数据(Data)是一项资产的观念形成虽然时间不长,但已经成为人们的共识。成为资产的两个基本前提条件是能够确权和定价。确权是确定谁拥有什么权利或权益,定价使得资产具备可转让性。相比其他资产类别,数据资产(Data Assets)的确权和定价的研究刚刚起步,但数字经济的发展迫切需要对这一课题进行研究。
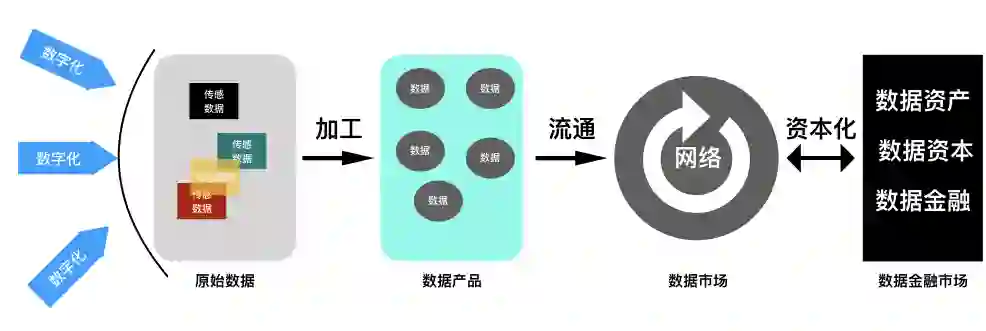
从数据流动的宏观结构观察,数字化首先形成初级的、未经处理的原始数据(Raw Data),这些原始数据是由不同的数字化设备(传感器)产生的“传感数据”(Sensor Data),经过简单的组合或融合而形成的。这些原始数据再经过处理,形成各种各样的数据产品(Data Products),进入数据交易市场。数据资本化进程的演进,逐渐形成包括数据资产、数据资本和数据金融的数据金融市场(如下图)。由此可以看出,数据必然的成为可进行交易的商品、必不可少的生产要素与资产。数据资产列入资产负债表,也只是时间问题。
![]()
不是所有的原始数据都能够加工成数据产品,能够加工成数据产品的原始数据需要满足一些特性。严格定义和测度究竟哪些原始数据能加工成数据产品还很难形成统一的标准。但目前,认为具备“大数据”特性的数据是能够加工数据产品,并进一步能够成为数据资产的观点基本能够形成共识。为避免歧义,本文所研究的数据,是指满足“大数据”特性的这一类数据。
在当前的数据市场中,买家和卖家之间几乎没有透明度、信息严重不对称。这种缺乏透明度和信息不对称,让参与交易的各方被误导并最终形成“柠檬市场”。如果存在数据定价的标准模型,这个模型考虑了影响数据价值的许多方面,例如数据的年龄、样本的可靠性以及其他因素。买家就可以进行适当的比较,以获得合理的价格。如果数据市场采用了基于这些标准化的定价模型,市场的效率将会得到大幅改进,并促进数据科学的研究和发展。
早期的研究主要是数据资产评估。Moody和Walsh(1999)提出信息资产作为一个有形资产进行评估,以为信息的价值由搜集信息成本、管理信息成本和信息质量共同决定。Long Staff和Schwartz(2001)运用B-S期权定价理论提出LSM方法,解决价格对历史数据依赖性的期权定价等问题。Pitney Bowes、John Gallaugher (2009)从数据资产管理的角度,研究从数据流动过程对数据资产进行管理。提出了数据资产管理包括目标数据、数据来源、数据体积、数据质量、数据托管等方面。
