Kaggle首战斩获第三,看深度学习菜鸟团队如何一鸣惊人
选自towardsdatascience
作者:Mercy Markus
机器之心编译
机器之心编辑部
背靠 fast.ai 库与视频教程,首战 Kaggle 竞赛,新手在油棕种植园卫星图像识别中获得第三名。
Women in Data Science 与合作伙伴共同发起了 WiDS 数据马拉松竞赛(WiDS datathon)。赛题是创建一个能够预测卫星图像上油棕种植园存在情况的模型。
Planet 和 Figure Eight 慷慨地提供了卫星图像的带注释数据集,而该卫星图像是最近由 Planet 卫星拍摄的。该数据集图像具有 3 米的空间分辨率,并且每一副图像都基于是否含油棕种植园来标记(0 意为没有油棕种植园,1 意为存在一个油棕种植园)。
竞赛任务是训练一个模型,该模型能够输入卫星图像,输出包含油棕种植园图像的似然预测。在模型开发中,竞赛举办者提供带标签的训练和测试数据集。
详细信息参见:https://www.kaggle.com/c/widsdatathon2019
我和队友(Abdishakur、Halimah 和 Ifeoma Okoh)使用 fast.ai 框架来迎接这项赛题。非常感谢 Thomas Capelle 在 kaggle 上的启动内核,该内核为解决这个问题提供了诸多见解。
此外,还要感谢 fast.ai 团队,该团队创建了一门不可思议的深度学习课程,该课程简化了大量困难的深度学习概念。现在,深度学习初学者也可以赢得 kaggle 竞赛了。
课程地址:https://course.fast.ai/
从一个通俗易懂的深度学习指南开始
不要想着马上就能理解所有东西,这需要大量的练习。本指南旨在向深度学习初学者展示 fast.ai 的魅力。假定你了解一些 python 知识,也对机器学习稍有涉猎。这样的话,我们就走上了学习正轨。
(引用)本文展示的所有代码可在 Google Colaboratory 中找到:这是一个 Jupyter 笔记本环境,不需要进行任何设置就可以使用,并且完全在云端运行。你可以通过 Colaboratory 编写和执行代码,保存和分享分析,访问大量的计算资源,所有这些都是免费的。
代码参见:https://colab.research.google.com/drive/1PVaRPY1XZuPLtm01V2XxIWqhLrz3_rgX。
导入 fast.ai 和我们将要使用的其他库

输入库
获取竞赛数据
为了尽可能简洁明了,Abdishakur 上传竞赛数据文件至 dropbox.com。你可以在竞赛页面上找到这些数据。你需要接受竞赛规则,并在参赛后访问数据。

观察数据
我们在解决一个问题时首先要做的是观察可用数据。在想出解决方案之前,我们需要理解这个问题以及数据是什么样的。观察数据意味着理解数据目录的构成方式、数据标签以及样本图像是什么样的。

使用 pandas 库来读取数据。

训练模型所要使用的数据标签。
处理「图像分类数据集」和「表格数据集」的主要区别在于标签的存储方式。这里的标签指的是图像中的内容。在这个特定的数据集中,标签以 CSV 文件格式存储。
想要了解更多计算「分数」列的方法,点击:
https://success.figure-eight.com/hc/en-us/articles/201855939-How-to-Calculate-a-Confidence-Score。
我们将使用 seaborn 的 countplot 函数来观察训练数据的分布。我们从下图中看到,大约 14300 个图像中没有发现油棕种植园,而仅有 942 个图像中发现了油棕种植园。这就是所谓的不平衡数据集,但我们在这里不讨论这个深度学习问题。我们此刻正迈出了一小步。

统计两个类别的样本数。

训练数据集中分布
准备数据
提供的测试数据放置于两个不同的文件夹中: leaderboard 留出数据和 leaderboard 测试数据。由于竞赛要求提交这两种数据集的预测,所以我们将两者相结合。我们共获得 6534 副图像。

