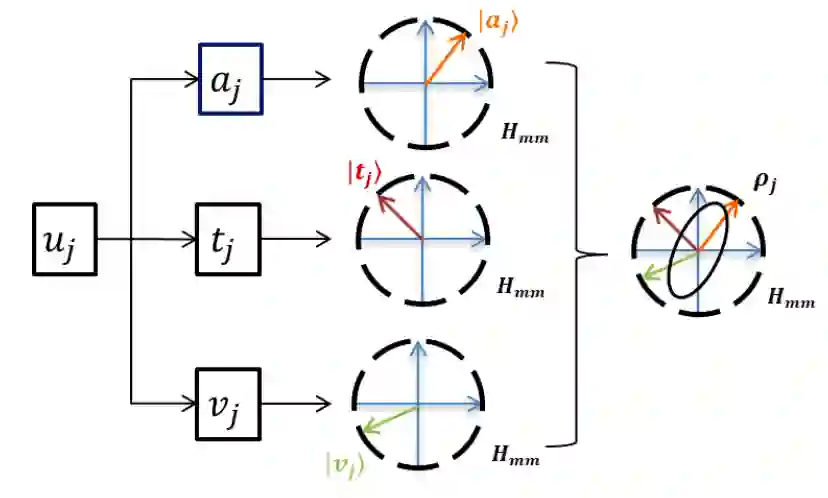
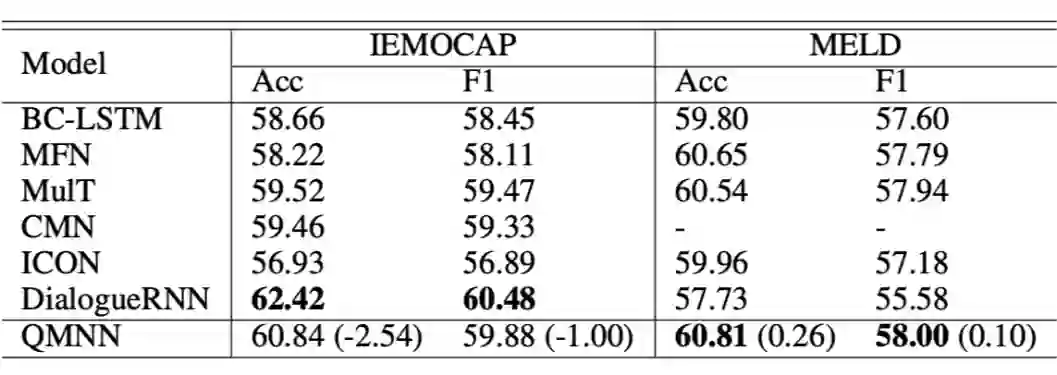
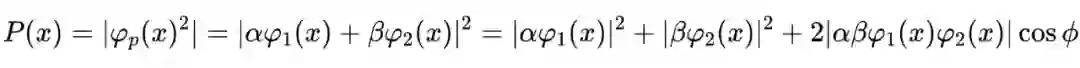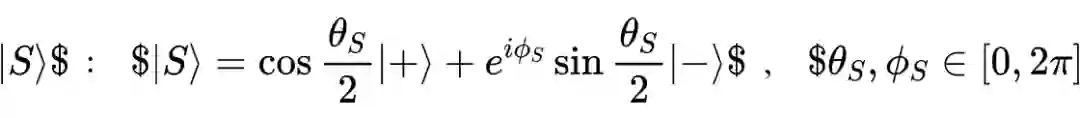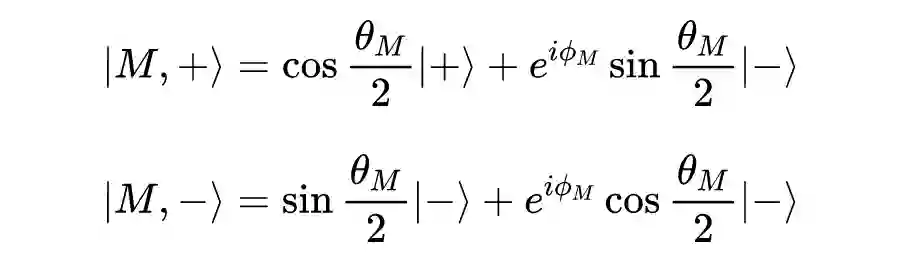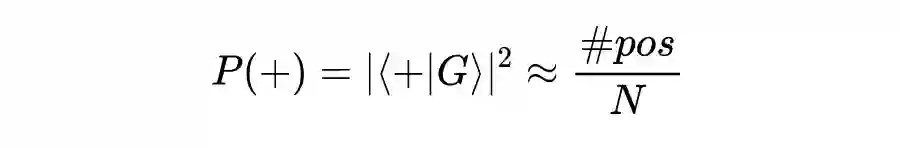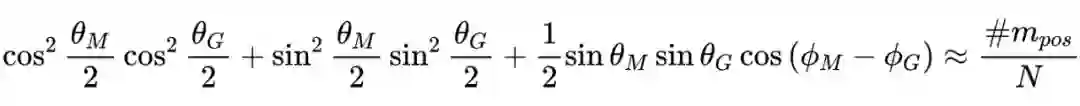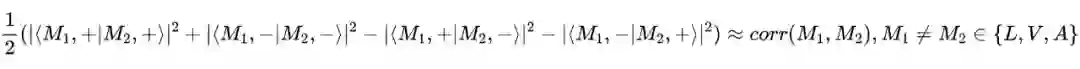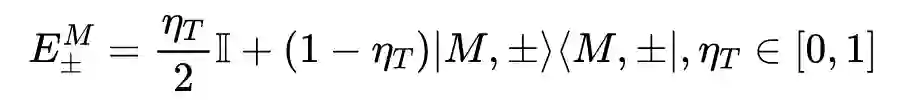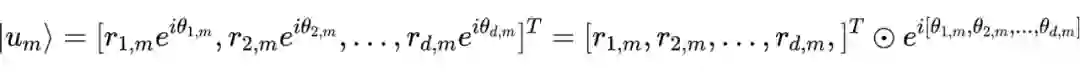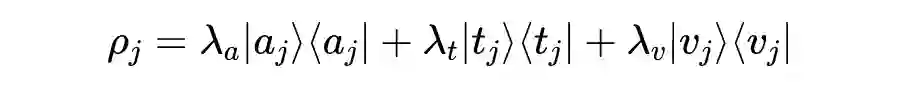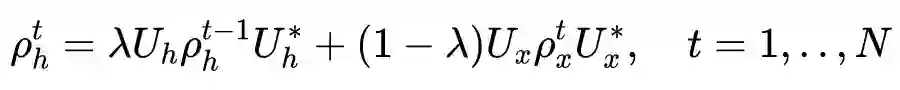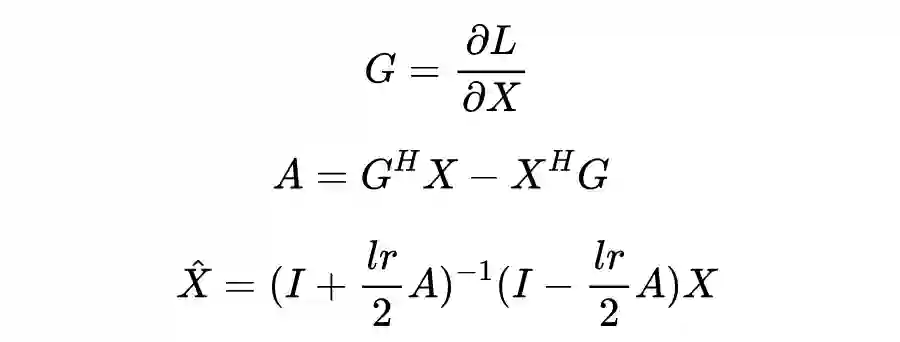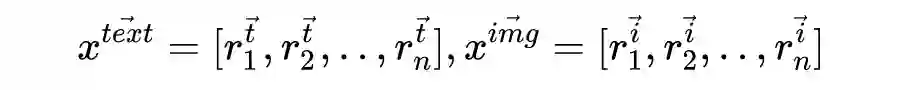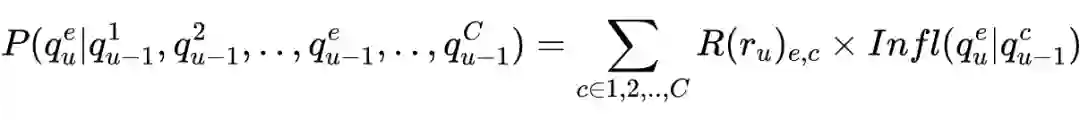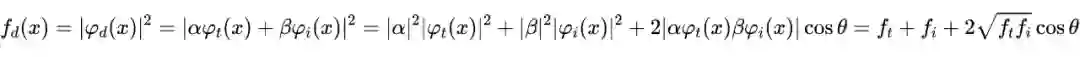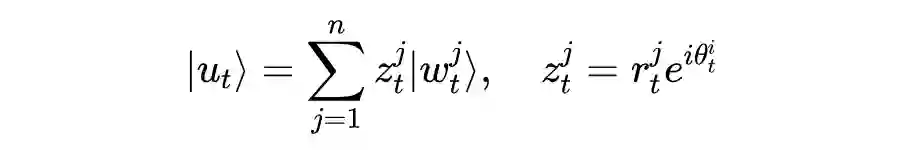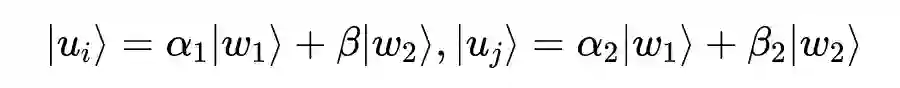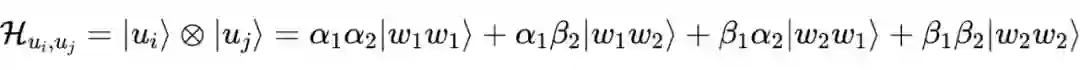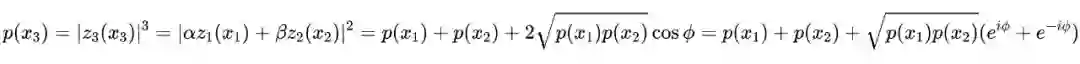©作者 | 刘耀琛、李秋池、张亚洲、宋大为
单位 | 北京理工大学、帕多瓦大学、郑州轻工业大学
研究方向 | 多模态建模
简介
多模态情感分类任务是当下深度学习领域最热门的话题之一,它涉及到跨领域的知识使用,有效解决该任务的核心是如何将多模态的信息输入有效地融合。当在多模态情感分析任务中加入对话上文信息后,任务的难度更高,除了要建模多模态信息的交互,还需要建模对话上下文的交互。
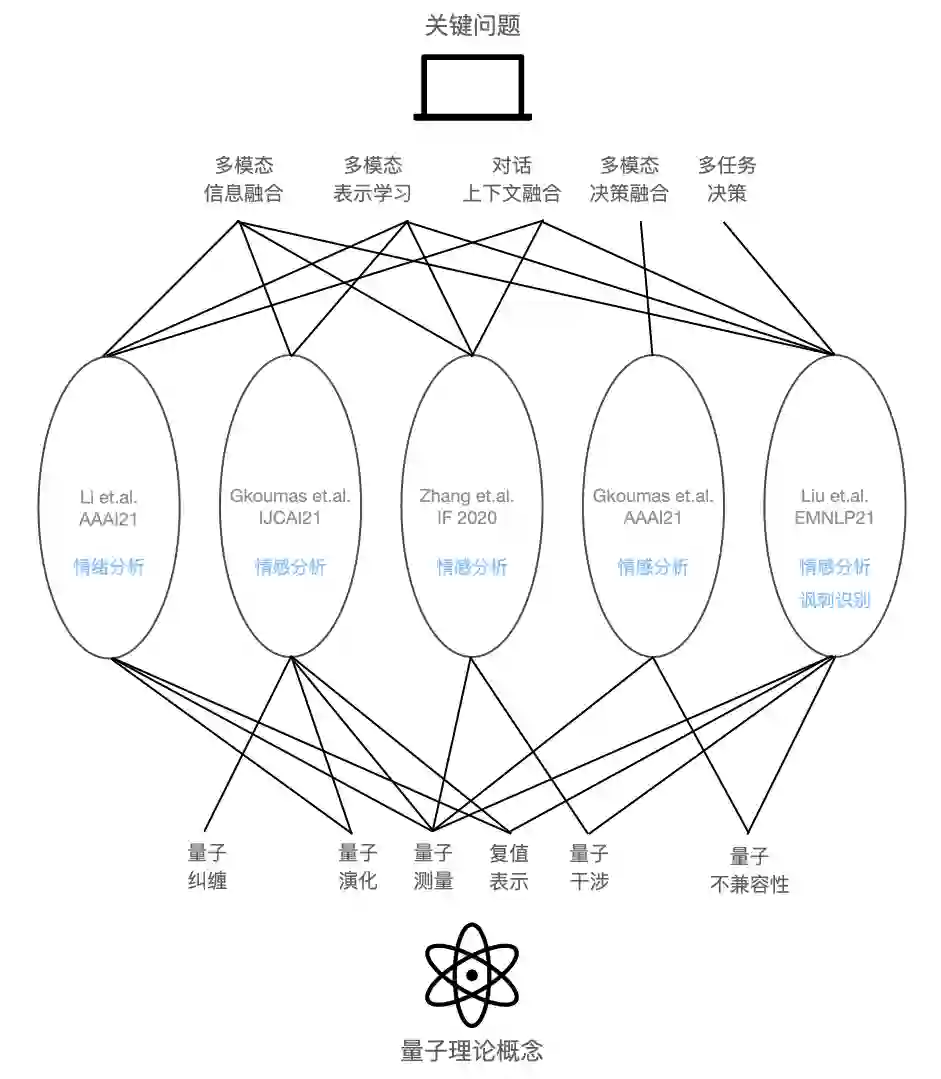
已有的工作很少同时聚焦于建模这两种交互动态。并且,已有的基于神经组件的模型是类似黑盒的,可解释性较弱。除了以上两个核心的问题之外,多模态(对话)情感分析任务的关键问题还包括如何进行多模态表示学习,多种模态的决策怎样融合,在多任务框架下如何解决多任务决策等。
无论是多模态信息处理的问题,还是情感分析任务,它们归根结底都是人类认知的问题。从人类认知的角度出发建模模态间和上下文动态交互,基于经典概率理论的方法往往无法有效捕获这些动态交互,然而量子理论已被证明可以解决经典概率论在人类认知建模中的悖论,而且基于量子理论的模型在获得与 SOTA 相媲美的效果的同时具有更好的可解释性。
复值表示作为量子理论的基本内容,可以很自然地作为带有先验知识的多模态信息的基础;通过使用量子纠缠和量子干涉的概念,多模态信息可以以非线性的方式进行有效融合;量子演化和量子复合系统的概念可以用来建模对话上下文的交互;量子测量可以为融合后的量子系统做出情感决策。
基于这些概念,近期,来自北京理工大学、英国开放大学、意大利帕多瓦大学和郑州轻工业大学的研究人员在会议 AAAI、IJCAI、EMNLP 和期刊 Information Fusion 上发表了五篇量子启发的多模态(对话)情感(情绪)分类模型。每篇文章的问题设定有所不同,从多模态情感分析,到多模态对话情感分析,再到多模态多任务对话情感分析。
文章列表:
Gkoumas D, Li Q, Dehdashti S, et al. Quantum Cognitively Motivated Decision Fusion for Video Sentiment Analysis[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(1): 827-835.
Gkoumas D, Li Q, Yu Y, et al. An entanglement-driven fusion neural network for video sentiment analysis[C]//Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence. International Joint Conferences on Artificial Intelligence Organization, 2021: 1736-1742.
Li Q, Gkoumas D, Sordoni A, et al. Quantum-inspired Neural Network for Conversational Emotion Recognition[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(15): 13270-13278
Zhang Y, Song D, Li X, et al. A quantum-like multimodal network framework for modeling interaction dynamics in multiparty conversational sentiment analysis[J]. Information Fusion, 2020, 62: 14-31.
Liu Y, Zhang Y, Li Q, et al. What Does Your Smile Mean? Jointly Detecting Multi-Modal Sarcasm and Sentiment Using Quantum Probability[C]//Findings of the Association for Computational Linguistics: EMNLP 2021. 2021: 871-880.
▲ 图1 每篇文章中主要应的量子理论概念,以及所聚焦的关键问题
