
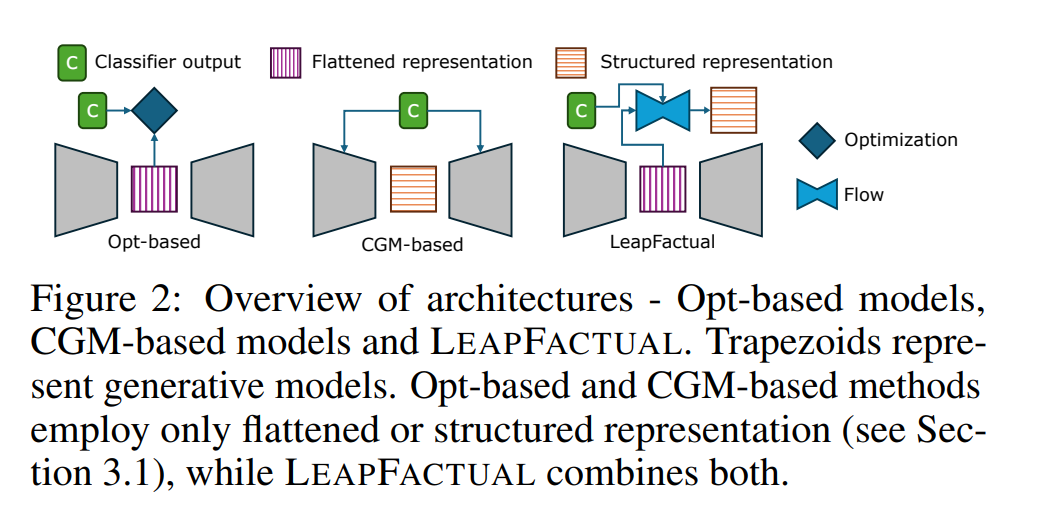
随着机器学习(ML)与人工智能(AI)模型不断深入高风险领域(如医疗保健与科学研究),模型不仅需要具备高精度,还应具备 可解释性 。在现有的可解释方法中, 反事实解释(counterfactual explanation) 通过识别能够改变模型预测结果的最小输入改变量,从而提供更深入的解释性洞见。然而,当前的反事实生成方法仍存在关键性局限,包括 梯度消失 、 潜在空间不连续 ,以及 过度依赖学习到的决策边界与真实决策边界的一致性 等问题。 为克服上述限制,我们提出了一种基于 条件流匹配(conditional flow matching) 的全新反事实解释算法—— LEAPFACTUAL 。该方法能够在真实与学习的决策边界不一致的情况下,生成 可靠且信息丰富的反事实样本 。遵循模型无关(model-agnostic)的设计理念,LEAPFACTUAL不仅适用于具有可微损失函数的模型,还能处理 人类参与式系统(human-in-the-loop systems) ,从而将反事实解释的应用范围扩展到需要人工标注者参与的领域,如 公民科学(citizen science) 。 我们在多个基准与真实世界数据集上进行了大量实验,结果表明:LEAPFACTUAL能够生成 准确且分布内(in-distribution) 的反事实解释,为模型提供 可操作性洞见(actionable insights) 。例如,我们观察到,所生成的与真实标签一致的可靠反事实样本可作为新的训练数据,用于进一步提升模型性能。总体而言,所提出的方法具有广泛的适用性,不仅促进了 科学知识发现 ,也增强了 非专业用户的可解释性理解。
成为VIP会员查看完整内容
相关内容
相关主题