结合 leaderboard 留出数据和 leaderboard 测试数据。
我们将使用 fast.ai 的 DataBlock API 来构成数据,这是一种将数据集呈现给模型的简便方法。
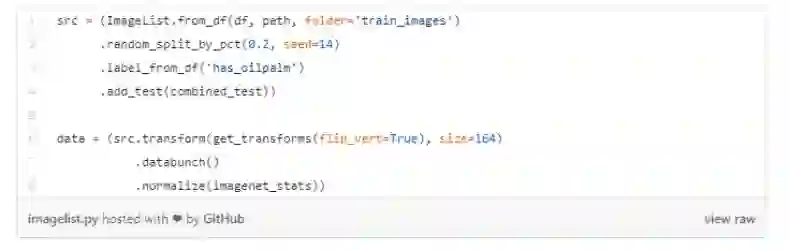
创建一个 ImageList 来保留数据
我们将使用 ImageList 来保存训练数据,并使用 from_df 方法读取数据。这样做的原因是,我们将训练集信息储存在了名为 df 的 DataFrame 中。
接下来需要随机分割训练集,并保留 20% 作为验证集,从而在训练中监督模型性能。我们选择了一个 seed,以确保再一次训练时能得到相同的结果,通过相同的 seed,我们就能知道哪些改进是好的,哪些是坏的。
此外,我们同样还要把训练集的标签地址提供给 ImageList,并将数据与标签合并。
最后,还需要在数据上执行转换,通过设定 flip_vert = True 将翻转图像,这能帮助模型识别不同朝向的图像。此外,还需要使用 imagenet_stats 来归一化图像。
预览图像
如下是有或没有油棕种植园的卫星图像:

展示两个 Batch 的图像。

有油棕的图像标记为 1,没有油棕的标记为 0
训练我们的模型
现在,开始训练我们的模型。我们将使用卷积神经网络作为主体,并利用 ResNet 模型的预训练权重。ResNet 模型被训练用来对各种图像进行分类,不用担心它的理论和实现细节。现在,我们构建的模型以卫星图像作为输入,并输出这两个类别的预测概率。

卷积神经网络

搜索最佳模型学习率。
接下来,我们用 lr_find() 函数找到了理想的学习率,并使用 recorder.plot() 对其进行了可视化。
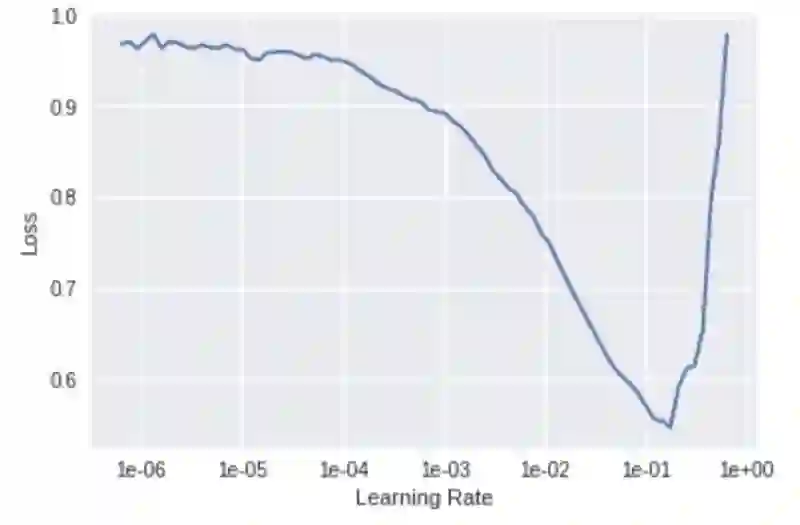
搜索最佳模型学习率。
我们将选择斜率最大的学习率,在这里我们选择的是 1e-2。

