图灵奖得主Jack Dongarra:高性能计算与AI大融合,如何颠覆科学计算

来源:智源社区
本文为约3530字,建议阅读7分钟
本文介绍
了在第十届全国社会媒体处理大会(SMP 2022)上,图灵奖得主Jack Dongarra梳理的高性能计算近年最主要的应用和发展。
导读:在过去的三十年间,高性能计算(HPC)取得了突飞猛进的进展,在科学计算等领域发挥着重要的作用。而当前,云计算和移动计算正逐渐成为主流的计算范式,与此同时深度学习等AI方法所带来的颠覆性影响,给HPC与AI的融合带来了新的挑战和机遇。在第十届全国社会媒体处理大会(SMP 2022)上,图灵奖得主Jack Dongarra梳理了高性能计算近年来最主要的应用和发展。
高性能计算广泛应用于科学的“第三极”

当前,高性能计算(HPC)方法广泛地应用于科研仿真,而仿真也被誉为科学研究的“第三极”。一直以来,科学研究和工程研究通常采用基于理论和实验的范式。然而,这两种方法存在很多固有的限制,比如,通常建造大型的风洞非常的困难,试验飞机引擎与飞鸟碰撞的成本将非常昂贵,等待观察气候变化将会非常的耗时与缓慢,新药品和武器等试验将会非常的危险等等。此外,我们有时无法通过实验来研究某些问题,比如研究星系运动和研发新药品等。因此,研究者们逐渐利用科学计算手段进行仿真,研究此类问题。这种方法通常基于已知的物理规律和数字计算方法,通过高性能的计算机系统仿真相应的物理现象。
算力之巅——超级计算机
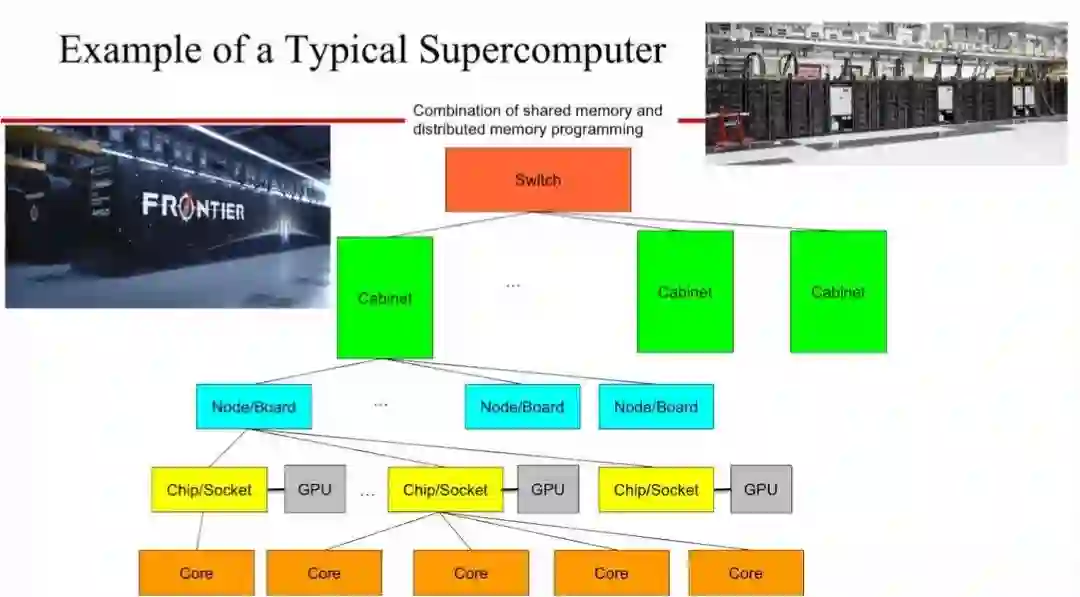
人们一般基于商品化的成熟芯片构建典型的超级计算机,在一个板卡上集成多个芯片,每个芯片中都拥有多个核心(Core)。同时,通常会在板卡上使用图形处理单元(GPU)等作为增强算力的加速器。在同一机架柜上,不同的板卡通过高速的链接进行通信,不同的机柜通过交换机(switch)互联在一起,这样组成的一个超级计算机可能需要占用两个网球场那么大的空间。

这样的超级计算机的并行性非常之高,通常采用的是分布式内存和「MPI+Open-MP」的编程范式。与数据的浮点计算相比,在HPC系统不同部分之间数据的移动非常的昂贵。现有的超级计算机支持包括64,32,16,8等位宽的不同的精度的浮点计算。

