如何成为一名异构并行计算工程师

作者 | 刘文志
责编 | 何永灿
随着深度学习(人工智能)的火热,异构并行计算越来越受到业界的重视。从开始谈深度学习必谈GPU,到谈深度学习必谈计算力。计算力不但和具体的硬件有关,且和能够发挥硬件能力的人所拥有的水平(即异构并行计算能力)高低有关。
一个简单的比喻是:两个芯片计算力分别是10T和 20T,某人的异构并行计算能力为0.8,他拿到了计算力为10T的芯片,而异构并行计算能力为0.4的人拿到了计算力为20T的芯片,而实际上最终结果两人可能相差不大。异构并行计算能力强的人能够更好地发挥硬件的能力,而本文的目标就是告诉读者要变成一个异构并行计算能力强的工程师需要学习哪些知识。
异构并行计算是笔者提出的一个概念,它本质上是由异构计算和并行计算组合而来,一方面表示异构并行计算工程师需要同时掌握异构计算的知识,同时也需要掌握并行计算的知识;另一方面是为更好地发展和丰富异构计算和并行计算。通过异构并行计算进一步提升了知识的系统性和关联性,让每一个异构并行计算工程师都能够获得想要的工作,拿到值得的薪水。
对于一个异构并行计算工程师的日常来说,他的工作涉及的方面很广,有硬件,有软件,有系统,有沟通;是一个对硬实力和软实力都有非常高要求的岗位。
异构并行计算的难度是非常高的,而市场对这个职位的需求一直在提升,期待读者能够和我一起投身于异构并行计算的行列,为异构并行计算在中国的推广做出贡献。
异构并行计算工程师技能树
要想成为一个优秀的异构并行计算工程师需要掌握许多知识和技能,这些技能可以分为两个方面:
处理器体系,处理器如何执行具体的指令;
系统平台方面,这又可以分成多个细的主题,包括硬件的特点,软件编程相关的平台和基础设施。
读者可以从图1具体了解到异构并行计算工程师需要掌握的技能和知识。
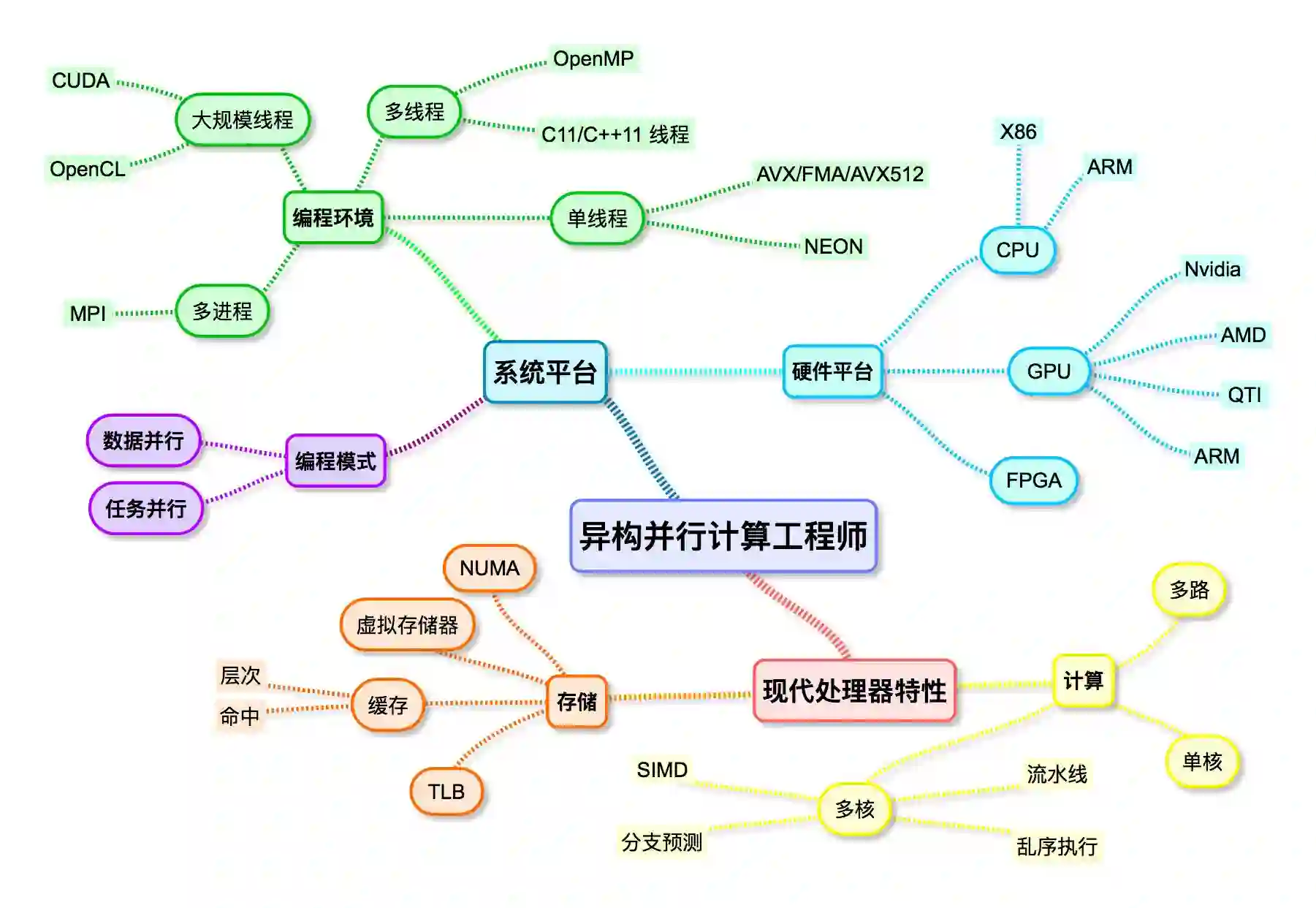
图1 异构并行计算工程师技能树
异构并行计算工程师成长详解
每个人甚至每个技术领域都是在不停的成长,通常公司的岗位会区分为初级、中级、高级、主任等,这是按照贡献、能力和责任大小来分,并不适合用来表示技术。为了更好地帮助读者学习知识,本文从技能体系角度来分析,因此并不能对应到各个公司招聘的岗位需求上,也意味着读者不能简单的把本文的技能和各个公司的岗位级别对应。
为了帮助读者更好地理解,本文会使用先硬件后软件的方式介绍。和异构并行工程师相关性最大的硬件知识即处理器特性,我们从这一点开始。
现代处理器的特性
从系统启动到终止,处理器一条接着一条地执行存储器中的指令,站在使用者的角度来看就好像是前一条指令执行完之后下一条指令才开始执行,是一个完完全全的串行过程。实际上,现代处理器利用了指令级并行技术,同一时刻存在着多条指令同时被执行,并且处理器执行指令的顺序无需和汇编代码给出的指令顺序完全一致,编译器和处理器只需要保证最终结果一致即可,这类处理器称为“乱序执行处理器”。而严格按照顺序一次执行一条指令,只有前一条执行完才开始执行后一条指令的处理器,称为“按序处理器”。而即使是在按序执行处理器上,编译器也可以对源代码进行类似的优化,以提高程序性能。对于一个特定的流水线来说,现代乱序执行处理器只保证指令执行阶段可以乱序,而其他阶段通常还是顺序的。目前主流的CPU和GPU,甚至DSP,无论是在服务器端,还是在移动端基本上都已经是乱序执行处理器了。
