百度研究院:都知道数据越多越好,现在我们还能预测增加了数据以后具体有多好

文 | 杨晓凡
来自雷锋网(leiphone-sz)的报道
雷锋网 AI 科技评论按:在深度学习界,「数据越多,模型表现就越好」是大家公认的规律,不过很多时候我们都不太清楚具体的「增加多少数据,能带来多大提升」。
前几个月谷歌的一项大规模实验就有力地(甚至令人害怕地)证明了即便数据已经很多的情况下仍然「数据越多越好」,这次百度研究院的大规模研究就定量地分析了「增加的数据能带来多大提升」,得到的结果还可以用于预测面向实际问题的模型的表现,可以说是非常实在了。
雷锋网 AI 科技评论把百度研究院的这篇成果介绍文章编译如下。

这是一个数字世界和其中的数据以前所未有的速度增加的时代,增加速度甚至超过了计算能力的增加速度。在深度学习的帮助下,我们可以快速地从海量的数据中获取有价值的信息,并且带给我们带有人工智能的产品和使用体验。
为了能够持续地提升用户体验,深度学习科学家和开发人员们就要着眼于现有的以及不断新出现的应用场景,快速地改进深度学习模型。研究新的模型架构当然能带来重大改进,但这方面的研究往往需要的是灵感闪现;大的突破常常需要为建模问题建立复杂的新框架,测试它的效果也还要再花几周到几个月的时间。
如果除了研究新的模型结构之外,我们还能有更可靠的方法提升模型的准确率就好了。
百度研究院近日发布的一项大规模研究报告就表明,随着训练数据的增多,深度学习模型的准确率也有可预期的提高。通过实际实验,百度研究院的研究员们发现,只要有足够的训练数据和计算资源,那么训练大模型时随着规模提升带来的准确率提升就是可以预期的。在百度研究院研究的机器翻译、语言建模、图像分类、语音识别四个应用领域中,在众多的顶尖模型上都能看到这样的结果。
更具体地来说,百度研究院的研究结果表明,对于他们用来衡量模型在新样本上的表现的「泛化误差」指标,错误率的指数基本随着训练数据的指数线性下降。之前有一些理论研究也同样得到了这样的对数下降关系。然而,那些成果预测出的学习曲线都很「陡峭」,就是说幂公式的指数是-0.5,这意味着深度学习模型应当能学习得很快。百度研究院从大量实验中采集的学习曲线表明这个指数应当在 [-035,-0.07] 这个范围内,就是说真实世界的模型从真实世界的数据中学习的速度要比理论预测得要慢得多。
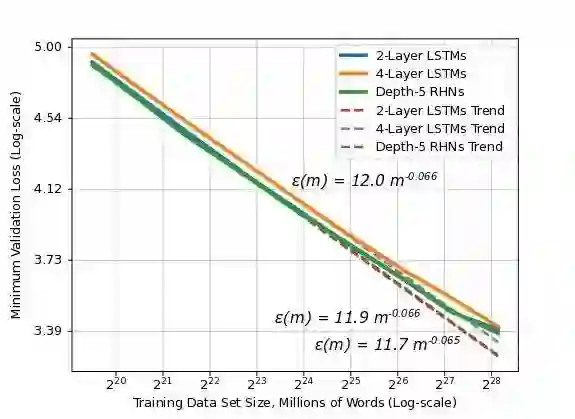
语言建模模型上的实验结果就展现出,随着训练数据的增加,错误率的指数基本随着训练数据的指数线性下降(注意横轴纵轴都是对数坐标)
对于语言建模任务,百度研究院在 Billion Word 数据集的子集上测试了 LSTM 和 RHN 模型。上方的图中显示的就是不同数据量下每个架构模型的最佳验证误差(作为泛化误差的近似)。图中几条曲线都可以根据指数关系进行预测,甚至连幂公式中的指数都惊人地一致。对于很大的训练数据集,模型的表现会稍微偏离曲线一点,但是百度研究院的研究人员们同时发现如果优化超参数就往往可以让模型表现回到曲线上来。
「有尽头」、「可预测」的学习
模型预测误差的改进从「最可能的猜测」开始,沿着指数关系下降,最终来到「无法消除的误差」。
更广泛地说,百度研究院实际实验得到的结果表明,学习曲线基本会是这样的形式的:

实际应用中成指数关系的学习曲线(横轴纵轴仍然都是对数坐标)
从这张示意图中可以看到,与训练数据数量的指数成线性关系的这一段把学习曲线分成了不同阶段。
一开始是小数据阶段,模型只有很少的训练数据;在这个阶段,模型的表现就和瞎猜差不多,只是看猜得稍微有点谱还是完全瞎猜。学习曲线上中间的这部分就是符合刚才说到的指数关系的一部分,这里每一张新增加的训练样本都能给模型提供有用的信息,提高模型分辨从未见过的样本的能力。幂公式中的指数就决定了这一阶段的线条的斜率(对数-对数坐标下)。从这个指数上也可以看到理解训练数据的难度。
最后,对于大多数的真实世界应用来说,最终都会有一个不为零的错误率下限,模型表现只能无限接近这个下限,无法进一步降低错误率(百度研究院的实验中,用于解决真实问题的模型还尚未接近这个下限,不过简单问题上的实验中已经清洗显示出了这个下限)。这种无法消除的错误率就来自真实世界数据中种种因素的组合。
综合了所有模型的测试结果,百度研究院得到的结论是:
指数关系的学习率曲线在所有的用途、所有的模型架构、所有的优化器、所有的损失函数中都会出现;
非常惊人的是,对于同一种模型用途,不同的模型架构和优化器却表现出了同样的指数关系。这里,随着训练数据集增大,不同的模型的学习率有着相同的相对增长率。
对于不同数量的训练数据,最适合的模型大小(以参数数目衡量)是随着数据的数目次线性增加的。其中的关系同样可以通过实验描述,然后用于未来的预测。
百度研究院希望这些研究成果可以在深度学习大家庭中引发更多的讨论,让大家更多地思考有哪些可以帮助深度学习快速提高的方法。
对于深度学习研究者来说,学习率也可以帮助 debug 模型,并且预测改进模型结构之后的准确率目标。学习曲线中的指数也还有很大空间做进一步的理论预测或者解释。另外,可预测的学习曲线也可以帮助决定要不要增多训练数据、如何设计和拓展计算系统,这实际上都体现了不断提升计算规模的重要性。
论文地址:https://arxiv.org/abs/1712.00409
via Baidu Research,雷锋网 AI 科技评论编译
计算机视觉基础入门教程
计算机视觉基础班,上海交通大学博士讲师团队;从算法到实战应用,涵盖CV领域主要知识点;手把手项目演示,全程提供代码;深度剖析CV研究体系,轻松实战深度学习应用领域!详情点戳阅读原文链接或长按识别下方二维码~



