【CVPR2021】通过上下文和运动解耦的自监督视频表示学习

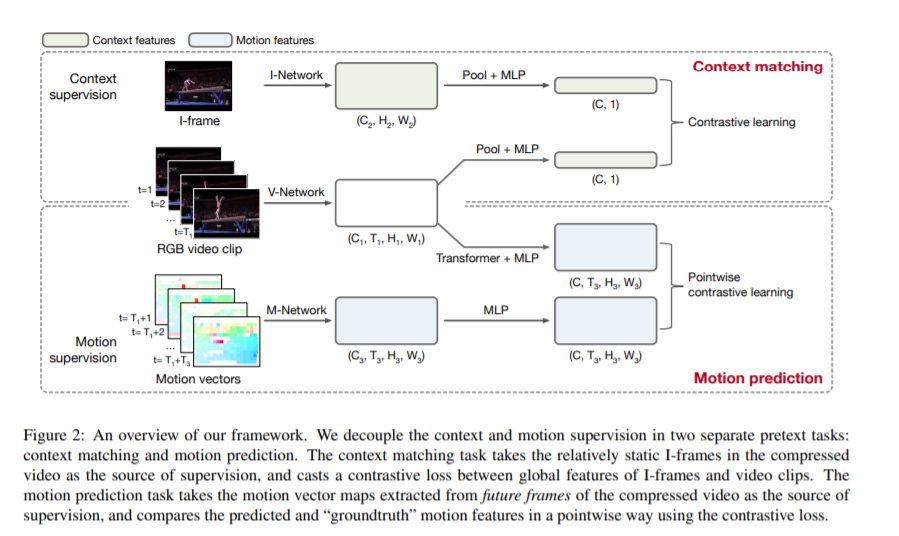
视频行为理解中的一个核心难点是「场景偏差」问题。比如,一段在篮球场跳舞的视频,会被识别为打篮球,而非跳舞。我们提出一种自监督视频表征学习方案,通过直接在代理任务中显式解耦场景与运动信息,处理「场景偏差」难题。值得注意的是,本方案中,解耦的场景与运动信息均从「视频压缩编码」中提取得到。其中场景由关键帧 (keyframes) 表示,运动由运动向量 (motion vectors) 表示,二者提取速度是光流的100倍。基于该解耦方案预训练的视频网络模型,迁移至行为理解和视频检索两项下游任务,性能均显著超过SOTA。
https://www.zhuanzhi.ai/paper/591341f12cfa1759edac18c262ce5a31
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“CMDV” 就可以获取《【CVPR2021】通过上下文和运动解耦的自监督视频表示学习》专知下载链接



登录查看更多
相关内容



相关VIP内容
相关资讯