今天大多数处理器都是哈佛架构的变体,其根本特征是在程序执行时把指令和数据分开存储,程序员通常可以忽略指令存储,实际上异构并行计算更关注的是:计算和数据访问。
计算和访存
以作者正在使用的处理器E5-2680v3来说,其主频为2.6GHz,支持FMA指令集,其单核单精度浮点计算能力为2.6*2*8*2=83.2 GFlops;而单通道内存的带宽大约为20GB/s。主流处理器的处理速度远快于内存读写速度,为了减小访问数据时的延迟,现代主流处理器主要采用了两种方式:
利用程序访问数据的局部性特点:采用了一系列小而快的缓存保存正在访问和将要被访问的数据,如果数据会被多次访问且数据能够被缓存容纳,则能够以近似于内存的价格获得近似于缓存的速度;
利用程序的并行性:在一个控制流由于高延迟的操作而阻塞时,执行另一个控制流,这样能够提高处理器核心的利用率,保证处理器核心一直在忙碌的状态。
简单来说,前一种方法是将经常访问的数据保存在低延迟的缓存中,以减少访问数据时的延迟,通过更快为处理器提供数据而提高性能,主要是目前主流的CPU采用。而后一种方法则尽量保证运算单元一直在忙碌工作,通过提高硬件的利用率以提高程序的吞吐量,这种方法目前主要为主流的GPU所采用。这两种办法没有天然的壁垒,现代处理器(无论是CPU还是GPU)都采用了这两种方法,区别只是更偏重于使用哪一种方法。
指令级并行
现代处理器具有许多和代码性能优化相关的特点,本节主要介绍以下部分:
指令级并行技术:主要有流水线、多发射、VLIW、乱序执行、分支预测、超标量等技术;
向量化:主要有SIMT和SIMD技术;软件开发人员如果了解现代多核向量处理器的这些特性,就能写出性能效率超过一般开发人员的代码。
多核
多核是指一个CPU模块里包含多个核心,每个核心是一个独立的计算整体,能够执行线程。现代处理器都是多核处理器,并且为多核使用场景所优化。
多核的每个核心里面具有独立的一级缓存,共享的或独立的二级缓存,有些机器还有独立或共享的三级/四级缓存,所有核心共享内存DRAM。通常第一级缓存是多核处理器的一个核心独享的,而最后一级缓存(Last Level Cache, LLC)是多核处理器的所有核心共享的,大多数多核处理器的中间各层也是独享的。如Intel Core i7处理器具有4~8个核,一些版本支持超线程,其中每个核心具有独立的一级数据缓存和指令缓存、统一的二级缓存,并且所有的核心共享统一的三级缓存。
由于共享LLC,因此多线程或多进程程序在多核处理器上运行时,平均每个进程或线程占用的LLC缓存相比使用单线程时要小,这使得某些LLC或内存限制的应用的可扩展性看起来没那么好。
由于多核处理器的每个核心都有独立的一级、有时还有独立的二级缓存,使用多线程/多进程程序时可利用这些每个核心独享的缓存,这是超线性加速(指在多核处理器上获得的性能收益超过核数)的原因之一。
多路与NUMA
硬件生产商还将多个多核芯片封装在一起,称之为多路,多路之间以一种介于共享和独享之间的方式访问内存。由于多路之间缺乏缓存,因此其通信代价通常不比DRAM低。一些多核也将内存控制器封装进多核之中,直接和内存相连,以提供更高的访存带宽。
