![]()
本文约4000字,建议阅读10分钟。
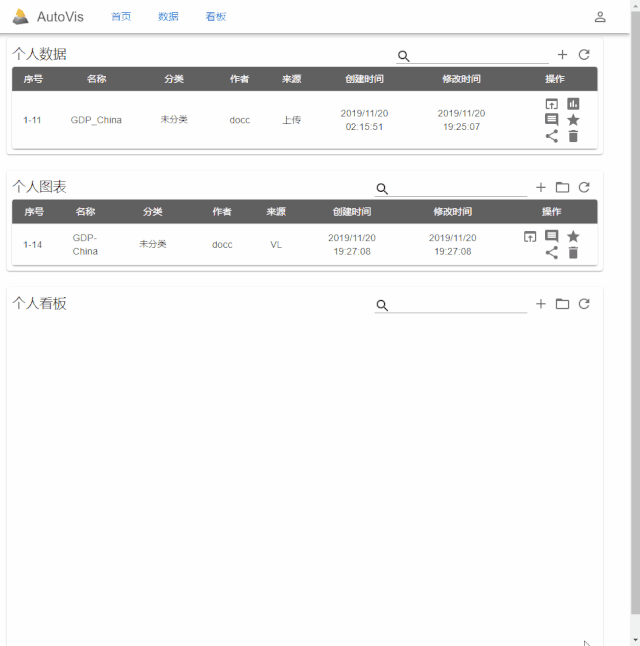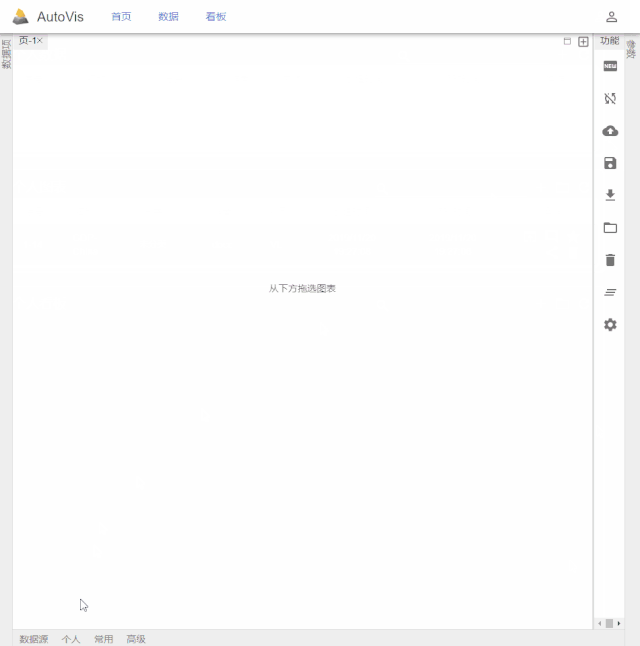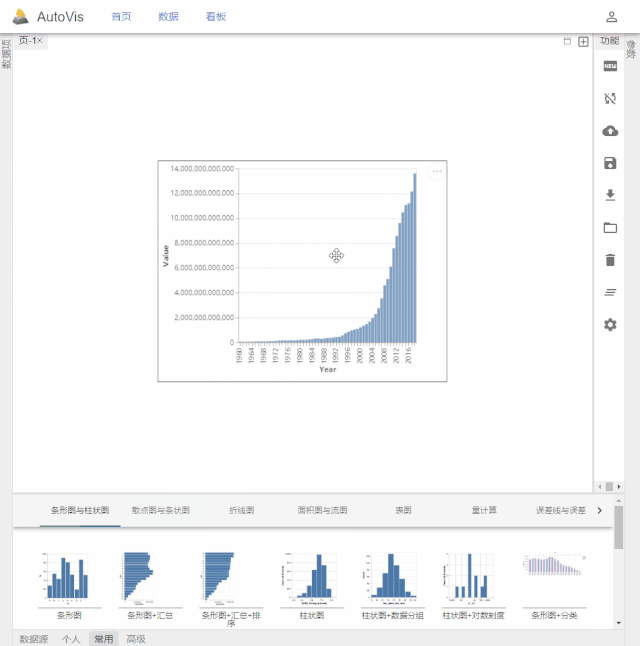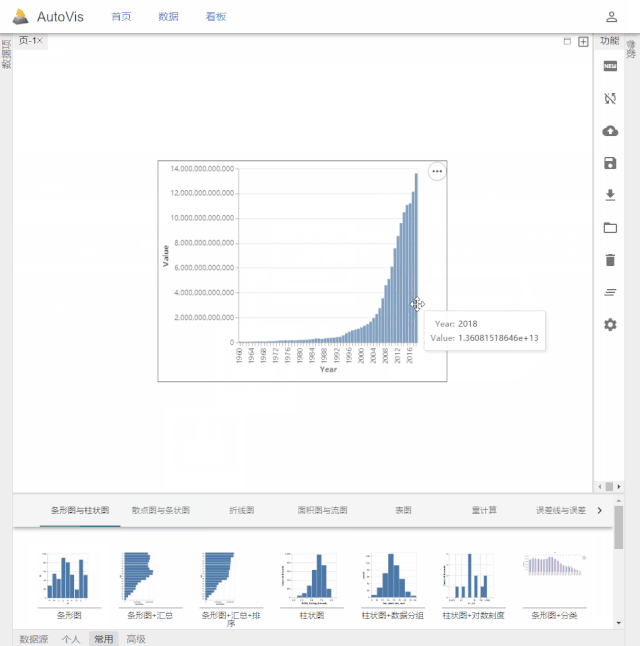
本文从大数据应用出发,讨论数据可视化在大数据时代所面临的一系列挑战,并重点介绍AutoVis针对这些挑战所做尝试及其体系架构、关键技术和功能特点。
简介:
AutoVis是清华大学“大数据系统软件国家工程实验室”自主研发的大数据可视化设计框架
。
面向大数据应用,特别是工业场景,此框架提供了一种新的数据生成图表和看板的方式,具有表达能力丰富、简单易用、高可扩展、高效率等特点,已应用于中车四方车辆有限公司、石家庄天远科技集团有限公司等工业企业。
“看见”是人类的基本需求,也是人类探索未知的重要途径。2019年,多个机构通过捕捉射电波,收集大量数据,帮助人类第一次“看见”黑洞。数据可视化使得人们透过数据“见所不见”,成为人与数据之间的“桥梁”。作为第四范式“数据密集型科学发现”的组成部分,数据可视化已广泛应用于不同的科学研究领域。伴随着计算机通用化、信息时代、互联网时代的发展,数据可视化逐渐应用于人们生活的各个领域。在大数据时代,数据可视化应用更加广泛,并面临诸多新的挑战。
大数据时代,数据应用需求多种多样,数据特点亦发生本质上的变化。