这些研究,大多没有涉及数据本身。本文主要讨论数据本身的定价问题。
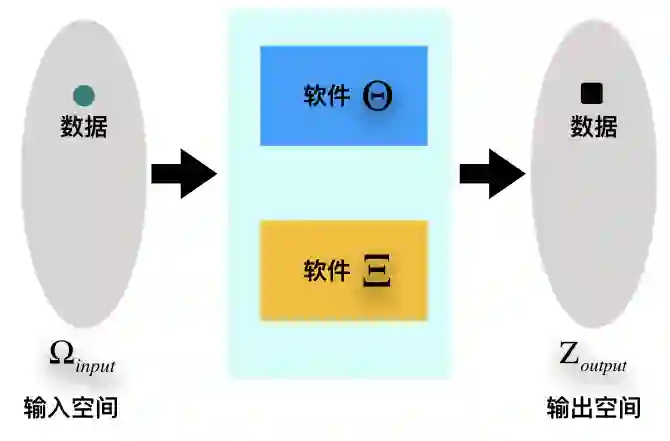
从经济学的视角看,这类数据无法由经济人通过人工方式直接处理,必须且只能够借助某种软件来处理。因此,对经济人而言,数据产生的效用应该是数据和软件共同作用的结果。
处理数据的软件也处于不断演进中。从最简单的到复杂的人工智能,软件的发展极大的提高了数据处理的能力,同时,也对数据产生巨大的需求。为了训练一个人脸识别AI,需要大量的采集人脸数据进行训练;自动驾驶AI系统,无论在训练时,还是在工作中,都需要大量的数据。
以微观的视角,将处理数据的软件与数据分开来考察的好处是,可以基于经济学的理论体系,构建一个关于数据和软件的经济学分析框架。这个分析框架的核心要点主要是两个:一个是将满足一定规范条件的输入数据无差别化处理,考察不同的软件在处理相同输入的情况下,其输出的效用差异;一个是将软件看作经济人的智能代理(Intellgent Agent),运用代理理论来对数据市场的交易行为进行分析。
需要补充的是,对于程序员和工程师而言,将软件和数据进行分离是一件不可思议的事情。但将软件和数据分开,是为了更好的在经济学意义上,分别研究软件、数据的经济学性质。特别的,这样的分离更便于建立数据交易和定价所需要的微观基础。
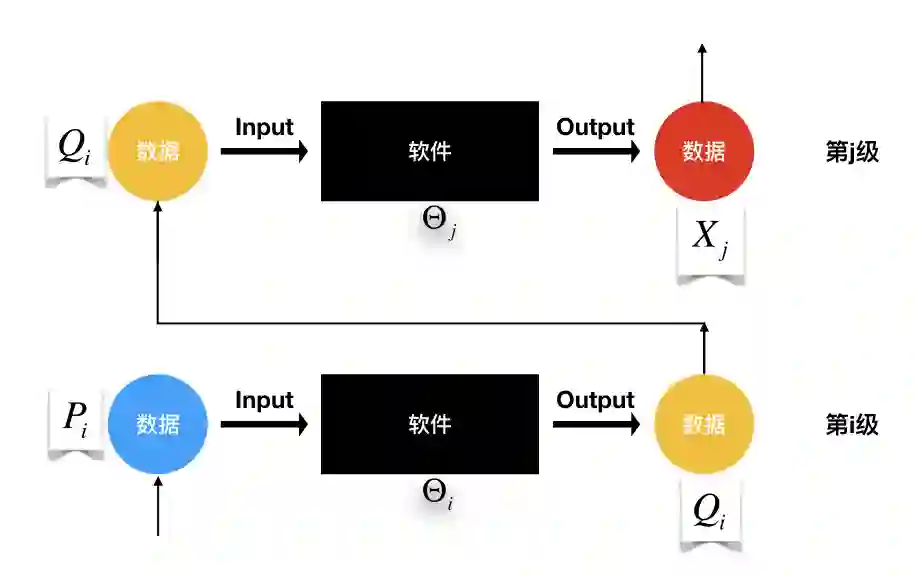
首先分析软件,为此建立了一个初步的软件经济学分析框架。在这个分析框架中,得出的结论是:软件本质上,代表的是某个时期,人们关于处理某类数据的全部知识和方法的总和。软件作为经济人的智能代理,按照委托,处理特定的数据,向经济人提供效用。
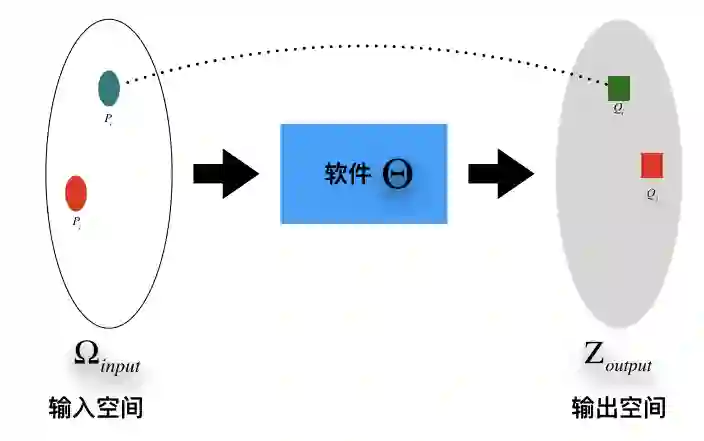
