【ICCV 13大不可错过的有趣项目】实时任意风格迁移、手机照片背景模糊……

【AI WORLD 2017世界人工智能大会倒计时 2 天】
“AI达摩”齐聚世界人工智能大会,AI WORLD 2017议程嘉宾重磅发布
在2017年11月8日在北京国家会议中心举办的AI World 2017世界人工智能大会上,我们邀请到阿里巴巴副总裁、iDST副院长华先胜,旷视科技Face++首席科学家、旷视研究院院长孙剑博士,腾讯优图实验室杰出科学家贾佳亚教授,以及硅谷知名企业家、IEEE Fellow Chris Rowen,共论人脸识别等前沿计算机视觉技术。
抢票链接:http://www.huodongxing.com/event/2405852054900?td=4231978320026
大会官网:http://www.aiworld2017.com
新智元编译
来源:techcrunch
作者:Devin Coldewey 编译:马文
【新智元导读】计算机视觉领域顶会之一的 ICCV 结束不久,图像质量提升、从头创建图像、风格迁移、图像描述等方面都出现许多新颖、创造性的工作。本文梳理了ICCV上13个最令人印象深刻的项目,一起来看。
打开新智元微信公众号,直接回复【ICCV 2017】下载全部论文


不要让手机的传感器和镜头小这个劣势妨碍了伟大的摄影作品。ICCV的这篇论文研究了在几个不同平台上拍摄的相同场景的照片,并对它们之间的差异进行建模。研究者提出一种算法,不仅能改变低质量照片的尺寸,还能在更深层次上进行转换,智能地精细调整照片的细节和颜色。它没有创造出不存在的东西,但它可以有助于提升照片质量,而不仅是调整曲线和对比度。
论文:DSLR-Quality Photos on Mobile Devices with Deep Convolutional Networks

用智能手机拍摄人像时添加人造的背景模糊很流行,但这不像使用魔棒工具抠出人像,然后模糊掉其余部分那样简单。头发或衣服的复杂性以及场景的视觉复杂性使算法不容易决定哪些像素是人的部分,哪些不是。来自腾讯和香港中文大学的研究者的这项工作将两种基本的计算机视觉工具结合在一起,形成一个更强大的工具。
一方面,这个系统使用简单的光流(optical flow)来表示图像中明显的边界,另一个物体识别系统将图像分割成明显的部分。通过将这两种分析的数据结合起来,系统可以减少识别错误,创建更精确的图像地图。这样,添加背景模糊就很方便了!
论文:High-Quality Correspondence and Segmentation Estimation for Dual-Lens Smart-Phone Portraits

想象一下,有一栋倒过来的房子,是用肉类做成的,还有人往上面倒芥末。这不是很愉快的形象,但你在脑海里想象这个场景没有任何困难,对吧?让计算机做同样的事情需要很强大的工具,也是一个有趣的挑战。
这类研究实际上以前做过,但结果并不好。在这个研究中,研究人员首先让计算机基于对单词和图像的认识,初步尝试创造图像。然后用另一种算法对结果进行评估,并提出改进的建议,让计算机细化图像。这有点像你针对脑海中的想法画了一个粗略的草图,然后看着草图继续修改。这个研究得到的照片仍然很粗糙,但重要的是,他们可以被辨认出来。
论文:StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
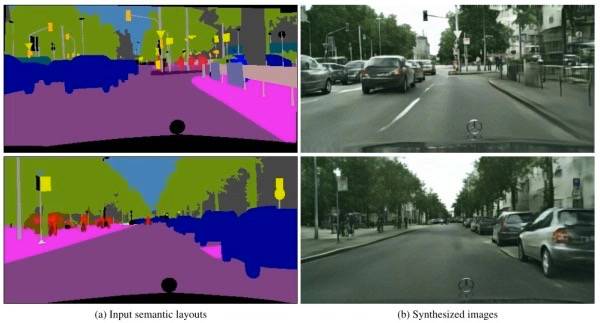
这个研究跟上一个相似,但不完全一样。想象一下,你想创造一个场景,把人物放在这儿,树木种在那儿,群山放到那边。你把这些信息输入给一个AI系统,它会搜索他的图像数据库,找到适合你需要的形状和大小的图像片段,然后将这些片段组合在一起。
由此产生的图像质量非常高——就像建筑模型一样,人和长凳等都被放在模型里面,显然它不是真实的,但是看起来很合理。你就可以用它模拟一个家庭,一个街景,或一个公园,就像用MSPaint画草图一样简单。
论文:Photographic Image Synthesis with Cascaded Refinement Networks
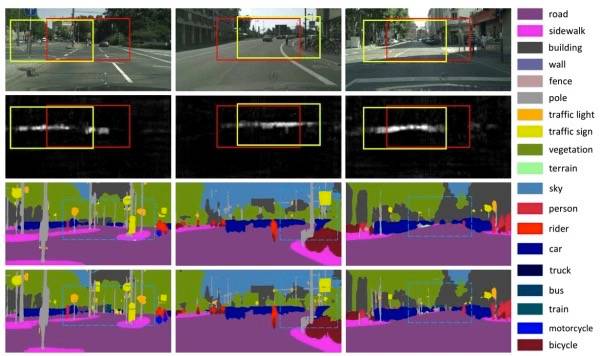
对于训练自动驾驶系统来说,一个最困难的部分是给系统充分标记好的录像,例如:这是一辆停着的车,这是一个电缆塔,等等。如果能够可靠地完成这些,你可以在几秒内快速注释几小时的视频,给自动驾驶的视觉系统提供大量额外信息。这就是该研究的目标,它提出一种新的方法,将深度感知(depth perception)结合进来,使识别对象更容易。它给视觉系统带来一些常识,告诉系统在这种情况下,不能将卡车和附近的一辆相同颜色,相同运动方向的电车混为一谈,他们是两个完全不同的对象。研究结果是实现了更可靠地标记图像中的对象和区域。
论文:FoveaNet: Perspective-aware Urban Scene Parsing

