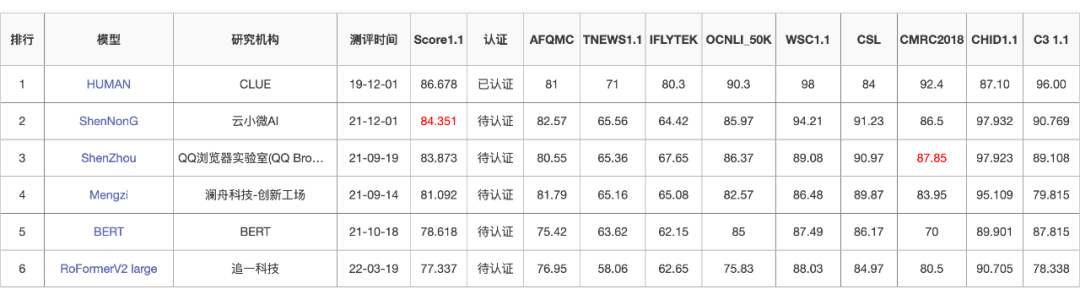
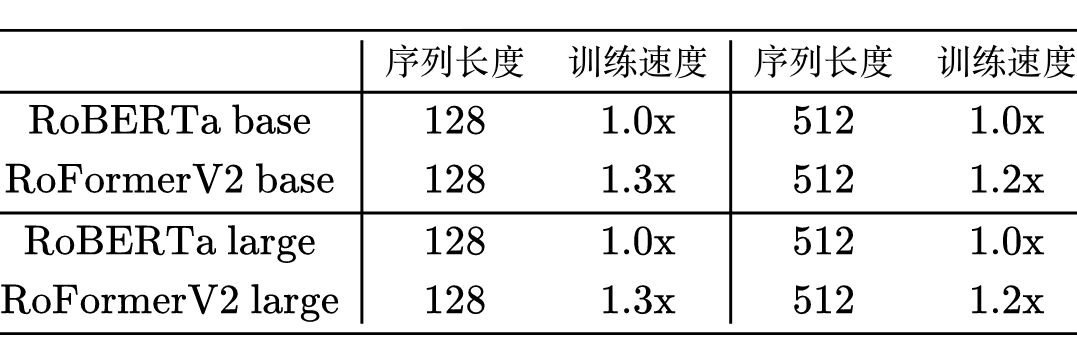
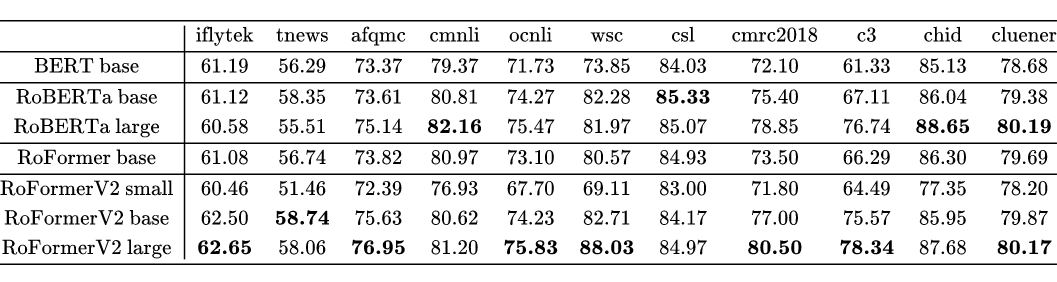
RoFormerV2:自然语言理解的极限探索

Github:
https://github.com/ZhuiyiTechnology/roformer-v2




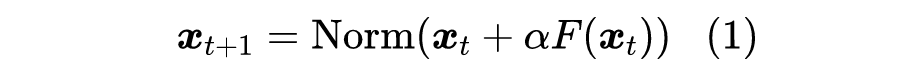




参考文献

🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧

登录查看更多
相关内容

Arxiv
14+阅读 · 2019年8月8日
Arxiv
16+阅读 · 2017年11月20日



相关VIP内容
相关资讯