多路上还有两个和内存访问相关的概念:UMA(均匀内存访问)和NUMA(非均匀内存访问)。UMA是指多个核心访问内存中的任何一个位置的延迟是一样的,NUMA和UMA相对,核心访问离其近(指访问时要经过的中间节点数量少)的内存其延迟要小。如果程序的局部性很好,应当开启硬件的NUMA支持。
硬件平台
异构并行计算人员的能力最终需要通过运行在硬件上的程序来证明,这意味着异构并行计算编程人员对硬件的了解与其能力直接正相关。
目前大家接触到处理器主要类型有:X86、ARM、GPU、FPGA等,它们的差别非常大。
X86
X86是Intel/AMD及相关厂商生产的一系列CPU处理器的统称,也是大家日常所见。X86广泛应用在桌面、服务器和云上。
SSE是 X86 向量多核处理器支持的向量指令,具有16个长度为128位(16个字节)的向量寄存器,处理器能够同时操作向量寄存器中的16个字节,因此具有更高的带宽和计算性能。AVX将SSE的向量长度延长为256位(32字节),并支持浮点乘加。现在,Intel已将向量长度增加到512位。由于采用显式的SIMD编程模型,SSE/AVX的使用比较困难,范围比较有限,使用其编程是一件比较痛苦的事情。
MIC是Intel的众核架构,它拥有大约60左右个X86核心,每个核心包括向量单元和标量单元。向量单元包括32个长度为512位(64字节)的向量寄存器,支持16个32位或8个64位数同时运算。目前的MIC的核为按序的,因此其性能优化方法和基于乱序执行的X86处理器核心有很大不同。
为了减小使用SIMD指令的复杂度,Intel寄希望于其编译器的优化能力,实际上Intel的编译器向量化能力非常不错,但是通常手工编写的向量代码性能会更好。在MIC上编程时,软件开发人员的工作部分由显式使用向量指令转化为改写C代码和增加编译制导语句以让编译器产生更好的向量指令。
另外,现代64位X86 CPU还利用SSE/AVX指令执行标量浮点运算。
ARM
目前高端的智能手机、平板使用多个ARM核心和多个GPU核心。在人工智能时代,运行在移动设备上的应用对计算性能需求越来越大,而由于电池容量和功耗的原因,移动端不可能使用桌面或服务器高性能处理器,因此其对性能优化具有很高需求。
目前市场上的高性能ARM处理器主要是32位的A7/A9/A15,已经64位的A53/A57/A72。ARM A15 MP是一个多核向量处理器,它具有4个核心,每个核心具有64KB一级缓存,4个核心最大可共享2MB的二级缓存。ARM 32支持的向量指令集称为NEON。NEON具有16个长度为128位的向量寄存器(这些寄存器以q开头,也可表示为32个64位寄存器,以d开头),可同时操作向量寄存器的16个字节,因此使用向量指令可获得更高的性能和带宽。ARM A72 MP是一个多核向量处理器,其最多具有4个核心,每个核心独享32KB的一级数据缓存,四个核心最高可共享4MB统一的二级缓存。ARM 64支持的向量指令集称为asimd,指令功能基本上兼容neon,但是寄存器和入栈规则具有明显的不同,这意味着用neon写的汇编代码不能兼容asimd。
GPU