你可能已经认识风格迁移神经网络,它能使你的视频看起来像衣服印象派油画,或其他看起来永远需要人工创作的东西。风格迁移很酷,但通常仅限于预训练的一组外观,而且需要时间让系统表现良好。
这个研究描述了一种新的风格迁移网络,它不仅可以实时地工作,而且可以将任何场景或图像作为输入,并立即应用。不喜欢梵高《星夜》(Starry Night)的风格?还有蒙克《呐喊》(The Scream)的版本,看看这是不是你喜欢的风格。期待做成一款app。
论文:Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization

让计算机描述视频中发生的事件是非常困难的,因为场景往往比“小孩子在房间里走动”这样的单个句子要复杂得多。这可能是最主要的事件,但那只会在中途吠叫的狗呢? 还有最后家长们的欢呼呢? 视频通常包含许多事件,相关的和不相关的,任何观众可以很容易地描述所有事件。 那么为什么机器学习系统不可以呢?
这就是这篇论文描述的:一个可以描述时间上重叠的事件的系统,或者可以将不同长度和起始点的时间联系起来。你可以想象一下,如果要在YouTube上找到一个指定长度的视频片段,这样的系统是多么有用——你可以直接跳到视频中“大猩猩出现的部分”。
论文:Dense-Captioning Events in Videos

请观察左边的图像。下面的两种文字说明,哪个更好,更像人的描述?“一只牛站在房子前面”和“一只灰色的牛在房子前面一片绿色的草地上散步”。可能是后者更好。但是,计算机对描述听起来像人的描述的东西没有任何直觉的理解——除非它们被教导使自己的描述类似人类的自然描述。
在这个研究中,一个神经网络被用来创造关于场景的描述,另一个网络则将这个描述与人类创造的描述进行对比,并给与人类的话语风格更相像的描述更高的得分。这可以使计算机对图像和视频的描述更自然——不是“小孩走向一辆车”,更多描述成“一个小女孩走向一辆米色的小货车。”
论文:Towards Diverse and Natural Image Descriptions via a Conditional GAN

机器学习系统有一个弱点时根本性的,就是它们对于行为和对象的“词汇量”通常非常有限。它可能理解“人骑马”,而不是骑“狗”。因此,如果有人骑着什么东西,这个东西肯定不是“狗”——或者,如果一个人在狗上方,那人肯定不是在“骑”它。但是对象和行为的不寻常的组合总是经常发生——事实上,这些组合常常是最值得记录的!
在这个研究中,系统被训练来基于空间线索( spatial cues)来识别物体和它们之间的关系,无论是什么类型的物体。虽然这个系统可能从来没有见过一只“猪”在“煎煎饼”,但当它看到这样的场景,它能够正确描述——因为它有基本的概念,知道猪是什么样子的,煎饼是什么样子的,煎炸的动作时怎样的,然后将这些组合在一起。
论文:Weakly-supervised learning of visual relations