这个分析框架将数据作为软件所定义的输入空间和输出空间的子集【定义1】。数据从一个层级“流动”到上一个层级,驱动数据流动的动力是数据的价值(分析框架示意图如下)。
![]()
![]()
本文后续的讨论,为了将研究对象聚焦在数据上,假设经济人都使用相同的软件,但输入数据是有差别的。【假设1】
对经济人而言,拥有软件
![]() ,软件成本为
,软件成本为
![]() 。
输出数据的预期效用
。
输出数据的预期效用
![]() 大于输入数据的效用
大于输入数据的效用
![]() 和软
件使用成本,经济人才会考虑购买输入数据,即
和软
件使用成本,经济人才会考虑购买输入数据,即
![]() 【条件1】。
【条件1】。
![]()
对于任意两个输入数据子集,
![]() 和
和
![]() ,通过同一软件
,通过同一软件
![]() 处理后的对应输出为
处理后的对应输出为
![]() 和
和
![]() 。
如果期望效用
。
如果期望效用
![]() 大于
大于
![]() ,那么很合理的结论是经济人愿意为数据
,那么很合理的结论是经济人愿意为数据![]() 付出比数据
付出比数据![]() 更高的价格。
对任意输入数据子集
更高的价格。
对任意输入数据子集![]() ,事实上面临两类情况:a)这个输入数据子集经过软件的处理,在输出空间上没有输出;b)这个输入数据子集经过软件的处理,能够在输出空间上得到输出数据。显然,在a)情况下,没有人愿意为这个数据付钱;在b)情况下,只要满足【条件1】,数据就会有价值。
既然这些输入数据子集都满足“输入数据规范”,为什么还存在得不到输出的a)情形呢?
用一个形象的类比来说明:将软件看作是一个秤,要秤的东西是输入空间的数据,秤的重量刻度表是输出空间。我们将某些数据放在称上时,能够秤出重量的,可以从刻度表上读取数值;不能称出重量的,就无法从刻度表读取数值。(下图示意)
,事实上面临两类情况:a)这个输入数据子集经过软件的处理,在输出空间上没有输出;b)这个输入数据子集经过软件的处理,能够在输出空间上得到输出数据。显然,在a)情况下,没有人愿意为这个数据付钱;在b)情况下,只要满足【条件1】,数据就会有价值。
既然这些输入数据子集都满足“输入数据规范”,为什么还存在得不到输出的a)情形呢?
