实例对比 Julia, R, Python,谁是狼语言?

目标受众:对Julia感兴趣的人
阅读时长:本文大约800字。全文读完可能需要这首歌的时间
狼,就是比狠,更狠一点!
比京香还火?Julia到底是个什么来头
最近突然火了一门语言叫Julia。有多火呢?
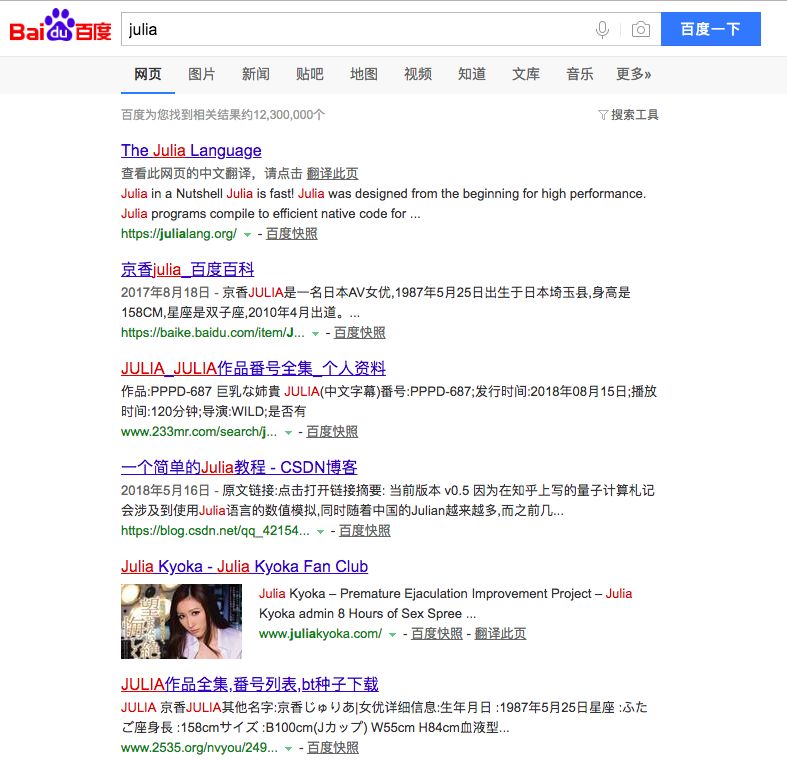
我们知道,百度首页的结果一定是广大人民群众最关注、最为熟知的内容。
而如此一门小众的语言,居然能盖过著名女影星,登上搜索结果第一条,可见它的火爆程度。
就此事件,记者询问了身边的程序员。程序员纷纷表示可以给记者分享珍藏在硬盘里,Julia 历年来出演的所有影片。

所以记者认为有必要解释一下 Julia 到底是什么:

这门语言很年轻,诞生至今也不到10年,前段时间才正式进入1.0版本。
所以大家下次看到招聘要求10年Julia开发经验的,绝对不要去。
Julia,R 和 Python 谁的势力大
因为 R 语言设计的初衷就是应用在科研领域。所以这次的三方势力比拼,我们限制在数据研究领域:
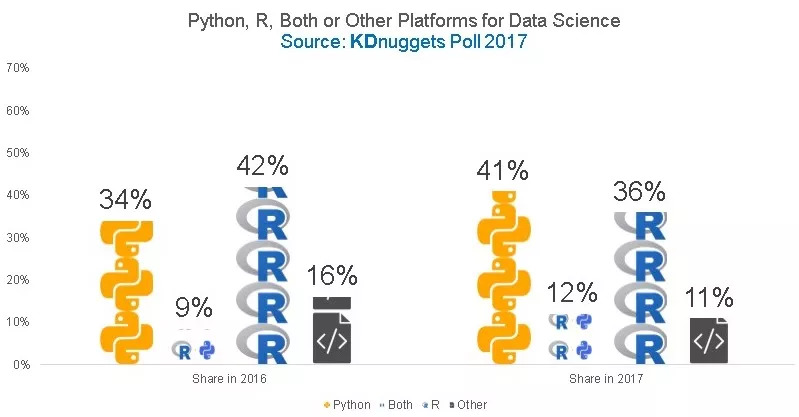
根据上图 KDnugget 的调查显示,2016年的时候,R 占据了 42% 的份额成为 dalao,Python 紧随其后成为 dalao 的小老弟,Julia 根本就默默无闻。
没想到短短一年时间,双方的位置就互换了。然后 Julia 还是保持了默默无闻。
可见即使在特别垂直的领域,Python 这种粘合剂语言配合强大的第三方库,也是拥有恐怖的战力。
Julia,R 和 Python 谁更狠一点?
背景介绍
就此问题,人工智能头条记者找到了戴卓嘉。他是一名拥有10年金融开发经验的数据科学家、全栈开发者、信用风险模型团队leader。并获得授权,翻译他的文章《Julia vs R vs Python: simple optimization》。
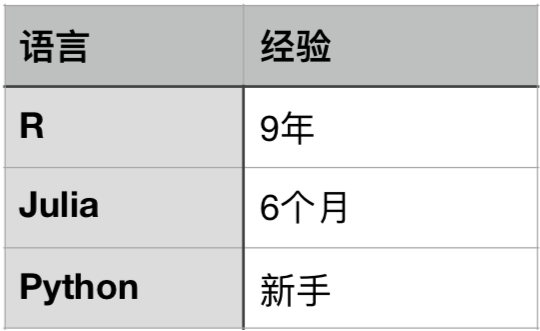
戴卓嘉对三种语言的熟悉程度分别是:
有人做过测试,不依赖第三方装备的情况下,在计算比10⁵更小数的时候 Python 还是要比Julia快的。从10⁵开始,Julia 的速度就比 Python 比更快还快了。
这也是为什么 Julia 的布道者 Chris Rackauckas 说,在处理10秒内就能解决的小问题时,并不能体现出 Julia 的优势。而一旦问题复杂到一定程度,Julia 的优势就体现出来了。
本次实例,尝试使用三种语言,分别去优化一个似然函数。属于比较小的优化问题,可能在性能上的差距不是很明显。但在解决问题的过程中,还是很好的体现了三者之间的优劣势。
接下来,我们就开始这段优化吧。
问题描述
指定一个观察序列 Q₁, Q₂, Q₃...Q៷,我们的目标是找出可以优化下面这个似然函数的参数μ和σ
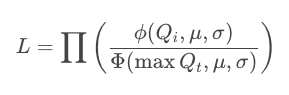
通常我们是去优化对数似然