来自 Gkoumas 等人的两篇文章聚焦于视频情感分析。在 AAAI21 的工作中,他们假设单模态情感判断不是独立的,受其他模态的影响,其他模态作为当前模态下情感判断的上下文,进而假设单模态的情感判断是不兼容的(即,不同模态的决策的顺序是会对其他模态的决策产生影响的,并且不同的决策不可以同时被测量来产生最终决策)。他们通过 POVM(Positive-Operator Valued Measurement) 解决不兼容问题,进行多模态决策融合。所提出的模型在 CMU-MOSI 和 CMU-MOSEI 两个数据集上与最好的对比模型效果相比,在 F1 指标上分别实现了 6.8% 和 3.0% 的提升。
在 IJCAI21 的工作中,针对现有量子理论驱动模型简单地将量子态视为经典的状态混合或跨模态的可分离张量的生成物,而没有将它们以相关或不可分离(即纠缠)的方式建模它们之间相互作用的问题。进而提出使用量子纠缠的概念,来捕获跨模态对表示之间的相关性。该模型在 CMU-MOSI 和 CMU-MOSEI 两个数据集上相对于 SOTA 模型分别有 2.7% 和 2.6% 的提升。
来自李秋池和张亚洲等人的两篇文章,在多模态情感分析的基础上加入了对话上下文信息。其中李秋池等人在 AAAI21 的工作将对话情绪识别和完整的量子测量过程进行类比,将量子测量过程中的步骤刻画为识别对话中说话人情绪特征的过程。并且与已有的量子理论驱动模型不同,它们设计了一个专用优化器来更新复值酉矩阵,使神经网络可端到端训练。所提出模型在 MELD 数据集上获得了最好的 F1值 和正确率,但在 IEMOCAP 数据集上略逊于 DialogueRNN。
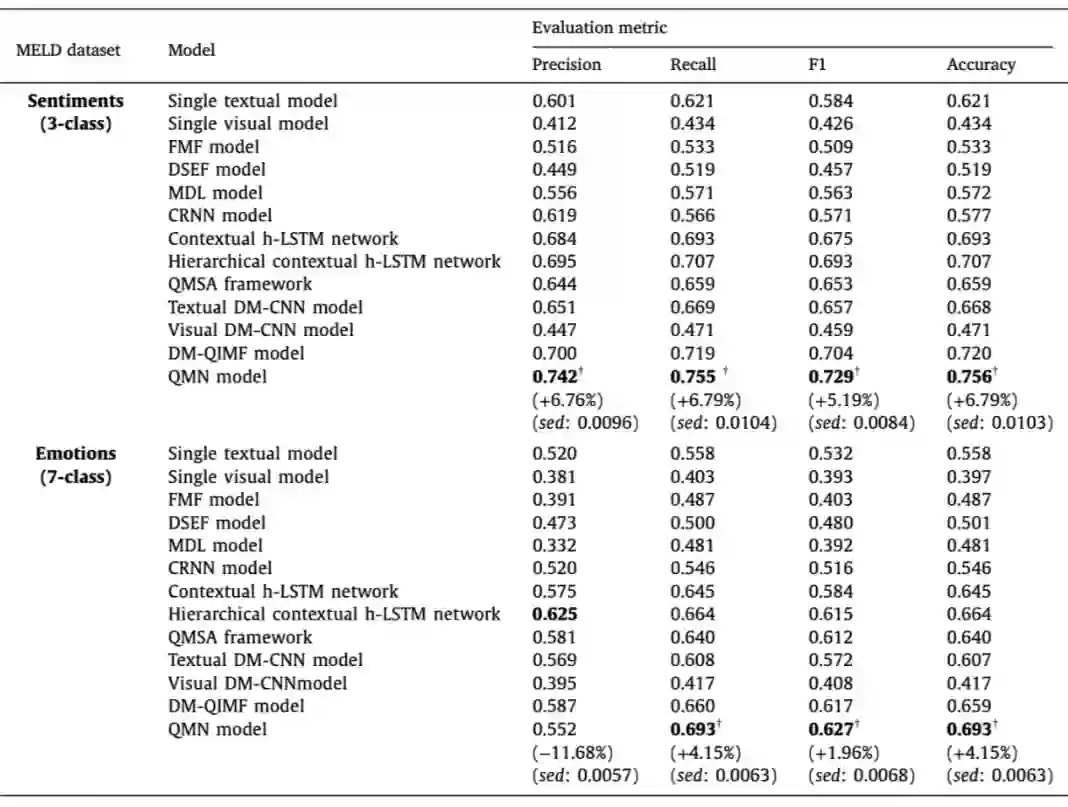
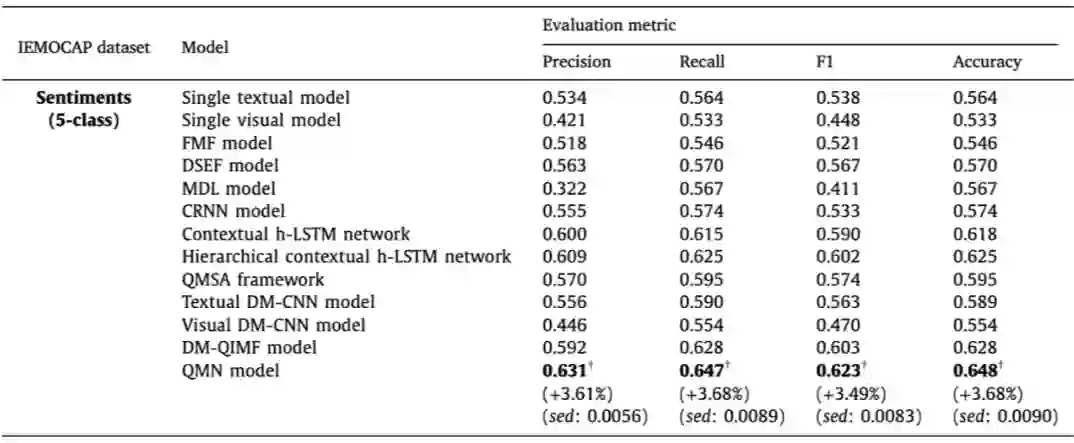
在 Information Fusion 的工作中,张亚洲等人也同样将量子测量的概念的引入模型中,设计了量子测量启发的强弱影响模型,并将其与 LSTM 模型结合,来更好地推断说话者之间的交互影响。除此之外,他们还引入了量子干涉效应的概念,提出了一种受量子干涉启发的多模态决策融合方法来模拟不同模态之间的决策相关性。在 MELD 数据集上相对于 h-LSTM 模型实现了 6.7% 的正确率提升,在 IEMOCAP 数据集上相对于 h-LSTM 实现了 4.2% 的正确率提升。
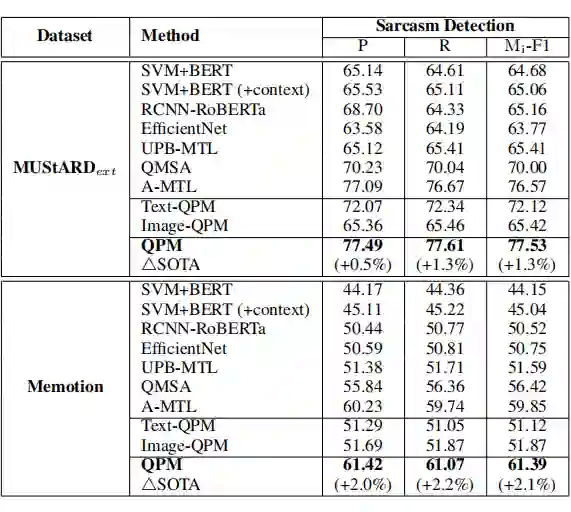
最后刘耀琛等人在 EMNLP21 中的工作面向讽刺和情感联合识别,在以上工作的基础上加入了多任务框架。讽刺和情感表达蕴含了人类认知的内在的不确定性,量子概率理论在建模这样的不确定上相较经典概率理论更具优势。与已有的量子启发式的工作不同,该工作的核心是对话上下文环境中,进行多模态融合建模,并使用量子不兼容测量来探索任务间的相关性。该工作使用量子复合系统和量子干涉融合组件分别捕获上下文和模态间相关性,最后引入了量子不兼容测量的概念来建模多任务之间的关联。该模型在两个数据集 MUStARD 和 Memotion 上相对于 SOTA 模型 A-MTL 实现了 1.3% 和 2.1% 的 F1 值提升。
量子概率理论的数学基础是建立在希尔伯特复值空间上的,将该空间记为
。一个量子状态向量
表示为一个 ket
,它的共轭转置向量表示为 bra
。向量
和向量
的内积和外积记为
和
。
量子叠加态表示量子状态可以以一定的概率分布同时处于多个互斥基态,直到它被测量,任意量子系统的纯态向量
都可以表示为叠加态,即
个基态的加权和,纯态向量
可以表示为以一定概率分布的概率振幅的形式:
,这里
表示复值概率振幅,
是非负标量,满足
,
表示虚数,
表示相位。量子混合态使用密度矩阵来表示,密度矩阵
,这里
表示组成混合态的每一个纯态向量的概率分布。
量子复合系统描述了一个由多个单独的量子系统组合成的复合体系。对于
和
维的两个空间,一个状态向量
表示为乘积空间的任意基
的线性组合,表示为:
表示概率振幅,满足
。
当复合量子系统在包含各个子系统之间相互作用的哈密顿量下演化时,复合系统的结果状态不再是可分离的,也就是处于纠缠态。二分冯诺依曼纠缠熵是对复合纯态的量子纠缠程度的度量。
2.3 量子干涉
在双缝干涉实验中,两条路径相互干扰彼此,导致在粒子抵达探测屏上的位置的概率分布受到干扰。可以使用波函数
来建模这一行为。波函数使用概率振幅来表示粒子处于位置
的概率,并且波函数的平方可以表示概率。用公式
来表示粒子处于路径 1 和路径 2 的量子叠加态的状态,这里
和
是路径 1 和路径 2 的波函数表示,
和
是复数。概率可以通过下式来计算:
上式中
表示干涉角度。
是干涉项,它描述了两条路径的交互。
2.4 不兼容性
不兼容的概念仅适用于希尔伯特空间。每个定义概率事件的基态都有一个投影
来评估事件。两个事件不一定是可交换的。假设
和
分别是
和
事件的两个连续测量。在量子认知中,两个事件的联合概率分布等于两个投影
和
的乘积,对应于基态
。
如果
,则称这两个事件是相容的,否则是不兼容的。不兼容意味着不能在不相互干扰的情况下联合访问这两个测量。经典概率假设测量总是兼容的,因而无法捕捉到这种干扰。然而,量子概率的数学形式是经典概率论的推广,它允许兼容和不兼容的测量。
AAAI 21:用于视频情感分析的量子认知驱动决策融合
论文标题:
Quantum Cognitively Motivated Decision Fusion for Video Sentiment Analysis
AAAI 2021
https://arxiv.org/abs/2101.04406
3.1 简介 假设单模态情感判断不是独立发生的,它们在信息上存在交互,因此受到作为当前模态上下文的其他模态的影响。例如,存在的不同决策视角的顺序可能导致有争议的情绪判断的情况(首先关注语言然后关注视觉图像,反之亦然)。在这种情况下这两种决策视角是不兼容的。这种不兼容意味着不能联合测量对不同模态的判断,作为经典概率理论的泛化,量子理论可以解释并解决该现象。
本文介绍了一种受量子认知启发的新型决策级融合策略。目标是预测与语言、视觉和声音信息相关的视频中话语的情绪。首先将话语表述为积极和消极情绪的量子叠加状态(即,它可以同时是积极和消极的,直到在特定上下文下进行判断),并将单模态分类器建模为由不同的单模态情感基向量张成的复值
空间
上的互不相容的可观察量。使用 POVM 测量近似单模态分类器的情绪结果。