人们在提出有关图像或情景的问题时,并不总是使用很精确的语言。例如,他们不会说:“蓝色的车后面有人吗?”,而是问,“有人在车后面吗?”。除非系统知道“有人”(anyone)是指什么,以及你指的是哪辆车,否则它可能会宕机。在这个研究中,研究人员提出一种机器学习系统的方法,它可以让系统在运行中对你的意思做出最接近的猜测,并试图找到答案。
问题的关键在于找出需要解决哪些问题(其中有多少问题,如何描述这个问题),以及这些问题有怎样的关联——对于计算机来说,这是相当困难的。不过,这篇论文建立了一个相当有效的系统。
论文:Inferring and Executing Programs for Visual Reasoning
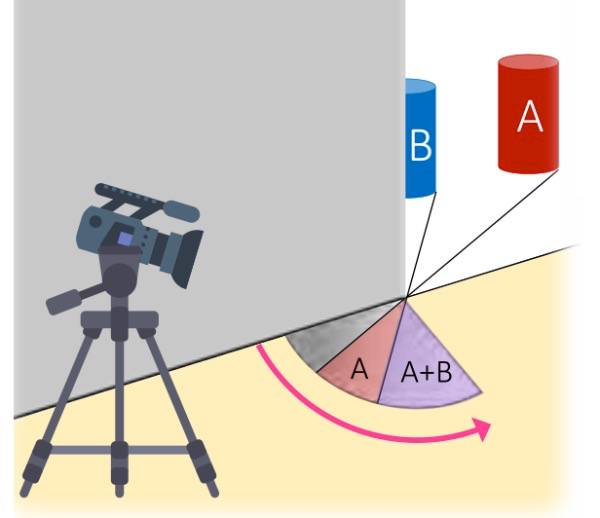
对于人类来说,有时你能分辨出角落里不能直接看到的东西,例如,你知道电视机在角落里,因为你能看到它的光反射在闪亮的地板上。如果你仔细观察,你或许还能从这些光的细微变化找到更多关于这个场景的信息。这个研究提出的就是这样一个系统。
通过仔细观察从角落可以看到的不同角度的光线(但不需要绕过去看),这个系统将颜色、空间关系等基本特征显示成一个“1-D视频”。虽然不能“看到”很多信息,但只要研究附近的地面就能看到角落里的任何东西,这是相当令人印象深刻的。
论文:Turning Corners into Cameras: Principles and Methods

了解参加一项活动的人数有多少,对于规划人员和场馆管理人员至关重要,但是除非你仔细追踪每个进场和离场的人,否则很容易搞混计数。 人们可以计算出约略的数字,比如一个房间里的人数可以说“大约250人”,但是消防调查人员往往需要确切的数字。这个系统旨在快速准确地统计照片中的人数,并且与其他方法相比取得更好的结果。
论文:Generating High-Quality Crowd Density Maps using Contextual Pyramid CNNs
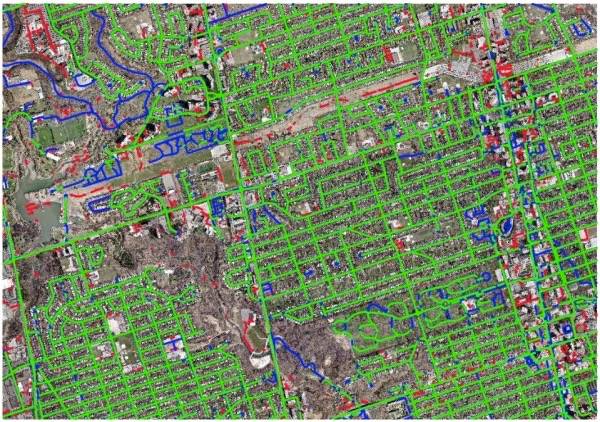
只需要利用航空影像,自动得出道路的走向,这是人们多年来一直在研究的工作——但是很难。现在,机器学习系统可以对图像进行分析,并能够很好地理解他们没有实际上看到的部分。这个系统利用多伦多大部分地区的数据进行训练,然后在该市其他区域进行应用。结果非常好。
上图中绿色的线是系统标记正确的敌方,红色是标记错误,蓝色是没有标记作道路的地方。这个系统虽然不完美,线条有一点扭曲,但是作为一个完全自动化的系统的第一次作业,这个结果并不差。人类工作者或其他系统可以进行下一步的处理。
论文:DeepRoadMapper: Extracting Road Topology from Aerial Images
11月8日新智元AI World 2017世界人工智能大会,阿里巴巴副总裁、iDST副院长华先胜,旷视科技Face++首席科学家、旷视研究院院长孙剑,腾讯优图实验室杰出科学家贾佳亚等多位计算机视觉技术领袖,将共论视觉前沿。
深入了解AI 技术进展和产业情况,参加新智元世界人工智能大会,马上抢票!
【AI WORLD 2017世界人工智能大会倒计时 2 天】点击图片查看嘉宾与日程。
抢票链接:http://www.huodongxing.com/event/2405852054900?td=4231978320026
AI WORLD 2017 世界人工智能大会购票二维码:





