NLPer内部巨大分歧!美国三所顶尖大学发布调查报告:62%从业者认同寒冬正来临
![]()
新智元报道

新智元报道
【新智元导读】NLP研究者对行业现状和前景怎么看?
自然语言理解(NLP)素有人工智能皇冠上的明珠的盛誉,在大规模语言模型的加持下,人类也终于有了让计算机理解语言的能力。
但这个「理解」还是得打个引号,按目前NLP模型的效果来看,虽然在部分领域模型可以为人类提供辅助,例如写作、文本分类等,但离真正达到人类水平的语言智能还有很远的距离。
今年5月-6月,华盛顿大学、纽约大学、约翰霍普金斯大学的11位研究人员在NLP研究社区中发起了一份调查问卷,对NLP领域的争议性问题广泛征求意见,包括行业在该领域的影响力、行业规模、通用人工智能(AGI)的风险的担忧、语言模型是否理解语言、未来的研究方向以及道德问题等。

调查主页:https://nlpsurvey.net/
报告地址:https://nlpsurvey.net/nlp-metasurvey-results.pdf
-
语言模型能理解语言吗?未来可以做到吗? -
传统的模型基准范式是否仍然可用? -
构建和发布哪种预测类模型对于研究者来说符合道德标准? -
下一个最有影响力的进步会来自工业界还是学术界?
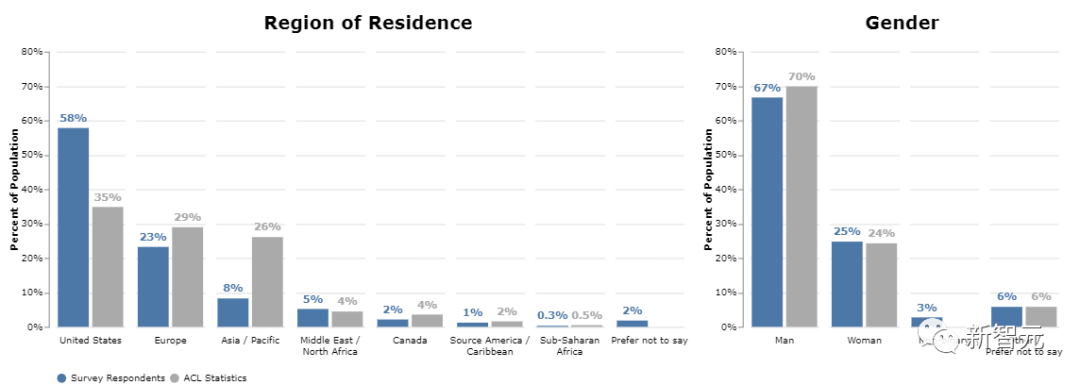
以地理位置进行划分的话,58%来自美国(超过ACL统计值35%),23%来自欧洲,8%来自亚洲(远小于ACL统计值26%)。其中,来自中国的 NLP 研究者占3%(ACL统计值为9%)。
领域现状
领域现状
该部分包括六个问题,用户需要回答「认同」、「稍微认同」、「不太认同」、「不认同」。
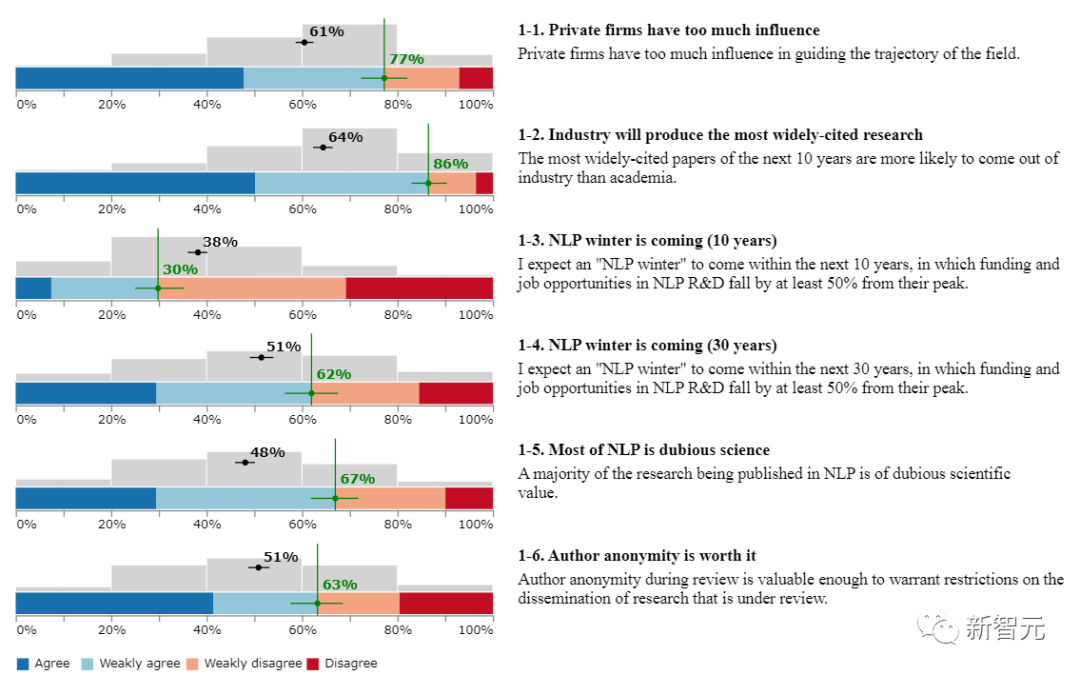
1、私营公司的影响力过大?
77%的受访者认同。
2、工业界将会产出最被广泛引用的研究成果?
86%受访者认同未来十年被广泛引用的论文更有可能来自工业界而非学术界。