智能硬件的丰富与普及,互联网、物联网、移动化、智能化的浪潮,给数据可视化带来新的机遇与挑战。
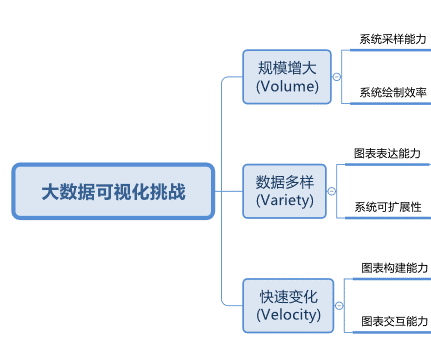
如下图所示,我们简要梳理了数据可视化(系统)在大数据应用中所面临的一些关键问题,例如数据规模增加,屏幕像素空间有限,数据可视化系统的数据采样能力与绘制效率问题突出。
数据多样的特点要求数据可视化系统不仅需要支持更多的可视化方法,也要具有良好的系统可扩展性以适应不断出现的新数据、新需求。
数据快速变化的特点要求数据可视化系统能够快速构建新的图表,及时捕捉数据变化。
由于不同使用者所关注数据特征的差异及数据探索的需求,可视化图表的交互性在大数据时代将更加重要。
![]()
大数据时代数据可视化(系统)所面临的一些挑战
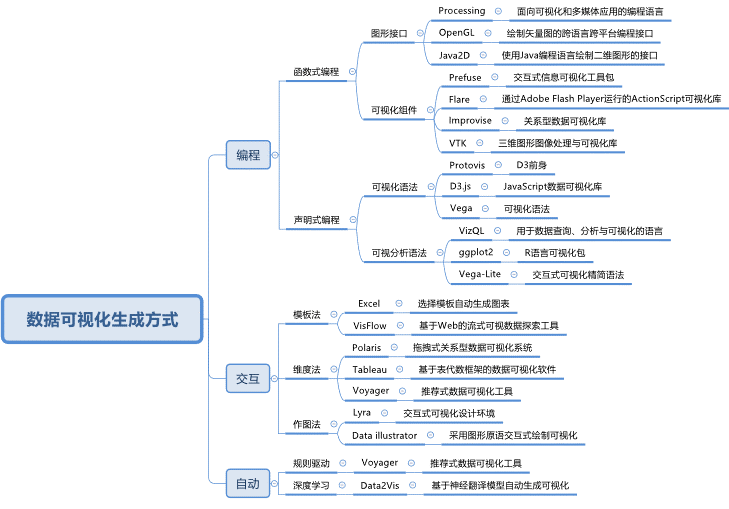
为了探究数据可视化是否满足大数据应用场景,我们梳理了相关编程工具及系统的研究与应用现状,如下图所示,数据可视化生成方式可以分为编程、交互与自动生成三种。面向不同的应用领域,出现了众多可视化编程工具,例如常用的OpenGL、VTK、D3.js。编程方式的优点在于丰富的表达能力,缺点在于需要使用者具有编程经验。交互方式提供了一种不需要编程的可视化生成方式,例如PowerBI、Tableau、Qlik,推动了数据可视化工具的普及,其在表达能力方面有所欠缺。近些年,一些学者提出了根据数据自动生成图表的方法,其优点是不需要用户具备数据可视化背景,缺点是自动生成的图表类型有限,未能体现使用者的个性化需求。