作者从训练数据中估计复值希尔伯特空间和单模态可观察量,然后从学习到的单模态可观察量中建立测试话语的最终多模态情感状态。本工作是第一个探索和建模视频情感分析中情感判断不兼容性的量子认知理论启发的方法。
3.2 量子测量 测量是量子认知中计算量子概率的基本概念。在量子测量中,Projection-Valued Measure(PVM)通过将状态投影到其特定相应的基态,将系统状态从不确定性状态转移为精确事件。在没有测量的情况下,状态存在不确定性,因为它同时处于所有可能的测量值上。
测量后,状态会坍缩到某个基态。然而,更大系统的子系统上的 PVM 不能通过作用于系统本身的 PVM 来描述。Positive-Operator Valued Measure(POVM)克服了这一限制,通过为每个测量结果关联一个正概率,忽略测量后的状态。也就是说,POVM 是 PVM 的泛化,为整个集成的子系统提供状态的混合信息。
POVM 测量
是一组半正定的赫尔米特算子
,并且有
。对于一个纯态向量
,它的密度矩阵为
。测量得到状态
的概率为:
,并且
。
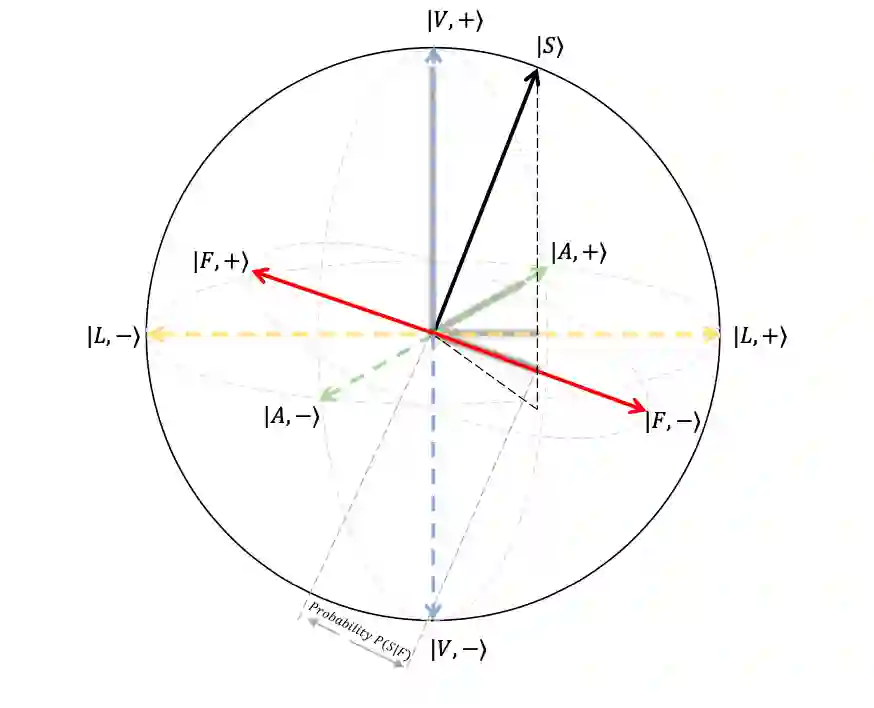
▲ 图1 情感希尔伯特空间。话语被表示为属于布洛赫球体表面的纯态向量,两个相对的单位向量代表正面和负向情感判断。相关的三种单模态可观察量 L,V,A 和三模态可观察量 F 是不兼容的。带阴影的基向量表示 S 在相应基上的投影,即事件的概率。
3.4.1 情感希尔伯特空间
该模型定义在由基态
张成的二维情感希尔伯特空间
上,两个基态
和
对应于正向的和负向的情感状态。将一个话语
定义为
上的一个纯态向量
(可以缩写为
)。单模态情感分类器被公式化为不兼容的可观察量(表示为
),话语可以在不同的基态集合下表示。因为模态不是独立的,所以可观察量之间彼此不正交。
一个话语表示为由正负情感基向量张成的 2- 维希尔伯特空间
上的一个纯态向量:
依据波恩定理,话语处于正向和负向状态的概率分别为
和
,并且
。相对相位
在捕获不兼容的可观测值之间的相关性,和产生与经典情况根本不同的结果方面起着至关重要的作用。
作者将单模态的情感判定结果表示为在
上相互不兼容的可观察量(
)。对于情感二分类任务,每一个可观察量都与两个特征值(
)和两个特征状态(相对应的负向情感和正向情感)相关联。在这种情况下,不兼容性由属于单模态基向量的不同特征状态触发
在量子理论中,一般的可观测量可以被正交的特征状态分解为:
,特征状态
表示测量后可能表现的状态。单模态可观测量表示如下:
为:
,它张成了
并且与单模态可观测量不兼容。
遵循投影几何结构,特征状态上的测量概率等于系统状态在其上的投影,即向量的平方内积:对于单模态正向情感为
对于多模态正向情感为
。
下的测量概率代表语言模态下话语的情感,其他模态也是如此。最后,它的多模态情感极性由可观察量
决定。
3.5 模型操作
本节介绍了一种用于操作所提出的融合模型的方法。一般的,在物理学中,数学问题的研究涉及利用近似技术的建模方法。在本工作中作者利用数据中的统计信息来学习上一节中描述的情感希尔伯特空间,从而利用不兼容的可观察量来确定话语的情感极性。作者提出了一个由三个步骤组成的 pipline:(1)首先从训练数据中估计通用单模态可观察量
;(2)然后根据学习到的单模态可观察量和单模态情感预测结果为每个测试话语
构建情感状态;(3)最后,用多模态可观察量
判断情感。
单模态可观测值是根据训练数据的整体统计数据构建的。这些值被映射到它们的量子表达式以估计单模态可观测值的参数。单模态可观察量和纯态应符合以下性质:I)纯态应符合数据集的统计量,II)单模态情感测量结果应符合训练子集中正负样本比值 ,III)可观测值之间的量子相关性应与从训练数据导出的每个样本预测结果的经典相关性对齐。
然后研究成对模态可观测值之间的相关性,其中相对相位起着关键作用。从量子测量的角度出发,两个可观测量
的量子和经典相关性的关系可以由下式给出:
表示经典相关性。通过求解方程组,可以计算每个单模态可观测量
的参数。
由于观测量
互不兼容,因此无法同时访问测量结果。为此,作者利用
同时获得所有不兼容测量的结果。构造运算符:
在测试话语上应用单模态
来衡量其在每种模态上的情绪:
,
表示是积极情绪判断的单模态概率。该公式给出了一个具有三个方程的系统,每个方程对应一个不同的模态,以及三个未知变量
, 求解该系统可以构造状态
。
测试话语
的情感可以通过
来测量。结果是
,
。如果
那么
的情感极性判定为正向,否则为负向。
3.6 实验
在两个数据集 CMU-MOSI,CMU-MOSEI 上验证了模型的有效性。
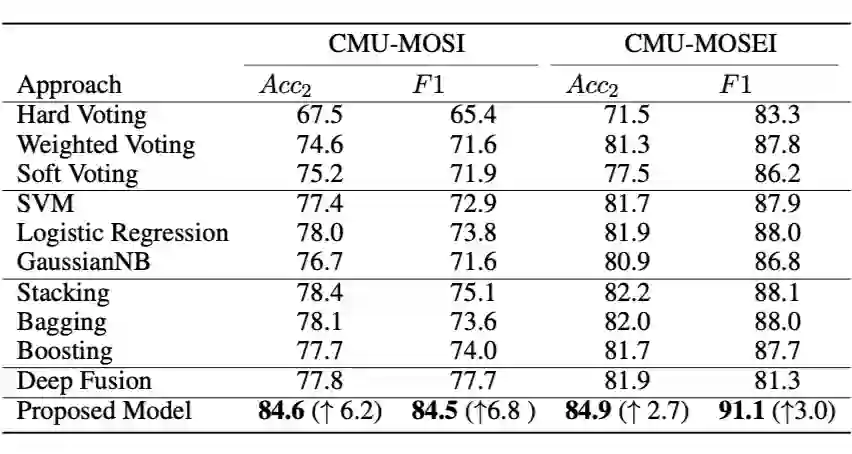
总的来说,加权投票是基于投票的聚合、逻辑回归和堆叠方法中表现最好的方法。对于这两个任务,Stacking 和 Bagging 是最有效的基线决策级融合策略。在 CMU-MOSI 上,与 Stacking 的 78.4% 相比,所提出的模型的准确率提高到 84.6%,显着提高了 6.2%。对于 CMU-MOSEI,与 Stacking 的 82.2% 相比,该模型的准确率提高到 84.9%,即显着提高了 2.7%。
▲ 表1 决策级别对比实验结果
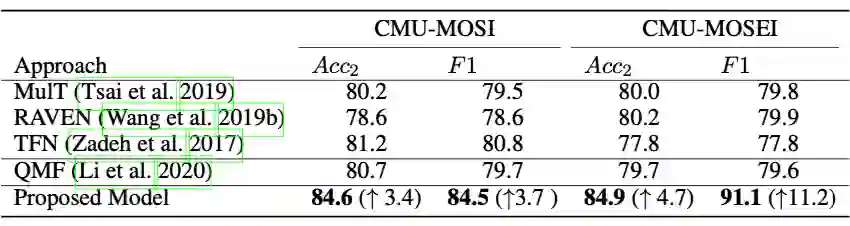
对于 CMU-MOSEI,RAVEN 在基线中取得了最高的准确率。与 RAVEN 的 80.2% 相比,所提出的模型的准确率提高到 84.9%,提升了了 4.7%。
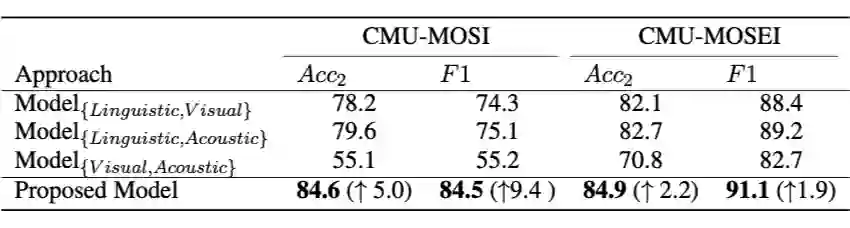
表 3 显示了消融实验的结果。前三行列出了当没有对跨模态交互建模时单模态分类器的性能。由于使用在大型语料库上训练的词嵌入,语言模态是最具预测性的。对于 CMU-MOSEI,语言分类器甚至优于所有基于内容级别和基于投票的融合方法。
作为第二组消融实验,作者在仅使用双模态时测试了所提出的模型。在表 4 中给出了结果,它表明语言和音频模态是最有用的。然而,三模态模型优于所有可能的双模态组合,CMU-MOSI 的准确率提高了 5.0%,CMU-MOSEI 的准确率提高了 2.2%。
本文引入了一种受量子认知启发的融合策略。将话语表述为量子状态,将单模态决策表述为复值情感希尔伯特空间中互不相容的可观察量。不兼容性捕获了决策融合过程中的认知偏差。所提出的模型已被证明能够处理所有组合模式,包括所有单模态分类器给出错误情绪判断的情况。与内容级和决策级 SOTA 模态融合方法相比,所提出的方法实现了更高的性能。将来,作者将研究对话视频情感识别任务的模型。
