图解 LZ77 压缩算法

点击图片报名参加广州&珠海源创会
数据压缩是一个减小数据存储空间的过程,目前被应用在软件工程的各个地方,了解其一些原理,方便我们更好的甄选压缩方案。
压缩方案有很多种,常见的就是有损和无损压缩。霍夫曼编码和LZ77(Lempel-Ziv-1977)都是无损压缩,其中霍夫曼是采用最小冗余编码的算法进行压缩,而LZ77是采用字典的方式进行压缩。关于霍夫曼编码的算法,网上有很多对其详细的讲解,我们本篇幅不在细说,主要图解一下LZ77压缩算法的方式,看看其有哪些优缺点。
本篇主要内容如下:
1、信息熵
2、LZ77算法原理
3、压缩过程
4、解压过程
5、优缺点
信息熵
数据为何是可以压缩的,因为数据都会表现出一定的特性,称为熵。绝大多数的数据所表现出来的容量往往大于其熵所建议的最佳容量。比如所有的数据都会有一定的冗余性,我们可以把冗余的数据采用更少的位对频繁出现的字符进行标记,也可以基于数据的一些特性基于字典编码,代替重复多余的短语。
LZ77算法原理
LZ77压缩算法采用字典的方式进行压缩,是一个简单但十分高效的数据压缩算法。其方式就是把数据中一些可以组织成短语(最长字符)的字符加入字典,然后再有相同字符出现采用标记来代替字典中的短语,如此通过标记代替多数重复出现的方式以进行压缩。要理解这种算法,我们先了解3个关键词:短语字典,滑动窗口和向前缓冲区。
关键词:
前向缓冲区
每次读取数据的时候,先把一部分数据预载入前向缓冲区。为移入滑动窗口做准备
滑动窗口
一旦数据通过缓冲区,那么它将移动到滑动窗口中,并变成字典的一部分。
短语字典
从字符序列S1...Sn,组成n个短语。比如字符(A,B,D) ,可以组合的短语为{(A),(A,B),(A,B,D),(B),(B,D),(D)},如果这些字符在滑动窗口里面,就可以记为当前的短语字典,因为滑动窗口不断的向前滑动,所以短语字典也是不断的变化。
LZ77的主要算法逻辑就是,先通过前向缓冲区预读数据,然后再向滑动窗口移入(滑动窗口有一定的长度),不断的寻找能与字典中短语匹配的最长短语,然后通过标记符标记。我们还以字符ABD为例子,看如下图:
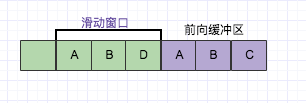
目前从前向缓冲区中可以和滑动窗口中可以匹配的最长短语就是(A,B),然后向前移动的时候再次遇到(A,B)的时候采用标记符代替。
压缩
当压缩数据的时候,前向缓冲区与移动窗口之间在做短语匹配的是后会存在2种情况:
1.找不到匹配时:将未匹配的符号编码成符号标记(多数都是字符本身)
2.找到匹配时:将其最长的匹配编码成短语标记。
3.短语标记包含三部分信息:(滑动窗口中的偏移量(从匹配开始的地方计算)、匹配中的符号个数、匹配结束后的前向缓冲区中的第一个符号)。
一旦把n个符号编码并生成响应的标记,就将这n个符号从滑动窗口的一端移出,并用前向缓冲区中同样数量的符号来代替它们,如此,滑动窗口中始终有最新的短语。
我们采用图例来看:
1、开始

2、滑动窗口中没有数据,所以没有匹配到短语,将字符A标记为A

3、滑动窗口中有A,没有从缓冲区中字符(BABC)中匹配到短语,依然把B标记为B

4、缓冲区字符(ABCB)在滑动窗口的位移6位置找到AB,成功匹配到短语AB,将AB编码为(6,2,C)

5、缓冲区字符(BABA)在滑动窗口位移4的位置匹配到短语BAB,将BAB编码为(4,3,A)

6、缓冲区字符(BCAD)在滑动窗口位移2的位置匹配到短语BC,将BC编码为(2,2,A)

7、缓冲区字符D,在滑动窗口中没有找到匹配短语,标记为D

8、缓冲区中没有数据进入了,结束

解压
解压类似于压缩的逆向过程,通过解码标记和保持滑动窗口中的符号来更新解压数据。
当解码字符标记:将标记编码成字符拷贝到滑动窗口中
解码短语标记:在滑动窗口中查找响应偏移量,同时找到指定长短的短语进行替换。
我们还是采用图例来看下:
1、开始

2、符号标记A解码

3、符号标记B解码

4、短语标记(6,2,C)解码

5、短语标记(4,3,A)解码

6、短语标记(2,2,A)解码

7、符号标记D解码

优缺点
大多数情况下LZ77压缩算法的压缩比相当高,当然了也和你选择滑动窗口大小,以及前向缓冲区大小,以及数据熵有关系。其压缩过程是比较耗时的,因为要花费很多时间寻找滑动窗口中的短语匹配,不过解压过程会很快,因为每个标记都明确告知在哪个位置可以读取了。

更多干货请前往公众号菜单栏“读我”->“干货分享”查看。