在统计学上,这是截断正态分布的最大似然估计(MLE)。
使用 Julia
利用Optim.jl对符号的支持,可以直接使用希腊字母μσ作为变量名。

在下面硬编码了准备在MLE估计中使用的 Q_t 的值

最终输出效果,看起来非常舒服,格式经过精心的排版,描述也经过了精心的处理。完美的支持数学公式显示。
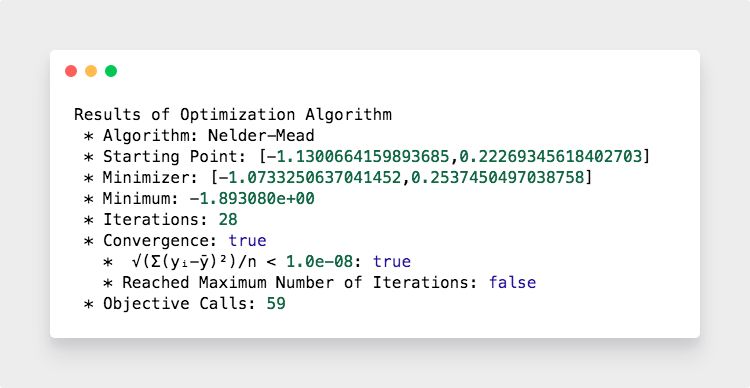
评分:

使用 R
使用 truncnorm包来处理截断正态
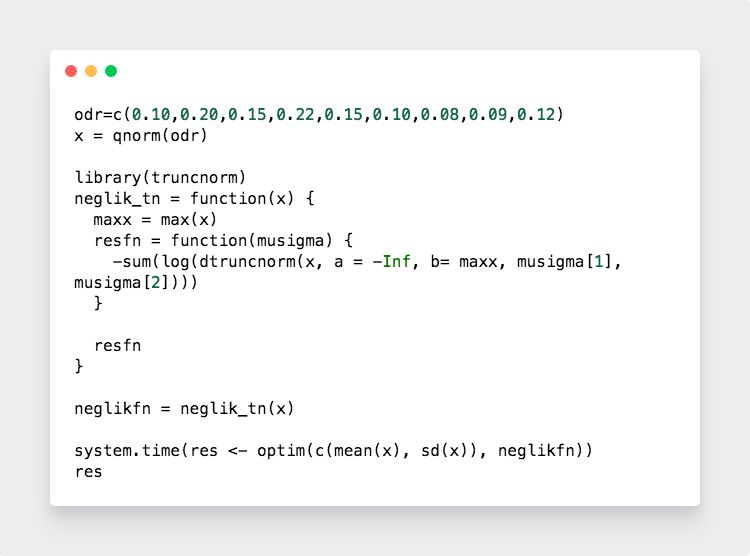
输出结果显示
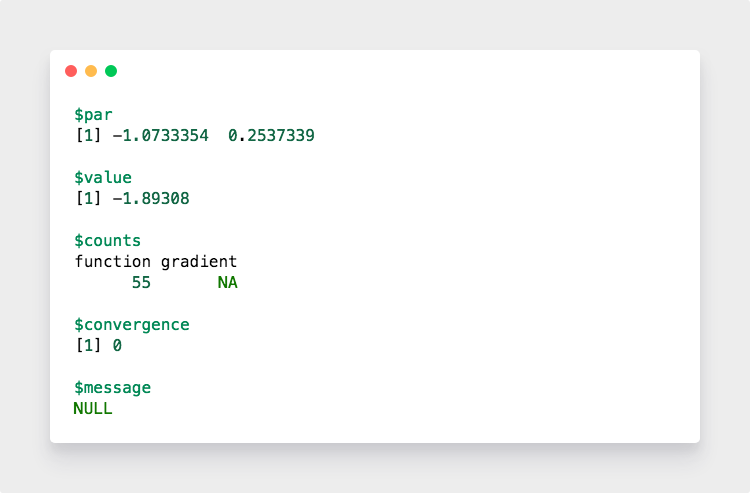
只能用一个词形容:简单粗暴!
评分:

使用 Python
代码
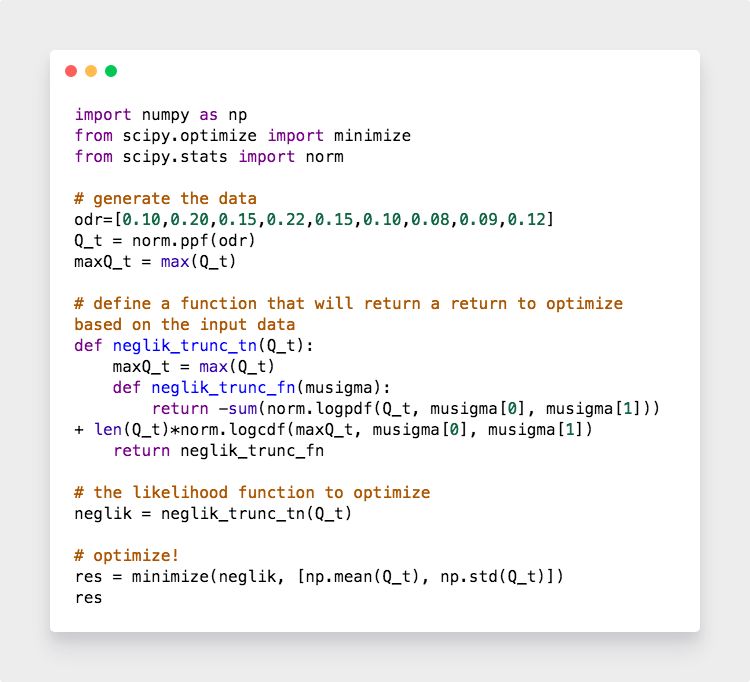
输出结果显示
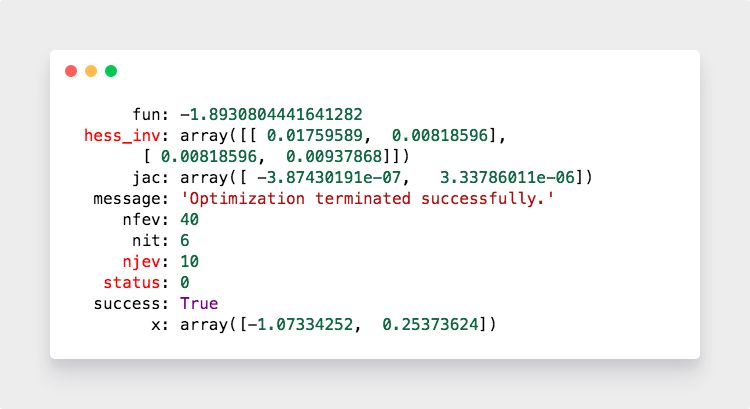
虽然比 R 是强了不少,但跟 Julia 还是没法比。而且不支持数学公式
评分
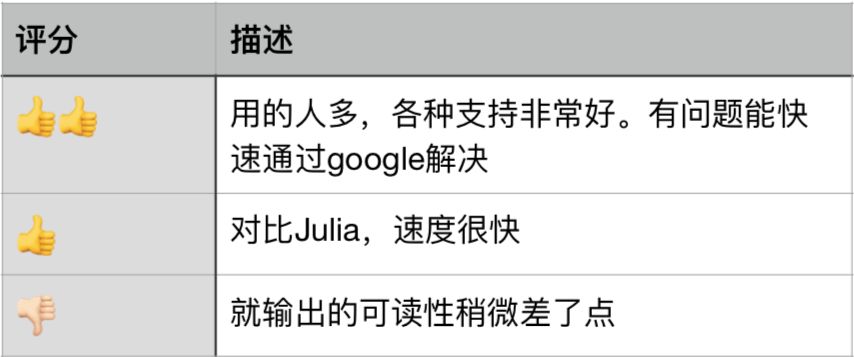
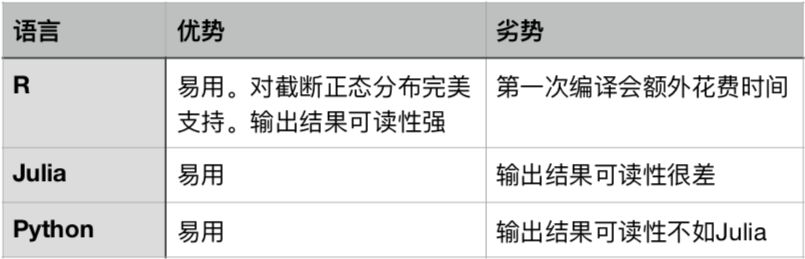
最终用一个表格来总结一下此次对比结果:

点击“阅读原文”学英语
👇👇👇