长文档的激增为信息检索(IR)带来了根本性的挑战,因为其篇幅长度、证据分散以及结构复杂性,使得仅依赖标准的段落级技术远远不够。本综述首次对长文档检索(Long-Document Retrieval, LDR)进行了系统性的总结,整合了不同时期的方法、挑战与应用。我们梳理了该领域从经典的词法模型、早期神经模型,到现代的预训练语言模型(PLM)和大语言模型(LLM)的演进过程,涵盖了诸如段落聚合、层次化编码、高效注意力机制,以及最新的基于 LLM 的重排序与检索方法等核心范式。除模型方法外,我们还回顾了面向特定领域的应用、专门的评测资源,并指出了关键的开放挑战,例如效率权衡、多模态对齐与结果可靠性等问题。本综述旨在为研究者提供一个全面的参考,同时提出面向基础模型时代推进长文档检索的前瞻性研究议程。
1 引言与贡献
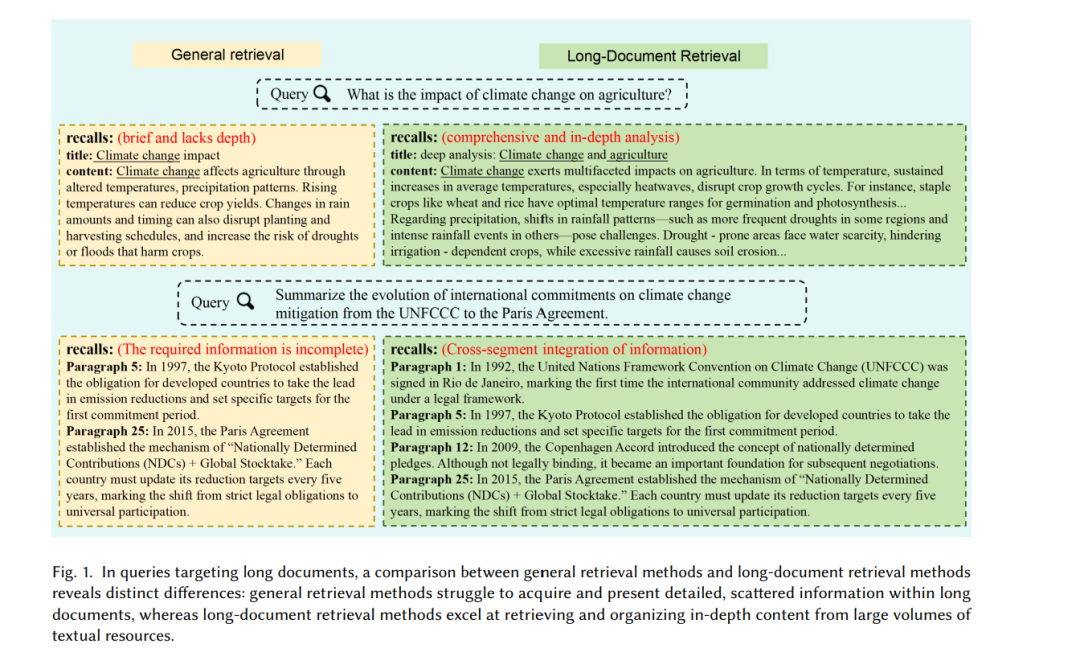
从在数百页的法律合同中定位一个关键条款,到在成千上万篇生物医学研究论文中综合证据,如何从长篇文档中精准检索信息,已经成为当代信息环境中的基础性挑战。数字信息的指数级增长催生了庞大的语料库,这些语料以科学论文与专利、法规与司法判决、金融与技术报告、临床笔记、书籍以及富媒体网页为代表,成为知识的主要载体。这些文档往往包含数千到数万个 token,且具有丰富的内部结构。从此类材料中检索证据,对于网络搜索、法律发现(legal discovery)、科学知识挖掘、临床决策支持以及企业智能等任务来说都是基础。然而,正是长文档的这些特性——分散的证据、层次化的组织结构、文档间的链接关系——使得其对传统信息检索管线构成了重大挑战。 我们研究的长文档检索(Long-Document Retrieval, LDR)任务可以表述为:给定查询 qqq 和一个长文档语料库 DDD,系统需要返回一个文档或文档内单元的排序结果,并理想情况下给出片段级(span-level)的解释。在实际中,索引通常建立在多粒度水平,相关性既需要兼顾文档整体效用,也要覆盖支持性的细粒度片段。LDR 相比标准的即席检索(ad hoc retrieval),在以下三个维度上有所不同:(i)证据分散性:相关信号分布在多个片段中,必须加以聚合;(ii)层次化与跨文档结构:标题、引用、超链接以及版本图都会影响相关性判断;(iii)计算约束:编码与交互的成本随文档长度急剧增加,若不调整模型架构或管线,效率难以保障。该问题还可进一步推广至长查询场景以及多模态文档场景。 传统的词法方法稳健且高效,但在长文本上容易退化,原因包括冗长性偏差、主题漂移以及无法建模跨片段依赖关系。早期的神经排序器在段落尺度上改进了匹配效果,但仍受限于输入窗口大小和注意力机制的二次复杂度,而朴素的截断或滑动窗口启发式方法则会牺牲全局一致性并引入顺序偏差。这些限制推动了三代逐步应对 LDR 特定挑战的技术浪潮。 在 PLM 时代,研究者通过三类关键创新扩展了预训练 Transformer 编码器以处理长输入:首先是基于段落的“分而治之”策略,通过汇聚各块的得分来建模,如 BERT-MaxP/SumP 和 PARADE;其次是发展了层次化模型,能够利用文档的显式结构进行信息汇聚,如 KeyB 和 IDCM;第三类则是引入稀疏与高效注意力机制(如 Longformer 与 BigBird),以缓解长序列处理中的二次复杂度。 在此基础上,LLM 时代引入了可执行指令的模型,主要承担两类角色:一类是作为强大的重排序器(re-ranker),典型如基于 listwise 提示的 RankGPT;另一类则是通过微调实现端到端的检索器,如双编码器变体 RepLLaMA 与 RankLLaMA。同时,系统层面也伴随出现了长上下文高效处理的创新,例如 LLM 的稀疏注意力、提示压缩(prompt compression)、以及 KV-cache 复用。 