用学习率 1e-2 对模型展开 5 个周期的训练。
我们将使用 fit_one_cycle 函数对模型进行 5 个 epoch 的训练(遍历所有数据 5 次)。
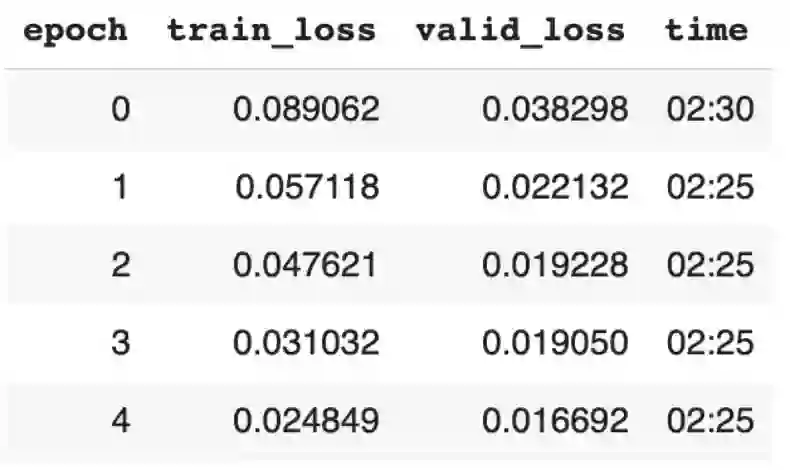
训练和验证损失。
注意展示的 metrics,即 training_loss 和 valid_loss。随着时间的推移,我们使用它们来监控模型的改进。
最佳模型是在第四个 epoch 时获得的。
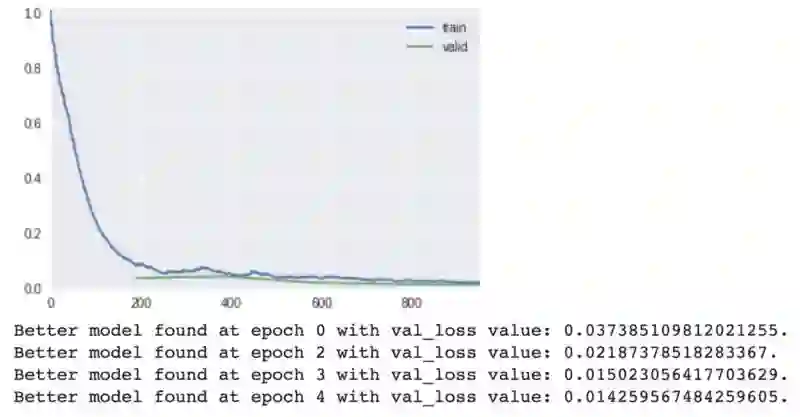
训练阶段模型的输出;训练和验证损失的变化过程。
在你进行训练和验证数据集时,fast.ai 只在内部挑选并保存你的最佳模型。
评估我们的模型
竞赛提交的材料是根据预测概率和观测目标 has_oilpalm 之间的 ROC 曲线来评估的。默认情况下,Fast.ai 不会附带这个指标,所以我们将使用 scikit-learn 库。
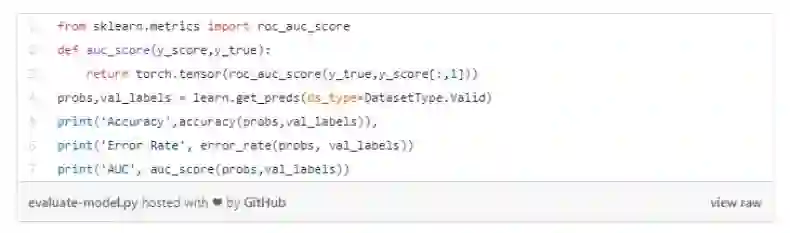
打印验证指标。
使用预训练模型和 fast.ai 的妙处在于,你可以获得很好的预测准确率。在我们的案例中,没有费多大力就获得了 99.44% 的准确率。

训练第一阶段的指标。
保存模型,并绘制关于预测的混淆矩阵。

使用混淆矩阵查看结果

绘制混淆矩阵
混淆矩阵是一种图形化的方式,可以查看模型准确或不准确的预测图像数量。
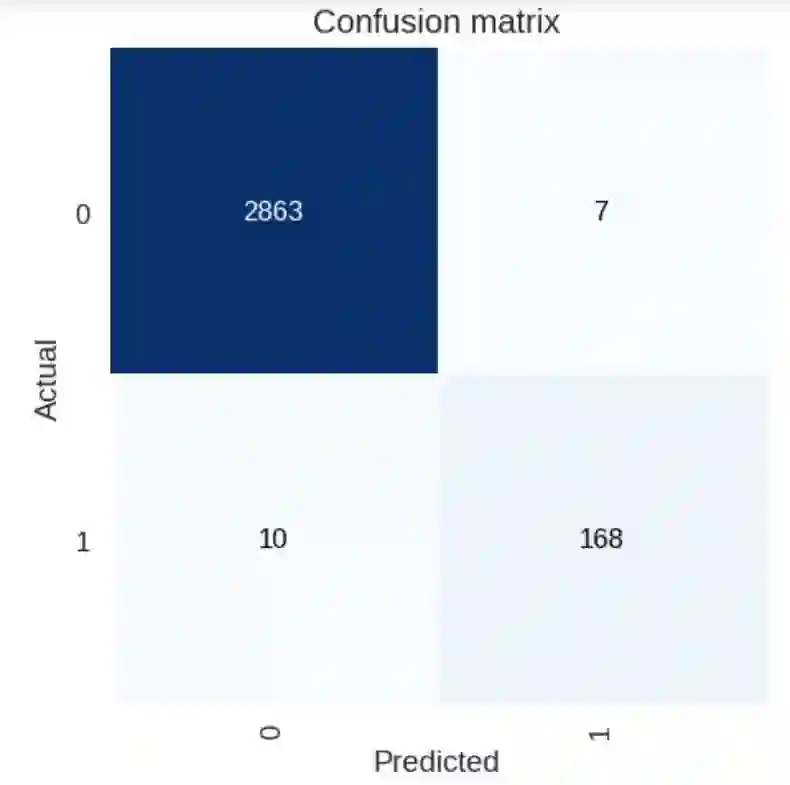
第一个训练阶段的混淆矩阵。
从这个矩阵中可以看出,模型准确地预测出有 2863 张图像中没有油棕,168 张图像中有油棕。10 张有油棕的图像被分类为没有,而 7 张没有油棕的图像则被分类为有油棕。
对这种简单的模型来说,这个结果不错了。接下来,我们搜索到了训练的理想学习率。