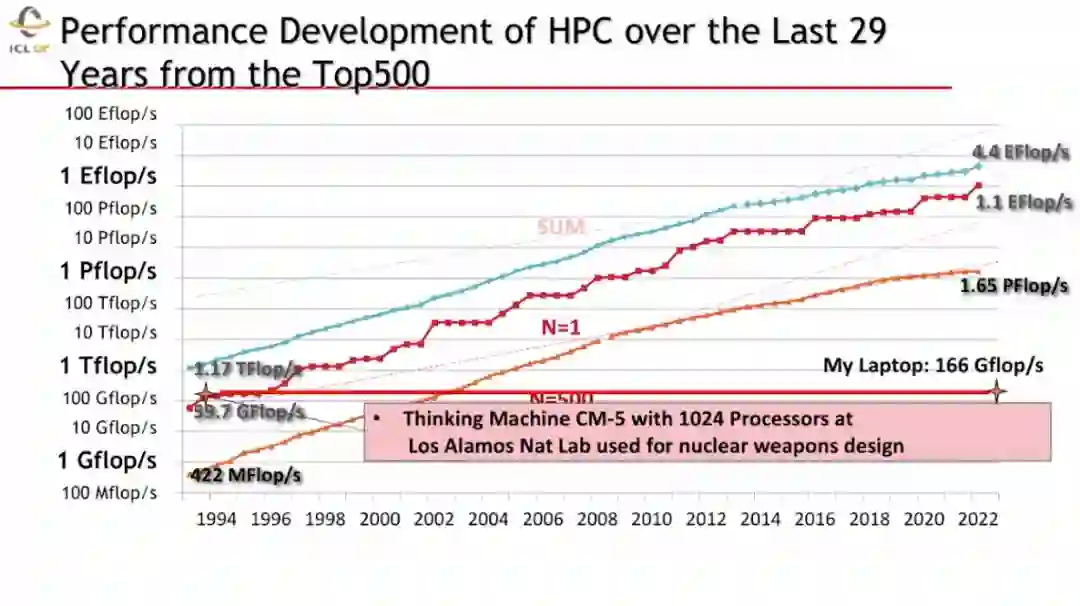
当前,最快的超级计算机能够提供Exaflop/s级别(1018)的算力。这是一个非常巨大的数值,如果每个人一秒钟完成一次乘加计算,那么,需要全球所有人花费四年的时间才能完成超级计算机一秒钟完成的计算。同时,为了维持这样的超级计算机的运转,每年需要花费千万美元的电费。

HPC和ML计算有着相似又不同的特性。HPC属于数字计算密集型的,通常输入非常有限的数据,经过非常大量的数字计算,输出大量的数据。而在ML领域进行高性能数据处理(HPDA),通常需要输入大量的数据,输出的却是相对比较少的数据。两者使用的数据精度也非常不同,在科学仿真等高性能计算场景下通常使用64比特浮点数据,而在机器学习场景下会使用16比特浮点数据。

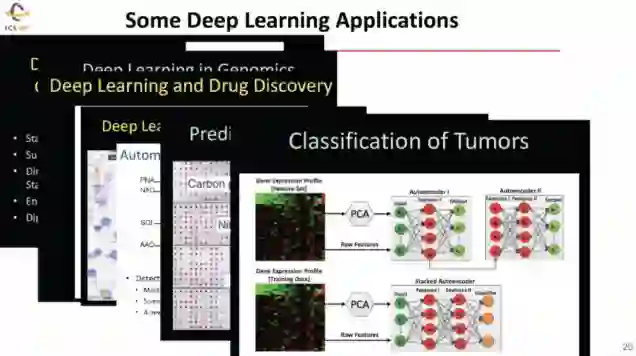
AI在科学研究的诸多不同的方面发挥着非常重要的作用:AI能够在不同领域辅助科学发现,提高计算体系结构的性能,以及在边缘管理和处理大量数据。因此,在科学计算领域机器学习等技术被应用到气候学、生物学、药学、流行病学、材料学、宇宙学甚至高能物理等等很多学科以提供增强的模型和更先进的仿真方法。比如,用深度学习辅助药品研发、预测流行病以及对基于医学影像的肿瘤进行分类等等。

