资源 | 领英开源TonY:构建在Hadoop YARN上的TensorFlow框架
选自engineering.linkedin
作者:Jonathan Hung、Keqiu Hu、Anthony Hsu
机器之心编译
参与:张倩、王淑婷、Geek AI
领英用户超过 5.75 亿,其 Hadoop 集群中存储了数百 PB 的数据,因此需要一种可扩展的方式处理所有这些信息。TensorFlow 支持分布式训练,但构建分布式 TensorFlow 框架并非易事,因此需要将分布式 TensorFlow 的分析能力和 Hadoop 的扩展能力结合起来,领英在 YARN 上构建了一个 TensorFlow 框架 TonY 并将其开源。本文介绍了 TonY 的内部细节、领英实现并用来在 Hadoop 上扩展分布式 TensorFlow 的功能以及实验结果。
领英(LinkedIn)高度依赖人工智能技术为其超过 5.75 亿的会员提供原创内容,并创造赚钱的机会。随着最近深度学习技术的快速发展,我们的人工智能工程师们已经开始在由相关性驱动的领英产品中使用深度神经网络,包括 feed 流订阅和智能回复(Smart Replies)。许多这类用例都是构建在 TensorFlow 平台上的,TensorFlow 是一个由谷歌编写的流行的深度学习框架。
起初,我们内部的 TensorFlow 用户在小型、缺乏管理的「裸机」集群上运行这套框架。但是,我们很快意识到,我们需要将 TensorFlow 与基于 Hadoop 的大数据平台的强大计算和存储能力结合在一起。在我们的 Hadoop 集群中存储了数百 PB 的数据,这些数据可以被用于深度学习。因此,我们需要一种可扩展的方式处理所有这些信息。幸运的是,TensorFlow 支持分布式训练,这是一种有效的处理大型数据集的技术。然而,构建分布式 TensorFlow 框架并非易事,也不是所有数据科学家和相关的工程师都具备所需的专业知识,或想要这样做——尤其是因为这项工作必须手动完成。我们想要一种灵活、可持续的方式将分布式 TensorFlow 的分析能力和 Hadoop 的扩展能力结合起来。
开源 TonY
为了满足以上需求,我们在 YARN 上构建了 TensorFlow on YARN(TonY),同时我们也知道很多对分布式机器学习感兴趣的人正在运行大型 Hadoop 部署,所以我们决定将该项目开源。使用细节见 TonY 项目 Github 链接。
地址:https://github.com/linkedin/TonY。
下面将介绍 TonY 的内部细节、我们实施并用来在 Hadoop 上扩展分布式 TensorFlow 的功能以及实验结果。
现有的解决方案
在 Hadoop 上运行分布式 TensorFlow 的初步探索中,我们找到了几个现有的解决方案,但最终发现没有一个方案可以满足自己的需求,因此我们决定构建 TonY。
TensorFlow on Spark 是来自 Yahoo 一种开源解决方案,使得用户可以在 Apache Spark 计算引擎上运行 TensorFlow。我们得以在这一框架上搭载我们的内部深度学习应用,但也遇到了几个问题,最显著的问题是缺乏 GPU 调度和异构容器调度。此外,我们将来想要做的任何调度和应用程序生命周期增强都必须在 Spark 中完成,这比在独立的 YARN 应用程序中进行更改要困难得多。
另一个开源解决方案是 Intel BigData 组研发的 TensorFlowOnYARN。但是,这一项目的容错支持和可用性不能满足我们的需要。而且,该项目已经终止。
出于以上种种原因,我们决定构建 TonY 以实现我们对 Hadoop 群集资源的完全控制。此外,由于 TonY 直接在 YARN 上运行,而且运行时属于轻量级依赖,我们可以轻松地使其与 YARN 堆栈的较低级部分或 TensorFlow 中的较高级部分一起进化。
TonY 是如何工作的?