LDR 的评测尤为复杂。Web 与企业级测试集中的标签稀疏性、混合的相关单元以及分级判断,都使得标准指标难以直接适用。除文档级的 nDCG/MAP/MRR 外,常常需要引入片段级的改造指标和层次化召回,尤其在部分标注场景下。专门的评测协议还会涉及长查询(如 QBD)以及结构或版式感知的检索任务,在此类任务中,章节锚点和页面元素直接决定相关性。近期数据集也扩展到跨语言和多模态场景,以贴合真实应用需求。 本综述所涵盖的方法论,直接受到那些“文档冗长本身就是挑战”的应用驱动。例如,法律检索要求判例之间的匹配、法规版本对齐以及跨来源研究,这些文档常常包含修辞结构和密集的引用/版本关系。生物医学文献检索与临床决策支持依赖 PubMed/PMC 与 EHR 全文证据的定位,并日益结合多模态信号。Web 搜索需要处理长篇新闻特写与技术白皮书,常常要求文本与图像、表格或嵌入媒体的对齐。科学论文检索则受益于结合引用信号和 LLM 引导的概念索引的文档级表示;而跨语言 LDR 则要求在不同语言间桥接的同时保留片段级的溯源能力。在这些领域中,有效系统必须保持层次结构、聚合分散证据,并提供可审计的推理依据。
与现有综述的对比
虽然已有关于神经信息检索【32】、高效 Transformer 架构【76】以及大语言模型在信息检索中的应用【98】的综合性综述,但这些工作通常只是将长上下文作为众多挑战之一,而非核心焦点。因此,它们未能对 LDR 内在的关键问题(如跨超长文本的证据分散、层次结构建模,以及针对长文档的专门评测协议演化)给出统一且端到端的分析。据我们所知,这是首个专门针对长文档检索的系统化综述,从经典词法模型到最新的 PLM 和 LLM 范式,完整追踪了该领域的演进过程。我们的工作不仅系统化了模型方法,还为特定领域的应用、评测基准和未来研究议程提供了综合指导,从而为该领域提供了一份完整的参考。
本文贡献
为了为研究者与实践者提供清晰的研究路线并推动未来创新,本综述的主要贡献包括: * 统一的问题表述:我们将 LDR 在文档级、段落级和版式级目标下(涵盖短查询与长查询,包括 QBD)进行了形式化定义,为连接先前分散的研究提供了统一框架。 * 跨三代的发展脉络:我们系统化梳理了从词法与早期神经方法,到基于 PLM 的段落/层次/稀疏注意力模型,再到基于 LLM 的检索器与重排序器的演进,阐明各类方法如何应对片段稀释、保持全局一致性并控制计算成本。 * LLM 时代的整体相关性建模:我们识别出该领域从局部窗口投票转向指令对齐、全局建模与片段级解释的范式转变,分析了 listwise 与 pairwise 提示方式、LLM 判断的校准问题及幻觉风险。 * 长上下文的效率原则:我们总结了稀疏注意力、层次化池化、查询驱动路由、提示压缩以及 KV-cache 复用等设计模式,并将其与一阶段召回、重排序和阅读/生成任务关联起来。 * 评测指南:我们整合了纯文本、结构感知、多模态与跨语言的评测基准;讨论了片段级指标、部分聚合以及在稀疏标注下的可靠性,并提出了大规模语料评测的可复现性最佳实践。 * 应用蓝图:我们提供了适用于法律、生物医学与学术等场景的端到端系统框架,这些框架结合了结构感知索引、图结构扩展、长上下文重排序与片段级生成,契合特定领域的约束。 * 前瞻性研究议程:我们指出了当前的关键缺口,包括标签稀疏、稳健的长查询处理、忠实的多模态检索以及效率与效果之间的权衡,并勾勒了未来的研究方向。
研究路线
本文首先回顾 PLM 出现之前的基线方法,然后依次介绍基于 PLM 的 LDR、基于 LLM 的检索/重排序方法及其效率创新与多模态扩展。随后,我们给出比较分析,总结数据集与评测协议(包括结构与版式感知基准),并详细讨论在法律、生物医学、Web/新闻、科学检索以及跨语言场景中的应用蓝图。最后,我们提出开放挑战与未来研究议程。