科研仿真和AI计算可以非常有效地进行联合,因为二者都需要模型和数据。通常,仿真使用(数学)模型产生数据,(AI)分析使用数据来生成模型。使用分析方法得到的模型和其他的模型一起可以被用到仿真中去;仿真产生的数据和其他来源的数据一起可以被用于分析。这样就形成了一个相互促进的良性循环。
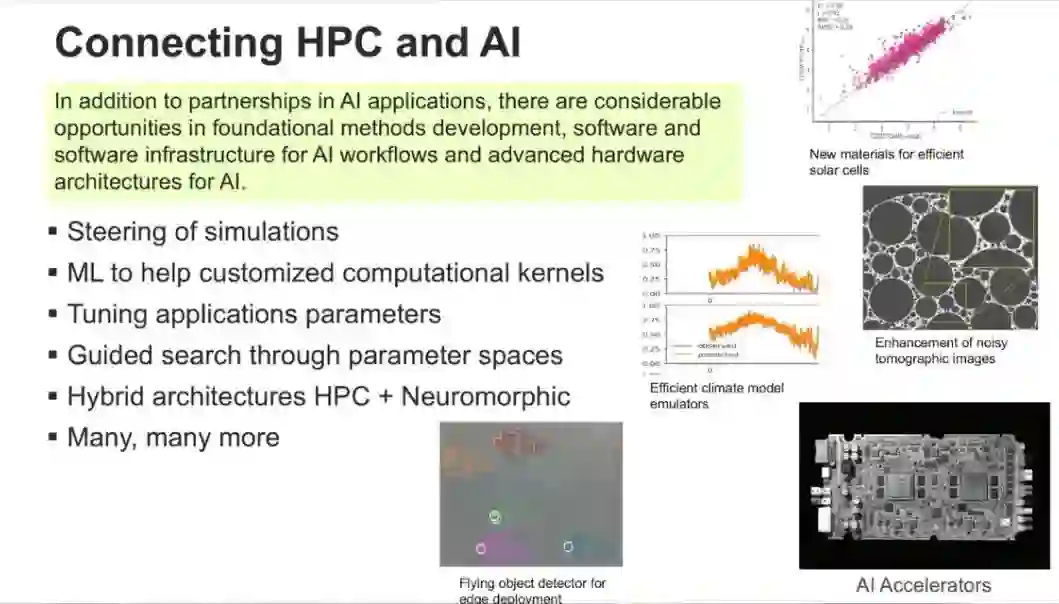
除了在具体的应用领域相互补充之外,HPC&AI在基本开发方法、软件与软件基础设施和AI硬件架构等领域都有非常多的联系。同时也将二者更广泛地联系起来,比如:AI可以用来引导仿真、更快地调整仿真应用的参数、提供定制化的计算核函数,以及将传统的HPC和神经形态计算相结合等很多内容。AI&ML具有颠覆性的影响力,正如通常所说:「AL&ML并不会代替科学家,但是使用AI&ML工具的科学家会代替那些不使用这些工具的科学家」。
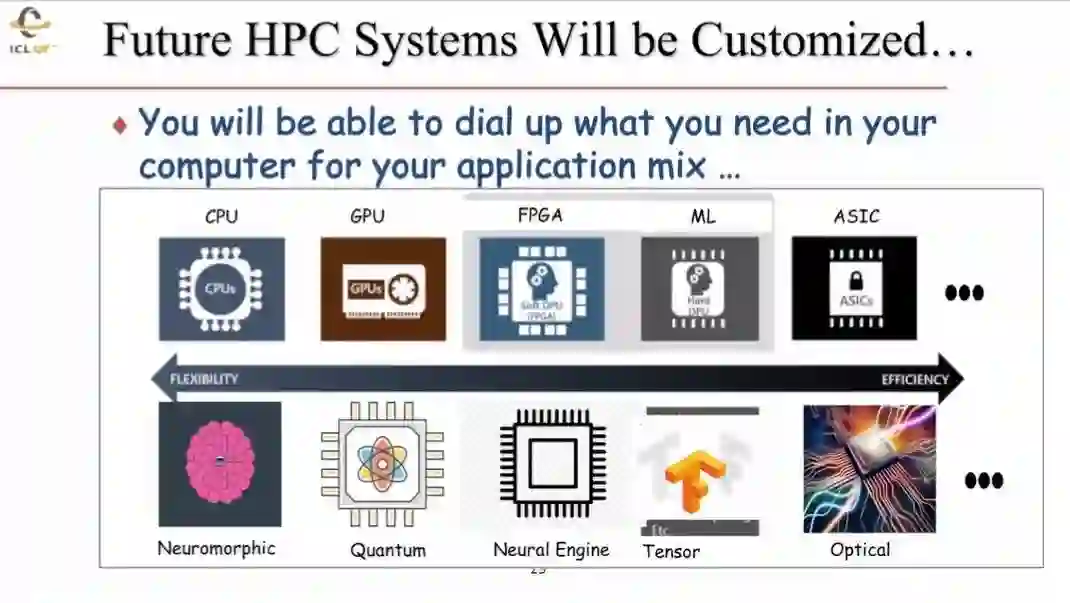
未来的HPC系统将可以被定制化。当前,HPC主要有CPU和GPU两种类型的处理器,未来将采用更多不同的单元,比如FPGA、ML加速器和ASIC芯片等等。更多采用不同结构和范式的处理器将会越来越多地添加HPC计算系统当中,比如神经形态处理处理、量子计算以及光计算等或将发挥越来越重要作用。在构建新的HPC系统的时候,人们将能够按需使用相应的模块与功能。