IJCAI21:用于视频情感分析的纠缠驱动融合神经网络
论文标题:
An Entanglement-driven Fusion Neural Network for Video Sentiment Analysis
IJCAI 2021
https://www.ijcai.org/proceedings/2021/239
4.1 简介 视频情感分析是多媒体信息处理中一个新兴的跨学科领域,汇集了人工智能(AI)和认知科学。它研究说话者通过语言(即语言)和非语言(即视觉、声音)内容表达情感。该研究领域的核心是对不同模态之间的交互进行建模。当前的模型忽略了如模型透明度、事后可解释性以及人们如何理解和推理情绪状态等问题。用于情感分析的不同模态的建模是一个具有挑战性的问题。
这是由于话语可能出现的情绪极性(例如,积极的、中性的或消极的)受到单个模态的上下文的影响。这意味着不能孤立地考虑不同的模态。必须以不可分离的方式建模多模态信息,也可以称为纠缠的方式。量子理论(QT)是唯一模拟不可分离性的理论。因此,可以使用 QT 理论来捕捉跨模态相关性,以及这些相关性如何影响关于话语情绪的最终产生。
本文提出了一个量子概率神经网络,它捕获不同模态的非经典相关性。作者将不同模态的实值输入特征转换为复值的纯量子态。模态状态相互交互的特定方式允许在统一框架中对模态之间的经典相关性和不可分离性(纠缠)进行建模。该工作与之前的概率神经网络方法的不同在于解决了上下文问题。所提出的模型在用于视频情感分析的两个基准数据集上进行了评估。实验结果表明,该模型的表现达到了 SOTA。结果还表明,纠缠态的不可分离程度可用于提高事后可解释性。
4.2 任务定义
模型的目标是预测视频话语的情感。数据集中包含
个标记的视频话语
。每一个话语
都与语言的、视觉的、音频的特征相关联,表示为
。每条话语相对应的标签表示为
正确映射到它对应的标签
上。
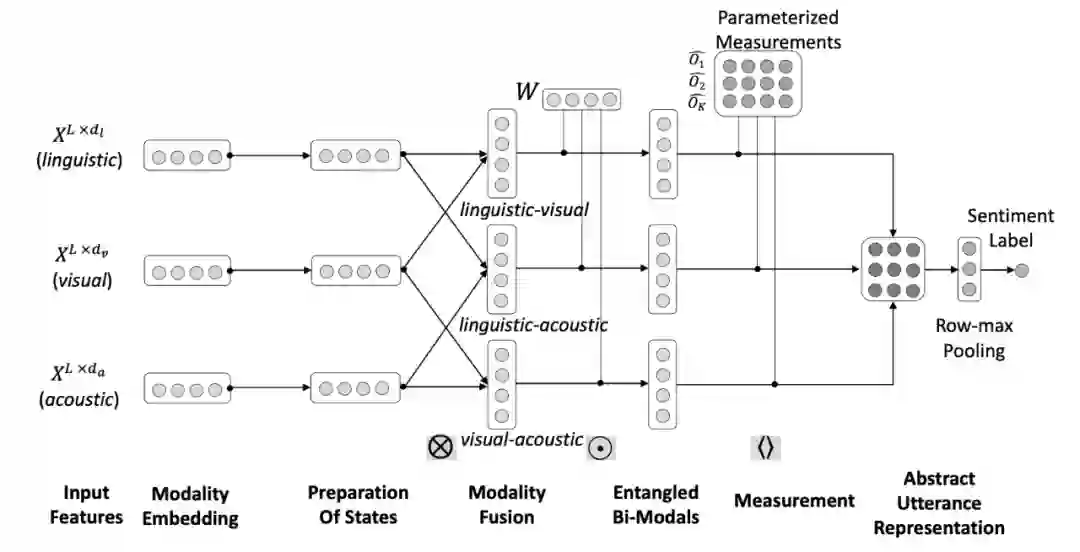
本文提出的量子概率神经模型叫做纠缠驱动的融合神经网络 EFNN。EFNN 首先获取多模态信息,即语言、视觉和声学信息,并将其输入三个独立的神经网络分支。多模态信息首先被投影到一个共维空间,然后通过准备步骤将信息转换为其量子模拟,即量子态。
之后通过任意一对双模态信息之间的张量积操作,生成成对模态融合。权重向量可以捕获基于双模态张量的表示中的相关性。一组参数化的测量通过量子测量假设,将复值表示映射到实值高级表示。然后,应用 row-max 池化算子,将全连接层传递给 softmax 函数进行分类。
▲ 图1-EFNN 模型图
4.3.1 量子态的准备阶段
每个话语都被建模为模态特定的希尔伯特空间
上的单模态纯量子态,其中
。与之前的工作一致,作者考虑复数的指数形式来表示量子态:
,其中振幅
是非负实值系数,相位
,
是虚数。
话语的模态特定的纯态向量
通常可以用以下形式表示:
表示各模态向量的维度,
表示逐元素向量积。在模数-参数形式中,对复数的任何运算都将生成模数和参数的非线性组合。
通过卷积神经网络将输入特征从各个输入特征投影到相同维度
中,并在最后一个隐藏层中使用修正线性单元(ReLU)作为激活函数
仍能捕获话语中单词的局部结构。然后,作者对输出进行归一化以创建单位长度的向量:
。
第二个向量
也是实值向量,取值范围为
。相位
的分配是一个开放的研究问题。在这项工作中,为了使每个话语都能携带时间信息,将句子中单词的位置分配给相位部分。通过这种方式能够捕获话语中单词的全局结构:
,
表示由
的离散索引到实值向量的映射。
4.3.2 纠缠驱动的模态融合
作者设计了一个融合模块,它采用成对模态的话语状态,即语言-视觉、语言-声学、视觉-声学。对于每一对状态,通过计算它们的张量积来创建一个复合但可分离的状态。复合可分离状态定义在
维空间
上,公式为:
,其中
和
表示任意两种模态,
表示外积操作。
从表示的角度来看,张量积的操作可以被认为是一个加权的线性变换层。从量子的角度来看,
可以实现为酉算子
。在整个二元模态交互过程中,
作为对不同希尔伯特空间
的量子哈密顿控制,变换后产生纠缠。这意味着转换后的输出不能以可分解的形式写入,从而有可能捕获跨成对模态的非经典相关性。
4.3.3 量子测量
测量组件作用于三个不可分离的成对模态的集合。一组参数化测量
在一组不可分离的成对模态上执行,为每对模态生成一系列正标量:
,其中
是任意一对模态,每个
代表一个抽象的情感概念。输出是由测量产生的正实数值的
矩阵。
然后进行逐行最大池化,将三个抽象概念序列并联成一个高级话语表示。最后,高级表示被传递到一个全连接层,通过一个 softmax 分类器获得分类结果。
4.4 实验
4.4.1 性能分析
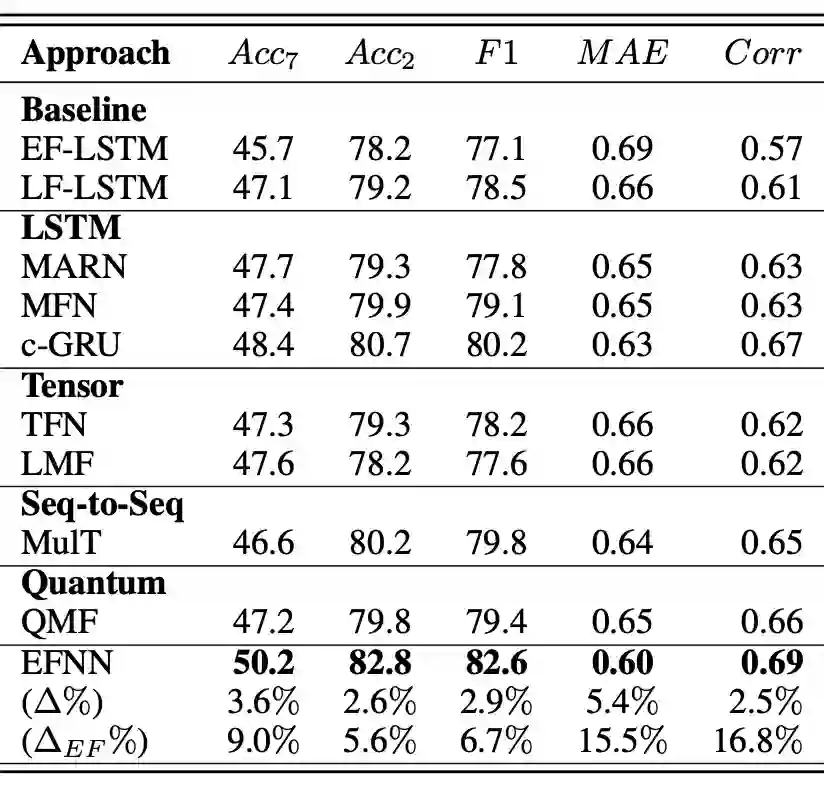
▲ 表1-EFNN 在 CMU-MOSI 上与基线模型效果对比
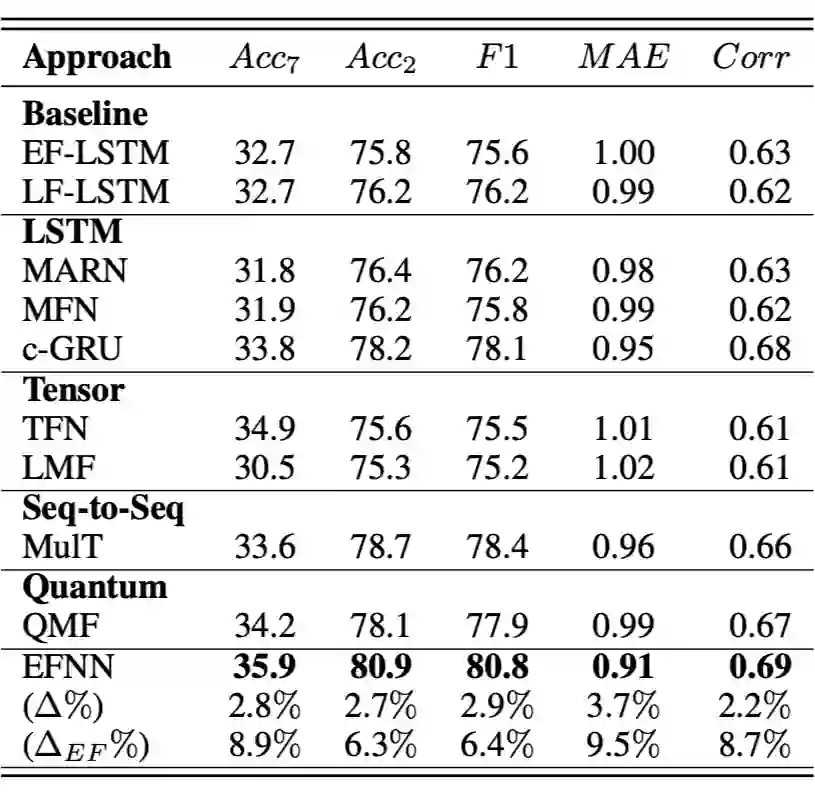
表 1 显示了 EFNN 在 CMU-MOSI 上与 SOTA 基线方法之间的比较结果。与其他基线相比,应用注意力机制来对齐成对模态的 c-GRU 和 MulT,表现出最高的二分类正确率。
▲ 表2-EFNN 在 CMU-MOSEI 上与基线模型效果对比
表 2 显示了在 CMU-MOSEI 上的实验结果。与 c-GRU 的 80.7% 相比,EFNN 的二分类正确率提高到 82.8%,显着提高了 2.6%(t-检验 <.05)。最后,EFNN 实现了在 CMU-MOSEI 上,在所有评估指标的改进。
4.4.2 消融实验
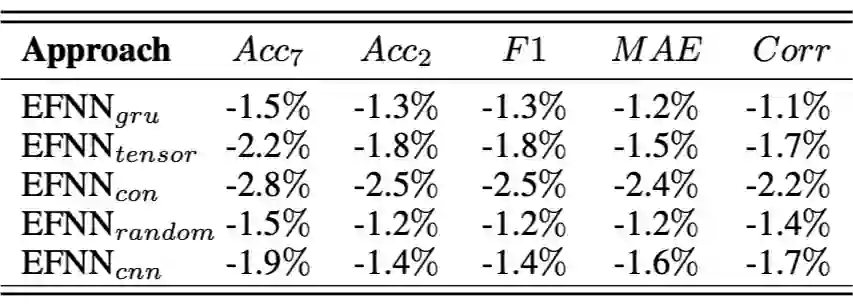
为了检查卷积神经网络
将模态投影到共维空间的有效性,作者将组件替换为 GRU 层 EFNNgru。通过引入 EFNN 的其他两种变体,在移除权重向量
后研究不可分离模态的影响:a)EFNNtensor 将所有模态融合到一个统一的基于张量的表示中;b)EFNNcnn 将所有模态连接成一个向量表示,然后输入测量组件。此外,还通过从标准正态分布 EFNNrand 初始化阶段来考虑影响词在话语中的位置。用卷积神经网络(CNN)替换测量值,其中 CNN 的
个滤波器用作
个测量值,以研究测量组件 EFNNcnn 的影响。