![]()
数据可视化编程工具与系统
梳理大数据可视化所面临的挑战与相关进展,可见其中有许多问题亟待解决,例如系统数据采样能力、表达能力、可扩展性、图表快速构建能力以及交互能力。下面介绍我们的相关工作。
AutoVis是清华大学 “大数据系统软件国家工程实验室”针对大数据场景自主研发的数据可视化设计框架。
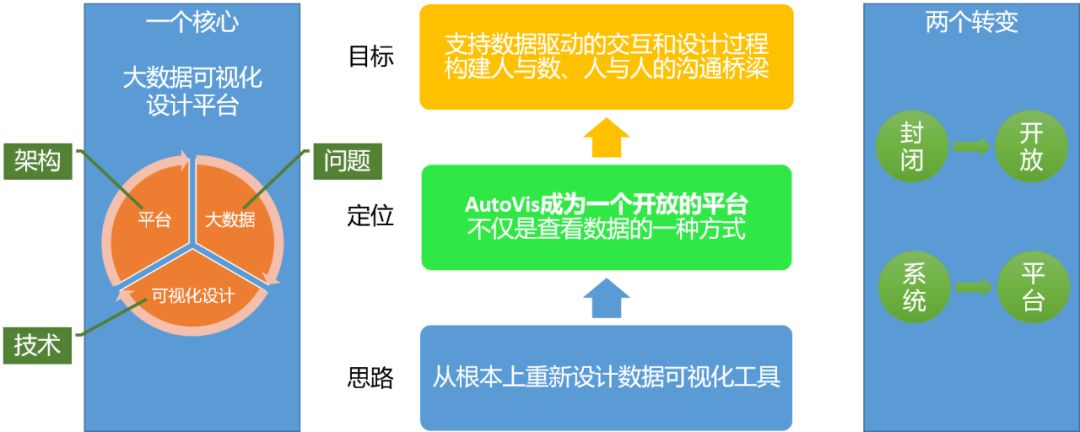
如下图所示,围绕大数据所带来的挑战,采用可视化设计的技术路线,基于平台化架构思想,我们尝试设计新的大数据可视化工具,其定位是成为一个开放平台,目标是支持数据驱动的交互和设计过程,构建人与数、人与人沟通的桥梁。
![]()
AutoVis基本思想
针对上述大数据可视化面临的挑战,我们尝试从12个方面探索应对的方法,如下图所示。针对系统所需的采样能力,提出了一种新的流式时序数据高效采样方法;实现了一种数据特征提取框架,支持扩展不同的特征提取方法。针对系统绘制效率,我们一方面采用了数据压缩传输,将数据通信量降低到非压缩通信的三分之一,另一方面,结合图表LAZY更新策略,着力降低图表非必要更新。针对图表表达能力要求,提出了一种新的图表模板化与交互式编辑方法,目前提供267种图表模板,覆盖常用数据可视化方法。针对系统可扩展性要求,提出一种平衡易用性与表达能力的图表模板扩展方法;设计实现了图表扩展实时反馈技术。针对图表构建能力的要求,设计实现了图表参数自动化填充技术,实现图表的秒级构建与响应,分钟级构建一个看板。针对图表交互能力的要求,实现了常用的图表交互方法;提出一种新的多图表联动关系自动发现技术,自动化支持多图表钻取。
