Magi 火了:搜索引擎界的一股清流

作者丨Tina
“Peak Labs”公司近日发布了其人工智能系统 Magi 的公众版“ magi.com ”。通过这一搜索引擎,用户输入关键词,即可获取 Magi 从互联网文本中自主学习到的结构化知识和网页搜索结果,每个结构化结果后面都会附上来源链接和其可信度评分。
这跟我们使用的传统搜索引擎不同,传统搜索引擎返回的是一系列的链接,要解读问题,还需要自己去点击网页挖掘有用信息。

这一引擎发布后,引来大批网友围观,将它的服务器玩挂了。Magi 作者发微博做了回应:“突然很多人关注到了我们,真的很感谢大家,其实搜索引擎真的不是我们的主业,我们自己没做任何推广,更没来得及准备应对这恐怖的流量……Magi 单次搜索的计算量比一般的网页搜索要重很多,请大家手下留情,同时再次表示抱歉!”
magi.com 的结果中,答案在搜索框的正下方,链接则在页面右边,跟主流搜索引擎的用户界面相反。如在 magi.com 里搜索“编程语言”,出来的首先是各种主流编程语言的合集:C#、Python、Java、JavaScript…同时给予“编程语言”这个词以“描述”和“属性”解释。红黄绿的颜色代表 Magi 给出的可信评分级别。
在答案的右侧提供了一些链接,用鼠标划过它们即可看到,答案是从哪个具体的来源学习到的:
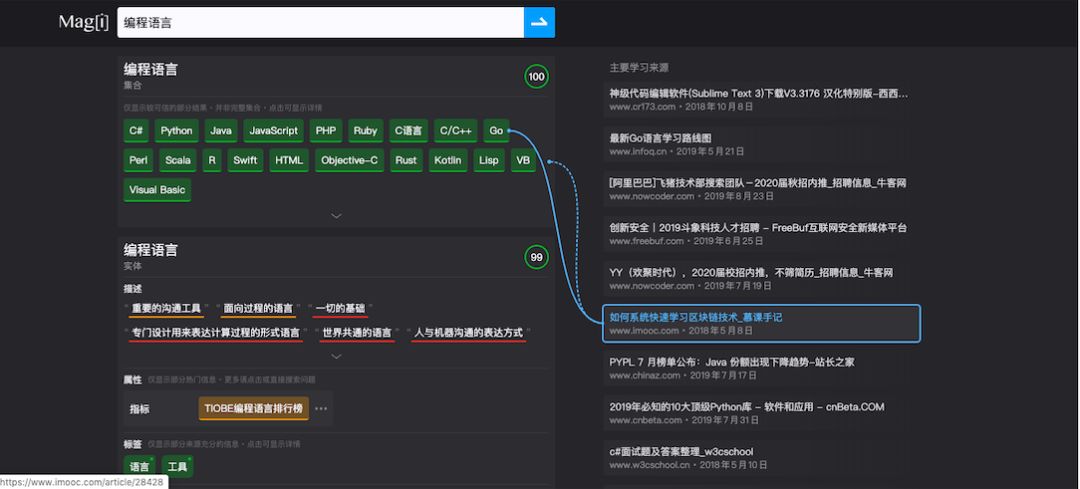
Magi 的关注点在用户搜索行为的本质,相对传统搜索引擎来说做了一点小改进 :“帮你思考”。当输入想了解事物或信息,传统搜索引擎给出的是按照结果的权重 (Page Rank) 展现的链接信息,需要自己去归纳和判断可信度。Magi 多做了一步,不仅收录互联网上的海量文本,还会去尝试理解并学习这些文本中蕴含的知识和数据。
季逸超表示,Magi 类似于民用版的 IBM Watson 或非学术版的 Wolfram Alpha。Wolfram Alpha 是一个读得懂你提问的搜索引擎,它的目标是“计算一切” 。按照发明者 Stephen Wolfram 的说法,它是一个计算知识引擎,而不是像百度或者谷歌那样的搜索引擎。简单地说来,它其实是一个绘图计算器、参考书图书馆、以及搜寻引擎的综合体,非常超前。
除了直接给出计算结果,Wolfram Alpha 还能够处理基于自然语言的事实问答问题,例如:
如果输入“China GDP”,出现的将不是一大堆网页,而是直观的数据和图表。包括:中国 GDP 最新情况,从 1970 年至今的中国 GDP 增长情况(图表形式)、中国通货膨胀率、失业人口率。
如果输入“How many people in China”,你可以看到当前中国的总人口数、人口密度、平均每年人口增长率、预期寿命和平均年龄等数据。