表 3 所示的消融测试结果表明,每个组件在 EFNN 中都起着至关重要的作用。特别是,与 EFNNrand 的比较显示了将单词位置建模到复值表示的相位部分的有效性。同时,EFNNtensor 和 EFNNcon 的性能下降揭示了对模态之间的非经典相关性(即纠缠)进行编码的优越性。此外,与 EFNNcnn 的比较显示了可训练测量的有用性。最后,EFNNgru 表明卷积神经网络可能是将模态投影到共维空间的更合适的方法。消融测试表明纠缠驱动的融合组件在 EFNN 的架构中起着最关键的作用。
4.4.3 事后可解释性
通过研究模态上下文交互后复合话语状态内的双模态相关性来评估事后可解释性。根据二分冯诺依曼纠缠熵,作者计算了语言和视觉模态的二分复合话语状态的量子纠缠度。
▲ 表4 事后可解释性试验
表 4 根据纠缠熵说明了纠缠最多和最少的语言、视觉模态的一些示例。纠缠程度最高的对是那些两种模态中的一种模棱两可或无信息的对。相比之下,当两种模态的上下文信息丰富、明确且同时存在时,纠缠熵接近于零。在这些情况下,复合表示是可分离的,不需要利用量子概率解释。然而,通过不可分离的概念,EFNN 能够捕获可分离和不可分离的双模态交互,作为现有概率模态融合方法的概括。这个属性是 EFNN 取得性能提升的核心原因。
4.5 结论
在这项工作中,作者引入了一种用于视频情感分析的量子概率神经模型。不可分离性作为融合双模态的量子纠缠的概念和形式使模型能够捕获模态之间的经典和非经典相关性。通过适当的措施量化非经典相关性,优化事后可解释性。在未来,作者希望利用对话上下文和系统的进化假设来扩展对话视频情感检测的框架。
AAAI21:用于对话情绪识别的量子启发神经网络
论文标题:
Quantum-inspired Neural Network for Conversational Emotion Recognition
AAAI 2021
https://ojs.aaai.org/index.php/AAAI/article/view/17567
5.1 简介 已有的多模态对话情绪识别工作,很少有工作在统一架构中同时加入多模态融合和对话上下文建模的方法。并且已有的基于深度学习的模型可解释性较弱,这些模型主要由类似黑盒的神经网络组件组成。作者设计了一个类量子的框架来处理对话情绪识别,以解决上述的一系列限制。
作者将量子测量过程与情绪识别过程进行了类比,在量子物理实验中,粒子在测量前处于多个相互独立的纯态的混合状态,测量会使其坍缩到单一的纯测量态。同样的,说话者处于多种独立情绪的混合状态,将对话上下文视为一种测量,会导致情绪状态坍缩到纯态。此外,量子态随时间的演变可以类比为说话者在交谈过程中情绪状态的演变。
这些类比启发了作者设计用于对话情绪识别的量子测量模型。作者构建了一个复值神经网络来实现测量过程。使用专用的优化器来更新量子概念中的复值酉矩阵,从而可以使用标准反向传播算法端到端地训练整个模型。
5.2 一个完整的量子测量过程
测量是衡量系统物理特性的过程。完整的量子测量过程包含状态准备、演化、测量和坍缩。
准备状态 即准备量子系统的过程。经过这个过程可以得到被测量系统的状态
。
演化 准备好的系统不会保持不变,而是在测量之前随着时间的推移进行复杂的演化过程。演化可以在数学上表述为酉算子或等效的复杂酉矩阵
,满足
。演化后的系统为:
。
测量 测量与希尔伯特空间中的可观察量
相关联,即
。一个可观察量可以特征分解为:
。其中特征向量
是构建整个希尔伯特空间的正交基向量,特征值
是测量后可能观测到的值。对于一个系统
,观测到值
的概率
可以通过波恩定理计算:
坍缩 在测量之后,系统总是会坍缩到可观测量的一个纯特征态
上。如果测量可以无限次的重复的话,那么系统可以以概率
坍缩到状态
。
5.3 方法
5.3.1 问题定义
输入是一个包含
个话语
的多模态对话
。每一个话语
都有相应的文本的,视觉的和音频的表示
,并且是被角色
表述的。假设整个数据集中共有
个角色,
。任务是,对于每一个话语
在有限的情绪集合
中预测出相应的情绪
。
对于不同模态建立的不同的神经网络提取特征。对于文本模态,使用 300 维的 Glove 词向量和 CNN 网络来提取特征。视频和音频模态使用 3D-CNN 和 openSMILE 来提取特征。
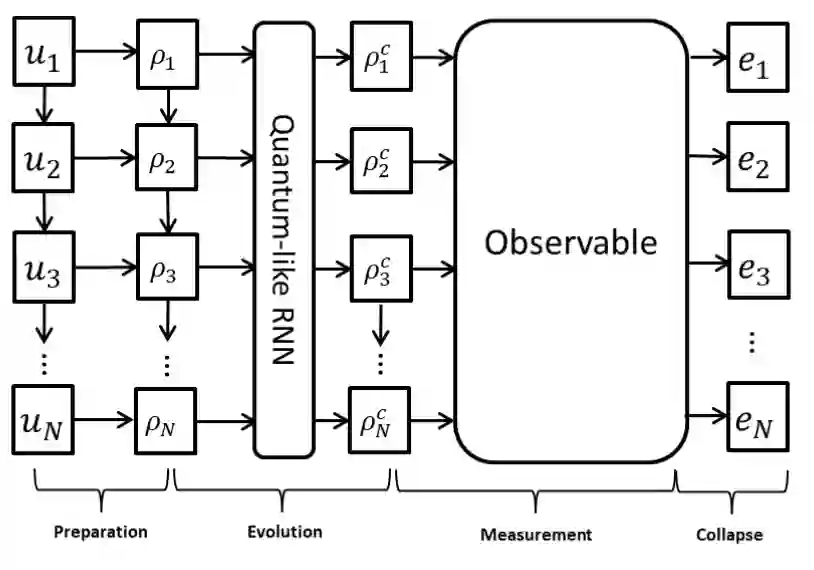
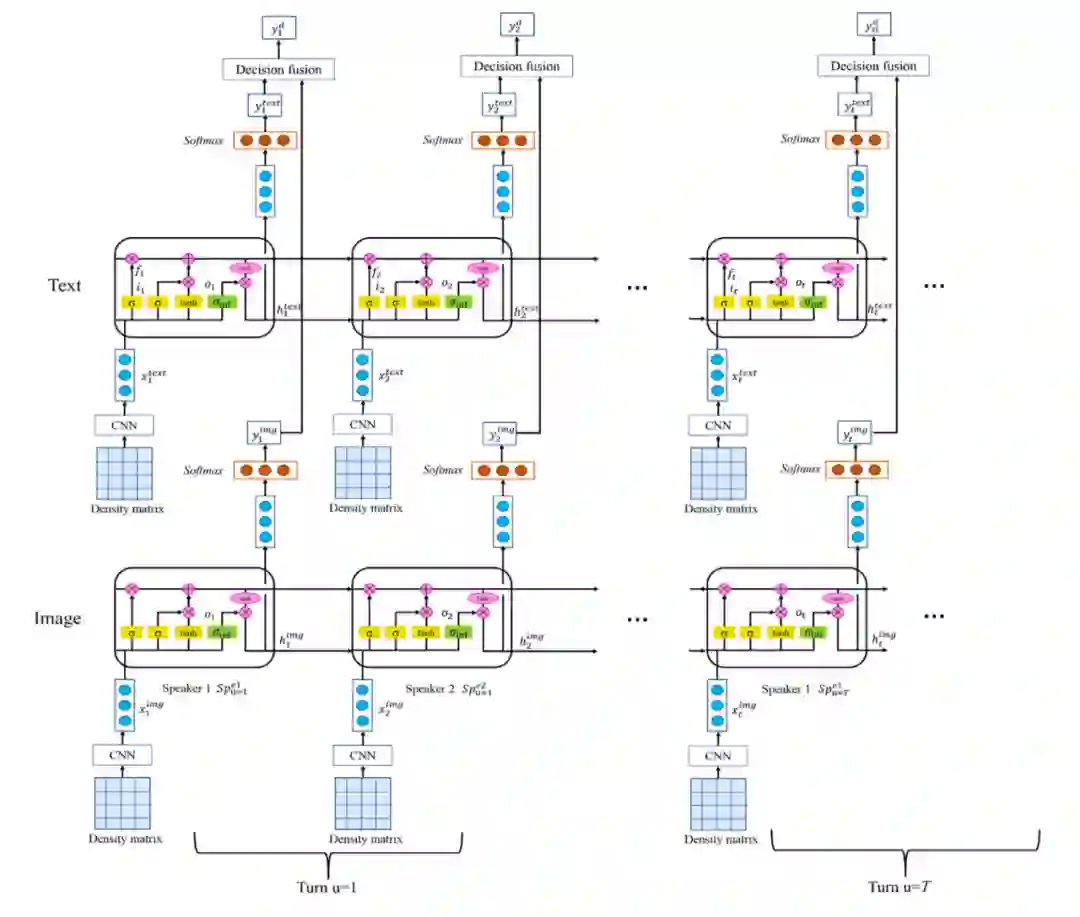
5.3.3 识别对话中情绪的量子启发神经网络
图 1 展示了提出的情绪识别网络。主要由四步构成,即上文所说的准备状态 ,演化 ,测量 和 坍缩 。
▲ 图1 所提出的模型。每一个话语被表示为相应的密度矩阵,演化过程由一个类量子的 RNN 来模拟,演化后状态被输入到由可观测态控制的测量中,情绪标签通过最大似然生成。
准备状态 将对话中的每一个语句
准备为状态
。通过多种方式的量子混合实现多模态的融合。单模态的特征被视为纯态,话语被视为单模态纯态的混合。图 2 展示了准备状态的过程。将每个模态的特征向量通过一个全联接层,并将结果进行规范化来将三种模态的特征投影到一个
维的空间中。使用相位-振幅的方式可以将单模态的纯态表示为两个向量的乘积形式。将话语顺序和说话者的信息作为相位部分。振幅部分即之前提取到的各个模态的特征向量。然后将各个模态的纯态进行融合:
▲ 图2 准备过程。通过建立三种模态的表示,并将其融合来得到多模态的混合态
演化 使用类量子的循环神经网络(QRNN)来建模演化过程。QRNN 的输入为密度矩阵的序列
。隐藏态的密度矩阵
表示了序列的信息,在时间步
它的值通过迭代计算:
和经典 RNN 有
类似,QRNN 也有
,更新函数
是一个参数化的酉矩阵
和实值
。
测量过程和坍缩 在演化过程之后,生成了一整个序列的
维状态
。使用一个全局的可观测量来测量每个语句的情绪状态。相互正交的特征状态可以构建一个
维的酉矩阵
。在测量之后,一个
维的概率分布被计算出来,它表示状态坍缩到相应特征状态的似然。然后这个
维的概率向量通过一层全联接层计算得到相应情绪标签的预测值。
5.3.4 模型训练
在模型训练时,应特别注意 QRNN 和测量层中的酉矩阵。为了在整个训练过程中满足酉约束,作者采用黎曼方法来更新酉矩阵。更新酉矩阵 X 的过程由下式给出:
其中
是梯度,学习率
控制
偏离
的程度。对于逆矩阵,通过将其分解为实部和虚部以便通过深度学习工具进行训练。
5.4 实验