用一个形象的类比来说明:将软件看作是一个秤,要秤的东西是输入空间的数据,秤的重量刻度表是输出空间。我们将某些数据放在称上时,能够秤出重量的,可以从刻度表上读取数值;不能称出重量的,就无法从刻度表读取数值。(下图示意)
![]()
为数据构建什么样的度量,直接影响和决定了输出数据。由此可以得出结论,导致数据效用差异的原因是数据内蕴的,这些差异必须通过建立某种度量来区分。而这些度量本身,也自然的成为数据定价的基础。
数据的度量(Metric)是研究数据交易、定价以及其他经济性质的起点。
为了建立数据的度量,我们首先需要了解数据的数学结构。为此,引入如下三条公理:对于输入空间的数据
![]() ,
【公理1】
,
【公理1】![]() 是一个集合,具有一些属性
【公
理3】集合的数据是由多种感应数据组合和融合的,
具有异质性(Heterogeneous)。
由以上公理,我们就可以建立数据的数学结构和度量,并进行计算和分析。
数据的属性是复杂多样的,人们可以根据需求选择一些属性来对数据进行计算和分析。因此,不同的软件被用来处理具有不同属性的数据。为了建立标准的模型,需要对这些属性进行规范化要求,由此就形成了“数据规范”。将数据标准化、规范化是进行商品化(Commditzation)的前提。
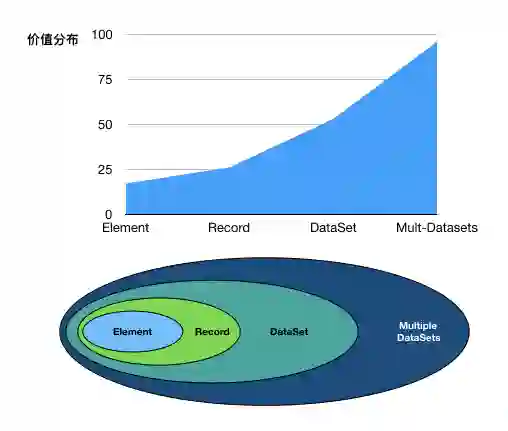
NIST提出了一个数据属性的层级关系模型(见下图),可以更好的理解数据内蕴的层次结构。
是一个集合,具有一些属性
【公
理3】集合的数据是由多种感应数据组合和融合的,
具有异质性(Heterogeneous)。
由以上公理,我们就可以建立数据的数学结构和度量,并进行计算和分析。
数据的属性是复杂多样的,人们可以根据需求选择一些属性来对数据进行计算和分析。因此,不同的软件被用来处理具有不同属性的数据。为了建立标准的模型,需要对这些属性进行规范化要求,由此就形成了“数据规范”。将数据标准化、规范化是进行商品化(Commditzation)的前提。
NIST提出了一个数据属性的层级关系模型(见下图),可以更好的理解数据内蕴的层次结构。
![]()
数据属性在每个层级都有其对应的、可以定性或定量的参数化(坐标)表示(每个属性可以看作为一个坐标)。上述三条【公理】使得可以对具有上述复杂层级结构的数据,建立“等价的”数学结构,有了恰当的数学结构,就能够很好的运用成熟的数学方法来进行分析和计算。目前主要有两类数学结构:一种是流形;一种是拓扑。无论那种数学结构,起点都是要找到一种合适的度量。
数学上,度量是指对于非空集合
![]() 中任意的两个元素
中任意的两个元素
![]() ,一个能够满足下面三个性质的距离函数
,一个能够满足下面三个性质的距离函数
![]() :
1)
:
1)
![]() ,而且等号成立当且仅当
,而且等号成立当且仅当
![]() ;
2)对于任意两点
;
2)对于任意两点![]() ,
,
![]() ;
3)对于任意三点
;
3)对于任意三点
![]() ,
,
![]() 。
欧几里德距离函数
。
欧几里德距离函数
![]() 是最常见的
度量,以此得到2维欧氏空间
是最常见的
度量,以此得到2维欧氏空间
![]() 。
推广到
。
推广到
![]() 维,得到维欧氏空间
维,得到维欧氏空间![]() 。
除了欧几里德距离函数,根据应用场景不同,还有很多距离函数:
例如汉明距离、曼哈顿距离、车比雪夫距离等。
不同距离函数是将数据的属性进行参数化(坐标)表示,进行计算,从而实现诸如分类、聚类等目的。
将度量的概念推广到流形的时候,就形成了黎曼度量
。
除了欧几里德距离函数,根据应用场景不同,还有很多距离函数:
例如汉明距离、曼哈顿距离、车比雪夫距离等。
不同距离函数是将数据的属性进行参数化(坐标)表示,进行计算,从而实现诸如分类、聚类等目的。
将度量的概念推广到流形的时候,就形成了黎曼度量
![]() 的
概念。
简单的说,为了计算流形中任意两点的距离,需要黎曼度量来决定无穷小距离
的
概念。
简单的说,为了计算流形中任意两点的距离,需要黎曼度量来决定无穷小距离
![]() ,它的形式可以写为:
,它的形式可以写为:
![]() 。
这些无穷小距离逐段相加,就可以计算出路径的长度,而这个长度就可以定义为两点之间的最短距离。
