何恺明团队最新力作RegNet:超越EfficientNet,GPU上提速5倍,这是网络设计新范式 | CVPR 2020
鱼羊 十三 发自 凹非寺
量子位 报道 | 公众号 QbitAI
大神(组团)出奇招,踢馆各路神经网络。
还是熟悉的团队,还是熟悉的署名,Facebook AI实验室,推陈出新挑战新的网络设计范式。
嗯,熟悉的Ross,熟悉的何恺明,他们带来全新的——RegNet。
不仅网络设计范式与当前主流“背道而驰”:简单、易理解的模型,也可以hold住高计算量。
而且在类似的条件下,性能还要优于EfficientNet,在GPU上的速度还提高了5倍!

新的网络设计范式,结合了手动设计网络和神经网络搜索 (NAS)的优点:
和手动设计网络一样,其目标是可解释性,可以描述一些简单网络的一般设计原则,并在各种设置中泛化。
又和NAS一样,能利用半自动过程,来找到易于理解、构建和泛化的简单模型。
论文毫无疑问也中了CVPR 2020。
PS:论文是3月30日在arXiv发布,So 大家不用担心是愚人节的玩笑……
三组实验对比,近乎“大满贯”
RegNet在性能上就是如此突出。
实验在ImageNet数据集上进行,目标非常清晰:挑战各种环境下的神经网络。
我们先来看下,与一众流行移动端神经网络的比较。
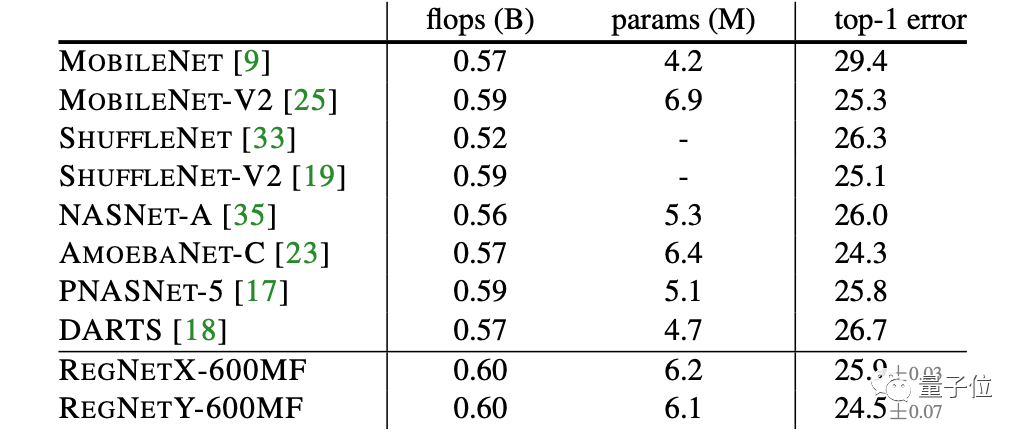
最近,许多网络设计工作都集中在移动机制(mobile regime,∼600MF)。
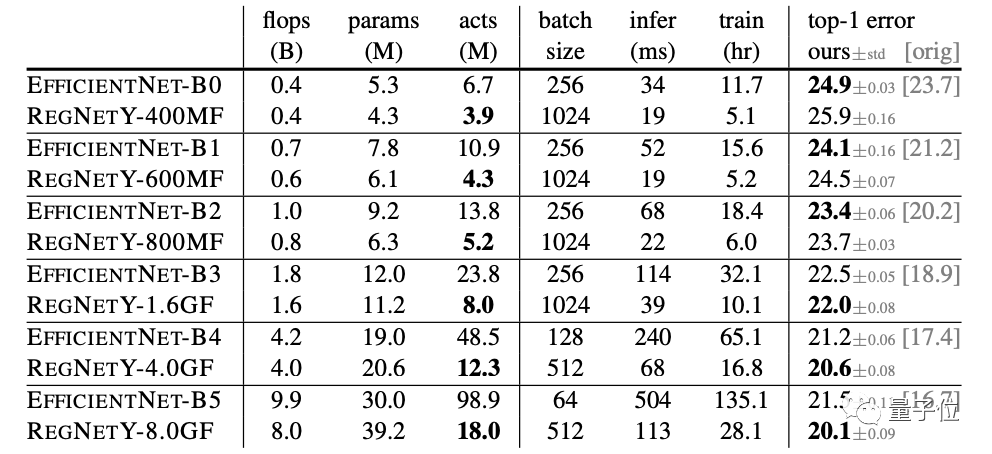
上表就是600MF的RegNet,与这些网络比较的结果。可以看出,无论是基于手动设计还是NAS的网络,RegNe的表现都很出色。
何恺明团队强调,RegNet模型使用基本的100 epoch调度(schedule),除了权重衰减外,没有使用任何正则化。
而大多数移动网络使用更长的调度,并进行了各种增强,例如深度监督、Cutout、DropPath等等。
接下来,是RegNet与标准基线ResNet和ResNeXT的比较。
为了公平起见,研究人员在相同的训练设置下,对它们进行对比,如下图所示:
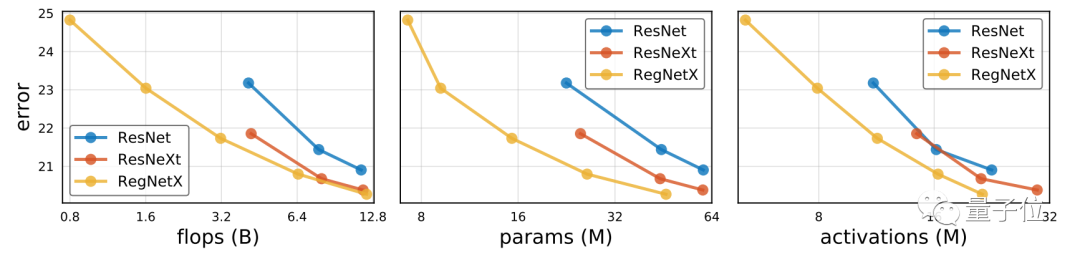
总体来看,通过优化网络结构,RegNet模型在所有复杂度指标下,都有了较大的改进。
研究人员还强调,良好的RegNet模型还适用于广泛的计算环境,包括ResNet和ResNeXT都不太适应的低计算环境。
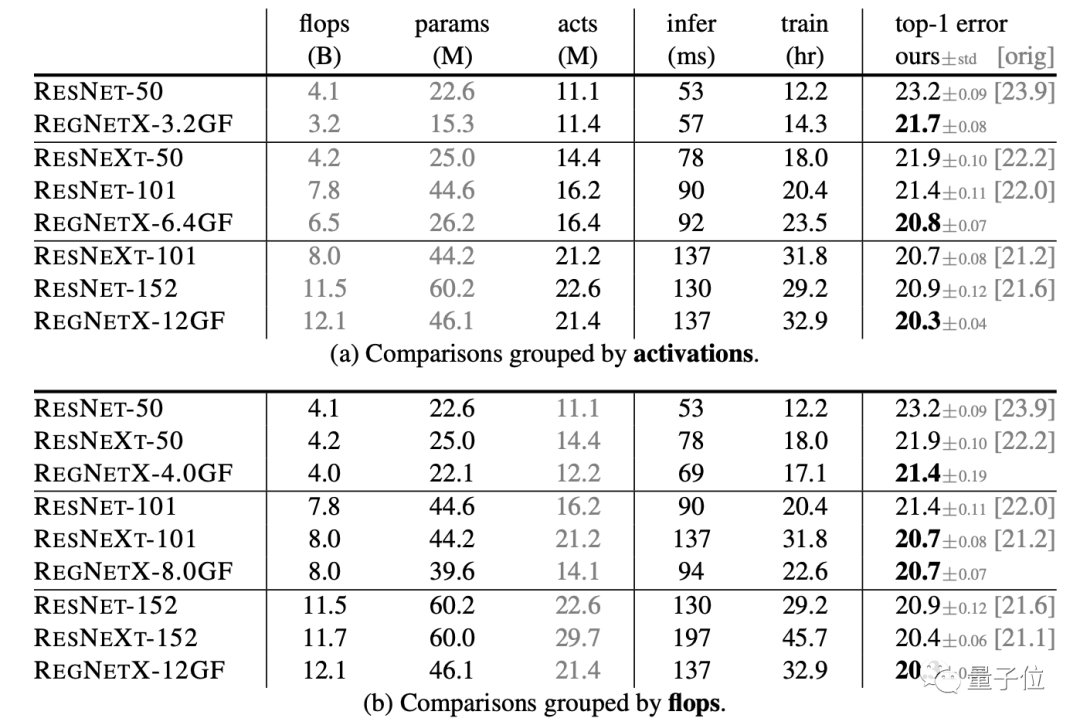
在上表(a)中,展示了按照activation分组的比较。
研究人员将activation定义为所有conv层的输出张量的大小,它会对像GPU这样的加速程度运行有较大的影响。
研究人员表示,这样设置的意义非常大,因为模型训练时间是一个瓶颈。未来可能在自动驾驶这样场景中,对改进推理时间有所帮助。给定固定的推理或训练时间,RegNet非常有效。
而在上表(b)中,展示了按照flops分组的比较。
最后,是RegNet与EfficientNet的比较。
EfficientNet,代表了当前最流行的技术,对比结果如下图所示:
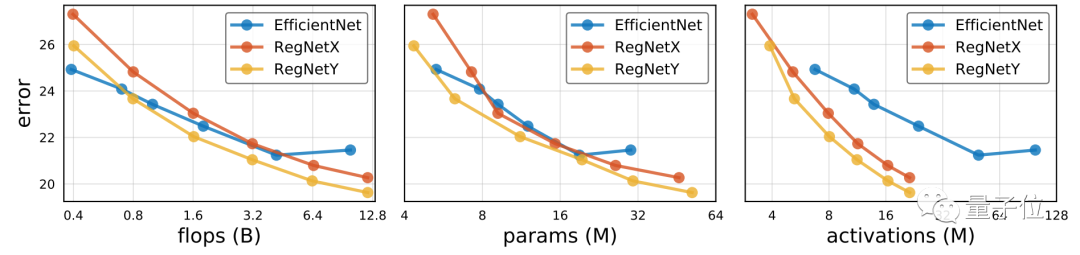
可以看到,在flops较低时,EfficientNet还有优势,但是随着flops的增大,RegNetX和RegNetY逐渐发力。
除此之外,何恺明团队发现,对于EfficentNet,activation与flops成线性关系;而对于RegNet,activation与flops的平方根成线性关系。
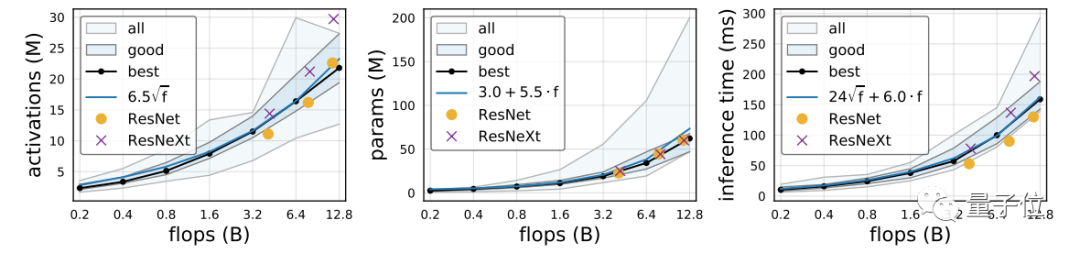
这就导致了EfficiententNet的GPU训练和推断速度变慢。而RegNeTX-8000比Efficient entNet-B5 快5倍,同时具有更低的误差,如下表所示:
如此性能,接下来问题来了,RegNet 究竟怎样炼成?
构建网络设计空间
这里首先介绍一下 Radosavovic 等人提出的网络设计空间(network design spaces)概念。
其核心思想是,可以在设计空间中对模型进行采样,从而产生模型分布,并可以使用经典统计学中的工具来分析设计空间。