![]()
AutoVis在应对大数据可视化挑战中的探索
动态数据采样与可视化:
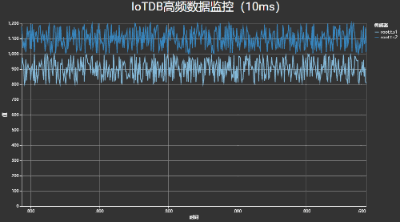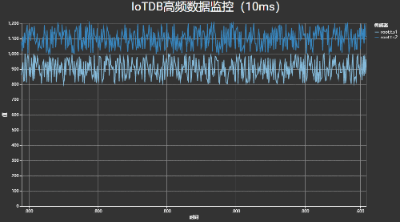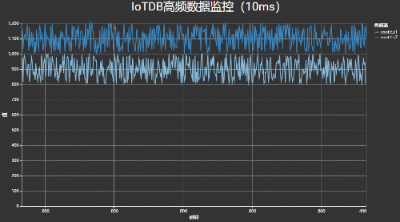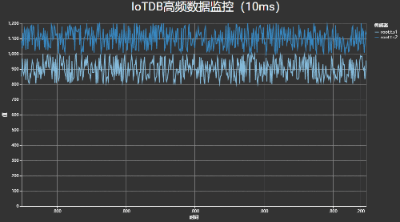
针对大数据场景中数据更新频繁和数据规模较大的挑战,我们提出了一种动态分桶与层级采样相结合的流式数据采样框架,实现了百万点的毫秒级查询,满足高频数据的可视分析与监控需求。
如下图所示,其中数据写入与图表刷新速度均达到了100次/秒。
![]()
高频时序数据可视化
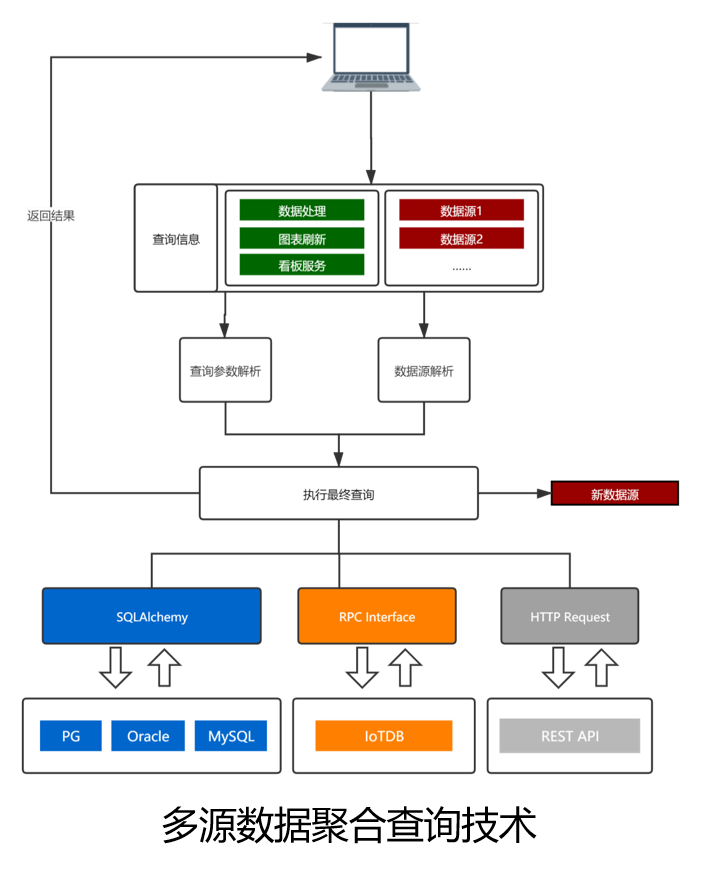
多源数据聚合查询技术:
针对数据检索与处理耗时长的挑战,我们设计实现了一种数据聚合查询技术,通过将常用数据查询与过滤操作映射成数据的SQL语句,将更多的数据过滤操作在数据库层完成。
有助于显著提升数据处理速度,提高数据可视化的效率与交互性。
![]()
图表模板编辑与管理技术:
针对已有可视化软件中图表模板有限,可扩展性弱,以及通过编码方式定义新的图表模板需要大量的人力资源和时间成本,复用性弱等挑战,我们设计了一种新的可扩展图表模板分类与管理技术以及交互式编辑工具。我们选择使用可视化编程语言Vega和Vega-Lite,并在其示例的基础上进行扩展,目前形成了267种图表模板。另外,提供了选项配置、参数扩展与自由配置三种自由度从低到高的图表目标交互式编辑方式,着力同时满足图表易用性、表达能力与可扩展性的需求。
图表参数自动填充技术:
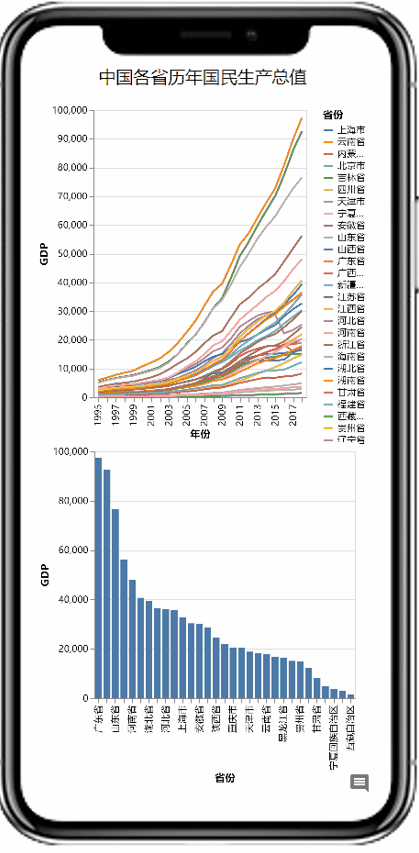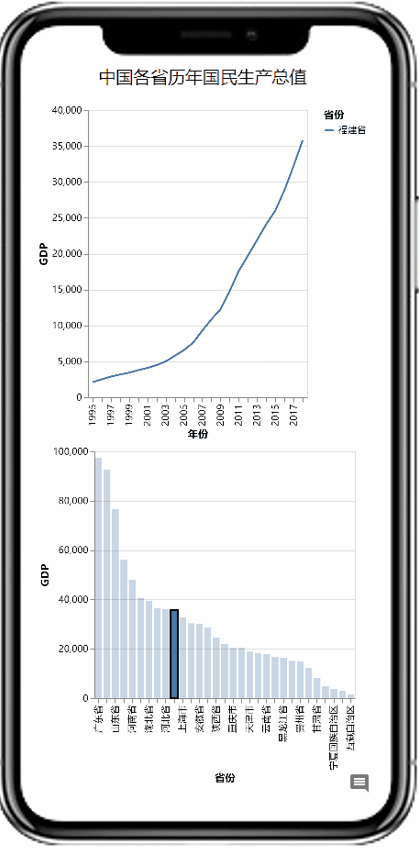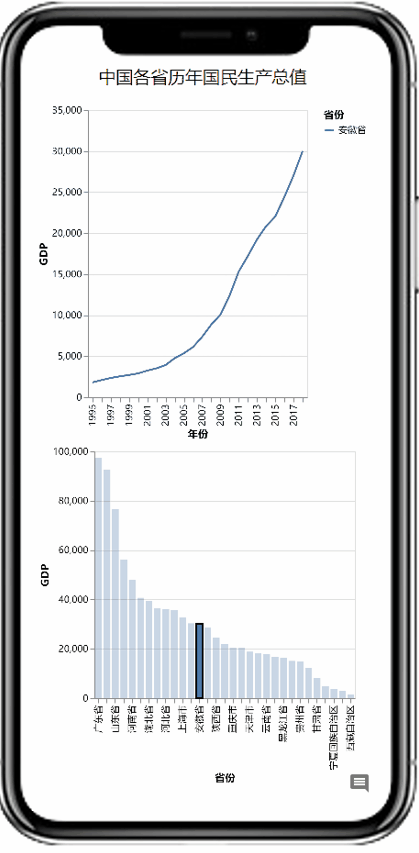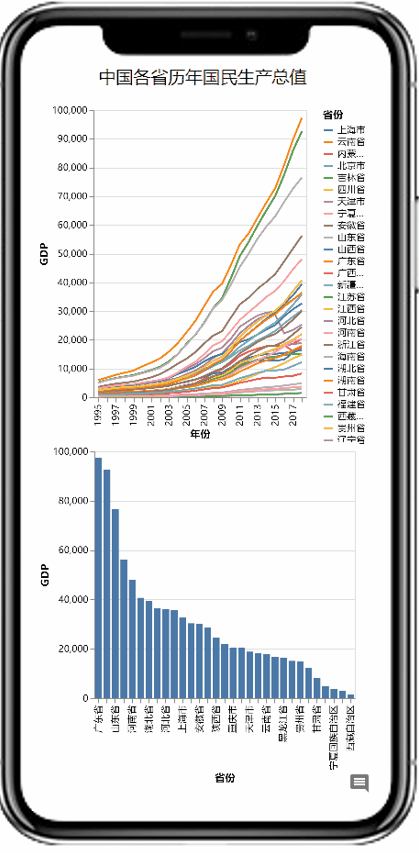
AutoVis提供了一种自动填充图表参数快速生成图表的技术。使用者在打开数据后,拖选图表模板,系统将根据数据信息及模板配置自动填充模板参数,实现可视化图表的一键生成。同时,AutoVis提供了即时响应的图表参数编辑技术,如果自动填充的结果不满足个性化需求,使用者可以很方便地修改图表参数,如下图所示。值得强调的是,AutoVis系统实现了参数推荐与自动补全,努力减少使用者修改参数所需的交互次数。
![]()
AutoVis快速生成图表
看板模板描述语言与编辑工具:
看板是可视化设计工具生成的主要内容,为了在达到图表模板化、看板配置通用化目标的同时,满足跨平台和跨终端等常用需求,我们设计实现了一种面向可视化看板的描述语言,实现看板的轻量灵活定义。
