学会通知丨2019第二届中国“AI+”创新创业大赛大规模特征检索技术创新大赛通知
各相关单位:
2019第二届中国“AI+”创新创业大赛--大规模特征检索技术创新大赛(以下简称“大赛”)将于2019年5月至11月举行。
在信息时代,海量数据需要高效的检索算法进行归档。如何又快又好地检索数据库中与目标最相近的样本,是特征检索的主要目标。为了促进大规模特征检索技术的发展,中国人工智能学会特此主办本次特征检索技术大赛。为从事大规模特征检索研究的研究人员、产业界从业人员以及AI技术爱好者提供一个良好的沟通平台。
现将2019第二届中国“AI+”创新创业大赛--大规模特征检索技术创新大赛通知的有关事项通知如下:
一.大赛机构
1.主办单位
中国人工智能学会
2.组织单位
电子科技大学
3. 评测委员会
主席团:
宋井宽(电子科技大学)
王井东(微软亚洲研究院)
刘 丽(国防科技大学)
刘 力(Inception Institute of Artificial Intelligence)
二.参赛办法
1.参赛对象
本次大赛是面向全国高校,科研机构,和涉及特征检索、哈希、量化等技术的人工智能领域企业的赛事,欢迎各单位积极组织队伍申报参赛。
2.参赛组队形式
选手可在网上自行组队报名,每支队伍包含 3-5 名队员,选手的地区、年龄、职业不限,每队至少有一名中国国籍选手。
以公司为单位参赛,需已注册成立企业;高校以团队为单位参赛,需由指导教师带领。参赛个人及单位要求无不良记录;参赛项目的产品、技术及相关专利专属于参赛团队及个人,与其他任何单位或个人无产权纠纷,如在参赛期间发现有侵犯外单位知识产权或盗用成果等纠纷,一经核实,立即终止该参赛队参赛资格,取消其已获得的奖项。
3. 报名方式
2019年6月30日前,参赛队伍在大赛网站(https://aichina.caai.cn/)的报名系统中在线报名,完成相关信息录入,完成报名。(有特殊要求的各赛区自行确定后可以向大赛组委会提出需求)
4. 参赛选题
(1)竞赛背景
近年来随着大数据、数据挖掘以及深度学习在语音、图像、自然语言处理等人工智能任务中的高速发展,伴随这些生成的特征数据也极为庞大。在海量的特征中进行搜索对时间和精度尤其敏感。数据检索具有重要的实际意义,吸引了众多研究者的关注。目前,哈希技术和量化技术是特征检索中的主要技术。本赛题通过在大规模数据集上进行检索竞赛,检验检索技术的速度、压缩率和精度等多方面性能指标。
(2)赛题描述
比赛中分为模型训练,数据集编码和模型提交测试三个阶段。数据集分为训练集(Training Set)、检索集(Base Set)、测试集(Query Set)三个部分。选手首先使用训练集对模型训练,然后将检索集的数据压缩为二进制文件,最后使用二进制文件以及检索接口在测试集上进行检索,得到每条测试数据在检索集中最相近的前K个结果。
(a)初赛流程
我们将在公开数据集上进行评测,选手下载训练集并训练完成后,根据比赛要求提供测试接口,之后将代码、压缩后的检索集以及训练好的模型提交至服务器中用于评测,我们将会根据后述的评价指标进行排名。每组选手最多可提交15次,取最好的作为最终结果。
数据集详情:
SIFT1M:用于评价近似最近邻搜索算法性能的经典数据集,其中的样本来自于SIFT算法生成的128维正整数向量,取值范围在 [0, 255] 之间。训练集包含100,000条数据,检索集包含1,000,000条数据,测试集包含10,000条测试数据,训练集与检索集为同一分布。选手在本地测试代码时可以使用SIFT1M提供的数据来验证代码,但为避免作弊,我们将使用另外生成的测试数据而不是原始测试集。测试时,程序先对整个检索集进行编码得到压缩后的检索数据,再使用测试集的数据逐条检索,根据程序返回的前100个结果计算mAP@100、检索时间以及压缩率进行加权,得到评分,具体评价指标请见后述。Groundtruth的定义为:一个query在整个检索集中使用欧式距离遍历计算得到距离最小的样本。
下载:http://corpus-texmex.irisa.fr/
(b)决赛流程
决赛将会提供由我们生成的数据集进行评测,评测方式与初赛大致相同。需要注意的是,我们将只提供训练集,而不会提供测试集(Query Set)、检索集(Base Set)以及groundtruth。
数据集详情:
我们将使用ResNet-50在ImageNet上生成的一批2048维浮点向量作为数据集的样本,其取值范围在 (-1, 1) 之间。我们从ImageNet上随机抽取100个类,使用这些类的全部图片,并提取特征向量作为检索集;从检索集中再随机抽取5,000条数据作为训练集;再从ImageNet的验证集中使用相应100类的图片作为测试集。测试集将不公开,由我们统一评测,评测指标为mAP@5000、检索时间以及压缩率。Groundtruth的定义为:在检索集中,若数据与query属于同一分类,则为正样本,否则为负样本。需要注意的是,训练时不提供标签信息,为无监督训练。
下载:待补充
5.作品要求
参赛队的参赛内容应该是参赛队员独立设计、开发完成的作品,严禁抄袭、剽窃等行为。凡发现抄袭、剽窃等行为,将取消参赛队伍的参赛资格,并追究相关指导教师和单位的责任。
三.竞赛时间安排
2019年5月27日:发布大赛通知,开始报名
2019年6月1日:发布比赛训练集数据和具体评测方案
2019年6月30日:报名截止
2019年8月31日:提交测试集结果截止日
2019年9月05日:提交最终测试结果对应的系统代码及系统报告
2019年9月25日:决赛名单公布
2019年10月下旬或11月上旬:决赛和颁奖
四.竞赛赛制
1.比赛整体流程
