R语言数据抓取实战——RCurl+XML组合与XPath解析

经常有小伙伴儿跟我咨询,在使用R语言做网络数据抓取时,遇到空值和缺失值或者不存在的值,应该怎么办。
因为我们大多数场合从网络抓取的数据都是关系型的,需要字段和记录一一对应,但是html文档的结构千差万别,代码纷繁复杂,很难保证提取出来的数据开始就是严格的关系型,需要做大量的缺失值、不存在内容的判断。
如果原始数据是关系型的,但是你抓取来的是乱序的字段,记录无法一一对应,那么这些数据通常价值不大,今天我以一个小案例(跟昨天案例相同)来演示,如何在网页遍历、循环嵌套中设置逻辑判断,适时的给缺失值、不存在值填充预设值,让你的爬虫代码更稳健,输出内容更规整。
加载扩展包:
#加载包:
library("XML")
library("stringr")
library("RCurl")
library("dplyr")
library("rvest")
#提供目标网址链接/报头参数
url<-'https://read.douban.com/search?q=Python'
header =c('User-Agent'='Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.79 Safari/537.36')构建抓取函数:
getcontent<-function(url){
#这个数据框是为最终的数据汇总返回提供的初始值 myresult=data.frame()
#这些空向量是遍历单页书籍记录提供的初始值 title=author=category=subtitle=eveluate_nums=rating=price=c()
#开始遍历网页 for (page in seq(0,3)){
#遍历不同页面 link<-paste0(url,'&start=',page*10)
#请求网页并解析 content<-getURL(link,httpheader=header) %>% htmlParse() #计算单页书籍条目数 length<-content %>% xpathSApply(.,"//ol[@class='ebook-list column-list']/li") %>% xmlSize()
###提取标题: title<-content %>% xpathSApply(.,"//ol/li//div[@class='title']/a| //ol/li//h4/a",xmlValue) %>% c(title,.)
###提取图书类别: category=content %>% xpathSApply(.,"//span[@class='category']/span[2]/span | //p[@class='category']/span[@class='labled-text'] | //div[@class='category']",xmlValue) %>% c(category,.)
###提取作者/副标题/评论数/评分/价格信息: author_text=subtitle_text=eveluate_nums_text=rating_text=price_text=rep('',length)
for (i in 1:length){
###提取作者 author_text[i]=content %>% xpathSApply(.,sprintf("//li[%d]//p[@class]//span/following-sibling::span/a | //li[%d]//div[@class='author']/a",i,i),xmlValue) %>% paste(.,collapse='/')
###考虑副标题是否存在 if (content %>% xpathSApply(.,sprintf("//ol/li[%d]//p[@class='subtitle']",i),xmlValue) %>% length!=0){ subtitle_text[i]=content %>% xpathSApply(.,sprintf("//ol/li[%d]//p[@class='subtitle']",i),xmlValue) }
###考虑评价是否存在: if (content %>% xpathSApply(.,sprintf("//ol/li[%d]//a[@class='ratings-link']/span",i),xmlValue) %>% length!=0){ eveluate_nums_text[i]=content %>% xpathSApply(.,sprintf("//ol/li[%d]//a[@class='ratings-link']/span",i),xmlValue) }
###考虑评分是否存在: if (content %>% xpathSApply(.,sprintf("//ol/li[%d]//div[@class='rating list-rating']/span[2]",i),xmlValue) %>% length!=0){ rating_text[i]=content %>% xpathSApply(.,sprintf("//ol/li[%d]//div[@class='rating list-rating']/span[2]",i),xmlValue) }
###考虑价格是否存在: if (content %>% xpathSApply(.,sprintf("//ol/li[%d]//span[@class='price-tag ']",i),xmlValue) %>% length!=0){ price_text[i]=content %>% xpathSApply(.,sprintf("//ol/li[%d]//span[@class='price-tag ']",i),xmlValue) } }
#拼接以上通过下标遍历的书籍记录数 author=c(author,author_text) subtitle=c(subtitle,subtitle_text) eveluate_nums=c(eveluate_nums,eveluate_nums_text) rating=c(rating,rating_text) price=c(price,price_text) #打印单页任务状态 print(sprintf("page %d is over!!!",page)) }
#构建数据框 myresult=data.frame(title,subtitle,author,category,price,rating,eveluate_nums)
#打印总体任务状态 print("everything is OK")
#返回最终汇总的数据框 return(myresult) }提供url链接并运行我们构建的抓取函数:
myresult=getcontent(url)[1] "page 0 is over!!!"
[1] "page 1 is over!!!"
[1] "page 2 is over!!!"
[1] "page 3 is over!!!"