同时,AutoVis提供了一种所见即所得的看板编辑工具,使用者可以采用类Visio画图的交互方式,直观调整看板图表大小与布局。
另外,AutoVis还支持面向不同终端的针对性看板设计,方便使用者设置适用于特定终端的可视化看板。
![]()
AutoVis设计看板
运行时看板交互技术:
大数据时代,使用者对于数据的关注多种多样,不再满足于单向呈现数据的图表,希望通过交互发掘所关注数据特征,满足特定需求,这时需要提供合理的交互方式。
AutoVis对于单个图表提供了常用的交互手段,特别地,我们设计实现了一种多图表联动关系自动发现技术,使用者在定义看板时,不需要手工定义图表之间的联动关系,即可实现图表之间的联动与数据钻取。
图数据布局与可视化探索:
现实生活中不同的关联关系越来越普遍,例如人与人、人与商品,知识图谱的应用亦越来越普遍。
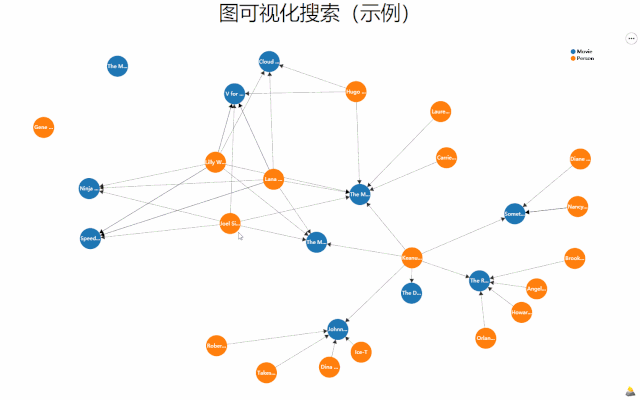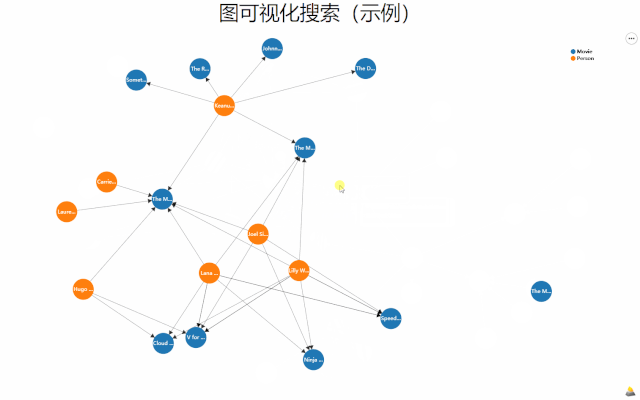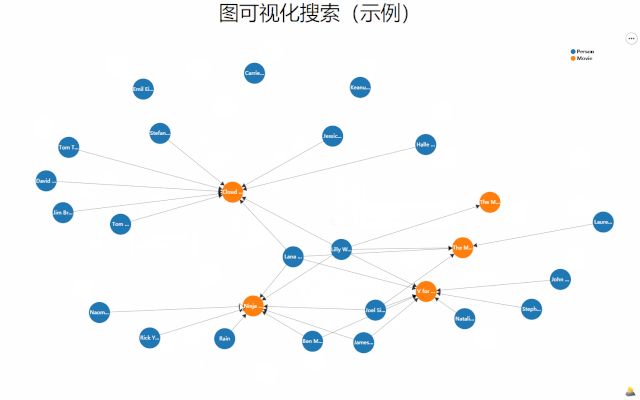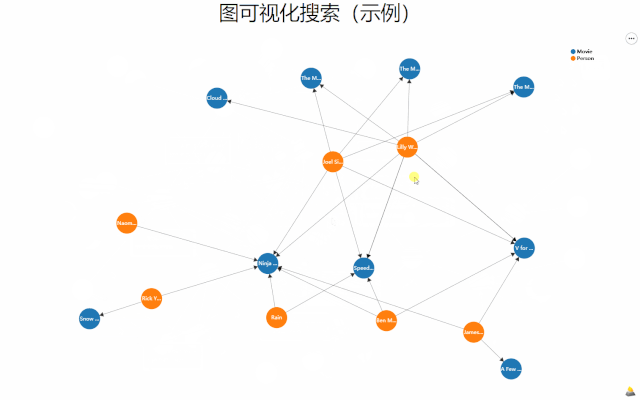
如何有效地与图数据进行交互,AutoVis实现了一种新的图布局算法MGLA以及可视化探索方法。
MGLA算法实现了多子图情况下关键节点与边突出的保结构布局,使用者可以通过鼠标标记关注节点,系统亦能够根据不同的搜索条件自动解析所关注节点。
![]()
图数据布局与可视化探索
大数据时代数据“无处不在”,这要求我们实现数据“随处可见”。
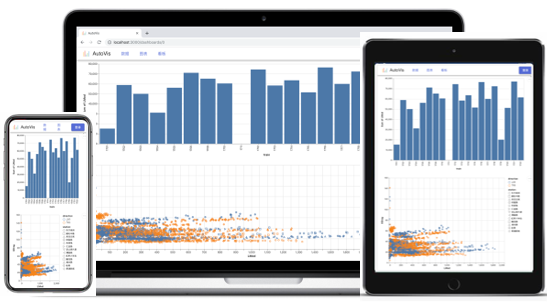
为此,AutoVis支持跨平台与跨终端,如下图所示,兼容常用操作系统、主流浏览器以及不同屏幕分辨率的终端设备。
此外,为了满足企业使用者的需求,AutoVis还实现了钉钉企业软件小程序,帮助企业实现数据驱动的共享、会商与决策。
![]()
AutoVis的跨平台、跨终端特性
![]()
AutoVis移动端看板示例
大数据时代数据可视化作为人与数据的桥梁,将发挥越来越重要的作用,经过数十年发展的数据可视化如何迎接新的机遇与挑战,值得大家的共同探索。
本文简介了我们在这方面的尝试,以希抛砖引玉。
如果读者对于AutoVis有兴趣,
http://101.6.240.89:18080/
;
https://github.com/eeyshen/AutoVis-issues反馈问题与需求;
欢迎读者共同研发,联系邮箱autovis@126.com。
沈恩亚,国防科技大学计算机科学博士,清华大学博士后,主持研发“清华数为”大数据可视化平台,长期从事数据可视化、可视分析和人机交互等方面的研究。曾经主持或参与多项863、973、科技重大专项、国家重点研发计划等项目,其中作为骨干完成的“极大规模并行可视计算系统”获得全军科技进步奖。在TVCG、VC等期刊和会议上发表论文10余篇,申请专利10余项。曾获得中国虚拟现实大会最佳论文,全国高性能计算学术年会最佳论文提名等。
——END——
![]()
![]()