(1)初赛:参赛队需于2019年6月30日前完成报名,并在数据发布之后从网站获取主办方发布的比赛用数据集。之后即可开始检索模型搭建和训练、编码,2019年6月20日起可以online提交各自模型和编码文件参与测试结果评测排名,2019年8月31日为最后系统提交更新日。2019年9月5日前,各参赛队需要提交源码,和介绍所提交模型、方法的系统报告。
(2)决赛:决赛将于2019年10月下旬或11月上旬组织,具体形式与初赛类似,根据复赛得分给出最终名次。决赛的具体时间将另行通知。
2.初赛评测规则
(1) 代码要求
我们将使用统一的运行环境,使用要求之外的代码库或语言将不被接受。具体环境为:
a.使用Python 3.6+ 作为编码语言,也可在 Python 中调用 C/C++ (GCC 5.4.0),但程序预留接口须为Python。
b.由于特征检索算法中仍包含许多非深度学习的算法,因此在进行检索时将屏蔽GPU只使用CPU进行计算,以便计算检索时间,训练和编码时可不受限制。
c.使用的代码库版本要求:Tensorflow 1.9+,PyTorch 1.0+,使用其他的深度学习框架请确保能够安装运行。
d.服务器环境:
CPU:2 × Intel Xeon E5-2650 v3 (20C 40T)
GPU:NVIDIA TITAN Xp (12189MiB)
Memory :256 GiB
(2) 代码接口
我们要求代码提供统一的接口以方便评测,要求如下:
建立一个main.py的文件,包含以下函数:
def retrieve(query:np.ndarray, R:int, dbpath:str) -> np.ndarray:
"""Retrieve the database and return the retrieved results by queries.
Arguments:
query {np.ndarray} -- Query features, a [N, D] array with N queries and D dimensions with dtype:float
R {int} -- Number of returned results
dbpath {str} -- The saved encoded database file path, directly from the return result of encode(...)
Returns:
np.ndarray -- The result matrix, a [N, R] array with dtype:int, each row is corresponded to each query, and each column indicates the index in database, results contain R indices which are sorted from the nearest to the furthest. i.e. [[3, 9, 2, ...], ...] means we think for the first query, the 4th sample in database is the closest, then 10th, then 3rd, etc.
"""
pass
最终我们将根据上传的压缩后的二进制文件以及retrieve(…) 得到的结果进行评测。
(3)评价指标
算法的性能好坏将从mAP,检索时间以及压缩率衡量。
mAP:
mAP (mean Average Precision) 是对所有queries的平均检索精度的均值。我们在评测时设置R=100并计算mAP@100。
检索时间:
检索时间是执行retrieve(…) 的运行时间,计算公式为
压缩率:
压缩率是训练模型文件加上压缩后的检索集文件体积与原始文件体积的比值,原始文件体积计算方式如下:(1) 若数据集为SIFT1M,那么体积为 ;(2)若数据集为Deep features, 那么体积为. 计算公式为
(4)编码长度
由于编码长度不同时,算法的性能也会变化,因此我们将测试12 bits, 24 bits, 36 bits, 48 bits的结果,并对每一组的结果加权得到最终结果。
最终结果计算如下:记mAP@R结果为A,检索时间结果为B,压缩率结果为C
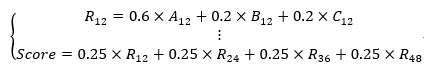
Score取值为 (0~1),越大越好。
(5)上传文件要求
综上所述,我们共需上传的文件如下:
a)训练好的模型和代码文件,包括预留好接口的main.py文件。若需编译或安装框架,请再添加一份readme;
b)以12 bits, 24 bits, 36 bits, 48 bits长度编码压缩后的四个检索集文件。
3.参赛规则介绍
1)允许使用开源代码、工具和公开数据集,及参赛队伍自己以往开发未公开的代码和数据集。
2) 经组委会评估后确认获决赛资格;如拒绝或未在规定时间内提供相应代码和文档则取消决赛资格。
五.奖项设置
本赛事预选8队进入决赛,最终角逐出冠军1队、亚军2队、季军3队。
六.竞赛管理
1.参赛费用
本次参赛不收取任何费用。
2.餐饮住宿
参加决赛队伍的教师和学生在决赛期间的食宿费用、交通费用及其他费用均自理。
3.竞赛秘书处联系方式
报名网站:https://aichina.caai.cn/
报名、赛务等联系人:
牛雷、2690553789@qq.com
电话:15051540646
2019第二届中国“AI+”创新创业大赛
--大规模特征检索技术创新大赛通知
2019年5月27日
点击“阅读原文”了解更多大赛信息~