在两个数据集 IEMOCAP 和 MELD 上测试了本文提出的模型。使用平均准确率和 F1 值作为评估标准。实验结果如表 1 所示,所提出的 QMNN 在 MELD 上获得了最好的 F1 和准确率效果,但在 IEMOCAP 上略逊于 DialogueRNN。QMNN 与现有模型之间没有观察到显着差异,结果表明与现有模型相当的效果。
5.5 结论
这项工作为对话情绪识别问题提供了一种新颖的量子观点。构建了一个完整的量子启发式网络来融合多模态数据,并构建对话上下文信息,在此基础上识别每句话语的情绪。网络的设计和使用酉矩阵的训练方法保证了量子模拟的真实性。模型在两个数据集上也达到了与已有模型相媲美的表现。
Information Fusion:一种用于对话情感分析中的交互动态建模的类量子多模态网络框架
论文标题:
A Quantum-Like multimodal network framework for modeling interaction dynamics in multiparty conversational sentiment analysis
Information Fusion
https://www.sciencedirect.com/science/article/abs/pii/S1566253520302554
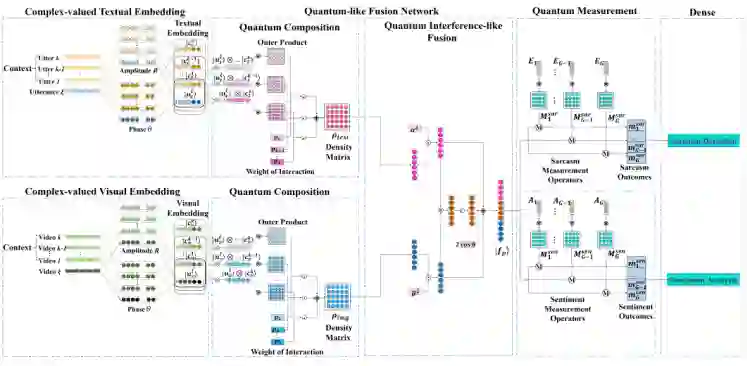
6.1 简介 在本文中,利用量子力学的形式理论和 LSTM 架构,作者提出了一种类量子多模态网络(QMN)框架,该框架通过捕获不同模态之间的相关性来联合建模话语内和话语间的交互动态,并推断说话者之间的动态影响。
首先,QMN 使用基于密度矩阵的 CNN(DM-CNN)子网络为一个视频中的所有话语提取和表示多模态特征。QMN 引入了一个强弱影响模型来测量说话者之间的影响,并将产生的影响矩阵合并到每个 LSTM 单元的输出门。然后,以文本和视觉特征作为输入,QMN 使用两个单独的 LSTM 网络来获取它们的隐藏状态,然后将其输入到 softmax 函数以获得局部情感分析结果。最后,设计了一种受量子干涉启发的多模态决策融合方法,以根据局部结果得出最终决策。
作者在两个广泛使用的对话情感数据集(MELD 和 IEMOCAP 数据集)上设计并进行了大量实验,所了提出的 QMN 框架与广泛的基线相比的有效性。
有两种类型的量子测量(QM),包括普通(强测量)和弱测量。量子测量描述了量子系统和测量系统之间的相互作用。强测量会导致量子态塌缩,而弱测量对量子态的干扰很小。在 QT 中,量子测量过程包括两个步骤:(i)量子测量设备与被测量的量子系统弱耦合;(ii)测量装置被强测量,其坍缩状态称为测量过程的结果。
该工作的目标是在话语(句子)级别确定每个说话者的态度。因此,研究的问题将每个话语
作为输入并生成其情感标签
作为输出。
所提出的的类量子多模态网络(QMN)框架的架构如图所示。首先通过基于密度矩阵的卷积神经网络(DM-CNN),提取每个话语的文本和视觉特征:
受量子测量理论的启发,设计了一个强弱影响模型来计算整个对话中说话者之间的话语上下文影响,用
表示。然后,基于提取到的多模态特征
,设计 LSTM 的变种模型,通过将输出门
与话语间影响
相结合,对对话中的情感演变进行建模。最后,受量子干涉效应的启发,作者提出了一种多模态决策融合方法来获得完整的情感标签
。
6.3.1 多模态表示学习
目前,一系列开创性研究提供了证据,证明在量子概率空间中定义的密度矩阵可以作为一种有效的表示方法应用于自然语言处理。与嵌入向量相比,密度矩阵可以编码二阶语义依赖。作者设计了一个基于密度矩阵的卷积神经网络(DM-CNN)来表示对话中所有话语的文本和图像。每种模态的表示为:
由词
的外积
表示。
在本文中使用 GloVe 来查找每个单词的向量表示。定义完每个单词的投影之后,使用密度矩阵
来表示一个句子:
,
表示单词出现的概率,满足
。在这项工作中采用了使用单词的出现频率来计算它们的概率和密度矩阵的方法。
然后将
输入到 CNN 网络中提取更抽象的文本特征
的滤波器,第二个卷积层有
个
滤波器。全连接层由
个神经元组成。最后将此文本特征
作为 QMN 模型的输入。
在对视觉模态进行特征抽取时,将一个图像视为视觉文档,使用视觉词
的概念来构建视觉的投影算子。提取每张图像的 SIFT 特征,SIFT 特征是 128 维的。然后使用 k-means 算法将 SIFT 特征聚类为 k 个类别,每一个聚类中心视为一个视觉语义单词,所有的视觉单词构建成了视觉词典
。然后使用这些视觉单词来构建视觉的投影算子
和相应的视觉密度矩阵
。视觉 CNN 特征提取网络包含六个卷积层,然后是一个全联接层。最终生成
维的视觉特征
,作为 QMN 模型的输入。
6.3.2 使用类量子多模态网络建模交互动态
在本小节中,首先提出了一个受量子测量启发的强弱影响模型,以捕捉不同说话者之间的交互影响。然后,引入了一种受量子干涉启发的多模态决策融合方法来模拟文本和图像之间的相互影响。最后,详细介绍了 QMN 模型。
量子测量启发的强弱影响模型 人类在进行对话时,情感会受到对话上下文的影响,强影响会造成我们的情感波动,而弱影响则不会。在 QT 中,量子测量描述了量子系统和测量设备之间的相互作用(耦合)。强测量导致量子系统状态的坍缩,而弱测量对量子系统状态的干扰很小。量子测量提供了建模说话者之间复杂交互作用的方式;作者用量子测量来模拟强弱相互作用,从而开发强弱影响模型。
强弱影响模型基于动态影响模型,它是 HMM 的泛化,用于通过构建影响矩阵来描述每个马尔可夫链对其他链的影响。该模型给出了影响的抽象定义:实体的状态受其邻居状态的影响并相应地发生变化。每个实体对网络中的每个其他实体都有影响。
假设整个系统中有
个实体,每个实体都可能出现集合
的任何状态。在每一轮中,每一个实体
都处于一个状态
(
表示轮次),依据
实体
每一轮都会表现出一个可观测状态
。影响被建模为当前轮次
的状态
与之前轮次
所有状态的条件依赖。建模为:
这里
是一个
大小的矩阵,
表示矩阵中处于位置
行
列的元素。
使用一个
的矩阵
来建模,表示为
表示处于位置
行
列的元素。矩阵
类似于转移矩阵,可以通过两个
的矩阵
和
来简化。
捕获自状态转换,
捕获邻接状态转换。
受到量子测量的影响,使用两个影响矩阵来表示强弱影响。
的切换由说话人情感得分的平均标准差
决定。得到了两个影响矩阵,它们捕获了一个说话者在不同交互环境下对另一个说话者的强弱影响。