黎曼度量是一大类度量的统称。例如,地球上,从任意一点A到B的最短距离是它们之间测地线的长度;Wasserstein距离是概率密度函数空间中的黎曼度量。对于任意给定的空间,有很多可能的黎曼度量。如何选择在某方面“最好”的黎曼度量一直是数学上的重大主题,这也是当前挖掘数据价值的主要来源之一。
上述度量构造方法在具有很大异质性的数据集合中,暴露出很多缺陷。人们逐渐认识到“距离函数”的局限性,很多数据集本身就不存在“距离”这种结构,或者无法构造出类似“距离”的结构。采用拓扑学的方法和工具来处理这些数据就成为必要的手段,由此发展出了计算拓扑学(computing topology)。拓扑的方法是分析数据集的拓扑性质,进一步的通过计算拓扑不变量,例如洞、环等(也是一种度量)来对数据集进行比较、分类和预测(示例如下图)。
。
这些无穷小距离逐段相加,就可以计算出路径的长度,而这个长度就可以定义为两点之间的最短距离。
黎曼度量是一大类度量的统称。例如,地球上,从任意一点A到B的最短距离是它们之间测地线的长度;Wasserstein距离是概率密度函数空间中的黎曼度量。对于任意给定的空间,有很多可能的黎曼度量。如何选择在某方面“最好”的黎曼度量一直是数学上的重大主题,这也是当前挖掘数据价值的主要来源之一。
上述度量构造方法在具有很大异质性的数据集合中,暴露出很多缺陷。人们逐渐认识到“距离函数”的局限性,很多数据集本身就不存在“距离”这种结构,或者无法构造出类似“距离”的结构。采用拓扑学的方法和工具来处理这些数据就成为必要的手段,由此发展出了计算拓扑学(computing topology)。拓扑的方法是分析数据集的拓扑性质,进一步的通过计算拓扑不变量,例如洞、环等(也是一种度量)来对数据集进行比较、分类和预测(示例如下图)。
![]()
通常可以在特定的任务下,通过选择数据的属性来人工的构建度量。然而这种方法需要很大的、有时候甚至很高端的人力资源投入。同时,由于存在人为因素,也可能对数据的改变非常不鲁棒。采用机器学习的方式,根据不同的任务来自主学习出针对某个特定任务的度量。这种方法极大的扩展了数据的度量方法,目前已经构建了几十种度量,而且还在不断增长中。
对于一个数据集合,往往采用多种度量,不同度量经过软件的处理会得到各自的数值。度量
![]() 和对应的值
和对应的值
![]() 描述了数据的特征,称之为特征空间
描述了数据的特征,称之为特征空间
![]() 。
数据的这些特征,软件最终将其表示为经济人能够理解和使用的信息,就产生了效用。
输入空间的不同数据,在输出空间得到不同的输出,其效用的差异是输入数据的特征诱导的。而这些特征是度量的函数。由此,可以看到度量与数据价值之间的联系。
输入空间的不同数据子集的价值差异的定量化,就是数据资产定价研究的核心问题。目前,业界研究了一些度量方法以及由此建立的定价模型。例如,出于对个人隐私的保护,很多学者研究了隐私数据度量的方法及基于隐私度量的数据定价模型;基于微观市场一般均衡机制的价差度量,建立了私人数据定价模型;一些大数据交易所和平台制订了包括数据质量评价指标、数据效用指标等在内的度量指标体系,并以此建立了包括协议定价、竞价等多种数据定价机制。
数据价值的发现和计量是通过度量来实现的,而度量的构建有着严格的数学基础。因此,建立标准的定价模型是可行的。
。
数据的这些特征,软件最终将其表示为经济人能够理解和使用的信息,就产生了效用。
输入空间的不同数据,在输出空间得到不同的输出,其效用的差异是输入数据的特征诱导的。而这些特征是度量的函数。由此,可以看到度量与数据价值之间的联系。
输入空间的不同数据子集的价值差异的定量化,就是数据资产定价研究的核心问题。目前,业界研究了一些度量方法以及由此建立的定价模型。例如,出于对个人隐私的保护,很多学者研究了隐私数据度量的方法及基于隐私度量的数据定价模型;基于微观市场一般均衡机制的价差度量,建立了私人数据定价模型;一些大数据交易所和平台制订了包括数据质量评价指标、数据效用指标等在内的度量指标体系,并以此建立了包括协议定价、竞价等多种数据定价机制。
数据价值的发现和计量是通过度量来实现的,而度量的构建有着严格的数学基础。因此,建立标准的定价模型是可行的。
当前数据资产交易通常由卖方推动,买方对于将要购买的数据的信息知之甚少。信息的这种不对称导致定价缺乏透明度,持续损害卖方利益,这就会形成典型的“柠檬市场”。由此,建立具有标准化定价模型的数据市场是非常必要的。
