SQL 编程思想:一切皆关系

来源:CSDN

在计算机领域有许多伟大的设计理念和思想,例如:
-
在 Unix 中,一切皆文件。 -
在面向对象的编程语言中,一切皆对象。
关系模型
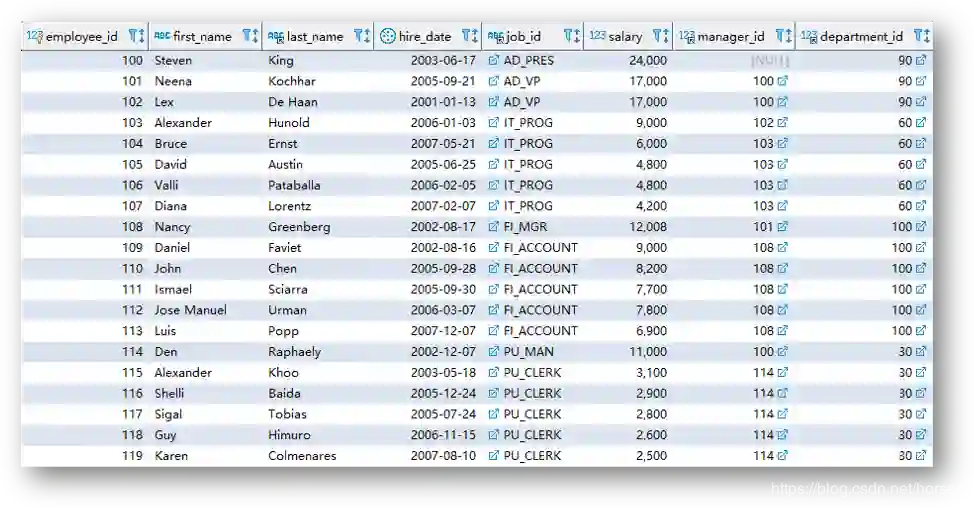
-
关系模型中的数据结构就是关系表,包括基础表、派生表(查询结果)和虚拟表(视图)。 -
常用的关系操作包括增加、删除、修改和查询(CRUD),使用的就是 SQL 语言。其中查询操作最为复杂,包括选择(Selection)、投影(Projection)、并集(Union)、交集(Intersection)、差集(Exception)以及笛卡儿积(Cartesian product)等。 -
完整性约束用于维护数据的完整性或者满足业务约束的需求,包括实体完整性(主键约束)、参照完整性(外键约束)以及用户定义的完整性(非空约束、唯一约束、检查约束和默认值)。
面向集合
📝在关系数据库中,关系、表、集合三者通常表示相同的概念。
SELECT
SELECT employee_id, first_name, last_name, hire_dateFROM employees;
SELECT *FROM (SELECT employee_id, first_name, last_name, hire_dateFROM employees) t;
-- PostgreSQLSELECT *FROM upper('sql');| upper ||-------|| SQL |

除了 SELECT 之外,还有一些常用的 SQL 子句。

ORDER BY 用于对查询的结果进行排序,示意图如下:
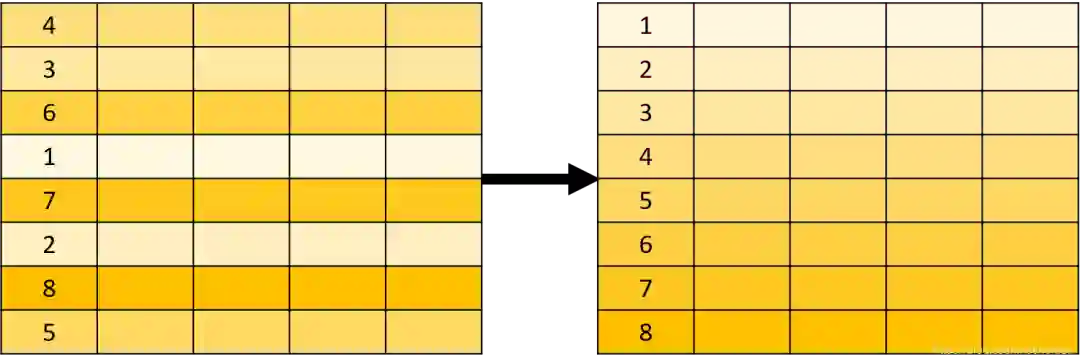
总之,SQL 可以完成各种数据操作,例如过滤、分组、排序、限定数量等;所有这些操作的对象都是关系表,结果也是关系表。

在这些关系操作中,有一个比较特殊,就是分组。
GROUP BY
SELECT department_id, count(*), first_nameFROM employeesGROUP BY department_id;
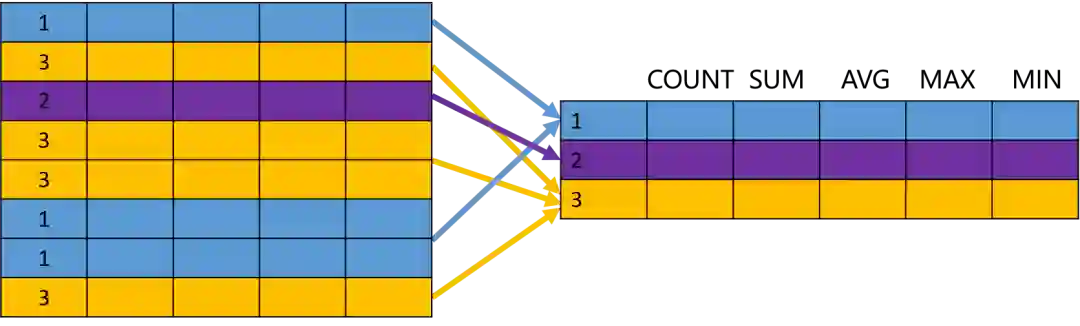
尽管如此,GROUP BY 的结果仍然是一个集合。
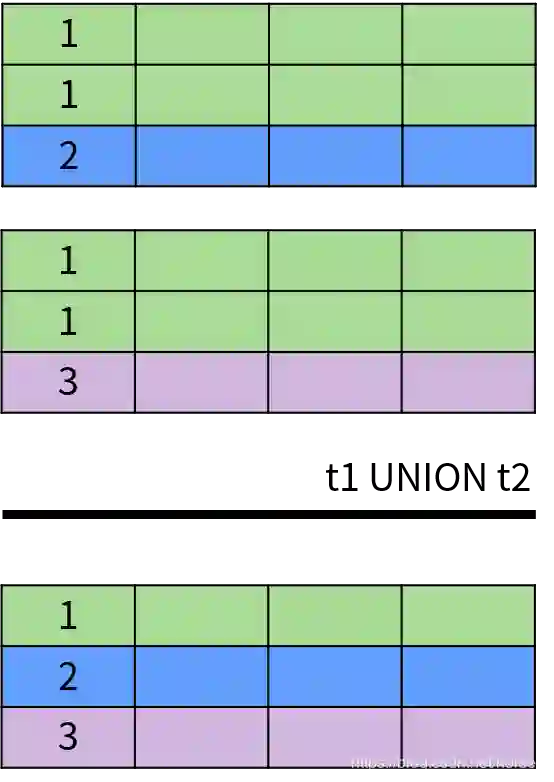
UNION
-
两边的集合中字段的数量和顺序必须相同; -
两边的集合中对应字段的类型必须匹配或兼容。
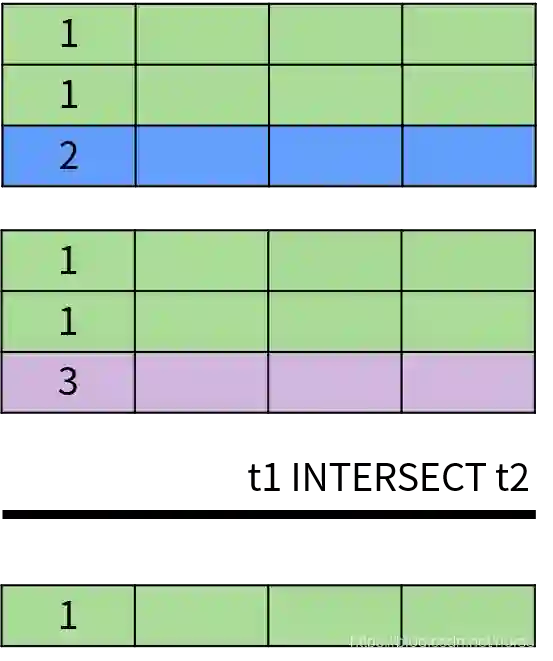
INTERSECT 操作符用于返回两个集合中的共同部分,即同时出现在第一个查询结果和第二个查询结果中的数据,并且排除了结果中的重复数据。INTERSECT 运算的示意图如下:
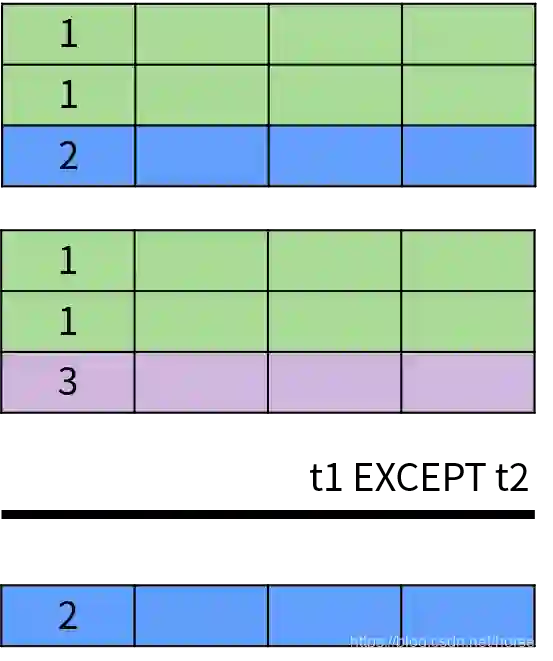
EXCEPT 或者 MINUS 操作符用于返回两个集合的差集,即出现在第一个查询结果中,但不在第二个查询结果中的记录,并且排除了结果中的重复数据。EXCEPT 运算符的示意图如下:
除此之外,DISTINCT 运算符用于消除重复数据,也就是排除集合中的重复元素。
📝SQL 中的关系概念来自数学中的集合理论,因此 UNION、INTERSECT 和 EXCEPT 分别来自集合论中的并集( ∪ \cup ∪)、交集( ∩ \cap ∩)和差集( ∖ \setminus ∖)运算。需要注意的是,集合理论中的集合不允许存在重复的数据,但是 SQL 允许。因此,SQL 中的集合也被称为多重集合(multiset);多重集合与集合理论中的集合都是无序的,但是 SQL 可以通过 ORDER BY 子句对查询结果进行排序。
JOIN

左外连接(Left Outer Join)返回左表中所有的数据;对于右表,返回满足连接条件的数据;如果没有就返回空值。左外连接的原理如下图所示:

右外连接(Right Outer Join)返回右表中所有的数据;对于左表,返回满足连接条件的数据,如果没有就返回空值。右外连接与左外连接可以互换,以下两者等价:
t1 RIGHT JOIN t2t2 LEFT JOIN t1

交叉连接也称为笛卡尔积(Cartesian Product)。两个表的交叉连接相当于一个表的所有行和另一个表的所有行两两组合,结果的数量为两个表的行数相乘。交叉连接的原理如下图所示:

📝其他类型的连接还有半连接(SEMI JOIN)、反连接(ANTI JOIN)。
SELECT department_idFROM departmentsUNIONSELECT department_idFROM employees;
SELECT COALESCE(d.department_id, e.department_id)FROM departments dFULL JOIN employees e ON (e.department_id = d.department_id);
DML
CREATE TABLE test(id int);-- MySQL、SQL Server 等INSERT INTO test(id) VALUES (1),(2),(3);-- OracleINSERT INTO test(id)(SELECT 1 AS id FROM DUALUNION ALLSELECT 2 FROM DUALUNION ALLSELECT 3 FROM DUAL);
SELECT *FROM (VALUES(1),(2),(3)) test(id);
本文链接:
https://blog.csdn.net/horses/article/details/104553075
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。



登录查看更多
相关内容

Arxiv
6+阅读 · 2018年1月24日



相关VIP内容
相关资讯
相关论文
Arxiv
6+阅读 · 2018年1月24日