不过很多受访者都认为一项工作的被引用次数并不能很好地代表其价值或重要性,而且工业界对该领域的持续主导地位将产生负面影响,比如在基础系统方面如GPT-3和PaLM的绝对领导地位。
而且在学术界的受访者中,认为工业界的影响力过大的人大约占82%,而工业界的受访者仅有58%的人认同。
3、NLP会在十年内进入寒冬?
仅有30%的受访者认同,届时NLP R&D的投资和工作机会将比高峰期至少减少50%。
尽管 30 %不是一个大数字,但这也反映了这一部分NLP研究者认为该领域将在不久的将来发生重大变化,至少投资资金会减少。至于悲观的原因可能有很多,比如由于工业界影响力过大而导致的创新停滞,工业界将凭借少量资源充足的实验室来垄断行业,NLP 和其他 AI 子领域之间的界限将消失等等。
4、NLP会在三十年内进入寒冬?
62%的受访者认同,长期来看,NLP领域可能会「退烧」甚至变冷。
5、大部分NLP领域发表的相关工作在科学价值上都值得怀疑(dubious)?
67%的受访者认同。
6、作者匿名评审很重要?
63%的受访者认同。评审期间作者的匿名是有价值的,足以证明对正在评审的研究的传播的限制。
规模化、归纳偏差和相关领域
规模化、归纳偏差和相关领域
该部分包含四个问题。

1、规模化可以解决几乎所有的关键问题?
仅有17%的受访者认同,如果用上21世纪内所有的计算资源和数据资源,用现有技术的规模化实施将足以实际解决任何重要的现实世界问题或NLP的应用。
2、引入语言学结构是必要的?
50%的受访者认同以语言学理论为基础的语言结构的离散的通用表征(例如,涉及词义、句法或语义图)对于实际解决NLP中的一些重要的现实世界的问题或应用是必要的。
3、专家的归纳偏见是必要的?
51%的受访者认同,专家设计的强归纳偏见(如通用语法、符号系统或认知启发的计算基元)对于实际解决NLP中一些重要的现实世界问题或应用是必要的。
4、 Ling/CogSci将对引用最多的模型作出贡献?
