手把手教你写网络爬虫(4):Scrapy入门

本系列:
《手把手教你写网络爬虫(1):网易云音乐歌单》
《手把手教你写网络爬虫(2):迷你爬虫架构》
《手把手教你写网络爬虫(3):开源爬虫框架对比》
上期我们理性的分析了为什么要学习Scrapy,理由只有一个,那就是免费,一分钱都不用花!
咦?怎么有人扔西红柿?好吧,我承认电视看多了。不过今天是没得看了,为了赶稿,又是一个不眠夜。。。言归正传,我们将在这一期介绍完Scrapy的基础知识, 如果想深入研究,大家可以参考官方文档,那可是出了名的全面,我就不占用公众号的篇幅了。

架构简介
下面是Scrapy的架构,包括组件以及在系统中发生的数据流的概览(红色箭头所示)。 之后会对每个组件做简单介绍,数据流也会做一个简要描述。
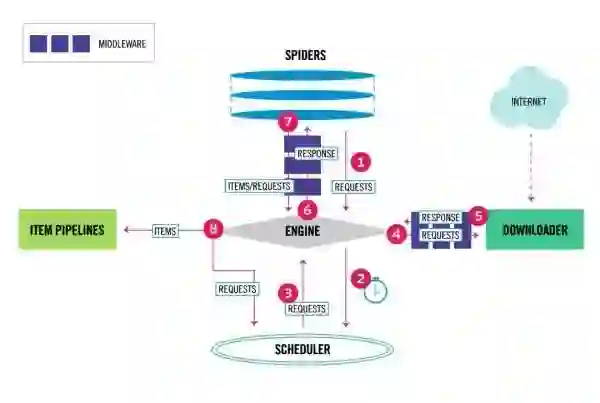

架构就是这样,流程和我第二篇里介绍的迷你架构差不多,但扩展性非常强大。
One more thing



scrapy startproject tutorial
该命令将会创建包含下列内容的 tutorial 目录:
tutorial/
scrapy.cfg # 项目的配置文件
tutorial/ # 该项目的python模块。之后您将在此加入代码
__init__.py
items.py # 项目中的item文件
pipelines.py # 项目中的pipelines文件
settings.py # 项目的设置文件
spiders/ # 放置spider代码的目录
__init__.py
编写第一个爬虫
Spider是用户编写用于从单个网站(或者一些网站)爬取数据的类。其包含了一个用于下载的初始URL,以及如何跟进网页中的链接以及如何分析页面中的内容的方法。
以下为我们的第一个Spider代码,保存在 tutorial/spiders 目录下的 quotes_spider.py文件中:
import scrapy
class QuotesSpider(scrapy.Spider):
name = “quotes”
def start_requests(self):
urls = [
‘http://quotes.toscrape.com/page/1/’,
‘http://quotes.toscrape.com/page/2/’,
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
page = response.url.split(“/”)[-2]
filename = ‘quotes-%s.html’ % page
with open(filename, ‘wb’) as f:
f.write(response.body)
self.log(‘Saved file %s’ % filename)
运行我们的爬虫
进入项目的根目录,执行下列命令启动spider:
scrapy crawl quotes
这个命令启动用于爬取 quotes.toscrape.com 的spider,你将得到类似的输出:
2017-05-10 20:36:17 [scrapy.core.engine] INFO: Spider opened
2017-05-10 20:36:17 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2017-05-10 20:36:17 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2017-05-10 20:36:17 [scrapy.core.engine] DEBUG: Crawled (404) <GET http://quotes.toscrape.com/robots.txt> (referer: None)
2017-05-10 20:36:17 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://quotes.toscrape.com/page/1/> (referer: None)
2017-05-10 20:36:17 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://quotes.toscrape.com/page/2/> (referer: None)
2017-05-10 20:36:17 [quotes] DEBUG: Saved file quotes-1.html
2017-05-10 20:36:17 [quotes] DEBUG: Saved file quotes-2.html
2017-05-10 20:36:17 [scrapy.core.engine] INFO: Closing spider (finished)
提取数据
我们之前只是保存了HTML页面,并没有提取数据。现在升级一下代码,把提取功能加进去。至于如何使用浏览器的开发者模式分析网页,之前已经介绍过了。
import scrapy
class QuotesSpider(scrapy.Spider):
name = “quotes”
start_urls = [
‘http://quotes.toscrape.com/page/1/’,
‘http://quotes.toscrape.com/page/2/’,
]
def parse(self, response):
for quote in response.css(‘div.quote’):
yield {
‘text’: quote.css(‘span.text::text’).extract_first(),
‘author’: quote.css(‘small.author::text’).extract_first(),
‘tags’: quote.css(‘div.tags a.tag::text’).extract(),
}
再次运行这个爬虫,你将在日志里看到被提取出的数据:
2017-05-10 20:38:33 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes.toscrape.com/page/1/>
{‘tags’: [‘life’, ‘love’], ‘author’: ‘André Gide’, ‘text’: ‘“It is better to be hated for what you are than to be loved for what you are not.”’}
2017-05-10 20:38:33 [scrapy.core.scraper] DEBUG: Scraped from <200 http://quotes.toscrape.com/page/1/>
{‘tags’: [‘edison’, ‘failure’, ‘inspirational’, ‘paraphrased’], ‘author’: ‘Thomas A. Edison’, ‘text’: ““I have not failed. I’ve just found 10,000 ways that won’t work.””}
保存爬取的数据
最简单存储爬取的数据的方式是使用 Feed exports:
scrapy crawl quotes -o quotes.json
该命令将采用 JSON 格式对爬取的数据进行序列化,生成quotes.json文件。
在类似本篇教程里这样小规模的项目中,这种存储方式已经足够。如果需要对爬取到的item做更多更为复杂的操作,你可以编写 Item Pipeline,tutorial/pipelines.py在最开始的时候已经自动创建了。

媒体合作请联系:
邮箱:xiangxiaoqing@stormorai.com