问题1:当前,业界和学界都比较关注神经网络大模型的训练,比如GPT3等具有超过1700亿的参数量,通常需要百个高性能的GPU训练1~3个月。未来采用高性能计算机可以在几天或几个小时内完成相关的训练吗?
回答1:GPU给计算机提供了强大的数值计算的能力。例如,超级计算机中98%的算力来自于GPU。而在CPU和GPU之间移动数据非常耗时。为了减少成本高昂的数据移动,可以通过将GPU和CPU距离更加贴近的方法,采用Chiplet等芯片设计方法或更为切实可行的实现路径。另外,直接将数据和对应的处理单元离得更近的方法对于解决数据搬运成本高昂的问题也将非常有帮助。
问题2:我们观察到一个现象,当前很多机器学习算法可以和硬件一起演化,并且相互影响。比如,当前ML领域性能最好的Transformer模型,英伟达等公司专门为其设计了专用的架构,使得Transformer更好用。您是否观察到这样的现象,如何评论?
回答2:这是一个非常好的例子,展现了硬件设计和其他方面的相互促进。当前很多硬件研究人员密切关注行业的变化,并对趋势做出判断。将应用与硬件进行联合设计可以显著地提升性能,进而销售更多的硬件。我认同这种「算法和硬件共同演化」的说法。
问题3:您指出未来高性能计算将是一个异构的混合体。集成这些部分将是一个非常困难的问题,甚至将会导致性能的降低。如果我们只是单纯地使用GPU,可能会导致更好的性能。您如何评价?
回答3:当前,高性能计算机中将CPU和GPU非常松散地耦合在一起,需要将数据从CPU传输到GPU上进行计算。未来,采用不同的硬件相互耦合到一起的趋势会继续延续。比如,使用专门的硬件做ML计算,可以是对GPU的进一步的增强。通过将ML相关的算法加载到对应的加速器上,在加速器上执行算法的细节并将计算结果传输给对应的处理器。未来也可实现可插拔的量子加速器,使其执行对应的量子算法等等。
问题4:HPC是非常昂贵的,尤其对于研究者和中小企业而言。是否存在类似云计算等方式能够让从事研究的师生和中小企业也用得起HPC?
回答4:在美国,使用HPC需要向有关部门提交相关的申请,说明正在研究的问题和需要的计算量。如果得到批准,就不用担心HPC使用的费用问题。在美国进行过一项是否应该将所有的HPC转变为基于云的系统的研究。结果表明,基于云的方案比直接使用HPC系统贵2-3倍。需要注意的是这背后的经济学假设:HPC被足够多的人共同使用,并且需要解决的问题有时需要使用整个HPC系统。这种情形下拥有一个专用的HPC更优于购买云服务。在美国和欧洲所观察到的现状是这样。

Jack Dongarra,高性能计算专家,2021年图灵奖获得者,美国田纳西大学创新计算实验室主任。其对数值算法和库的开创性贡献,使高性能计算软件在四十多年中与硬件的指数级改进保持同步。他获得过诸多学术成就,包括 2019 年他获得 SIAM / ACM 计算科学与工程奖,2020 年他因高性能数学软件领域的领导能力获得 IEEE 计算机先锋奖。他是 AAAS、ACM、IEEE 和 SIAM 的研究员,英国皇家学会的外国研究员,以及美国国家工程院的成员。