61%的受访者认同2030年被引用最多的五个系统中,很可能至少有一个会从过去50年的语言学或认知科学研究中的具体的、非微不足道的成果中获得明确的灵感。
AGI和主要风险
AGI和主要风险
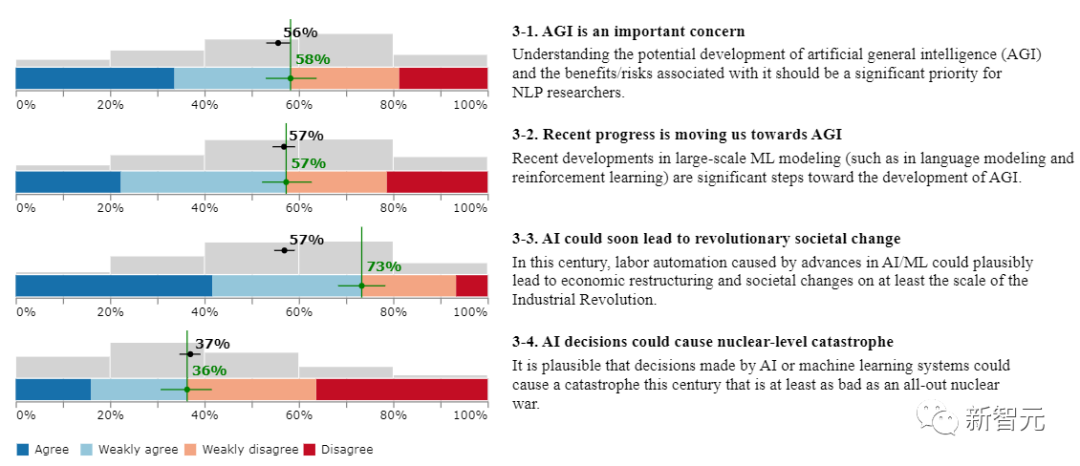
1、AGI是一个重要的关注点?
58%的受访者认同,了解人工通用智能(AGI)的潜在发展以及与之相关的利益/风险,应该是NLP研究人员的一个重要优先事项。
2、最近的进展正在使我们走向AGI?
57%的受访者认同,大规模ML建模的最新发展(如语言建模和强化学习)是朝着AGI发展的重要步骤。
3、人工智能可能很快导致革命性的社会变革?
73%的受访者认同,在本世纪,由人工智能/ML的进步引起的劳动自动化可能会导致经济重组和社会变革,其规模至少是工业革命时期的规模。
4、人工智能的决策可能导致核弹级别的灾难?
36%受访者认同,人工智能或机器学习系统做出的决策可能会在本世纪造成至少与全面核战争一样严重的灾难。
语言理解
语言理解
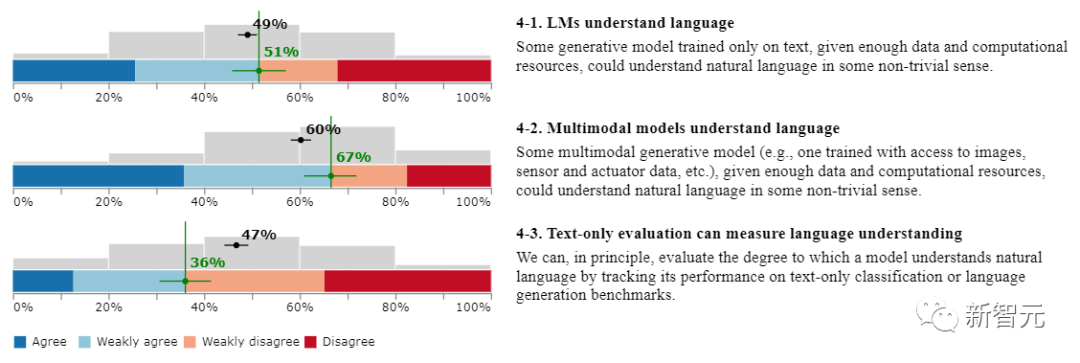
1、语言模型能理解(understand)语言?
51%的受访者认同。一些只对文本进行训练的生成模型,如果有足够的数据和计算资源,就可以在某种意义上理解自然语言
2、多模态模型能理解语言?
67%的受访者认同。对于多模态生成模型而言,比如一个经过训练可以访问图像、传感器和驱动器actuator数据等的模型,只要有足够的数据和计算资源,就可以理解自然语言。
3、纯文本评价可以衡量模型的语言理解能力?