搜索理想的学习率。
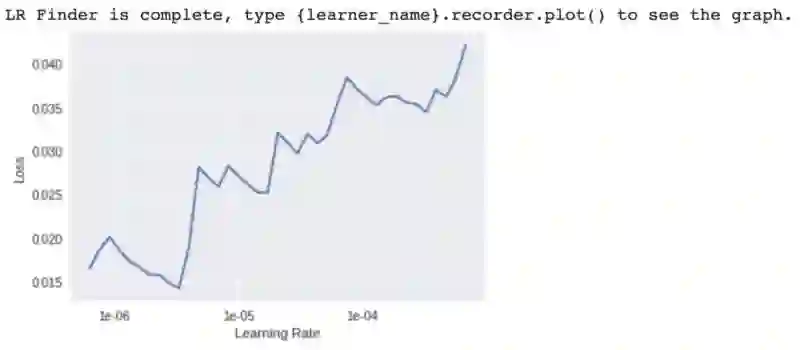
我们在学习率 1e-6 和 1e-4 之间选择了一个学习率。
在 7 个 epoch 内,使用 1e-6 和 1e-4 之间的最大学习率来拟合模型。

对模型进行 7 个周期的训练,学习率应在 1e-6 和 1e-4 范围内。
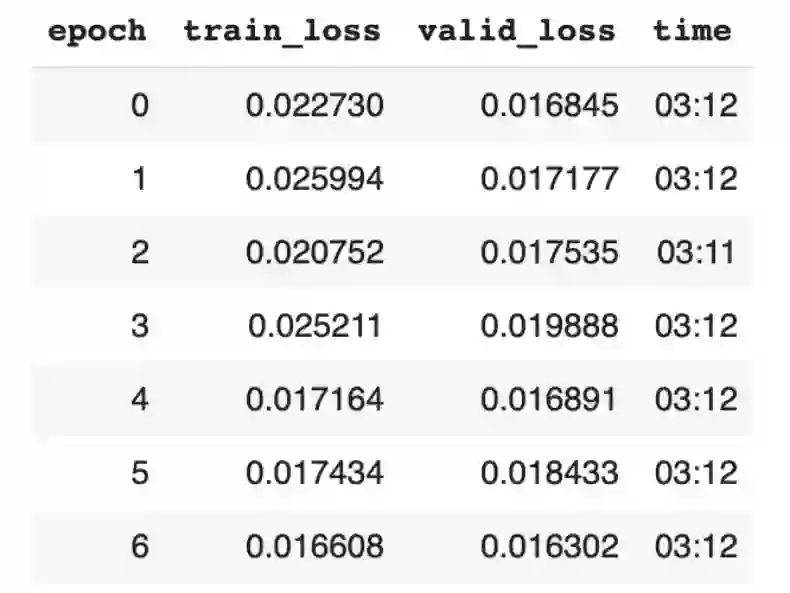
训练和验证损失。
以图形方式观察训练指标,以监控每个训练周期后模型的性能。
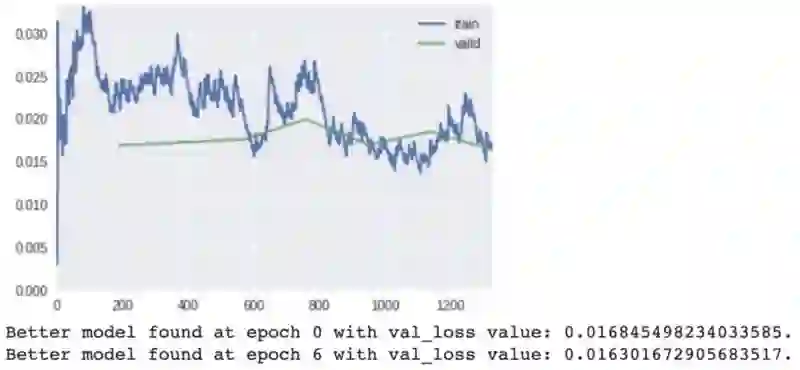
训练阶段模型的输出;训练和验证损失的变化过程。
保存模型的第二个训练阶段:
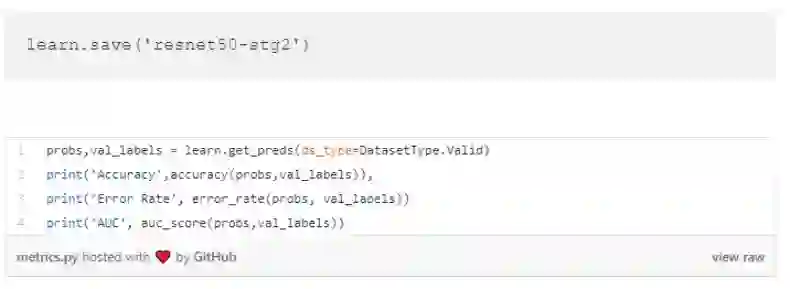
准确率、误差率和 AUC 分数
打印模型的准确率、误差率和 AUC 指标:

第二个训练阶段的指标。
如你所见,模型的准确率从 99.44% 上升到了 99.48%。误差率从 0.0056 降到了 0.0052。AUC 也从 99.82% 上升为 99.87%。

绘制混淆矩阵。
与我们绘制的上一个混淆矩阵相比,你会发现模型的预测效果更好了。
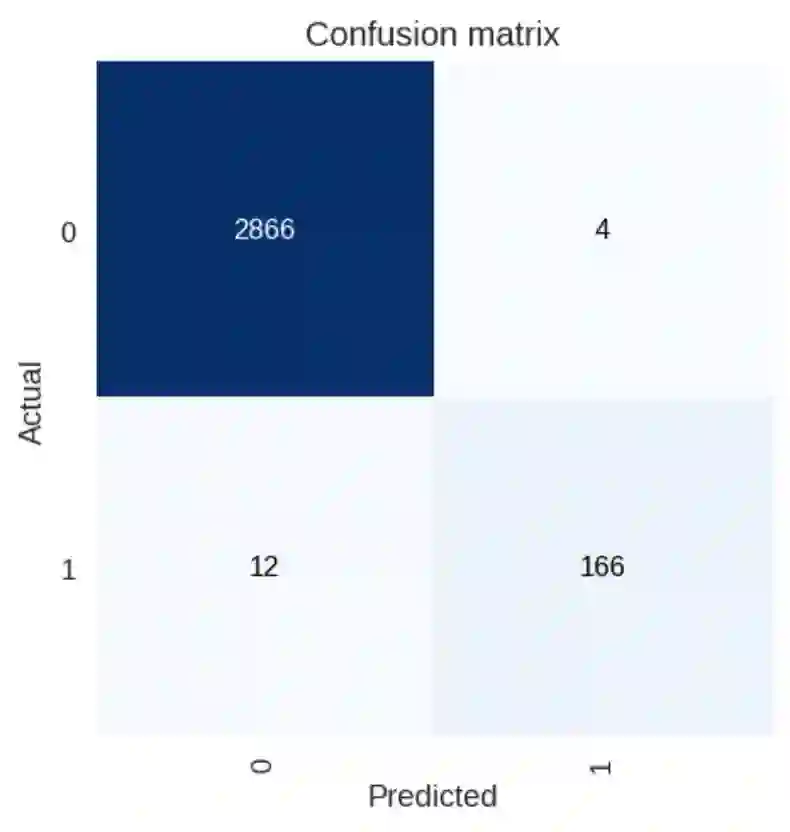
第二个训练阶段的混淆指标
之前有 7 张不含油棕种植园的图像被错误分类,现在降到了 3 张,这就是进步。
我们在训练和调参期间遵循了一种模式。大多数深度学习实验都遵循类似的迭代模式。
图像转换
我们将在数据上执行更多的图像转换,这应该是能提升模型效果的。图像转换的具体描述可以在 fast.ai 文档中找到:
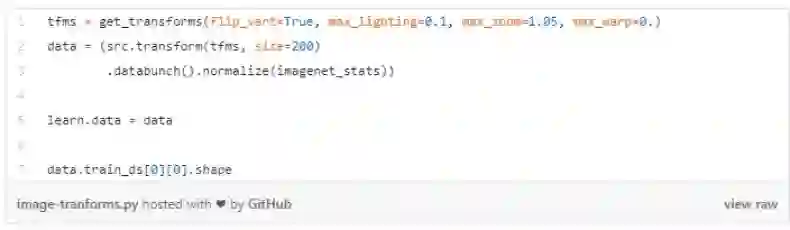
应用不同的转换以提升模型效果
max_lighting:如果超参不为 None,那么以 p_lighting 为概率随机进行亮度、对比度的调整,且最大亮度不超过 max_lighting。
max_zoom:如果超参不小于 1,那么以 p_affine 为概率随机放大 1 到 max_zoom 倍。
max_warp:如果超参不为 None,那么以 p_affine 为概率在-max_warp 和 max_warp 之间随机对称变换。
我们再一次搜索最优学习率:

搜索一个合理的学习率
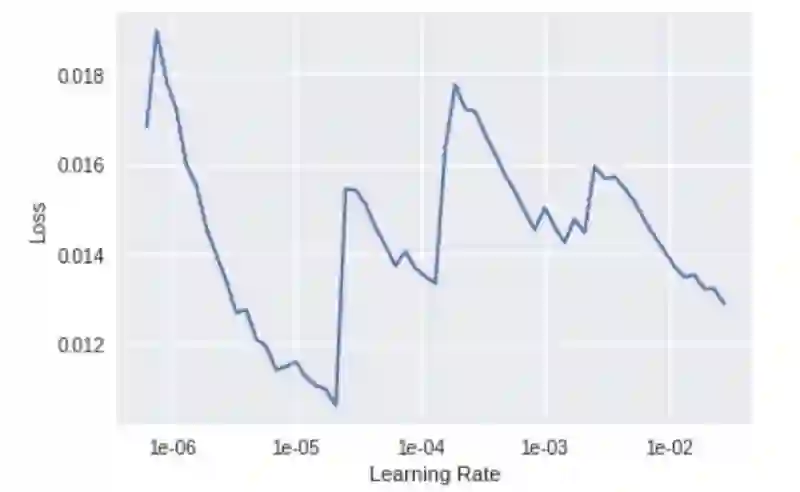
我们选择的学习率是 1e-6
将模型训练 5 个周期。

训练 5 个周期

训练和验证损失
比较训练指标,并与过去的指标进行比较。我们的模型在这次迭代中略逊于 0.0169 和 0.0163。先不要泄气。
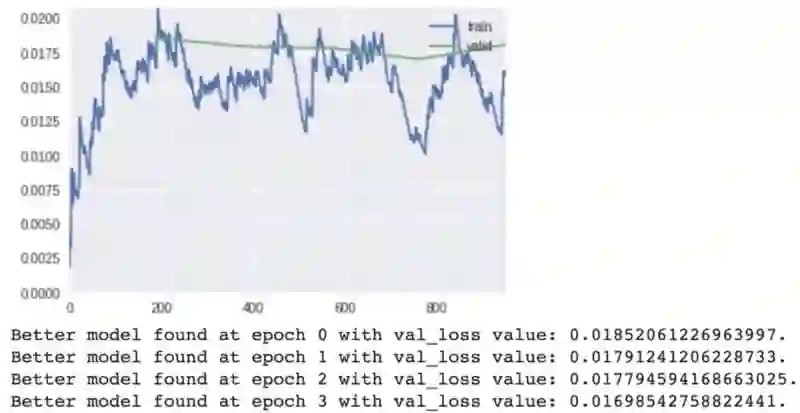
训练阶段模型的输出;在第 3 个 epoch 时得到最佳模型
保存模型训练的第三个阶段并打印出指标。如图所示,当前模型的准确率为 99.38,上一个阶段的准确率为 99.48%。AUC 分数从 99.87% 提高到了 99.91%,这是比赛评分的标准。