GPGPU是一种利用处理图形任务的GPU来完成原本由CPU处理(与图形处理无关的)的通用计算任务。由于现代GPU强大的并行处理能力和可编程流水线,令其可以处理非图形数据。特别在面对单指令流多数据流(SIMD),且数据处理的运算量远大于数据调度和传输的需要时,GPGPU在性能上大大超越了传统的CPU应用程序。
GPU是为了渲染大量像素而设计的,并不关心某个像素的处理时间,而关注单位时间内能够处理的像素数量,因此带宽比延迟更重要。考虑到渲染的大量像素之间通常并不相关,因此GPU将大量的晶体管用于并行计算,故在同样数目的晶体管上,具有比CPU更高的计算能力。
CPU和GPU的硬件架构设计思路有很多不同,因此其编程方法很不相同,很多使用CUDA的开发人员有机会重新回顾学习汇编语言的痛苦经历。GPU的编程能力还不够强,因此必须要对GPU特点有详细了解,知道哪些能做,哪些不能做,才不会出现项目开发途中发觉有一个功能无法实现或实现后性能很差而导致项目中止的情况。
由于GPU将更大比例的晶体管用于计算,相对来说用于缓存的比例就比CPU小,因此通常局部性满足CPU要求而不满足GPU要求的应用不适合GPU。由于GPU通过大量线程的并行来隐藏访存延迟,一些数据局部性非常差的应用反而能够在GPU上获得很好的收益。另外一些计算访存比低的应用在GPU上很难获得非常高的性能收益,但是这并不意味着在GPU实现会比在CPU上实现差。CPU+GPU异构计算需要在GPU和CPU之间传输数据,而这个带宽比内存的访问带宽还要小,因此那种需要在GPU和CPU之间进行大量、频繁数据交互的解决方案可能不适合在GPU上实现。
FPGA
FPGA是现场可编程门阵列的缩写,随着人工智能的流行,FPGA越来越得到产业界和学术界的重视。FPGA的主要特点在于其可被用户或设计者重新进行配置,FPGA的配置可以通过硬件描述语言进行,常见的硬件描述语言有VHDL和verilog。
使用VHDL和Verilog编程被人诟病的一点在于其编程速度。随着FPGA的流行,其编程速度越来越得到重视,各个厂商都推出了各自的OpenCL编程环境,虽然OpenCL降低了编程难度,但是其灵活性和性能也受到很大的限制。
传统上,FPGA用于通信,现在FPGA也用于计算和做硬件电路设计验证。目前主流的两家FPGA厂商是Altera和Xilinx,Intel在2014年收购了Altera,估计在2018年,Intel X86+FPGA的异构产品会出现在市场。
编程环境
本节将详细介绍目前主流的并行编程环境,既包括常见的指令级并行编程技术,也包括线程级并行编程技术和进程级技术。
Intel AVX/AVX512 Intrinsic
SSE/AVX是Intel推出的用以挖掘SIMD能力的汇编指令。由于汇编编程太难,后来Intel又给出了其内置函数版本(intrinsic)。
SSE/AVX指令支持数据并行,一个指令可以同时对多个数据进行操作,同时操作的数据个数由向量寄存器的长度和数据类型共同决定。如SSE4向量寄存器(xmm)长度为128位,即16个字节。如果操作float或int型数据,可同时操作4个,如果操作char型数据,可同时操作16个,而AVX向量寄存器(ymm)长度为256位,即32字节。