在何恺明团队的这项研究中,研究人员提出,设计一个不受限制的初始设计空间的逐步简化版本。这一过程,就称为设计空间设计(design space design)。
在设计过程的每个步骤中,输入都是初始设计空间,输出则是更简单、或性能更好的模型的精简模型。
通过对模型进行采样,并检查其误差分布,即可表征设计空间的质量。
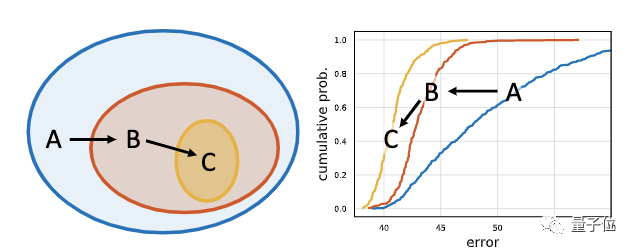
比如,在上图中,从初始设计空间A开始,应用2个优化步骤来生成设计空间B,然后是C。
C⊆B⊆A,可以看到,从A到B再到C,误差分布逐渐改善。
也就是说,每个设计步骤的目的,都是为了发现能够产生更简单、更有效模型的设计原理。
研究人员设计的初始设计空间是AnyNet。
网络基本设计很简单:主干(步幅为 2 的 3×3 卷积,32个输出通道)+ 执行大量计算的网络主体 + 预测输出类别的头(平均池化,接着完全连接层)。
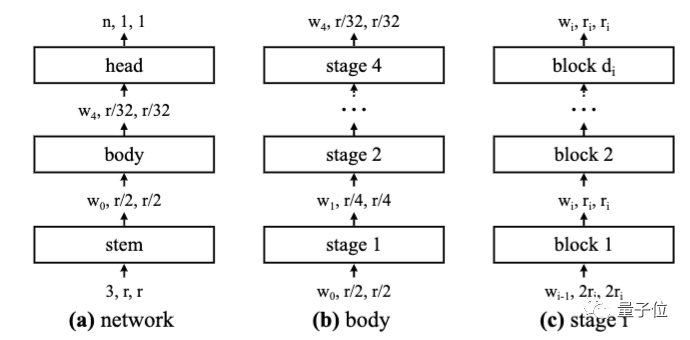
网络主体由一系列阶段组成,这些阶段以逐渐降低的分辨率运行。
除了第一个区块(使用 2 步长卷积)以外,每个阶段都包含一系列相同的区块。
虽然总体结构很简单,但 AnyNet 设计空间中可能存在的网络总数很庞大。
实验大多使用带有分组卷积的标准残差瓶颈块,研究人员称其为X block,在其基础上构建的 AnyNet 设计空间称为 AnyNetX。
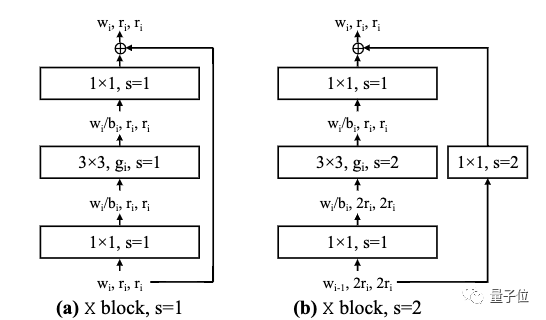
在 AnyNetX 上,研究人员旨在实现4个目的:
简化设计空间结构
提高设计空间的可解释性
改善或维持设计空间的质量
保持设计空间的模型多样性
于是,将初始的 AnyNetX 称作 AnyNetXA,开始进行“A→B→C→D→E”的优化过程。
首先,针对 AnyNetXA 设计空间的所有阶段,测试共享瓶颈率(bottleneck ratio)bi = b,将得到的设计空间成为 AnyNetXB。
同样,在相同设置下,从 AnyNetXB 采样并训练 500 个模型。