36%的受访者认同。原则上,我们可以通过跟踪一个模型在纯文本分类或语言生成基准上的表现来评估其理解自然语言的程度。
NLP未来的研究方向
NLP未来的研究方向
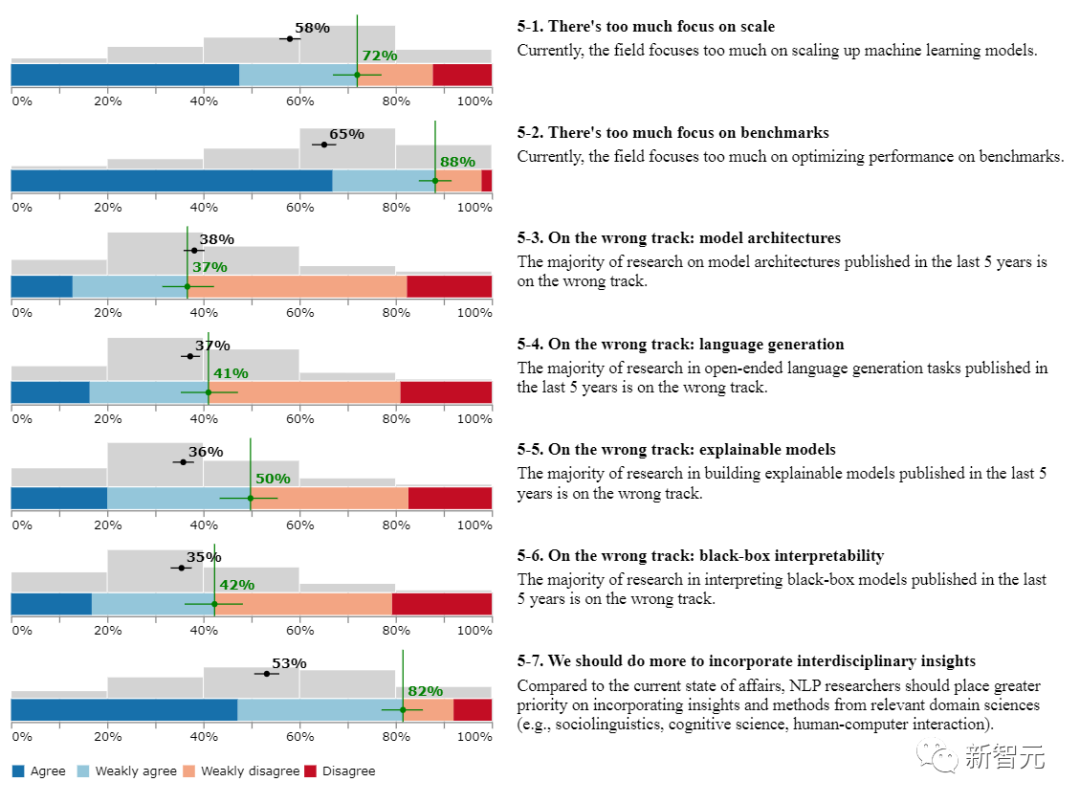
1、从业者太过于关注语言模型的规模?
72%受访者认同。目前,该领域过多地关注机器学习模型的大规模化。
2、过于关注基准数据集?
88%的受访者认同目前NLP模型过多地关注在基准上优化性能。
3、「模型架构」走错了方向?
37%受访者认同。过去5年发表的大部分关于模型架构的研究都走在了错误的道路上。
4、「语言生成」走错了方向?
41%受访者认同,过去5年中发表的关于开放式语言生成任务的大部分研究都走在了错误的道路上。
5、「可解释模型的研究」走错了方向?
50%的受访者认同,过去5年中发表的大多数关于建立可解释模型的研究都走在了错误的道路上。
6、「黑盒的可解释性」走错了方向?
42%的受访者认同过去5年中发表的关于解释黑箱模型的大部分研究都走在了错误的道路上。
7、我们应该做更多的工作来吸收跨学科的见解?