虽然SSE4/AVX指令向量寄存器的长度为128/256 位,但是同样支持更小长度的向量操作。在64位程序下,SSE4/AVX 向量寄存器的个数是16个。
SSE指令要求对齐,主要是为了减少内存或缓存操作的次数。SSE4指令要求16字节对齐,而AVX指令要求32字节对齐。SSE4及以前的SSE指令不支持不对齐的读写操作,为了简化编程和扩大应用范围,AVX指令支持非对齐的读写。
ARM NEON Intrinsic
NEON是ARM处理器上的SIMD指令集扩展,由于ARM在移动端得到广泛应用,目前NEON的使用也越来越普遍。
NEON支持数据并行,一个指令可同时对多个数据进行操作,同时操作的数据个数由向量寄存器的长度和数据类型共同决定。
ARMv7具有16个128位的向量寄存器,命名为q0~q15,这16个寄存器又可以分成32个64位寄存器,命名为d0~d31。其中qn和d2n、d2n+1是一样的,故使用汇编写代码时要注意避免寄存器覆盖。
OpenMP
OpenMP是Open Multi-Processing的简称,是一个基于共享存储器的并行环境。OpenMP支持C/C++/Fortran绑定,也被实现为库。目前常用的GCC、ICC和Visual Studio都支持OpenMP。
OpenMP API包括以下几个部分:一套编译器伪指令,一套运行时函数,一些环境变量。OpenMP已经被大多数计算机硬件和软件厂商所接受,成为事实上的标准。
OpenMP提供了对并行算法的高层的抽象描述,程序员通过在源代码中插入各种pragma伪指令来指明自己的意图,编译器据此可以自动将程序并行化,并在必要之处加入同步互斥等通信。当选择告诉编译器忽略这些pragma或者编译器不支持OpenMP时,程序又可退化为串行程序,代码仍然可以正常运作,只是不能利用多线程来加速程序执行。OpenMP提供的这种对于并行描述的高层抽象降低了并行编程的难度和复杂度,这样程序员可以把更多的精力投入到并行算法本身,而非其具体实现细节。对基于数据并行的多线程程序设计,OpenMP是一个很好的选择。同时,使用OpenMP也提供了更强的灵活性,可以适应不同的并行系统配置。线程粒度和负载均衡等是传统并行程序设计中的难题,但在OpenMP中,OpenMP库从程序员手中接管了这两方面的部分工作。
OpenMP的设计目标为:标准、简洁实用、使用方便、可移植。作为高层抽象,OpenMP并不适合需要复杂的线程间同步、互斥及对线程做精密控制的场合。OpenMP的另一个缺点是不能很好地在非共享内存系统(如计算机集群)上使用,在这样的系统上,MPI更适合。
MPI
MPI(Message Passing Interface,消息传递接口)是一种消息传递编程环境。消息传递指用户必须通过显式地发送和接收消息来实现处理器间的数据交换。MPI定义了一组通信函数,以将数据从一个MPI进程发送到另一个MPI进程。在消息传递并行编程中,每个控制流均有自己独立的地址空间,不同的控制流之间不能直接访问彼此的地址空间,必须通过显式的消息传递来实现。这种编程方式是大规模并行处理机(MPP)和机群(Cluster)采用的主要编程方式。实践表明MPI的扩展性非常好,无论是在几个节点的小集群上,还是在拥有成千上万节点的大集群上,都能够很好地应用。