AnyNetXA 和 AnyNetXB 在平均情况和最佳情况下,EDF几乎不变。说明耦合 bi 时精度没有损失。并且,AnyNetXB 更易于分析。
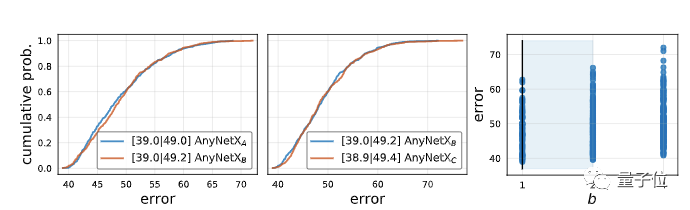
紧接着,从AnyNetXB开始,为所有阶段使用共享组宽度(shared group width),来获得 AnyNetXC。
与前面一样,EDF几乎没有发生变化。
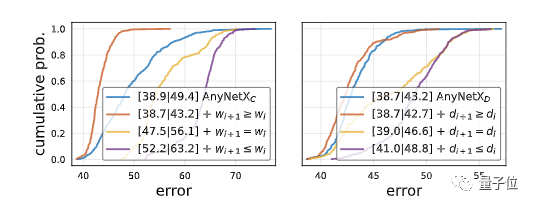
而后,研究人员在 AnyNetXC 中检验好网络和坏网络的典型网络结构。
他们发现:好网络的宽度是呈增长态势的。
于是,他们加入了设计原则 wi + 1 ≥ wi,将具有此约束条件的设计空间称为 AnyNetXD。
这大大改善了EDF。
△左:AnyNetXD,右:AnyNetXE
对于最佳模型,不仅仅是阶段宽度 wi 在增加,研究人员发现,阶段深度 di 也有同样的趋势,最后一阶段除外。
于是,在加入 di + 1 ≥ di 的约束条件之后,结果再一次改善。即 AnyNetXE。
在对 AnyNetXE 的进一步观察中,就引出了 RegNet 的一个核心观点:好网络的宽度和深度是可以用量化的线性函数来解释的。

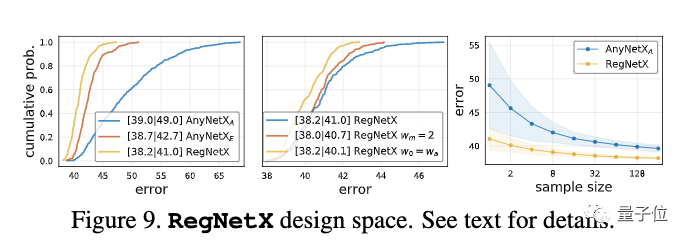
从 AnyNetXA 到 RegNetX,维度从16维降至6维,尺寸减小了近10个数量级。
从下图中可以看出,RegNetX 中的模型相比于 AnyNetX 中的模型,平均误差更低。并且,RegNetX 的随机搜索效率要高得多,搜索约32个随机模型就能产生好的模型。
设计空间泛化
一开始,为了提高效率,研究人员以低计算量、low-epoch 的训练方式设计了 RegNet 设计空间。
但是,他们的目标不是针对某一特定环境,而是发现网络设计的一般原理。
于是,他们在更高的 flops、更高的 epoch 的 5 步长网络中,以及各种不同类型的区块中,比较了 RegNetX 和 AnyNetXA、AnyNetXE。
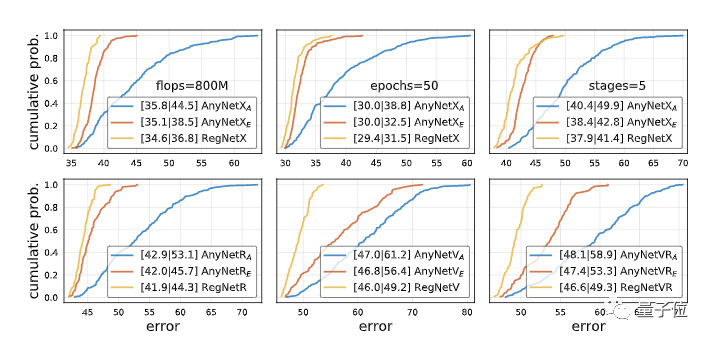
