论文浅尝 | AAAI2020 - 基于规则的知识图谱组合表征学习
论文笔记整理:康矫健,浙江大学计算机科学与技术系,硕士研究生。

论文链接:https://arxiv.org/pdf/1911.08935.pdf
发表会议:AAAI 2020
Motivation
现有的KG Embedding方法大部分仅关注每个三元组的结构化信息
有部分的工作把KG中的路径信息考虑在内而不仅仅是每次只考虑单个三元组,但是这种方法在获得路径表示的时候缺乏可解释性。
因此本文提出一种基于规则和路径的知识图谱表征学习方法,能够充分利用logic rules的可解释性和准确性。
Model
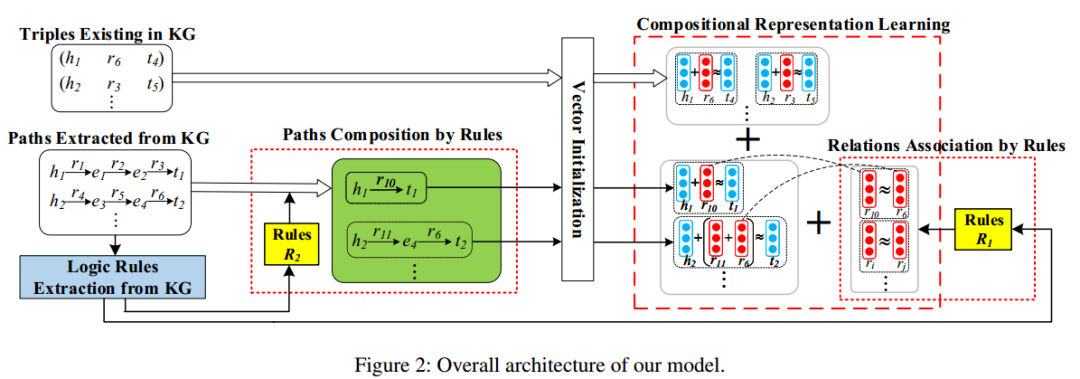
1. 挖掘规则:利用现有KG中的规则挖掘工具(如AMIE)自动从KG中抽取出规则,总共两类,包括长度为1的规则和长度为2的规则,每条规则有一个置信度 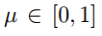

2. 挖掘KG中实体之间的路径:利用PtransE自动挖掘头实体h和尾实体t之间存在的路径p,每条路径p有一个置信度 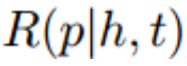
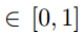
3. 利用挖掘出来的规则和实体之间的路径做实体的组合表征学习。
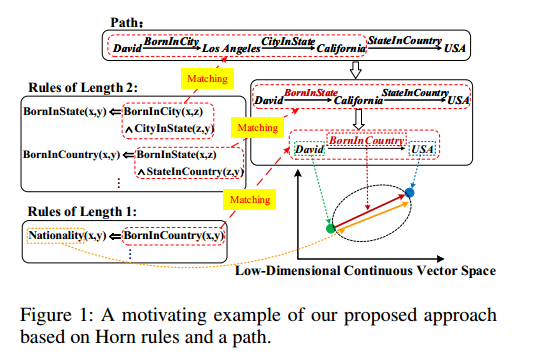
如上图所示PtransE挖掘出实体David和USA之间的一条路径如下

AMIE挖掘出2条长度为2的规则
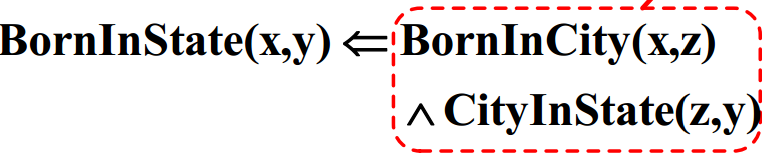
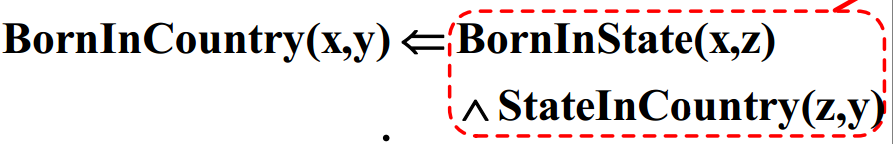
一条长度为1的规则
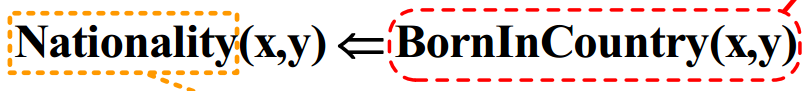
之后用长度为2的规则对路径做composition,其中长度为2的规则中的第一条可以将