由于消息传递程序设计要求用户很好地分解问题,组织不同控制流间的数据交换,并行计算粒度大,特别适合于大规模可扩展并行算法。MPI是基于进程的并行环境。进程拥有独立的虚拟地址空间和处理器调度,并且执行相互独立。MPI设计为支持通过网络连接的机群系统,且通过消息传递来实现通信,消息传递是MPI的最基本特色。
MPI是一种标准或规范的代表,而非特指某一个对它的具体实现,MPI成为分布式存储编程模型的代表和事实上的标准。迄今为止,所有的并行计算机制造商都提供对MPI的支持,可以在网上免费得到MPI在不同并行计算机上的实现,一个正确的MPI程序可以不加修改地在所有的并行机上运行。
MPI只规定了标准并没有给出实现,目前主要的实现有OpenMPI、Mvapich和MPICH,MPICH相对比较稳定,而OpenMPI性能较好,Mvapich则主要是为了Infiniband 而设计。
MPI主要用于分布式存储的并行机,包括所有主流并行计算机。但是MPI也可以用于共享存储的并行机,如多核微处理器。编程实践证明MPI的可扩展性非常好,其应用范围从几个机器的小集群到工业应用的上万节点的工业级集群。MPI已在Windows上、所有主要的UNIX/Linux工作站上和所有主流的并行机上得到实现。使用MPI进行消息传递的C或Fortran并行程序可不加改变地运行在使用这些操作系统的工作站,以及各种并行机上。
OpenCL
OpenCL(Open Computing Language,开放计算语言),先由Apple设计,后来交由Khronos Group维护,是异构平台并行编程的开放的标准,也是一个编程框架。Khronos Group是一个非盈利性技术组织,维护着多个开放的工业标准,并且得到了工业界的广泛支持。OpenCL的设计借鉴了CUDA的成功经验,并尽可能的支持多核CPU、GPU或其他加速器。OpenCL不但支持数据并行,还支持任务并行。同时OpenCL内建了多GPU并行的支持。这使得OpenCL的应用范围比CUDA广,但是目前OpenCL的API参数比较多(因为不支持函数重载),因此函数相对难以熟记。
OpenCL覆盖的领域不但包括GPU,还包括其他的多种处理器芯片。到现在为止,支持OpenCL的硬件主要局限在CPU、GPU和FPGA上,目前提供OpenCL开发环境的主要有NVIDIA、AMD、ARM、Qualcomm、Altera和Intel,其中NVIDIA和AMD都提供了基于自家GPU的OpenCL实现,而AMD和Intel提供了基于各自CPU的OpenCL实现。目前它们的实现都不约而同地不支持自家产品以外的产品。由于硬件的不同,为了写出性能优异的代码,可能会对可移植性造成影响。
OpenCL包含两个部分:一是语言和API,二是架构。为了C程序员能够方便、简单地学习OpenCL,OpenCL只是给C99进行了非常小的扩展,以提供控制并行计算设备的API以及一些声明计算内核的能力。软件开发人员可以利用OpenCL开发并行程序,并且可获得比较好的在多种设备上运行的可移植性。
OpenCL的目标是一次编写,能够在各种硬件条件下编译的异构程序。由于各个平台的软硬件环境不同,高性能和平台间兼容性会产生矛盾。而OpenCL允许各平台使用自己硬件的特性,这又增大了这一矛盾。但是如果不允许各平台使用自己的特性,却会阻碍硬件的改进。
CUDA
CUDA认为系统上可以用于计算的硬件包含两个部分:一个是CPU(称为主机),一个是GPU(称为设备),CPU控制/指挥GPU工作,GPU只是CPU的协处理器。目前CUDA只支持NVIDIA的GPU,而CPU由主机端编程环境负责。
CUDA是一种架构,也是一种语言。作为一种架构,它包括硬件的体系结构(G80、GT200、Fermi、Kepler)、硬件的CUDA计算能力及CUDA程序是如何映射到GPU上执行;作为一种语言,CUDA提供了能够利用GPU计算能力的方方面面的功能。CUDA的架构包括其编程模型、存储器模型和执行模型。CUDA C语言主要说明了如何定义计算内核(kernel)。CUDA架构在硬件结构、编程方式与CPU体系有极大不同,关于CUDA的具体细节读者可参考CUDA相关的书籍。
CUDA以C/C++语法为基础而设计,因此对熟悉C系列语言的程序员来说,CUDA的语法比较容易掌握。另外CUDA只对ANSI C进行了最小的扩展,以实现其关键特性:线程按照两个层次进行组织、共享存储器(shared memory)和栅栏(barrier)同步。
目前CUDA提供了两种API以满足不同人群的需要:运行时API和驱动API。运行时API基于驱动API构建,应用也可以使用驱动API。驱动API通过展示低层的概念提供了额外的控制。使用运行时API时,初始化、上下文和模块管理都是隐式的,因此代码更简明。一般一个应用只需要使用运行时API或者驱动API中的一种,但是可以同时混合使用这两种。笔者建议读者优先使用运行时API。
编程模式
和串行编程类似,并行编程也表现出模式的特征,并行编程模式是对某一类相似并行算法的解决方案的抽象。
和串行编程类似,并行编程对于不同应用场景也有不同的解决方法。由于并行的特殊性,串行的解决方法不能直接移植到并行环境上,因此需要重新思考、设计解决方法。并行编程模式大多数以数据和任务(过程化的操作)为中心来命名,也有一些是以编程方法来命名。
经过几十年的发展,人们已经总结出一系列有效的并行模式,这些模型的适用场景各不相同。本节将简要说明一些常用并行模式的特点、适用的场景和情况,具体的描述和实现则在后文详细描述。
需要说明的是:从不同的角度看,一个并行应用可能属于多个不同的并行模式,本质原因在于这些并行模式中存在重叠的地方。由于模式并非正交,因此适用于一种模式的办法可能也适用于另一种模式,读者需要举一反三。
任务并行模式
任务并行是指每个控制流计算一件事或者计算多个并行任务的一个子任务,通常其粒度比较大且通信很少或没有。
由于和人类的思维方式比较类似,任务并行比较受欢迎,且又易于在原有的串行代码的基础上实现。
数据并行模式
数据并行是指一条指令同时作用在多个数据上,那么可以将一个或多个数据分配给一个控制流计算,这样多个控制流就可以并行,这要求待处理的数据具有平等的特性,即几乎没有需要特殊处理的数据。如果对每个数据或每个小数据集的处理时间基本相同,那么均匀分割数据即可;如果处理时间不同,就要考虑负载均衡问题。通常的做法是尽量使数据集的数目远大于控制流数目,动态调度以基本达到负载均衡。
