「千言」是由百度联合中国计算机学会、中国中文信息学会共同发起的面向自然语言处理的开源数据集项目,旨在推动中文信息处理技术的进步。近日,在 2021 年 12 月 12 日的 WAVE SUMMIT+2021 深度学习开发者峰会上,清华大学长聘副教授黄民烈作了题为「千言:数据驱动技术进步」的演讲,回顾了千言过去一年中取得的进展和广泛影响力,并发布了千言的全新升级,重点聚焦大模型时代的机遇和挑战。此外,千言还推出了「百 +」计划,邀请更多的专家学者共同建设千言,构建世界范围内的中文 NLP 影响力。
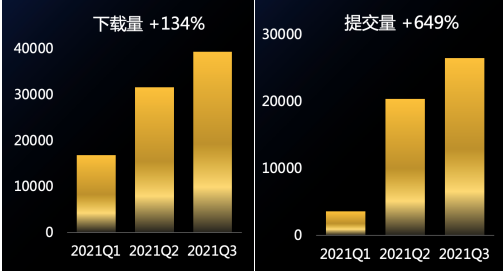
「千言」开源数据集项目自 2020 年 8 月发布以来,已经有来自清华、哈工大、中科院、美团、OPPO 等 14 家单位的数据集作者加入共同建设,目前已经覆盖了 10 多个自然语言处理的任务,包含了开放域对话、机器阅读理解、机器同传、文本生成、情感分析等任务。「千言」为研究者提供了一站式的数据集浏览、整理、下载以及评测体验,受到了越来越多研究者的关注和使用,数据集下载量增长 134%,相关任务的提交次数增长 649%,增长非常显著。
![]()
此外,千言还推动了多项自然语言处理的评测,截至目前总共支持了 20 多项技术评测,包含了语言与智能技术竞赛(LIC 2021)、CCF BDCI 多技能对话评测、NLGIW 2021 面向事实一致性的生成评测、CCF BDCI 问题匹配鲁棒性评测、NAACL 2021 机器同传评测等。其中,参与评测的人员有 57% 来自高校和科研院所,21% 来自企业,在学术界和工业界都产生了很大的影响力。开源数据集和技术评测的联动,很好的推动了相关任务的技术研究和应用发展。
「千言」升级:聚焦通用、可信、跨模态等大模型时代的机遇和技术挑战
推动人工智能技术进步的三大驱动力是算法、算力和数据。其中,数据作为最重要的基础,其数量和质量直接决定了算法能够达到的上限水平。人工智能的历史上,优秀的数据集极大地推动了领域技术的发展和行业的进步。近两三年,随着大模型技术的出现和发展,基于大模型的自然语言处理技术也取得了长足的进步。在取得进步的同时,大模型也带来了新的技术挑战和新的技术机遇,包括了通用、可信、跨模态等。「千言」的升级也重点聚焦在了这三个方面。
第一,通用。通用指模型需要具有全面的、处理多个子任务的能力,同时需要在跨领域数据上具有较好的泛化能力。「千言」推出了多技能对话任务和多形态信息抽取任务来促进模型通用性的提升。在多技能对话任务中,期望模型能够同时处理多种对话子任务,包括知识对话、闲聊对话、推荐对话、画像对话等;在多形态信息抽取任务上,期望模型能够同时处理句子级关系抽取、句子级事件抽取和以及篇章级事件抽取等任务。
第二,可信。可信是指模型在应用中需要有足够的鲁棒性、较高的可解释性以及结果的一致性。其中,为了促进提升模型的鲁棒性,「千言」发布了问题匹配鲁棒性数据集 DuQM、阅读理解鲁棒性数据集 DuReaderchecklist。为了提升模型的可解释性,「千言」发布了情感分析可解释数据集 DuTrust。在事实一致性方面,「千言」则推出三个生成任务来综合进行评测,分别包括了文案生成数据集 AdvertiseGen、摘要生成数据集 LCSTS、问题生成数据集 DuReaderQG。
第三,跨模态。跨模态是指随着内容承载形式的多元化,模型需要具有多模态融合(语言、图像、语音、视频等)的内容理解等能力。为此,「千言」推出了机器同传数据集 BSTC 以及跨模态情感分析数据集 DuVideoSenti 来促进跨模态领域的发展。机器同传主要关注语言和语音跨模态的交互,而跨模态情感分析主要关注语言和视频跨模态的交互。
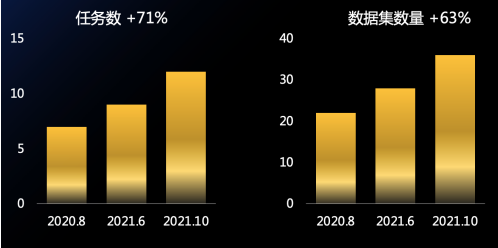
经过了一年的发展,千言所覆盖的任务和数据集数量显著增加,从最开始的 7 个任务,发展到最新的 12 个任务,对应的数据集数量,也从最开始的 22 个数据集,增加到了现在 36 个数据集。
![]()
千言「百 +」计划:共同构建世界范围内中文 NLP 的影响力
为了更好地帮助数据集作者提升数据集影响力和推进相关技术发展,千言项目正式推出了「百 + 计划」,覆盖了「百 + 数据集作者」和「百 + 技术专家」。作为「百 + 数据集作者」,会被邀请进入千言学术委员会。千言会帮助数据集作者发布评测,并提供飞桨开源基线、评测平台和 GPU 算力的支持,提升数据集的影响力,推动技术的发展。「百 + 技术专家」则是针对优秀开发者和学生的认证,技术专家可以得到大量分享和交流技术方案的机会,并会受邀参与官方活动。
![]()
中文是千年华夏文明传承的载体,是中华民族的骄傲和根基。在当下的人工智能时代,「千言」数据开源项目也希望与学术界、产业界携手,共同推动中文信息处理技术的进步,理解语言、拥有智能,改变世界,将华夏文明的宝藏学习并传承下去。
访问 https://luge.ai 或者扫描下方的二维码加入千言交流群来了解更多关于千言数据集的详细信息。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com