82%的受访者认同,与目前的状况相比,NLP研究人员应该更优先考虑纳入相关领域科学(如社会语言学、认知科学、人机交互)的见解和方法。
AI道德规范
AI道德规范
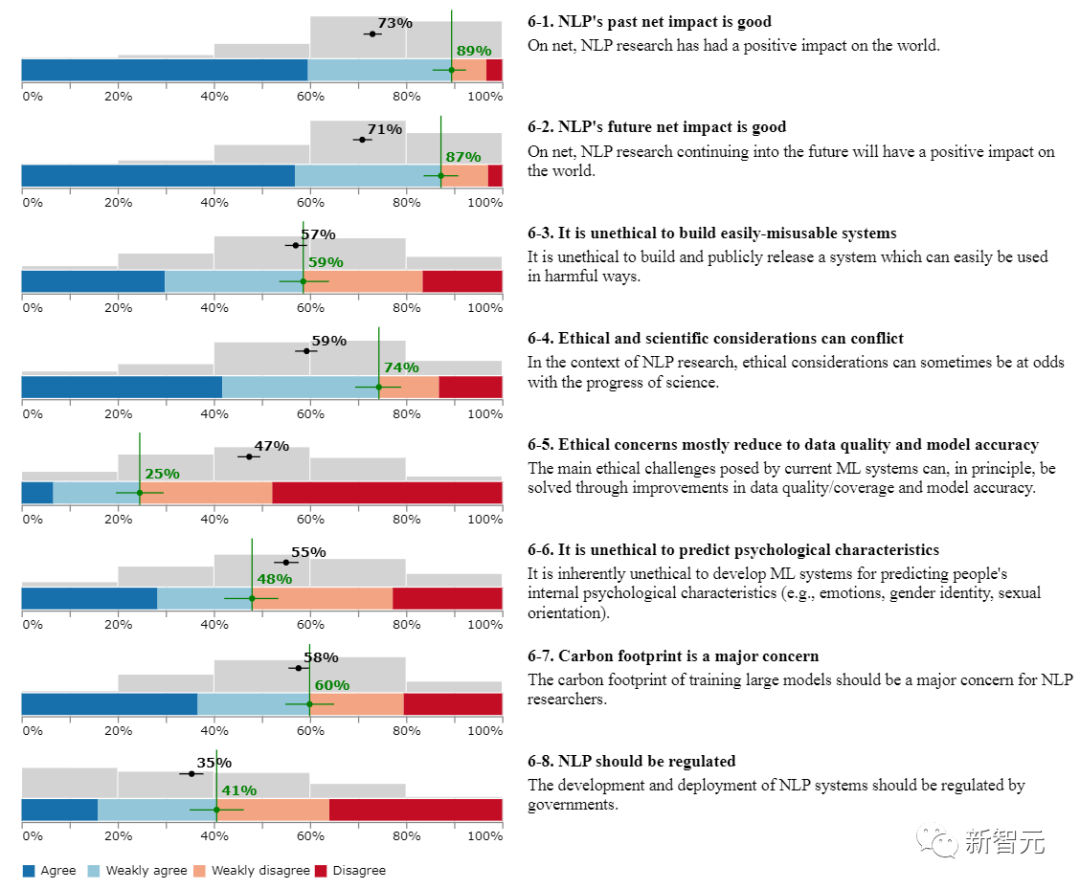
1、 NLP过去产生的影响是正向的?
89%受访者认同,总的来说,NLP研究对世界产生了积极的影响。
2、NLP的未来产生的影响会是正向的?
87%的受访者认同,总的来说,NLP的研究在未来会对世界产生积极的影响。
3、构建一个容易被滥用的系统是不道德的?
59%的受访者认同。
4、伦理和科学可能发生冲突?
74%的受访者认同,在NLP研究的背景下,伦理方面的考虑有时会与科学的进步相抵触。
5、伦理方面的问题大多归咎于数据质量和模型准确性方面?
25%的受访者认同,目前的机器学习系统所带来的主要伦理问题原则上可以通过提高数据质量/覆盖率和模型精度来解决。
6、预测心理特征是不道德的?
48%的受访者认同,开发机器学习系统来预测人们的内部心理特征(如情绪、性别认同、性取向)本身就是不道德的。
7、碳足迹是一个重要的考量吗?
60%的受访者认同,训练大型模型产生的碳足迹应该是NLP研究人员的一个主要关注点。
8、NLP应该受到监管吗?