量子干涉启发的多模态决策融合方法 在识别多模态内容的整体情感的过程中,用户通常会通过不同模态对应的多个模态通道,根据对内容的理解同时做出决策,这可能会造成认知干扰。作者用多模态情感分析来类比双缝实验。原始决策结果是不确定的,可以认为是光子。文本和图像中的情感可以看作是两个狭缝,每个情感分数是检测屏幕上的一个位置。在这样的类比中,决策结果对于文本和图像的情感处于类似叠加的状态,因此每种模态的情感信息都会同时影响最终决策。
作者使用波函数
来形式化该类比。决策结果是文本和图像情感的叠加。
,
和
表示文本和图像的情感的波函数表示。最终决策的概率分布可以测量为:
类量子的多模态网络 作为对标准 LSTM 的修改,QMN 模型由两部分组成,可以对文本和图像进行交互建模。主要思想是(1)对于每个 LSTM 单元,输出门
与学习到的影响矩阵
组合构成一个新的输出门,描述将要输出什么信息。因此新的输出门包含了上下文信息的影响。(2)将 DM-CNN 构建的文本和视觉向量作为输入,使用扩展的 LSTM 网络获得它们的隐藏状态
、
。(3)通过这种设计,QMN 模型对文本和图像进行局部决策,并使用受量子干扰启发的多模态融合方法在决策级别将它们融合。
6.4 实验
为了验证所提出的 QMN 模型的有效性,作者将模型与许多基线模型在两个数据集 MELD 和 IEMOCAP 上进行了比较。
▲ 表1 模型和对比模型在 MELD 上的表现
如表 1 所示,在 MELD 数据集上,提出的 QMN 模型在所有指标上都取得了最好的分类结果,并且明显优于所有基线。与非分层和分层上下文 h-LSTM 网络模型相比,准确率结果分别提高了 9.1% 和 6.7%。作者将主要改进归功于量子干扰启发的融合策略和量子测量启发的强弱影响模型,它们确保了 QMN 模型可以学习话语内和话语间的交互。
▲ 表2 模型和对比模型在 IEMOCAP 上的表现
如表 2 所示,在 IEMOCAP 数据集上,QMN 模型在准确率方面相对于分层上下文 h-LSTM 网络模型提高了 3.7%,在 F1 分数方面提高 3.3%。作者认为这种增强是由 QMN 和上下文 h-LSTM 网络模型之间的根本差异引起的,这体现在三个方面:a)通过基于密度矩阵的 CNN 进行多模态表示学习;b)强弱交互建模;c)多模态情感标签的决策融合。
6.5 结论
在本文中,作者设计了一个类量子多模态网络(QMN)框架,该框架利用量子理论(QT)的数学形式和长短期记忆(LSTM)网络,对话语内和话语间交互进行建模并识别说话者的情感。主要思想是使用基于密度矩阵的 CNN、量子测量启发的强弱影响模型和受量子干涉启发的多模态决策融合方法。所提出的 QMN 在很大程度上优于广泛的基线和最先进的多模态情感分析算法。
由于 QMN 模型在很大程度上依赖于密度矩阵表示,因此如何更进一步准确地捕获说话者之间的交互并将它们自然地合并到端到端框架中将留给未来的工作。
EMNLP21 Findings:用于联合检测讽刺和情感的多模态量子概率模型
论文标题:
What Does Your Smile Mean? Jointly Detecting Multi-Modal Sarcasm and Sentiment Using Quantum Probability
EMNLP 2021
https://aclanthology.org/2021.findings-emnlp.74/
7.1 简介 讽刺是人类语言中的一种微妙的表现形式,旨在通过夸张、比喻等方式表达批评、幽默或嘲讽的情绪。讽刺表达的字面含义与它所表达的实际含义往往是相反的,这样的表达可以将情感极性反转。作为从人类主观意识的产物,情感表达和讽刺表达天生就是紧密相关的。作者从人类认知角度得到启发,模型在两个任务上的理解可以彼此促进。因此,联合进行讽刺检测和情感分析将会对两个任务都带来提升。
在本文中作者提出了一个量子概率理论(QP)驱动的多任务(QPM)学习框架。QPM 框架主要包含复值多模态表示编码器,类量子融合网络,量子测量机制。与已有方法不同,该工作的核心是在对话环境下的多模态融合的量子启发建模,并通过量子不兼容测量探索任务间相关性。
文章中还给出了 QPM 适用于联合检测讽刺和情感的四点理论证明,可以概括为以下四点:1.量子概率在捕捉人类语言中的不确定性时更具一般性,2.量子干涉体现了非线性多模态融合,3.量子复合系统捕捉对话之间的上下文性,4.量子不兼容测量可以描述多任务之间的相关性。
7.2 模型设计
7.2.1 复值文本和视频编码器
对于文本模态,一句话可以视为单词的集合。量子概率理论是建立在复值希尔伯特空间上的,假设文本希尔伯特空间是由用单词表示的一组正交基态
组成的,从而可以将句子以极坐标形式表示为基态的量子叠加态:
对于视频模态,将图片的低层视觉特征视为基态,视觉希尔伯特空间由这些基态张成。与句子对应的图片由这些基态的量子叠加态来表示。
7.2.2 学习模态内上下文性的量子组合层
量子上下文描述了根据测量环境对粒子的测量结果。这直观的反应了话语的讽刺和情感状态由其语境决定的现象。假设
和
表示对话中两个邻接的句子,每个都是由两个基础词表达出来的:
两个句子
和
的上下文交互构造了复合系统的状态空间
,它被定义为单个状态空间的张量积:
上式展示了由话语组成的组合系统体现了单词之间的相关性,这启发了作者通过以“全局到局部”的方式对上下文进行建模。
本文将一组对话中的最后一句话作为目标语句,模型识别目标语句的讽刺和情感极性。将目标语句视为一个量子系统,将其上下文视为周围环境,基于这个假设提出了学习模态内上下文性的量子组合层。
对于每一个目标语句,假设其有
个上下文语句,那么该目标语句就可以组成
个量子系统。对于
个上下文语句中的第
个上下文,通过计算目标语句与第
个上下文,以及
之前的所有上下文的张量积来获取第
个量子系统。最后每一个量子系统计算与自己的内积,所有的内积结果做加权和,得到一个封装所有
个量子系统的密度矩阵,使用该密度矩阵作为包含上下文信息的一组对话的表示。对于视觉模态,同样先得到
个内积结果,再计算得到相应的图像的密度矩阵表示。
7.2.3 类量子干涉融合层
因此,多模态的概率可以表示为单模态概率的非线性组合,其中干涉项由相位
表示。这样的组合提供了一种更高等级的抽象。
在得到文本和视觉密度矩阵之后,将其展平为两个向量,用于类量子干涉融合。说话人的主观态度可以表示为文本模态和视觉模态组成的类量子叠加态,量子叠加态的平方作为多模态表示的概率分布,该概率分布可以分解为文本模态的概率分布和视觉模态的概率分布还有两种模态的概率分布的干涉项。