考察一种简单的情形:一个满足“输入数据规范”的所有数据构成的集合
![]() ,给定一组度量
,给定一组度量
![]() ,构成输入空间
,构成输入空间
![]() 。
对于其中的两
个子集
。
对于其中的两
个子集
![]() 和
和
![]() ,我们需要建立一个模型,能够根据其各自的度量值进行定价。
最基本的是权重法:对于任意度量
,我们需要建立一个模型,能够根据其各自的度量值进行定价。
最基本的是权重法:对于任意度量
![]() ,可以根据每个度量
对数据价值的贡献权重分配每一个度量相应的权重
,可以根据每个度量
对数据价值的贡献权重分配每一个度量相应的权重
![]() 。
然后根据其度量值分别计算后,进行定价。
例如,我们选择三种度量和固定权重计算两个数据的价值。(下图)
。
然后根据其度量值分别计算后,进行定价。
例如,我们选择三种度量和固定权重计算两个数据的价值。(下图)
![]()
这种方法比较简便和便于计算。度量是定量的,也可以是定性的。这种方法存在的问题和争议的地方包括度量的构建和权重分配的优化。解决的办法主要是依靠市场的交易数据的积累和反馈,寻求一种再调整和优化的机制。这种定价方式适合场外市场交易。
从数据的层级结构(NIST)考察,可以发现不同层级的数据对于整个数据集的价值贡献是不同的。大数据科学揭示出来的一个显著的特性就是,高层级数据包含更丰富的信息,因此对于数据价值的贡献也更多。由此,可以建立一个基于数据层级结构的价值树(Value Tree)模型:高层级的数据具有更高的权重,价值在不同层级的分布是不均匀的(示意图如下)。这种定价方法,需要确定价值在不同层级的分布情况。这方面的定性研究已经取得一些进展,但定量的研究还处于起步阶段。
![]()
如果存在一个有效的数据市场,那么可以通过交易来定价。有效的数据市场是指对于市场上交易的数据资产,有一个信任中介,有效的解决了信息不对称的问题。由于数据的特殊性,这样的数据市场需要构建基于区块链的数据交易基础设施。这些基础设施可以满足买卖双方对拟交易的数据资产的信息透明度以及信任问题。由于区块链的一些显著的特点和优势,它能够为交易各方提供数据来源、数据质量以及其他数据属性可信的、可靠的和不可删改的信息。因此,“链上的数据交易”会成为数据交易的主要方式。
基于链上的数据交易的主要方式有两种:1)点对点;2)Token化。
点对点的交易是买卖双方依据链上的规则来直接进行交易。定价的依据可以参照上述的模型。
Token化的交易是将标的数据Tokenization后的一种间接交易方式。交易各方不再直接交易数据,而是交易代表数据的Token。数据的定价反映在Token的价格上。这种方式的好处是,不仅将数据的真正买卖双方引入公开市场,也引入了投机交易者,从而通过市场机制更好的定价。Token的设计可以是权益、也可以是期权。由此,可以派生出很多不同数据权利产品的价值发现工具,有利于更好、更公允的定价。
Token化交易的另一个显著的优势是,可以解决不完全信息条件下的数据资产定价。主要原因是,由于认知差距,人们还无法对数据层级价值分布以及不同参数对价值贡献的掌握的非常准确。通过Token化,可以将未知的部分(风险)通过公开市场交易进行转移,从而有效的获得合理的、公允的定价。
由于云计算、物联网以及数据时效性的原因,数据市场的交易将越来越呈现实时性、高频率以及高频次。数据市场的交易的时间按毫秒计算、每次交易从发起到完成在秒级计算。同时,交易发起的频次非常高,每秒钟可能就会有高达几千次的交易发起。更为显著的是,交易参与方不再是人类,而更多的是智能代理。买卖双方都是机器,可以遇见数据市场的大多数交易都是M2M(Machine To Machine)的。
就如同当今的证券市场,超过80%的交易都是由算法驱动的程序或Robo完成的。一份研究报告指出,比特币市场上超过90%的交易都是Robo完成的。这些Robo交易者的策略以及交易行为,将显著的影响市场的价格和波动。特别是拥有更多自主AI算法的Robo交易者参与到市场中来的时候,我们还面临很多未知的问题。
这将是一种全新的交易环境。区别于我们已知的定价模型,这样的交易环境,其定价机制以及理论都尚待进一步的研究。
参考文献
A pricing Model for data marker, J.Heckman等 2015年