类似于 MapReduce 提供的在 Hadoop 上运行 Pig/Hive 脚本的引擎,Spark 提供使用 Spark API 运行 scala 代码的引擎,TonY 旨在通过处理资源协商和容器环境设置等任务,为在 Hadoop 上运行 TensorFlow 作业提供同样顶级的支持。
在 YARN 的 TonY 上运行 TensorFlow
TonY 主要包含三个要素:Client、ApplicationMaster 和 TaskExecutor。运行 TonY 作业的端到端处理过程如下:
1.用户向 Client 提交 TensorFlow 模型训练代码、参数及其 Python 虚拟环境(包含 TensorFlow 依赖)。
2.Client 设置 ApplicationMaster(AM)并将其提交给 YARN 集群。
3.AM 与 YARN 基于用户资源请求的资源管理(Resource Manager)进行资源协商(参数服务器及线程、内存和 GPU 的数量)。
4.一旦 AM 收到分配,它就会在分配的节点上生成 TaskExecutor。
5.TaskExecutor 启动用户的训练代码并等待其完成。
6.用户的训练代码启动,TonY 定期在 TaskExecutor 和 AM 之间跳动,以检查其活性。
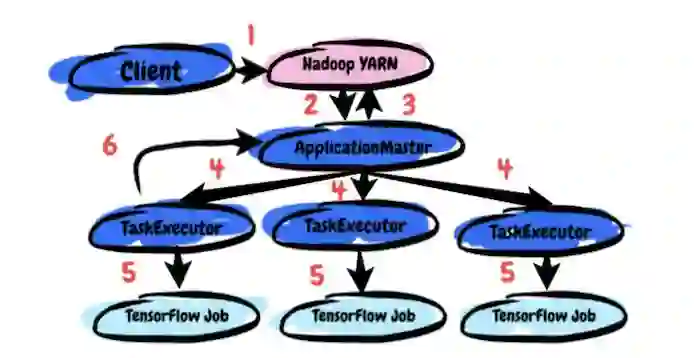
TonY 的架构
除了支持在 Hadoop 上运行分布式 TensorFlow 作业的基本功能之外,TonY 还实现了各种功能来改善运行大规模训练的体验:
GPU 调度:最近,YARN 增加了对 GPU 调度和隔离的本地支持。这意味着用户可以确保一旦从 YARN 接收到容器分配,他们就能可靠地获取自己请求的 GPU 数量。TonY 搭建在 YARN 基础上,于是也有 GPU 资源意识,因此它能够利用 Hadoop 的 API 从集群中请求 GPU 资源。
细粒度的资源请求:由于 TonY 支持请求不同的实体(如参数服务器和线程)作为单独的组件,用户可以对每种类型进行不同的资源请求。例如,参数服务器和线程可能有不同的内存需求。用户还可能想在 GPU 或其它一些专用硬件上运行训练,但是在参数服务器上使用 CPU 就足够了。这意味着更多地控制用户应用程序的资源需求,对于集群管理来说,这有助于避免昂贵硬件的资源浪费。
TensorBoard 支持:TensorBoard 是一种工具,可以使 TensorFlow 程序更易理解、调优和优化。由于 TensorBoard 是由一个线程在应用程序未知的地方启动的,因此我们通常无法从 Hadoop UI 中看到 TensorBoard。我们最近向 YARN 提供了代码,允许我们将 Hadoop 应用程序的跟踪 URL 重定向至 TensorBoard,这样仅需点击一下就可以查看 TensorBoard 了。
容错:TensorFlow 训练可能需要几个小时或几天,要使用大量机器。因此,长时间运行的 TensorFlow 作业比短时间运行的作业更容易受到瞬时错误或抢占的影响。TensorFlow 包含容错 API,用于将检查点保存到 HDFS,并根据以前保存的检查点恢复训练状态。TonY 通过提供一个弹性分布式基础设施来从节点故障中恢复,从而促进了这一过程。如果一个线程没有跳跃到 AM 或者超时,TonY 将重新启动应用程序,并从以前的检查点恢复训练。
实验结果
我们在 TonY 上运行了 Inception v3 模型,有 1 到 8 个线程,每个线程有一个 GPU,使用异步训练(也有一个执行在八个线程上使用 CPU 训练)。该模型是 ImageNet 的一个著名的深层神经网络,而 ImageNet 数据集包含了数百万幅用于训练图像分类模型的图像。正如在 Inception v3 分布式训练示例中一样,我们测量了批大小为 32 时,达到 10 万步所需的时间。结果如下:

这些结果是在 RHEL 6.6 和 TensorFlow 1.9 上得出的,每个线程上一个 CPU 的内存是 40G,使用的 GPU 是 Tesla K80 GPU。接受 GPU 训练的 8 个线程在达到 10 万步后,最终的前 5 名错误率为 26.3 %。
由于 TonY 在编排分布式 TensorFlow 的层中,并且不干扰 TensorFlow 作业的实际执行,我们预计这部分不会有开销。实际上,我们看到,对于 GPU 训练,运行时间线性扩展。我们还发现,运行 GPU 训练的速度比 CPU 训练快了大约四倍,考虑到模型的复杂性和深度,这种结果不出所料。

原文链接:https://engineering.linkedin.com/blog/2018/09/open-sourcing-tony—native-support-of-tensorflow-on-hadoop
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