准确率、误差率和 AUC 分数

第三个训练阶段的指标
最终训练阶段
你可能注意到了,我们刚开始使用的图像大小为 164,然后逐渐增加到 256(如下所示)。这么做是为了利用 fast.ai 用于分类的渐进式图像大小缩放,即在一开始使用小图像,之后随着训练逐渐增加图像大小。如此一来,当模型早期非常不准确时,它能迅速看到大量图像并实现快速改进,而在后期训练中,它可以看到更大的图像,学到更多细粒度的差别。(详情请参见:现在,所有人都可以在 18 分钟内训练 ImageNet 了)

应用不同的变换来改进模型,将图像大小增加到 256
我们又发现了一个最佳学习率。

找到理想学习率
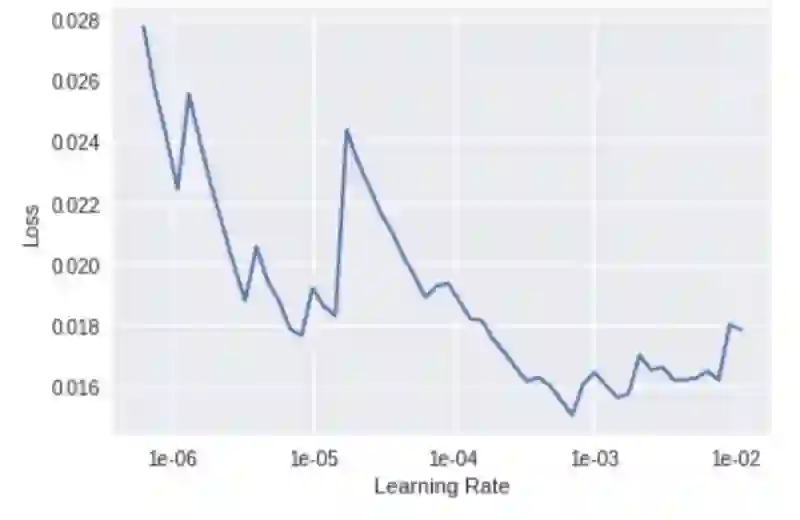
找到理想的学习率
以 1e-4 的学习率训练 5 个 epoch 以拟合模型。

以 1e-4 的学习率对模型训练 5 个周期

训练和验证损失
观察训练指标并与之前的指标对比。我们的模型有了小小的提升(损失从 0.169 降到了 0.168)。
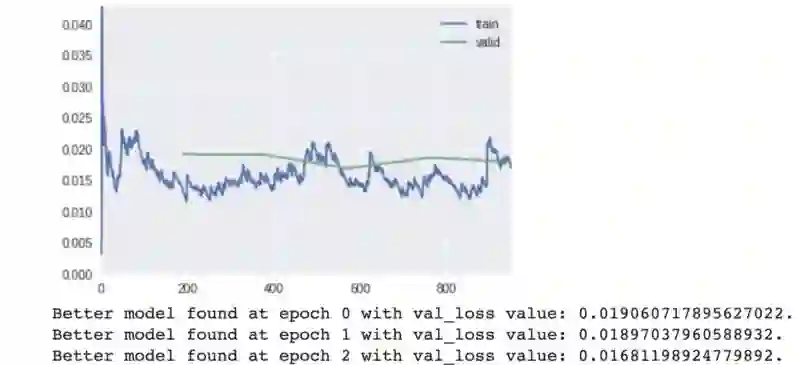
模型训练阶段的输出。在第 2 个 epoch 时得到最佳模型
保存模型最后的训练阶段并打印出指标。


准确率、误差率和 AUC 分数
如下所示,模型的准确率为 99.44%,优于上一个训练阶段 99.38% 的准确率。

第四个训练阶段的指标
准备一个竞赛提交文件
现在可以看到我们的模型对未见过的数据做出了多么好的预测。

准备一个 CSV 提交文件
将文件提交给 WiDS Datathon
你仍然可以参加 WiDS 竞赛并晚一点提交。进入参赛页面,点击「Join Competition」,了解比赛规则。现在你可以提交作品,看看自己会排到第几。

根据模型预测对提交的作品进行打分 
原文链接:https://towardsdatascience.com/how-a-team-of-deep-learning-newbies-came-3rd-place-in-a-kaggle-contest-644adcc143c8
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com