Magi 来自中国团队 Peak Labs,创始人季逸超在开发者圈子内也小有名气。2011 年,还在北大附中读书期间,他就独自完成了猛犸浏览器 iOS 的开发。2012 年,季逸超创办了自己的公司,继续推动浏览器和输入法项目。目前,Peak Labs 主要精力都放在 Magi 项目上,专注于背后的技术,以及相关商业产品的开发。
“我们真正做商业化的,是 Magi 背后的技术——基于迁移学习的开放信息提取。”Magi 采取的迁移学习 NLU 算法,具有的优势在于只需使用通用数据训练 AI 引擎,就能使 AI 引擎很好的适用专业垂直领域。Magi 首先使用互联网知识和自有的数据进行预训练,而专业垂直领域的任务仅需极少量人工数据标注,就能达到大规模数据的训练效果。
季逸超在知乎上给出了详细而全面的技术解读
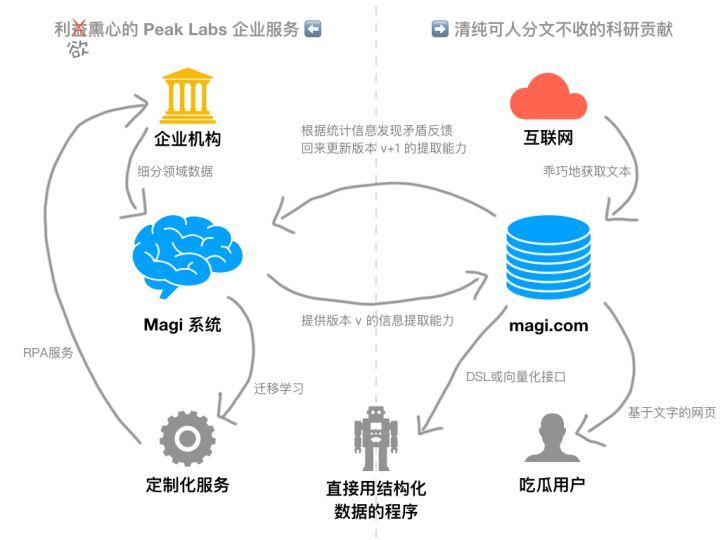
Magi 不再依赖于预设的规则和领域,“不带着问题” 地去学习和理解互联网上的文本信息,同时尽可能找出全部信息 (exhaustive) 而非挑选唯一最佳 (most promising)。Magi 通过一系列预训练任务淡化了具体实体或领域相关的概念,转而学习 “人们可能会关注内容中的哪些信息?”。为 Magi 设计了专门的特征表达、网络模型、训练任务、系统平台(下面都会讲到),并投入大量精力逐渐构建了 proprietary 的专用训练 / 预训练数据。Magi 通过终身学习持续聚合和纠错,为人类用户和其他人工智能提供可解析、可检索、可溯源的知识体系。
配合自家 web 搜索引擎以评估来源质量,信息源和领域不设白名单,综合 Clarity(清晰度)、Credibility(可信度)、Catholicity(普适性)三个 Magi 权衡知识工程的规模化和准确性难题的量化标准来进行来源质量评估。且注重时效性,时效性体现在上文提到的对既有知识的时间线追踪,做到不再周期性触发 batch 更新,整个系统持续在线上学习、聚合、更新、纠错。
没有前置 NER 和 dependency parsing 等环节,减少母文本信息的损失。为 Magi 的提取模型设计了专用的 Attention 网络结构以及数个配套的预训练任务。技术栈完全 language-independent,可以实现低资源和跨语言 transfer。
Magi 官网和季逸超自己也坦承还存在一些不足,比如消歧义、工程性,以及规模化和准确度等。对于搜索慢的问题,季逸超在微博中说,这是由于单次搜索的计算量比一般的网页搜索要重很多。Magi 搜索结果目前还不够好,但这也不妨碍它成为一个未来的搜索引擎方向,给用户提供一个可信任的和理解学习之后的知识。特别是发展在这个 AI 时代,搜索引擎的结果更应该贴近用户的需求。
现在的主流搜索引擎依靠机器抓取,建立在超链分析基础上的网页搜索,采用搜索爬虫和排序算法的组合,以关键词为核心自动检索,实现海量信息的自动获取与重要性排序。作为获取信息的入口,它直接关系到我们获取的信息的质量,也成就了早期的互联网公司。
但现在搜索引擎的过度商业化操作已经引起了用户的反感。Magi 的优势在于去除了商业化的元素,筛除了广告,使搜索到的信息更纯粹,更有价值,节省用户的时间。
季逸超在他的微博里说道:“现在的 Magi 饱含一个工程师朴素的初心,既不想拿广告恶心你,也对你的隐私毫无兴趣。”
Magi 引擎的“火”,说明了搜索引擎在向更好的方向发展。

点个在看少个 bug 👇