组合成

之后长度为2的规则中的第二条可以将

组合成

之后根据长度为1的规则,我们需要让


4. 损失函数
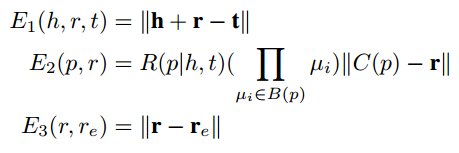
总共三个score function。
其中第一个score function源于TransE,不做过多解释。
第二个score function 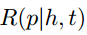
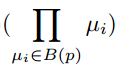
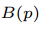
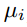
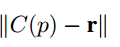
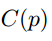
第三个score function 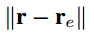
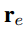
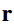
最终的损失函数为
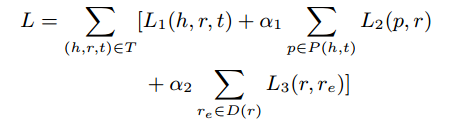
其中
分别是对对应三个score function的Margin Loss损失函数,其中第一个损失函数的负样本是随机将h、r、t替换掉;第二个损失函数及第三个是随机替换掉关系。
5. 模型整体框架如下
Experiment
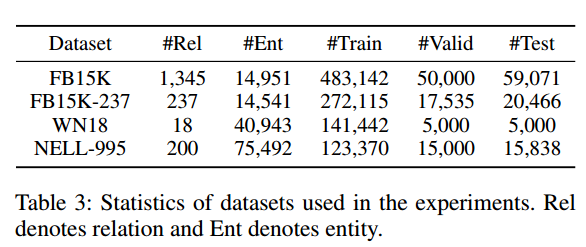
数据集情况:总共使用4个数据集。FB15K和FB15K-237是从Freebase中抽取的,WN18从WordNet中抽取,NELL-995从NELL中抽取。其中FB15-237是不包括inverse关系的,因此FB15K和FB15K-237一般被认为是两个不一样的数据集。
本文做的实验包括relation prediction和entity prediction。
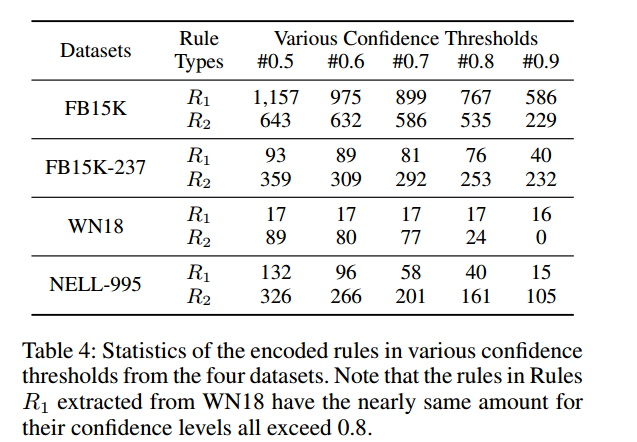
利用AMIE+挖掘出来的规则如下,每条规则会有一个0到1的阈值
评估指标
MR:the mean rank of correct entities
MRR:the mean reciprocal rank of correct entities
Hits@n :the proportion of test triples for which correct entity is ranked in the top n predictions
一个三元组的socre如下
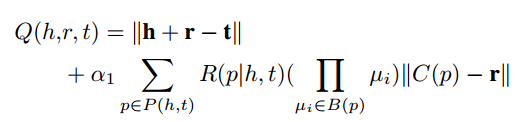
baseline的选择:第一种是TransE、TransR、TransH等Embedding methods;第二种是path-based的methods,如PtransE和DPTransE等。
第一个实验:rule置信度和路径长度对最终模型性能的影响
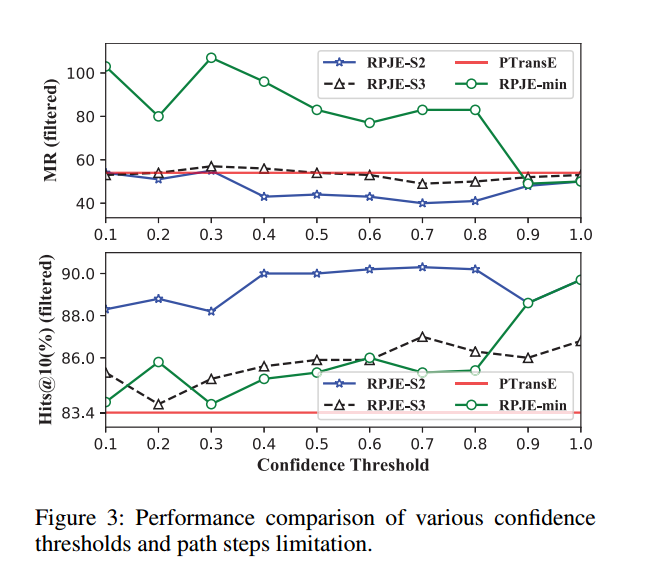
我们可以看到RPJE-S2的性能优于RPJE-S3说明采用长度最多为2的路径要优于采用长度最多为3的路径,这说明路径长度过长会使得在path composition的过程中引入过多噪音导致准确率下降。
RPJE-S2性能优于PTransE说明引入规则能够带来性能提升;
RPJE-S2性能优于RPJE-min说明规则的置信度需要引入到模型中,并更多关注那些置信度高的规则。
最终路径长度选择2,并过滤掉那些置信度小于0.7的规则
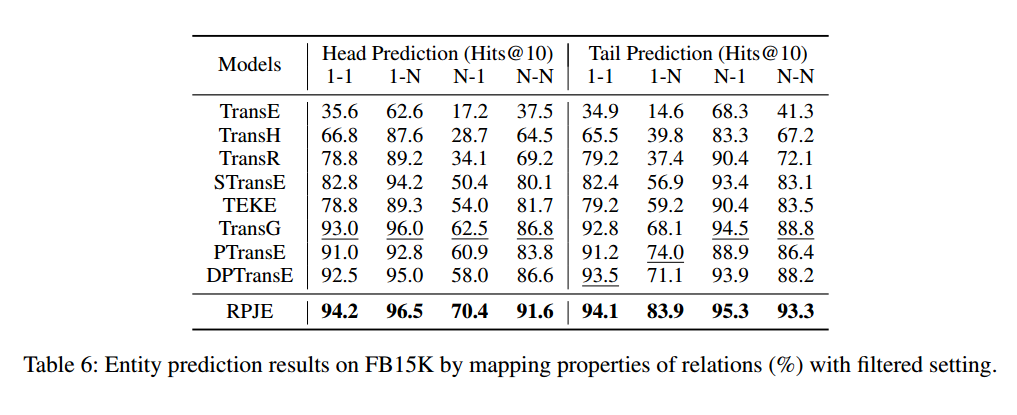
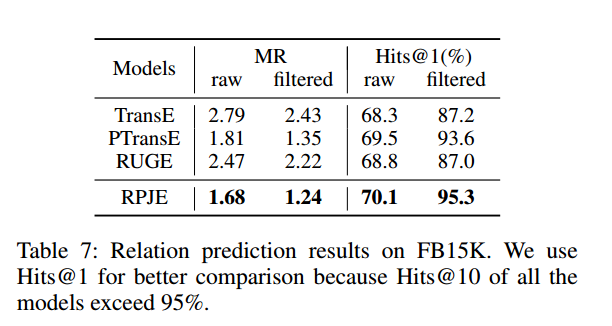
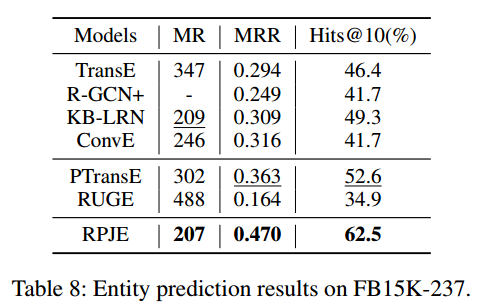
第二个实验:FB15K上的relation prediction和entity prediction,以及FB15K-237上的entity prediction。可以发现RPJE在所有指标上都比baseline好,说明了引入规则和路径的有效性。值得注意的是FB15-237中是没有inverse relation的,那么此时因此rules更能挖掘出关系之间的联系。
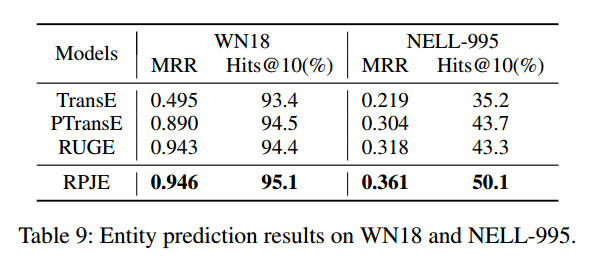
第三个实验:在WN18和NELL-995是关系很稀疏的两个数据集,因此可以挖掘的规则和路径少,但是RPJE仍然好于baseline,只是提升的程度比FB15K上的少,这说明RPJE可以在各种类型的KG中都有很好的表现,但是更能在那些关系比较多的KG中有好的表现。
第四个实验:引入规则为我们提供了可解释性。
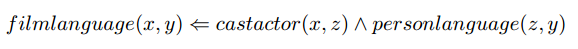
例如我们挖掘的规则中有上面这样一条规则,那么在测试的时候我们就知道在预测出来x和y之间有filmlanguage的时候的依据是什么。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。