7.2.4 量子测量层
讽刺和情感是紧密交织在一起的,对一个任务的判断可能会影响到另一个。在量子理论中,一个量子系统的属性(例如,话语的讽刺和情感信息)可以通过量子测量结果的概率分布来描述。在 QPM 模型中,两个不同的分支共享多模态表示,每个分支上进行量子不兼容测量,来获取讽刺和情感的概率特征。
7.2.5 全连接层
讽刺和情感概率特征通过全连接层和 softmax 分类器获取讽刺和情感的预测结果。 使用两个带 L2 正则化的交叉熵函数作为讽刺和情感的损失函数。
▲ 表1 对比实验结果
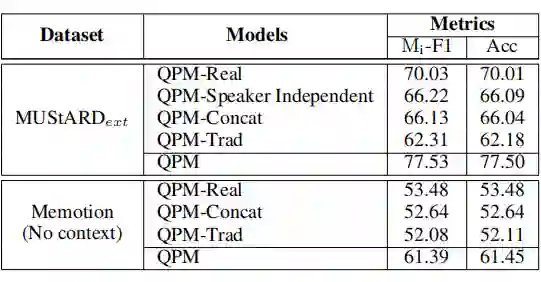
Text-QPM 和 Image-QPM 是 QPM 的单模态变体模型,表现不佳,这表明了文本的或视觉的模态信息单独处理多任务讽刺和情感任务有一定的局限性。和其他模型的对比结果可以表明,所提出的 QPM 框架利用了 QP 在模拟人类语言中不确定性方面具有优势。作者将主要改进归功于类量子融合网络和量子测量机制,这确保了 QPM 可以对模态内上下文和模态间交互进行建模。
7.3.2 模态与任务对比实验
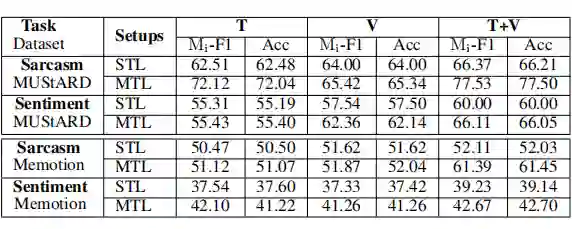
对于讽刺检测,MTL 在文本模态和双模态实验中效果优于 STL。原因是视觉讽刺检测涉及更高层次的抽象和更多的主观性。对于情感分析,MTL 和讽刺任务在一起进行时,在所有模态上效果都比 STL 更好。这表明讽刺通过知识来辅助情感分析,反之亦然。基于 QP 的 MTL 框架可以学习两个任务之间的相互依赖性,并提高模型性能。
7.3.3 消融实验
▲ 表3 消融实验结果
作者还进行了消融实验,结果显示量子不兼容测量对于模型的表现贡献最多,量子不兼容测量有效的捕获了任务之间的关联性。贡献度排在量子不兼容测量之后的是基于量子干涉的多模态融合和量子上下文建模,复值表示也起到了很重要得作用,它捕获了人类语言中的不确定性。
7.4 结论
作者提出了一个量子概率驱动的多任务学框架。主要思想是将话语视为一个复值向量。话语之间的上下文交互和跨模态的相关性是通过量子组合和量子干涉来建模的。再进行量子不兼容测量来产生概率分布。实验结果证明了 QPM 的有效性。
展望
这些模型取得了比较好的效果,也有很强的可解释性。然而受到理论应用和软硬件设施的限制,量子理论驱动的多模态情感分析模型的潜力依然还没有被完全释放。 例如,量子理论驱动的模型很大程度上依赖于对状态向量、密度矩阵等概念的运算,而这些运算往往需要很大的计算资源; 此外,诸如量子干涉、量子纠缠、量子不兼容性的概念,虽然已经被应用到了许多工作中,但是仍缺乏可以涵盖这些概念的,能将量子形式化理论应用更加充分的模型。
复值表示是量子理论中不可缺少的一个概念,已有的量子启发的工作更多的是使用波函数和极坐标方程的方式对复值进行表示,而所使用的深度学习框架直到最近才支持了复值的应用,所以如何真正有效利用复值表示也是值得探索的方向。
[1] Gkoumas D, Li Q, Dehdashti S, et al. Quantum Cognitively Motivated Decision Fusion for Video Sentiment Analysis[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(1): 827-835.
[2] Gkoumas D, Li Q, Yu Y, et al. An entanglement-driven fusion neural network for video sentiment analysis[C]//Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence. International Joint Conferences on Artificial Intelligence Organization, 2021: 1736-1742.
[3] Li Q, Gkoumas D, Sordoni A, et al. Quantum-inspired Neural Network for Conversational Emotion Recognition[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(15): 13270-13278
[4] Zhang Y, Song D, Li X, et al. A quantum-like multimodal network framework for modeling interaction dynamics in multiparty conversational sentiment analysis[J]. Information Fusion, 2020, 62: 14-31.
[5] Liu Y, Zhang Y, Li Q, et al. What Does Your Smile Mean? Jointly Detecting Multi-Modal Sarcasm and Sentiment Using Quantum Probability[C]//Findings of the Association for Computational Linguistics: EMNLP 2021. 2021: 871-880.
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读 ,也可以是学术热点剖析 、科研心得 或竞赛经验讲解 等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品 ,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬 ,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱: hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02 )快速投稿,备注:姓名-投稿
△长按添加PaperWeekly小编
🔍
现在,在「知乎」 也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」 订阅我们的专栏吧