在所有情况下,设计空间都没有出现过拟合现象。
也就是说,RegNet 具有良好的泛化能力。
最后,还是照惯例来介绍下这支AI研究梦之队吧。
熟悉的面孔,熟悉的团队
Ross和何恺明,这个组合很熟悉了。
这次的五位作者,全部来自Facebook AI研究院。
论文一作,Ilija Radosavovic,伦敦帝国理工学院本科生助教,曾在Facebook实习。
Raj Prateek Kosaraju和Ross Girshick,博士分别毕业于佐治亚理工学院和芝加哥大学,都是FAIR计算机视觉方向的科学家。
最后一位作者Piotr Dollar,博士毕业于美国加州大学圣迭戈分校,目前也就职于FAIR。
中国人民最熟悉的自然是天才AI研究员何恺明了。
而且此次何恺明团队提出的RegNet,从名字上看,也神似自己当年的力作——ResNet——2016年CVPR最佳论文奖。
除此之外,Kaiming大神也分别在2009年和2017年,获得了CVPR和ICCV最佳论文奖,至今仍难有后来者。
(继续膜拜ing……)

有意思的是,在此次研究中,还以ResNet作为了基线做对比。
不过也不意外,从近几年的研究来看,何恺明也在不断突破自己以前的方法、研究。
在超越何恺明的道路上,目前跑得最快的,依然是何恺明自己。
嗯,大神的快乐,就是这么朴实无华,且低调。
我们先膜为敬,如何评价RegNet就留给大家啦~
传送门
论文地址:
https://arxiv.org/pdf/2003.13678.pdf
作者系网易新闻·网易号“各有态度”签约作者
— 完 —
如何关注、学习、用好人工智能?
每个工作日,量子位AI内参精选全球科技和研究最新动态,汇总新技术、新产品和新应用,梳理当日最热行业趋势和政策,搜索有价值的论文、教程、研究等。
同时,AI内参群为大家提供了交流和分享的平台,更好地满足大家获取AI资讯、学习AI技术的需求。扫码即可订阅:
了解AI发展现状,抓住行业发展机遇

AI社群 | 与优秀的人交流


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !


