NLP前路何在?Bengio等27位NLP顶级研究者有话说
机器之心整理
作者:Sebastian Ruder
机器之心编辑部
Deep Learning Indaba 2018 是由 DeepMind 主办的深度学习峰会,于今年 9 月份在南非斯泰伦博斯举行。在此次大会上,AYLIEN 研究科学家 Sebastian Ruder、DeepMind 高级研究科学家 Stephan Gouws 和斯泰伦博斯大学讲师 Herman Kamper 采访了 20 多名 NLP 领域的研究者,包括 Yoshua Bengio、阿兰•图灵研究所 Fellow Annie Louis 等,试图就 NLP 的研究现状、当前困境和未来走向等问题给出解答。
Sebastian Ruder 近日公布了这次采访的谈话实录,以及大会演讲的 PPT,对整个采访进行了总结。
采访实录:https://docs.google.com/document/d/18NoNdArdzDLJFQGBMVMsQ-iLOowP1XXDaSVRmYN0IyM/edit#heading=h.brxm2juq8i2
演讲 PPT:https://drive.google.com/file/d/15ehMIJ7wY9A7RSmyJPNmrBMuC7se0PMP/view
这些采访基于四个相同的问题,如下所示。机器之心摘录了部分受访者的回答内容,包括 Yoshua Bengio、阿兰•图灵研究所 Fellow Annie Louis、谷歌大脑研究科学家 George Dahl、纽约大学助理教授&FAIR 研究科学家 Kyunghyun Cho,其中有些研究者并没有回答完四个问题,这是基于受访者自身的意愿。
您能否列举目前困扰 NLP 领域的三大难题?
如果必须选择一个,您认为过去十年 NLP 领域最有影响力的研究是什么?
您觉得有没有什么把 NLP 领域带向了错误的方向?
您对刚启动项目的 NLP 研究生有什么建议吗?
Annie Louis(爱丁堡大学/图灵研究院 Fellow)
1. 您能否列举目前困扰 NLP 领域的三大难题?
1)域适应:我们某种程度上假设不同领域的语言有明显的不同,因为我们的模型无法很好地迁移。而人类可以阅读大部分领域的内容。那么人们抽象了什么,或者忽略了什么,迁移了什么知识?如何让系统在多个领域中良好地运转?
2)文本及对话生成:基于神经网络的方法对于这些系统的端到端训练非常有用,这些系统目前在易出错的流程中包含了太多的组件。但尽管现在的输出流畅性很好,但内容往往非常古怪:输出很容易出现曲解、重复、不完整等现象。我们以前遇到过相反的问题:内容很好,但流畅性差。
3)利用有限的数据进行学习:突然之间,NLP 的数据集都开始变得非常大。系统非常渴望数据。这些大型数据集的问题在于,它们通常是近似的,因为里面的数据是从网页或其他渠道利用启发式方法收集到的。例如,你得到的可能不是一份真正的摘要,而是为搜索引擎索引提供的网页概要。这种数据无法反映语言上的复杂性及手工标注数据中包含的有趣现象。因此,有时候我们可能不是在解决有趣的问题,而仅仅是让神经类型的系统为任务而工作。这不是件坏事,但我们需要转向更加有趣的事物。如果我们需要从 100 万份示例中学习,那么有关复杂现象的数据仍然是一个问题。
2. 如果必须选择一个,您认为过去十年 NLP 领域最有影响力的研究是什么?
这个问题不好回答。最近比较有影响力的研究应该是编码器-解码器框架中的序列到序列学习。这一概念已经在 NLP 领域中广泛应用。
3. 您觉得有没有什么把 NLP 领域带向了错误的方向?
我猜 NLP 领域的人应该也对计算语言学感兴趣,想利用计算技术得到一些关于语言的科学理解。这个角度如今在 NLP 大会中有点小众。我们在做大部分任务时也不再有语言学假设或基于任务的故事。模型通用性较强,普适的技巧也有一大堆,这些技巧不是为某个单独的任务定制的。说实话,我认为语言不同于语音或视觉。在语音或视觉领域,输入是信号或像素,我们并不知道如何利用它们计算特征。它们不是人类使用的自然形式。但语言不是这样,馈入系统的输入与人们在纸上读到的内容形式相同,人们可以用同样的形式教给另一个人。归根结底,我们需要探索更好的方法,向模型中添加先验知识,这样才能取得大的进步。
4. 您对刚启动项目的 NLP 研究生有什么建议吗?
NLP 领域的研究人员需要深厚的专业知识,还需要跨学科阅读,这点是毋庸置疑的。尽管对于学科的强调有所改变,但这点是不会变的。或许我们需要少读点心理学,多读点机器学习的内容。我建议大家尽早拓宽阅读面。目标要远大,不要专挑简单的任务和方法。要致力于解决那些在语言、社会、经济领域举足轻重的问题。
George Dahl(谷歌大脑)
1. 您能否列举目前困扰 NLP 领域的三大难题?
首先,如何构建更好的基准来大规模揭露我们当前方法存在的局限性?MultiNLI 是还不错的基准,但它仍有很多难以纠正的问题。
参考:https://arxiv.org/pdf/1803.02324.pdf
看看我们在流行基准上的准确率就能明白,我们对在构建自然语言读写系统方面取得的进步有些过于乐观了。
我们需要新的评估数据集和任务来表明我们的技术是否对人类语言的可变性具备泛化性。我更希望基准测试低估而不是像现在这样高估我们在自然语言方面取得的进步。
其次,我们如何将「方向盘」与文本生成模型连接在一起?我们如何创建能够听从高级指令(如生成什么)或遵循对生成内容的约束的模型?我希望模型能够基于简化或受限的自然语言指令(指令说明要做哪些高级改变)编辑一段文字。我们如何利用自然语言交互来操作语言形式(linguistic formalism)?我们如何构建交互式的「证明」(proof)协议,证明统计系统捕获了一篇文章的所有重点?
最后,如何生成更多信息含量更大的训练数据?我们能否创建可扩展到编辑或转述等事情的语言游戏(编辑或转述可以自然生成对比示例)?我们可以从人类标注者那里引出更多不同的语言例子吗?我们能否构建词袋模型完全无法处理的大规模训练数据集?或者,我们可以找到更好的办法来实现在无标注文本上的自监督吗?
2. 如果必须选择一个,您认为过去十年 NLP 领域最有影响力的工作是什么?
神经机器翻译的成功及其持续发展。它仍然脆弱,犯了很多错,但是 amazing!
3. 您觉得有没有什么把 NLP 领域带向了错误的方向?
过分依赖次优基准。我们很多模型的性能只比强大的词袋基线模型好一点点。我们的一些数据集构建得不太好或者极其有限(例如大部分 paraphrase 数据集)。
4. 您对刚启动项目的 NLP 研究生有什么建议吗?
学习如何精调模型,学习如何建立强大的基线模型,学习如何构建能经受住特定假设考验的基线。认真对待任何一篇论文,要不止一次地等待结论出现。很多情况下,你可以发表更加稳固的研究,做出更加强大的基线。
Kyunghyun Cho(纽约大学&FAIR)
1. 您能否列举目前困扰 NLP 领域的三大难题?
NLP/MT 领域最大的问题或许是下一次飞跃的时间和方向。NLP/MT 在过去半个世纪中经历了两次巨变。第一次发生在 90 年代早中期,彼时统计学方法成为主导,推动 NLP 领域远离基于规则的方法。第二次发生在 2012-2015 年,那时深度学习成为主流方法。每次飞跃不仅带来实证方面的改进,还动摇了我们对 NLP 领域和待解决问题的既定理解。那么下一次飞跃将会是怎样的呢?每个人都有自己的猜测,我认为下一次飞跃将由新的人/群体开启,就像前两次那样。
2. 如果必须选择一个,您认为过去十年 NLP 领域最有影响力的工作是什么?
很难选,不过我还是会选 Collobert & Weston (2008) 的研究《A unified architecture for natural language processing: deep neural networks with multitask learning》及其后续期刊论文《Natural Language Processing (Almost) from Scratch》。Collobert 和 Weston 在这些论文中提出并展示了基于神经网络的方法对 NLP 领域大量问题的有效性,这与当时其他人所做的研究都不相同。
3. 您觉得有没有什么把 NLP 领域带向了错误的方向?
我并不认为该领域曾走到错误的方向。我坚信,科学并不总是直线前进,而是通过带指引的随机游走加深理解。昨天看似错误的方向或许在今天或明天看来就是正确的。例如,2006 到 2012 年很多人(包括我自己在内)曾研究深度网络逐层无监督预训练方法,当时该方法看起来是非常有前景的,但是现在大家不再追求这种方法了(至少不再积极探索了)。这是错误的方向吗?我不这么认为,因为我们从那些年的研究中得到了很多(ReLU、摊销推理等都是那个时代的遗产)。类似地,在 2014 和 2015 年有很多论文将 word2vec 方法应用于各种问题,现在大部分问题都被遗忘了,这是错误的方向吗?兴许不是。我们只是需要这个阶段作为垫脚石。我认为更好的问题在于科学「有指引的随机游走」,指引(guide)是什么?
4. 您对刚启动项目的 NLP 研究生有什么建议吗?
我认为科学研究总是充满失败。你的 100 个想法中 99 个都会失败。如果每个想法都有效,那么要么是你太容易满足,要么你在自我欺骗,也有可能你是天才。至于天才,每个世纪大概会出一个吧。因此,我的建议是:不要失望!
Yoshua Bengio(蒙特利尔大学)
1 您能否列举目前困扰 NLP 领域的三大难题?
接地(气)的语言学习,即联合地学习世界模型以及将其和自然语言对应起来的方式。
在深度学习框架中融合语言理解和推理。
常识理解,这只能结合以上两个问题来解决。
3 您觉得有没有什么把 NLP 领域带向了错误的方向?
贪婪。我们正在竭力追求短期成果和回报,因此我们将大量文本数据丢给深度神经网络,希望模型能完全自发地、智能地理解和生成语言,但如果我们没有解决构建世界模型(即理解我们的世界如何运行的模型,其中建模了人类和智能体)这一更艰难的问题这行不通,无论我们设计了多少神经架构技巧,上述愿景都无法实现。我们需要咬紧牙关,结合其它领域来一起解决 NLP 的问题,而不是以一种孤立的方式。
4 您对刚启动项目的 NLP 研究生有什么建议吗?
要有野心。不要将自己的阅读范围限制在 NLP 论文领域。要读大量的机器学习、深度学习、强化学习论文。博士生涯是一个人实现远大目标的绝佳时期,即使是实现了目标的一小步也会有很大的价值。
更多采访内容请参见原文。我们再简单介绍一下演讲 PPT 的大致内容和结构,Sebastian Ruder 的演讲聚焦于三个主题:
什么是 NLP?它在过去几年中的主要发展有哪些?
目前困扰 NLP 领域的最大难题是什么?
了解当地社区并开始考虑合作
对于第一个主题,Sebastian Ruder 展示了近年来 NLP 领域的重要研究进展,包括自然语言模型、多任务学习、词嵌入等,如下图所示:
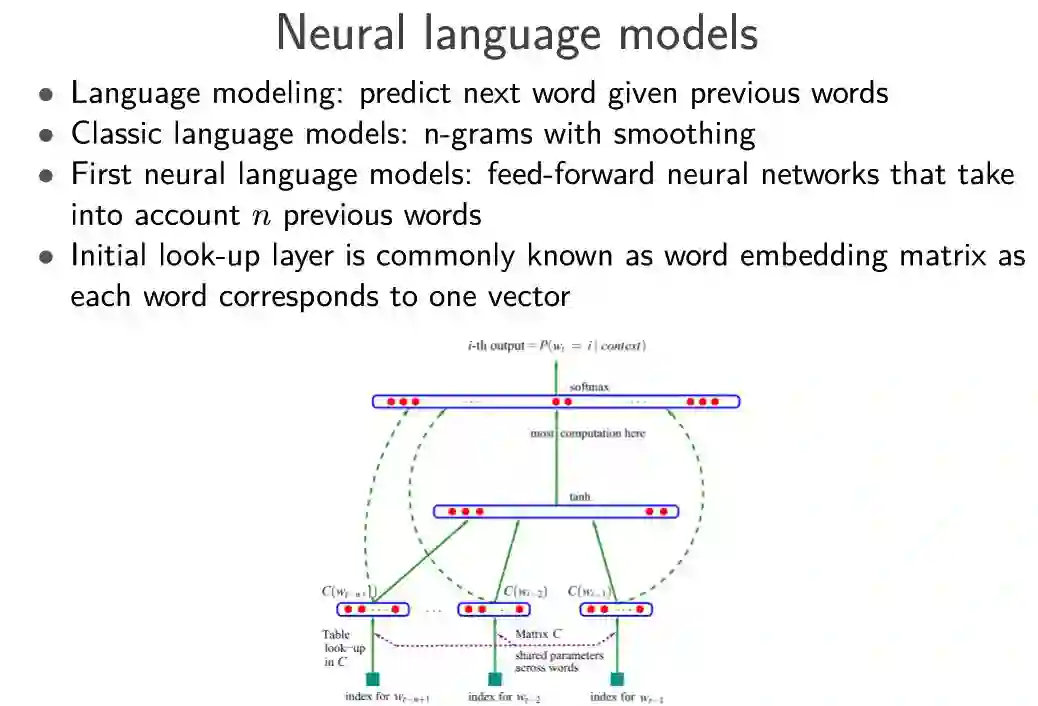
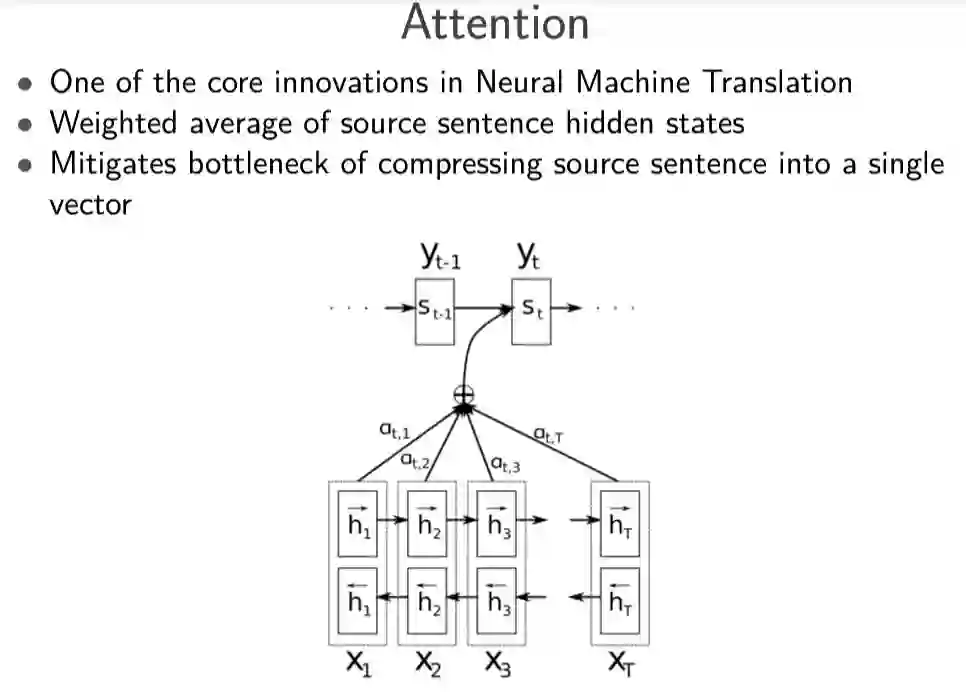
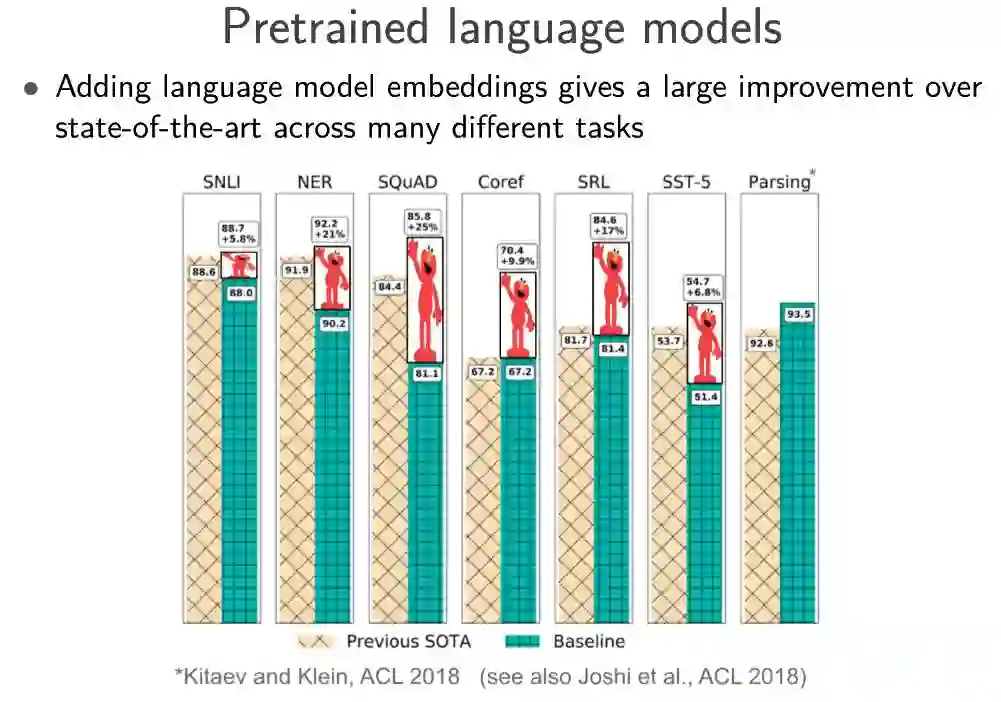
Sebastian Ruder 对每个进展列出了具体的突破性论文:
对第二个主题,Sebastian Ruder 等人通过受访研究者的谈话来解答,以下为受访人名单:

他们向多位研究者提出了上述提到的四个问题。
对于第一个问题,Sebastian Ruder 等人总结出研究者的回答涉及了以下层面:
自然语言理解
低资源场景下的 NLP
大规模或多文档推理
数据集、问题及评估
对于第三个问题,每个研究者都有着不同的理解:


更详细的演讲内容,请参见原文。

本文为机器之心整理,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