Gkatzelis V, Aperjis C, Huberman B A. Pricing private data[J]. Electronic Markets, 2012, 25(2): 1-15.
“大数据之父”维克托·迈尔·舍恩伯格。
Data As economic Goods,Yuri Demchenko等
https://baike.baidu.com/item/柠檬市场/2174659?fr=aladdin
Measuring the Value of information:an assets valuation approach. Daniel Moody & Peter Walsh,199
《开源软件经济学浅议》,张家林
NIST Big Data Interoperability Framework: Volume 2, Big Data Taxonomies
《TOPOLOGY AND DATA》,GUNNAR CARLSSON ,2009
https://blog.csdn.net/pipisorry/article/details/45651315
http://www.ams.org/journals/bull/2009-46-02/S0273-0979-09-01249-X/S0273-0979-09-01249-X.pdf
https://arxiv.org/pdf/1806.05167.pdf
http://www.cs.cmu.edu/~liuy/distlearn.htm
《结构化数据的隐私与数据效用度量模型》,谢明明等
Wagner I, Eckhoff D. Technical privacy metrics: a systematic survey [J].
ACM Computing Surveys, 2018, 51(3): articleNo 57
《基于隐私度量的数据定价模型》,彭慧波,周亚建。
《A theory of pricing private data》,Chao Li等
这里的数据效用不是经济学的效用函数,而是指经过处理之后的数据与没有处理的同组数据的相同程度或者真实程度,数据真实性越高,数据效用越好。
《浅析国内大数据交易定价》,赵子瑞
《数据定价机制现状及发展趋势》,彭慧波,周亚建。
1995年-1997年创办期货经纪公司,北京商品交易所会员,从事商品期货经纪业务。
1995年-2003年涉足证券投资与股权投资。
2006年-2009年在国外从事结构化金融衍生品交易,包括CDO,CDS等。
2009年6月创建私募证券投资管理公司,负责决定公司的投资计划、投资策略、投资原则、投资目标、资产分配及投资组合的总体规划。
2014年初创建金融科技公司,从事人工智能投顾、监管科技的业务。
1)发表过有金融人工智能、数字货币、网络空间贸易与投资、区块链等二十余篇文章,政策建议。著有《证券投资人工智能》等专著。
2)参与多项央行、证监会的多项优秀课题研究。2017、2018年证券业协会的优秀课题。
3)2015年开始涉足区块链的应用和技术研究。是Hyperledger中国区首家会员,开发多项区块链的应用研究和跨链技术。
编辑:文婧
校对:龚力
![]()

 ,软件成本为
,软件成本为
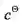 。
输出数据的预期效用
。
输出数据的预期效用
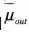 大于输入数据的效用
大于输入数据的效用
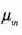 和软
件使用成本,经济人才会考虑购买输入数据,即
和软
件使用成本,经济人才会考虑购买输入数据,即
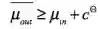 【条件1】。
【条件1】。
 和
和
 ,通过同一软件
,通过同一软件
 处理后的对应输出为
处理后的对应输出为
 和
和
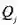
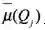 大于
大于
