缩的端到端可训练图像压缩框架。我们的方法基于变分自编码器,包含一个非线性编码器变换、均匀量化器、非线性解码器变换和后处理模块。压缩表征的先验概率通过使用超先验自编码器的拉普拉斯分布来建模,并与变换自编码器进行联合训练。为了去除低码率图像的压缩失真和模糊,我们提出了一种基于卷积的高效后处理模块。最终,考虑到 CLIC 挑战赛对码率的限制,我们使用一个码率控制算法来对每一个图像自适应性地分配码率。在验证集和测试集上的实验结果证明,使用感知损失训练出的该优化框架能够实现最优的 MS-SSIM 性能。结果还表明该后处理模块可以提高基于深度学习的方法和传统方法的压缩性能,在码率为 0.15 时最高 PSNR 达到 32.09。
1. 引言
近期,机器学习方法被应用于有损图像压缩,并利用自编码器取得了很有潜力的结果。基于典型神经网络的图像压缩框架由多个模块构成,例如自编码器、量化器(quantization)、先验分布模型、码率评估和率失真优化。自编码器用于将图像像素 x 转换为编码空间 y 中的数据,编码空间由编码器 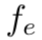
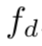
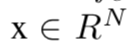
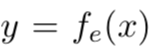
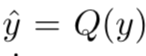
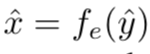
很明显,表征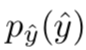
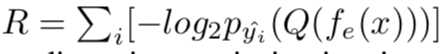
率失真优化的作用是在编码长度 R 和原始图像 x、重构图像 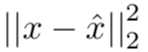
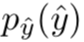
本论文提出的图像压缩框架基于之前的方法 。与这些方法不同,我们设计了一个金字塔自编码器和更高效的卷积结构,来提升压缩性能。此外,我们使用参数化零均值拉普拉斯分布对压缩表征的先验概率进行准确建模,该分布的参数通过超先验自编码器学习得到。考虑到如果该网络只通过保持低码率的像素相似度来学习,那么图像重建会遇到模糊的情况,对人眼的吸引力也会下降。因此我们使用一种基于 MS−SSIM 的高效损失函数来衡量感知损失,训练提高感知质量的压缩编码解码器。最后,我们使用基于卷积的后处理模块来提高图像重建质量。考虑到该挑战赛中对压缩测试图像和验证图像的限制是 0.15 bpp,因此我们设计码率控制算法来为每个图像选出最好的压缩参数。
2. 本论文提出的图像压缩框架
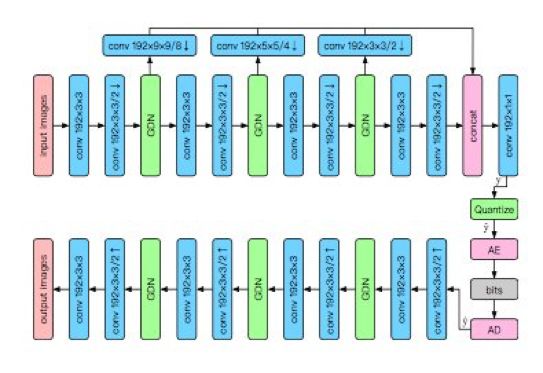
图 1:本论文使用的变分自编码器架构图示。卷积参数表示为:滤波器数量 × 卷积核高度 × 卷积核宽度/上(下)采样步幅,其中 ↓ 表示下采样,↑表示上采样。AE、AD 分别表示算术编码器和算术解码器。
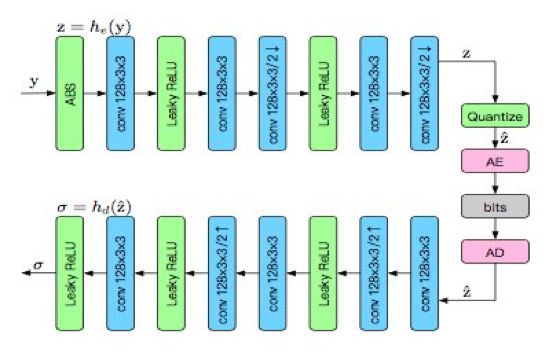
图 2:超先验自编码器的架构展示。
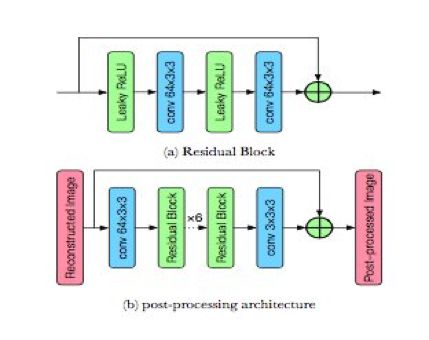
图 3:(a)残差块。(b)两个卷积层和 6 个残差块组成了后处理架构。
3. 实验结果
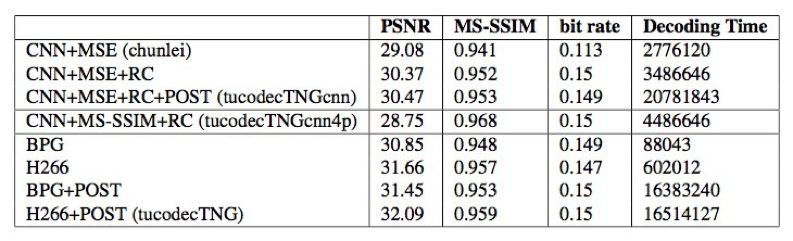
表 1:在 CLIC 2018 验证集上的评估结果。

表 2:在 CLIC 2018 测试集上的评估结果。
本文为机器之心报道,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