数据并行对控制的要求比较少,因此现代GPU利用这一特性,大量减少控制单元的比例,而将空出来的单元用于计算,这样就能在同样数量的晶体管上提供更多的原生计算能力。
基于进程的、基于线程的环境,甚至指令级并行环境都可以很好地应用在数据并行上。必要时可同时使用这三种编程环境,在进程中分配线程,在线程中使用指令级并行处理多个数据,这称为混合计算。
异构并行计算领域现状
在2005年之前,处理器通常提升频率来提升计算性能,由于性能是可预测的,因此在硬件生产商、研究人员和软件开发人员之间形成了一个良性循环。由于功耗的限制,处理器频率不能接着提升,硬件生产商转而使用向量化或多核技术。而以GPU计算为代表的异构并行计算的兴起,加上人工智能的加持,异构并行计算从学术界走向工业界,获得了大众的认可。今天几乎所有主流的处理器硬件生产商都已经在支持OpenCL,未来异构并行计算必将无处不在。今天无论上技术上还是市场上,它都获得了长足的发展,笔者可以预计在未来的十年,异构并行计算必将进一步深入发展,并且在更多的行业产生价值。
技术进展
由于工艺制程的影响,芯片的集成度提升会越来越难,现在14nm已经量产,未来7nm也将很快。随着制程技术到达极限,某些厂商通过制程领先一代的优势会消失,软件公司会进一步重视异构并行计算人才的价值。而一些硬件厂商会进化成系统厂商,不再只是提供单纯的硬件,进而会硬件和系统软件一起提供,通过把软件的成本转嫁到硬件上来获得利润。
随着异构并行计算影响力的提升,各个厂商和组织开发了一系列的技术,如WebCL、OpenVX、Vulkan等。这些技术进一步丰富和扩张了异构并行计算的领域,更促进了异构并行计算。今天基本上每家硬件和系统软件公司都或多或少的涉及到了异构并行计算。
市场需求
随着人工智能的兴起,市场对异构并行计算领域人员的需求已经从传统的科学计算、图像处理转到互联网和新兴企业,目前人员缺口已经很大了,从51job和智联招聘上能够查到许多招聘信息。
由于目前还在行业的早期,异构并行计算开发人员的能力和老板期望和支出之间存在明显的认知差距,再加上异构并行计算开发人员的工作成果往往需要和产品间接反应,故在多个层面上存在博弈。对于异构并行计算领域的人员来说,这个博弈有点不公平,因为职业特点要求异构并行计算领域的从业人员要比算法设计人员更了解算法实现细节、要比算法实现人员更了解算法的应用场景,再加上编程上的难度和需要付出更多的时间。但是由于行业刚形成不久,老板们并没有意识到这一点,他们还只是把异构并行计算从业人员当成普通的开发者,矛盾就产生了。
随着人工智能的兴起,市场对异构并行计算从业人员的认知逐渐变得理性。越来越多的企业认识到:异构并行计算是人工智能企业最核心的竞争力之一。可以预见在不远的将来,异构并行计算工程师会越来越吃香。
作者简介:刘文志,商汤科技高性能计算部门负责人,硕士毕业于中国科学院研究生院。曾于2011年至2014年间于英伟达担任并行计算工程师。后就职百度深度学习研究院高级研发工程师,负责异构计算组日常工作。
本文为《程序员》原创文章,未经允许不得转载。

CSDN AI热衷分享 欢迎扫码关注