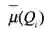 ,那么很合理的结论是经济人愿意为数据
,那么很合理的结论是经济人愿意为数据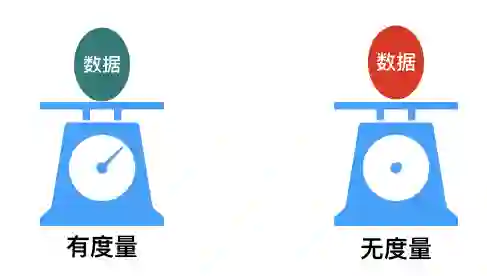
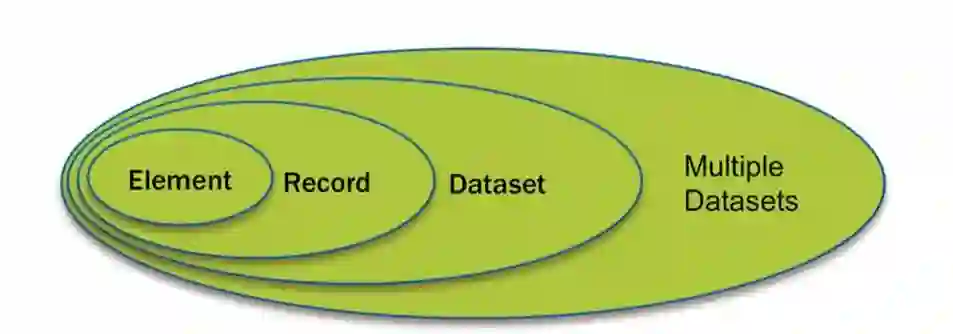
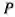 ,
,
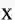 中任意的两个元素
中任意的两个元素
 ,一个能够满足下面三个性质的距离函数
,一个能够满足下面三个性质的距离函数
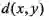 :
:
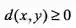 ,而且等号成立当且仅当
,而且等号成立当且仅当
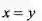 ;
;
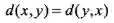 ;
;
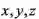 ,
,
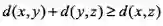 。
。
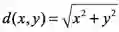 是最常见的
度量,以此得到2维欧氏空间
是最常见的
度量,以此得到2维欧氏空间
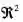 。
推广到
。
推广到
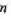 维,得到维欧氏空间
维,得到维欧氏空间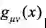 的
概念。
简单的说,为了计算流形中任意两点的距离,需要黎曼度量来决定无穷小距离
的
概念。
简单的说,为了计算流形中任意两点的距离,需要黎曼度量来决定无穷小距离
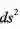 ,它的形式可以写为:
,它的形式可以写为:
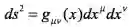 。
这些无穷小距离逐段相加,就可以计算出路径的长度,而这个长度就可以定义为两点之间的最短距离。
。
这些无穷小距离逐段相加,就可以计算出路径的长度,而这个长度就可以定义为两点之间的最短距离。

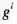 和对应的值
和对应的值
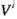 描述了数据的特征,称之为特征空间
描述了数据的特征,称之为特征空间
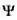 。
数据的这些特征,软件最终将其表示为经济人能够理解和使用的信息,就产生了效用。
。
数据的这些特征,软件最终将其表示为经济人能够理解和使用的信息,就产生了效用。
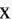 ,给定一组度量
,给定一组度量
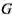 ,构成输入空间
,构成输入空间
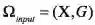 。
对于其中的两
个子集
。
对于其中的两
个子集
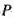 和
和
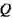 ,我们需要建立一个模型,能够根据其各自的度量值进行定价。
,我们需要建立一个模型,能够根据其各自的度量值进行定价。
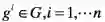 ,可以根据每个度量
对数据价值的贡献权重分配每一个度量相应的权重
,可以根据每个度量
对数据价值的贡献权重分配每一个度量相应的权重
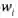 。
然后根据其度量值分别计算后,进行定价。
。
然后根据其度量值分别计算后,进行定价。