[1] "everything is OK"
查看数据结构:
str(myresult)规范变量类型:
myresult$price<-myresult$price %>% sub("元|免费","",.) %>% as.numeric() myresult$rating<-as.numeric(myresult$rating) myresult$eveluate_nums<-as.numeric(myresult$eveluate_nums)预览数据:
DT::datatable(myresult)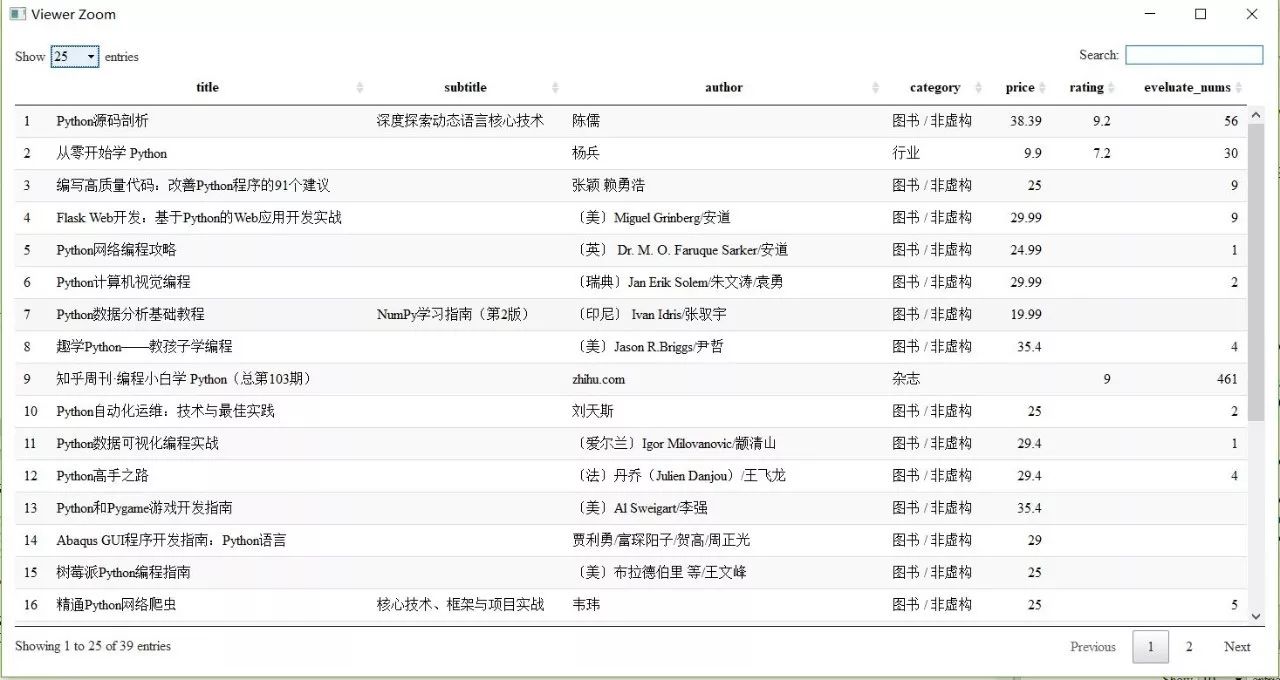
构建自动化抓取函数,其实挑战不仅仅是缺失值、不存在值的处理,变量作用域的设置也至关重要,以上自动以函数中使用了两层for循环嵌套,在内层for循环中还使用了四个if 判断,个别字段的XPath路径不唯一,为了数据规范,我在XPath中使用了多重路径“|”。
判断缺失值(或者填充不存在值)的一般思路就是遍历每一页的每一条记录的XPath路径,判断其length,倘若为0基本就可以判断该对应记录不存在。
通过设置一个长度为length的预设向量,仅需将那些存在的(长度不为0)记录通过下标插入对应位置即可,if判断可以只写一半(后半部分使用预设的空值)。
至于里面让人眼花缭乱的XPath表达式,请参考这一篇,你可以直接去W3C school查看完整版!
在线课程请点击文末原文链接:
往期案例数据请移步本人GitHub:
https://github.com/ljtyduyu/DataWarehouse/tree/master/File
相关课程推荐
R语言爬虫实战案例分享:
网易云课堂、知乎live、今日头条、B站视频
分享内容:本次课程所有内容及案例均来自于本人平时学习练习过程中的心得和笔记总结,希望借此机会,将自己的爬虫学习历程与大家分享,并为R语言的爬虫生态改善以及工具的推广,贡献一份微薄之力,也是自己爬虫学习的阶段性总结。

☟☟☟ 猛戳阅读原文,即刻加入课程。



